Download as PDF, PPTX



![Pointer analysis
void foo(int * a, float * b) {
for(int i = 1; i < N; i++) {
a[0] += a[i];
b[0] *= b[i];
} }
The purpose of pointer analysis is to detect whether a and b may
refer to the the same memory area.
It is difficult because:
Lack of information about program (in per-module build
mode)
Pointer analysis needs a lot of resources (in whole-program
mode)
Pointer analysis algorithms are complicated
3 / 20](https://image.slidesharecdn.com/12-50stbaaslides-170323100514/85/TMPA-2017-Simple-Type-Based-Alias-Analysis-for-a-VLIW-Processor-3-320.jpg)



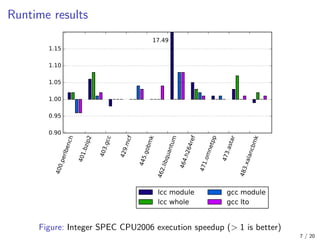
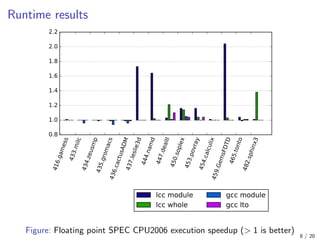
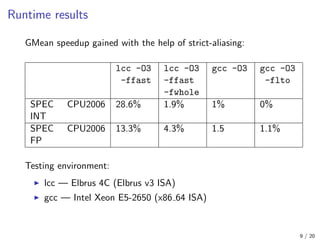

![462.libquantum
This test got 17.49 times execution speedup after enabling
strict-aliasing analysis for per-module build mode!
Three hottest functions have the same pattern:
void foo(str_1 * str) {
for(int i = 0; i < N; i++)
{
str->arr[i].field; // LOAD of arr and LOAD of
field
...
str->arr[i].field = val; // STORE to field
}
}
Dependence between STORE of field and LOAD of arr prohibits to
eliminate invariant LOAD.
11 / 20](https://image.slidesharecdn.com/12-50stbaaslides-170323100514/85/TMPA-2017-Simple-Type-Based-Alias-Analysis-for-a-VLIW-Processor-11-320.jpg)









The document discusses a simple type-based alias analysis algorithm implemented in the Elbrus compiler for a VLIW microprocessor, focusing on the benefits and challenges of strict-aliasing in C. The analysis reveals performance improvements in runtime execution speed by identifying compatible types, while also outlining the complexity and resource demands of pointer analysis. Additionally, it highlights future research directions for improving strict-aliasing error detection and enhancing the algorithm's capabilities.










![[Bop] Block Oriented Programming Automating Data-only Attacks](https://cdn.slidesharecdn.com/ss_thumbnails/bop-blockorientedprogrammingautomatingdata-onlyattacks-slide-cxm-181010081006-thumbnail.jpg?width=640&height=640&fit=bounds)