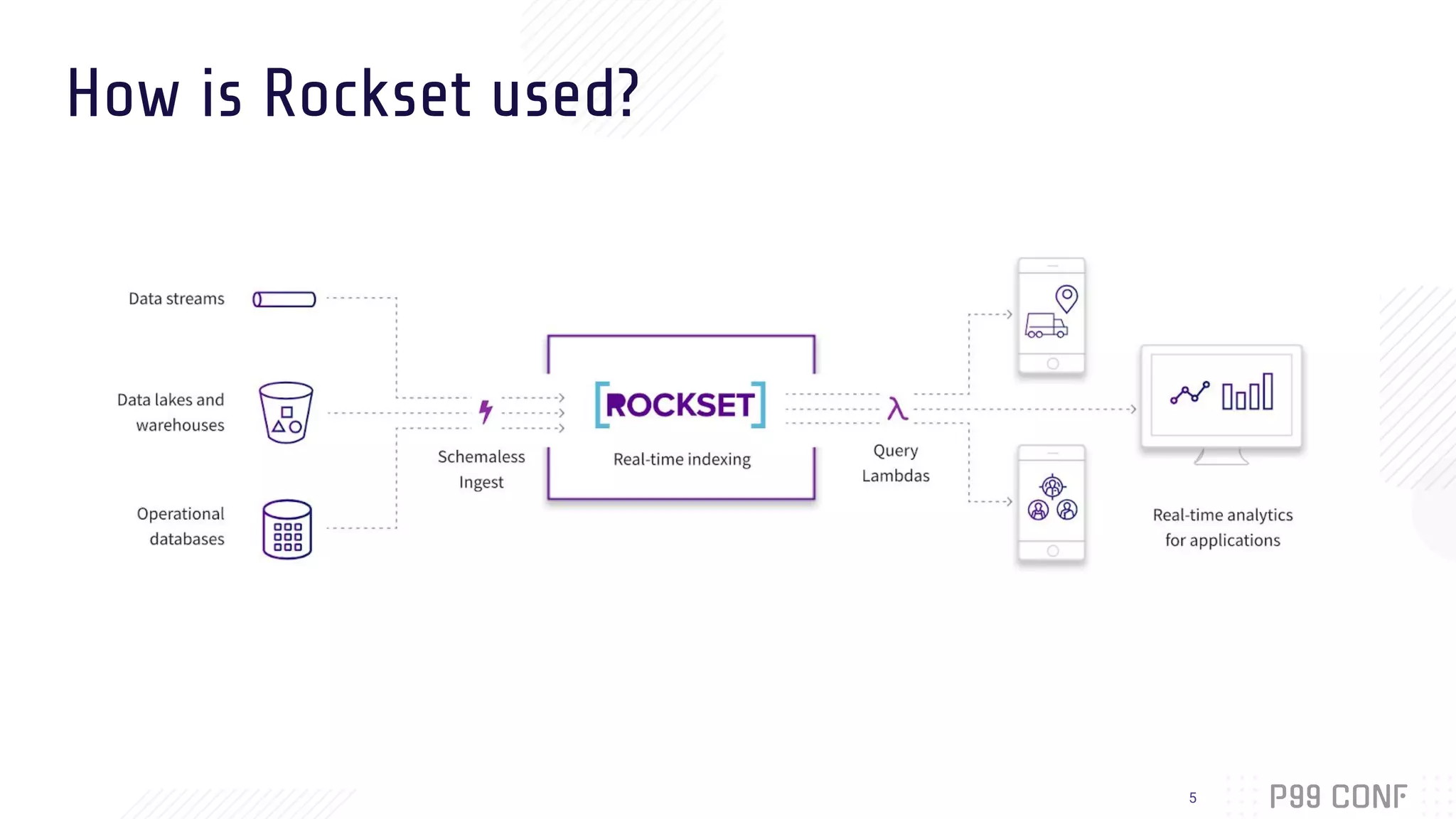
Download as PDF, PPTX









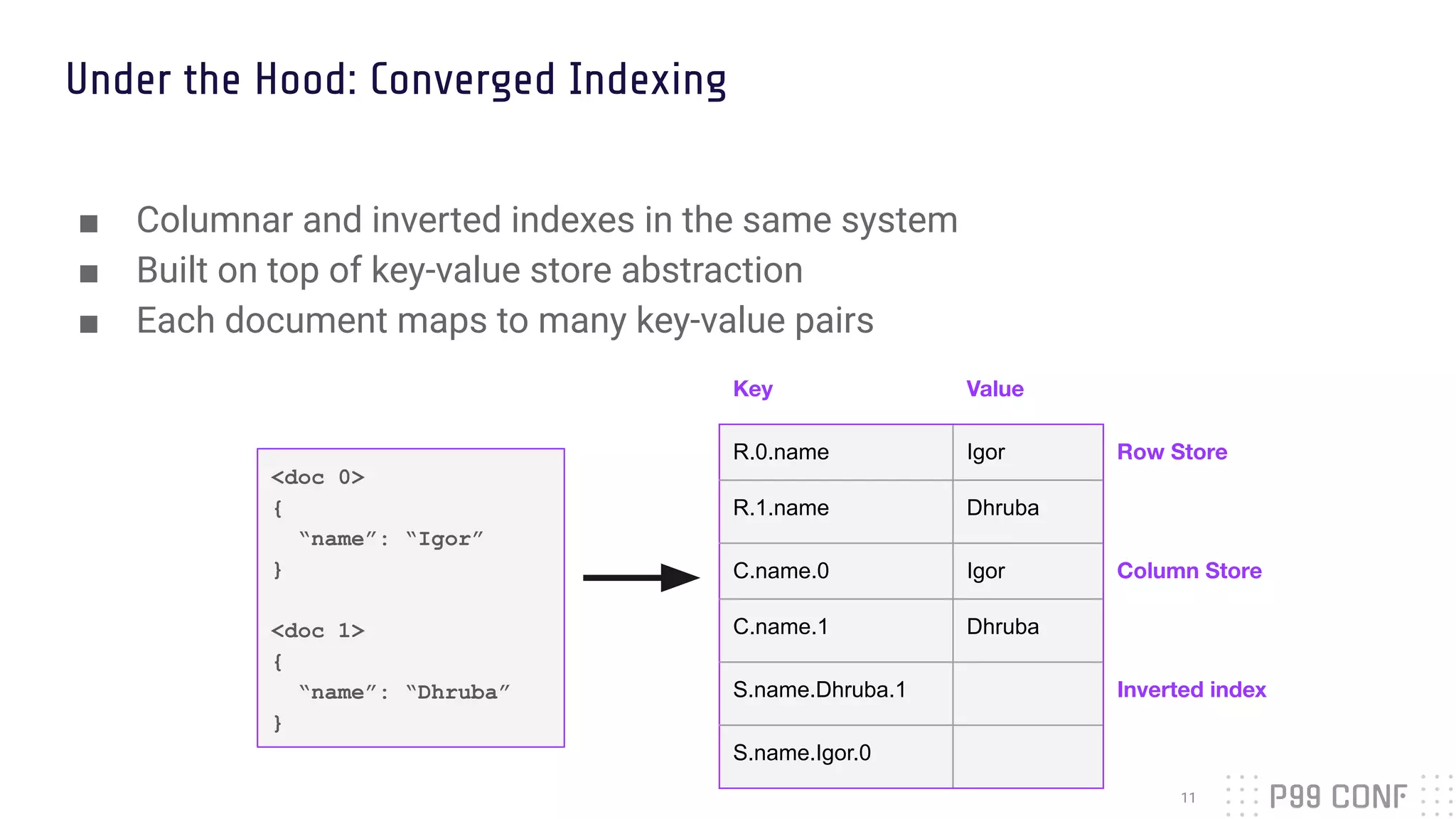
![Inverted Indexing for point lookups
■ For each value, store documents containing that value (posting list)
■ Quickly retrieve a list of document IDs that match a predicate
“name”
“interests”
Dhruba 1
Igor 0
databases 0.0; 1.1
cars 1.0
snowboarding 0.1
“last_active”
2019/3/15 0
2019/3/22 1
<doc 0>
{
“name”: “Igor”,
“interests”: [“databases”, “snowboarding”],
“last_active”: 2019/3/15
}
<doc 1>
{
“name”: “Dhruba”,
“interests”: [“cars”, “databases”],
“last_active”: 2019/3/22
}](https://image.slidesharecdn.com/p99-dhruba-borthakur-rockset-211004182037/75/Realtime-Indexing-for-Fast-Queries-on-Massive-Semi-Structured-Data-12-2048.jpg)
![Columnar Store for aggregations
■ Store each column separately
■ Great compression
■ Only fetch columns the query needs
<doc 0>
{
“name”: “Igor”,
“interests”: [“databases”, “snowboarding”],
“last_active”: 2019/3/15
}
<doc 1>
{
“name”: “Dhruba”,
“interests”: [“cars”, “databases”],
“last_active”: 2019/3/22
}
“name”
“interests”
0 Igor
1 Dhruba
0.0 databases
0.1 snowboarding
1.0 cars
1.1 databases
“last_active”
0 2019/3/15
1 2019/3/22](https://image.slidesharecdn.com/p99-dhruba-borthakur-rockset-211004182037/75/Realtime-Indexing-for-Fast-Queries-on-Massive-Semi-Structured-Data-13-2048.jpg)


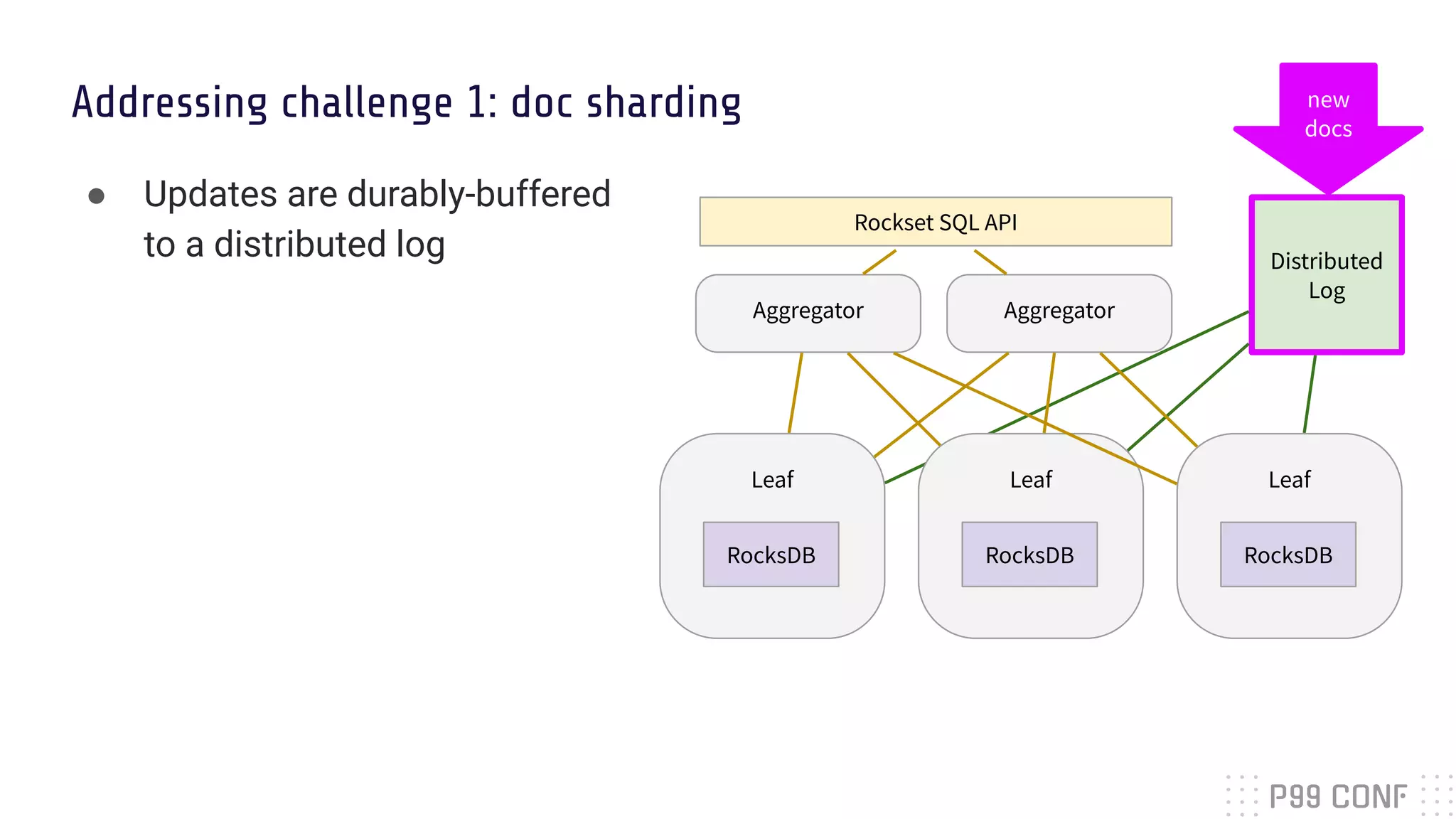
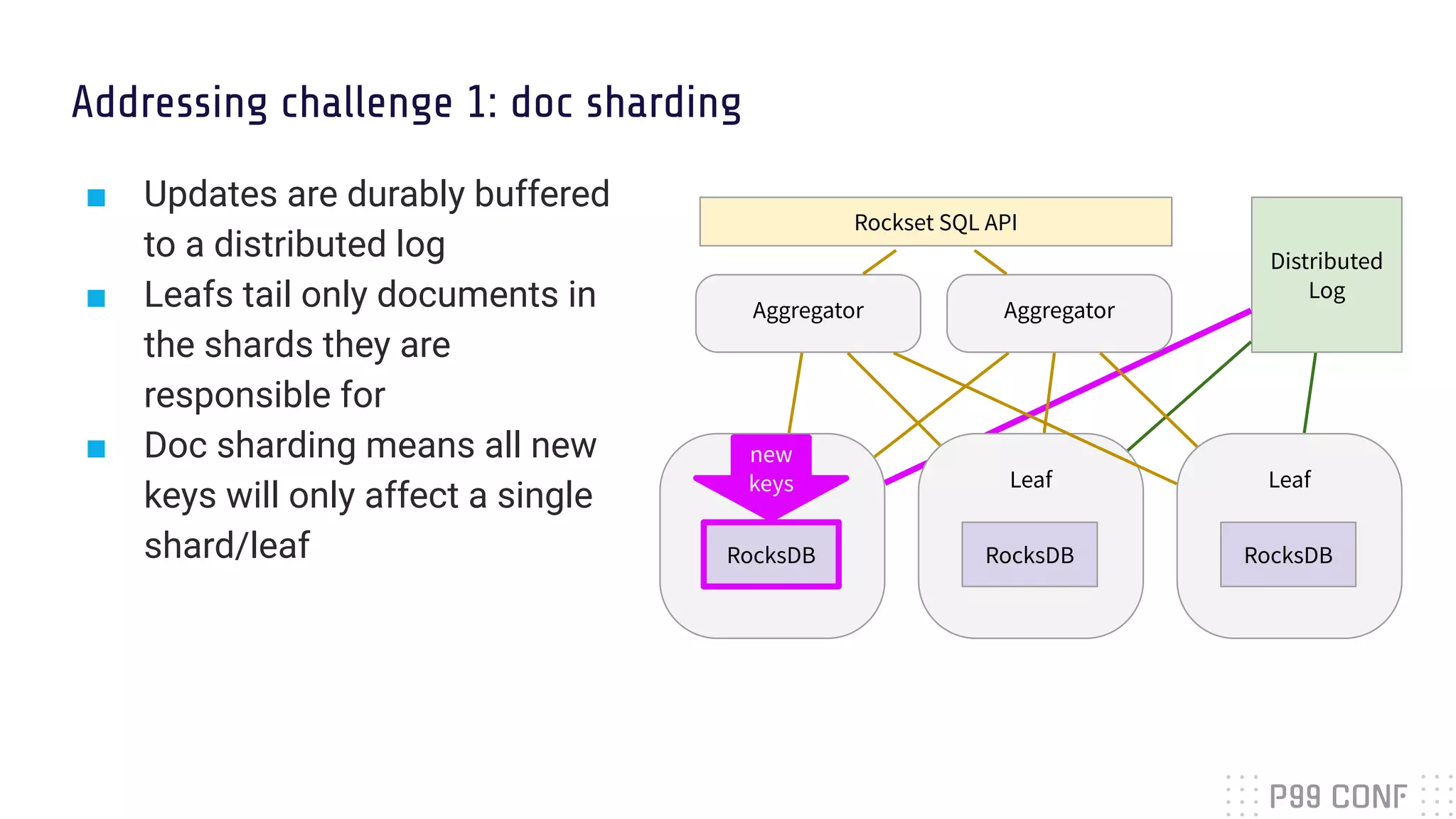
![Challenge 1: one new record = multiple servers updates
■ In a traditional database with term sharding and n indexes, one write
incurs updates to n different indexes on n servers
■ Requires a distributed transaction (paxos, raft) between n servers
<doc 1>
{
“name”: “Dhruba”,
“interests”: [“cars”, “databases”],
“last_active”: 2019/3/22
}
“interests”
Dhruba 1
Igor 0
databases 0.0; 1.1
cars 1.0
snowboarding 0.1
“last_active”
2019/3/15 0
2019/3/22 1
“name”](https://image.slidesharecdn.com/p99-dhruba-borthakur-rockset-211004182037/75/Realtime-Indexing-for-Fast-Queries-on-Massive-Semi-Structured-Data-16-2048.jpg)
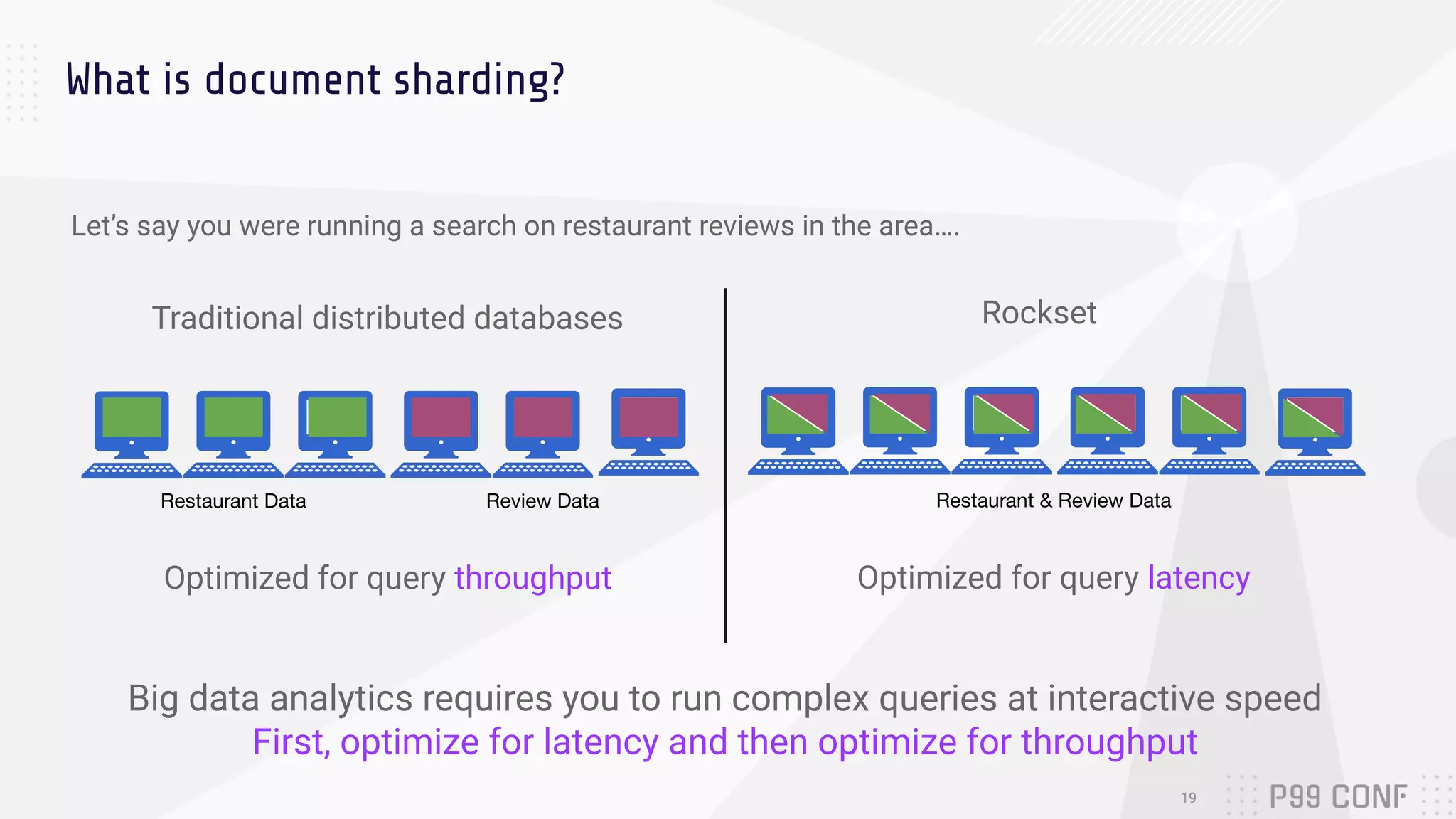

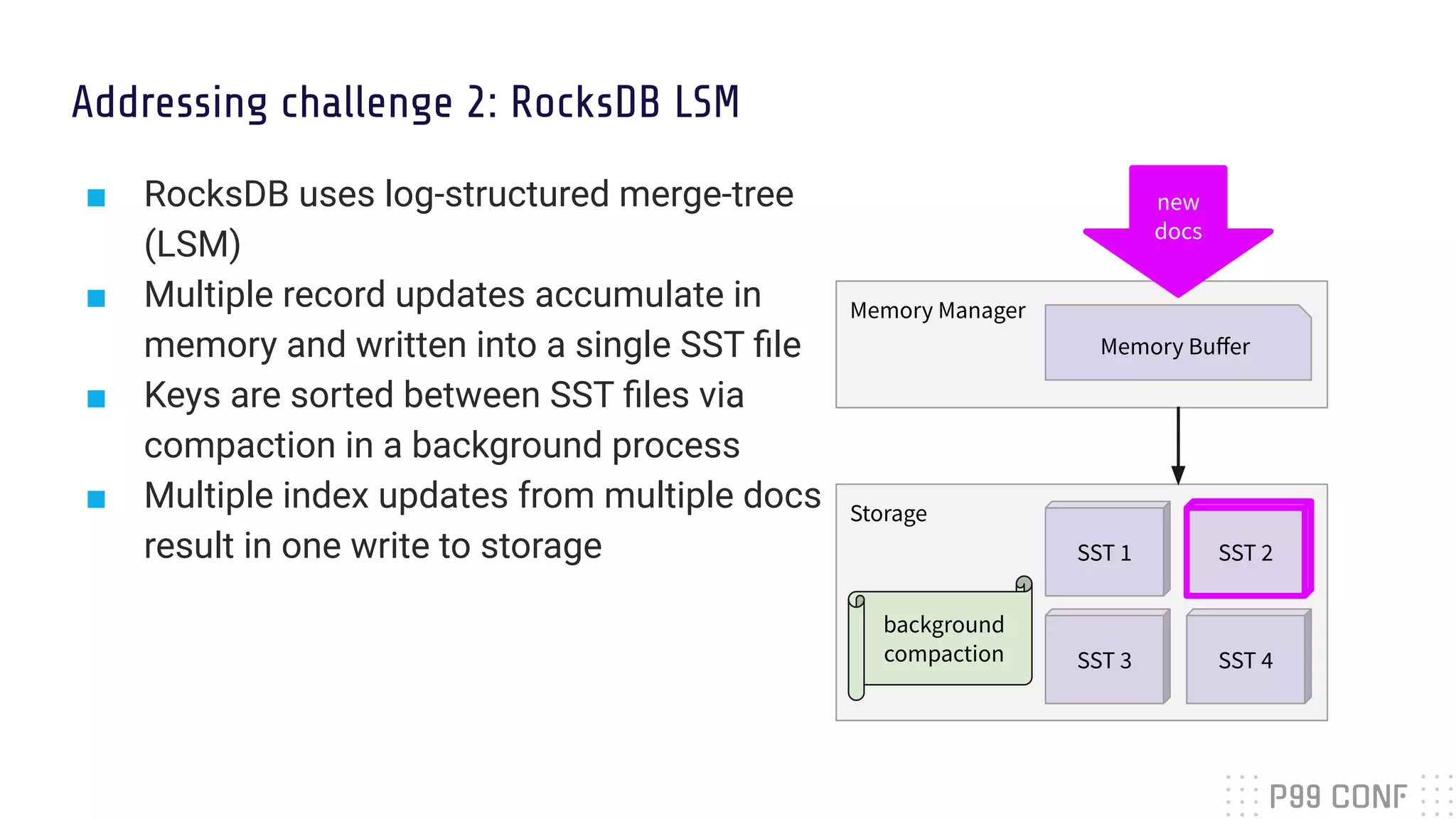


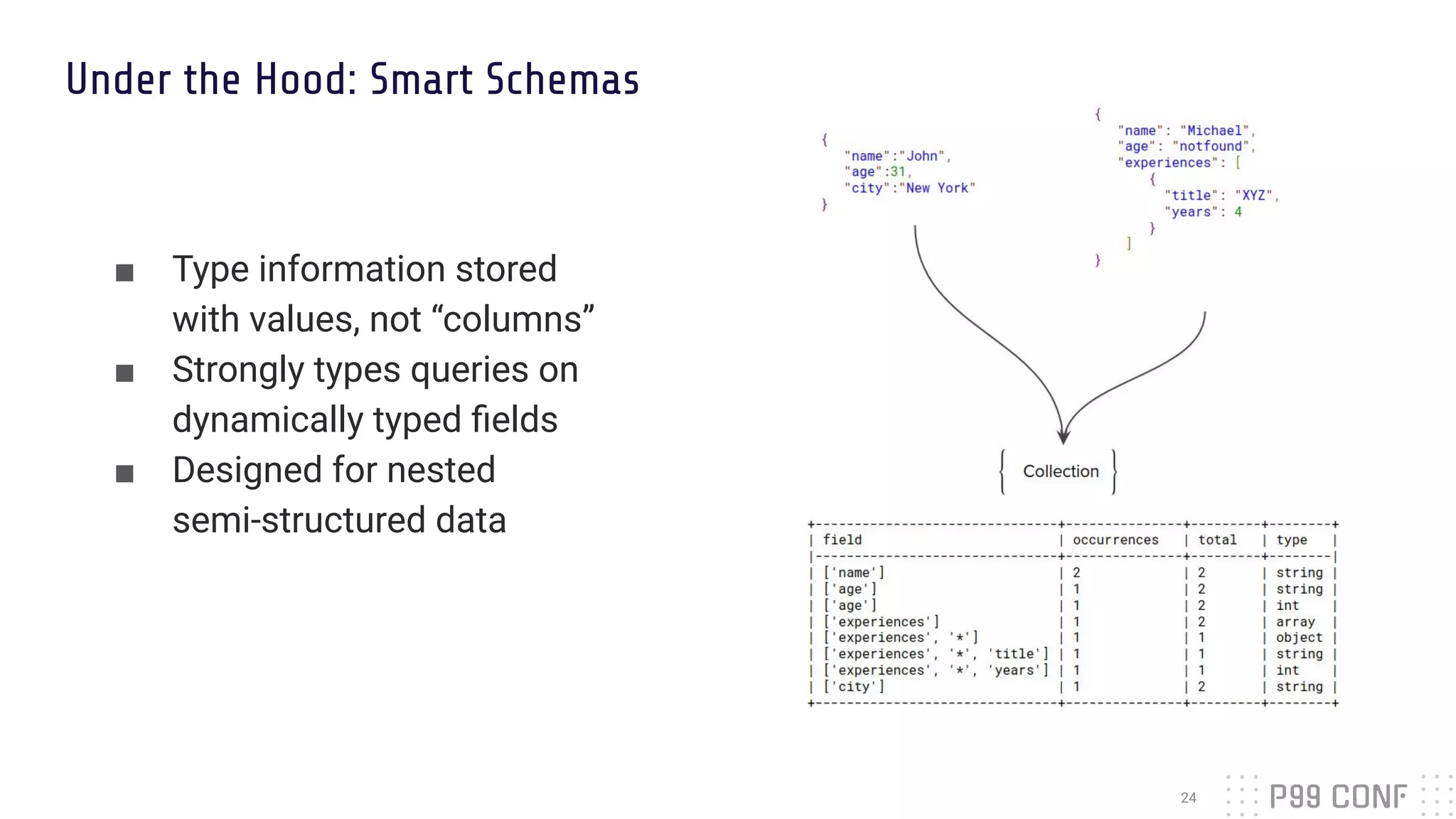
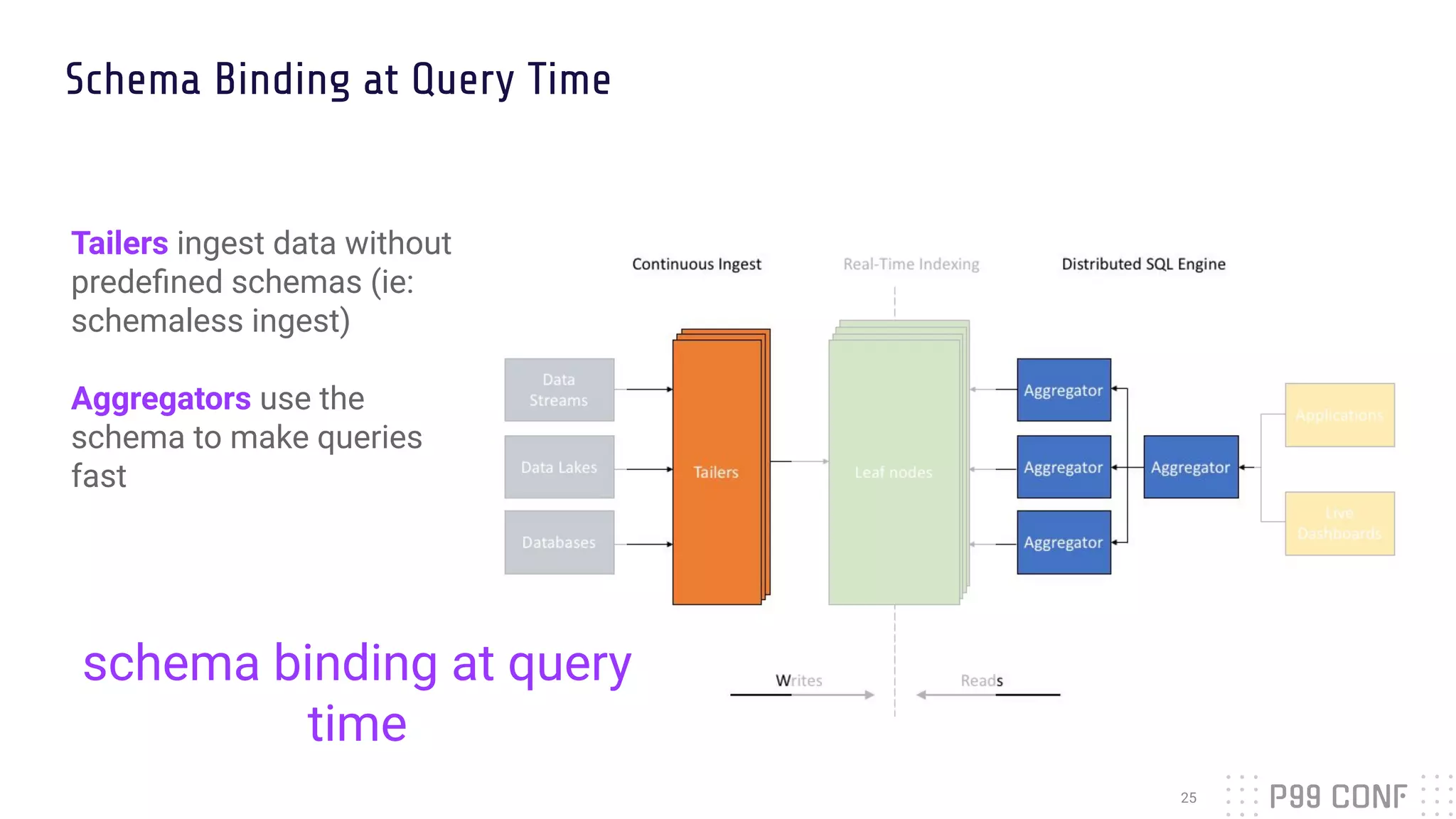








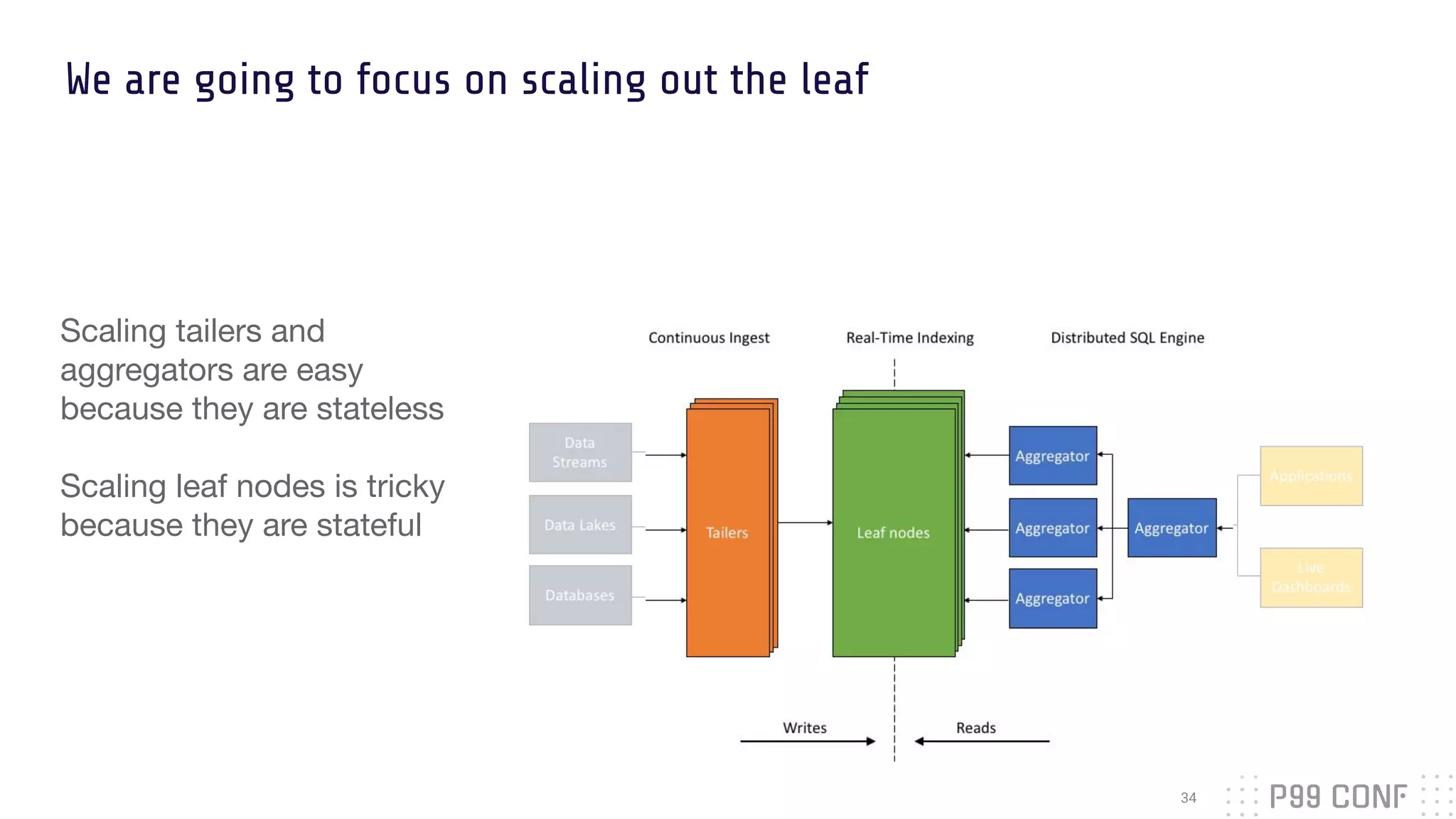

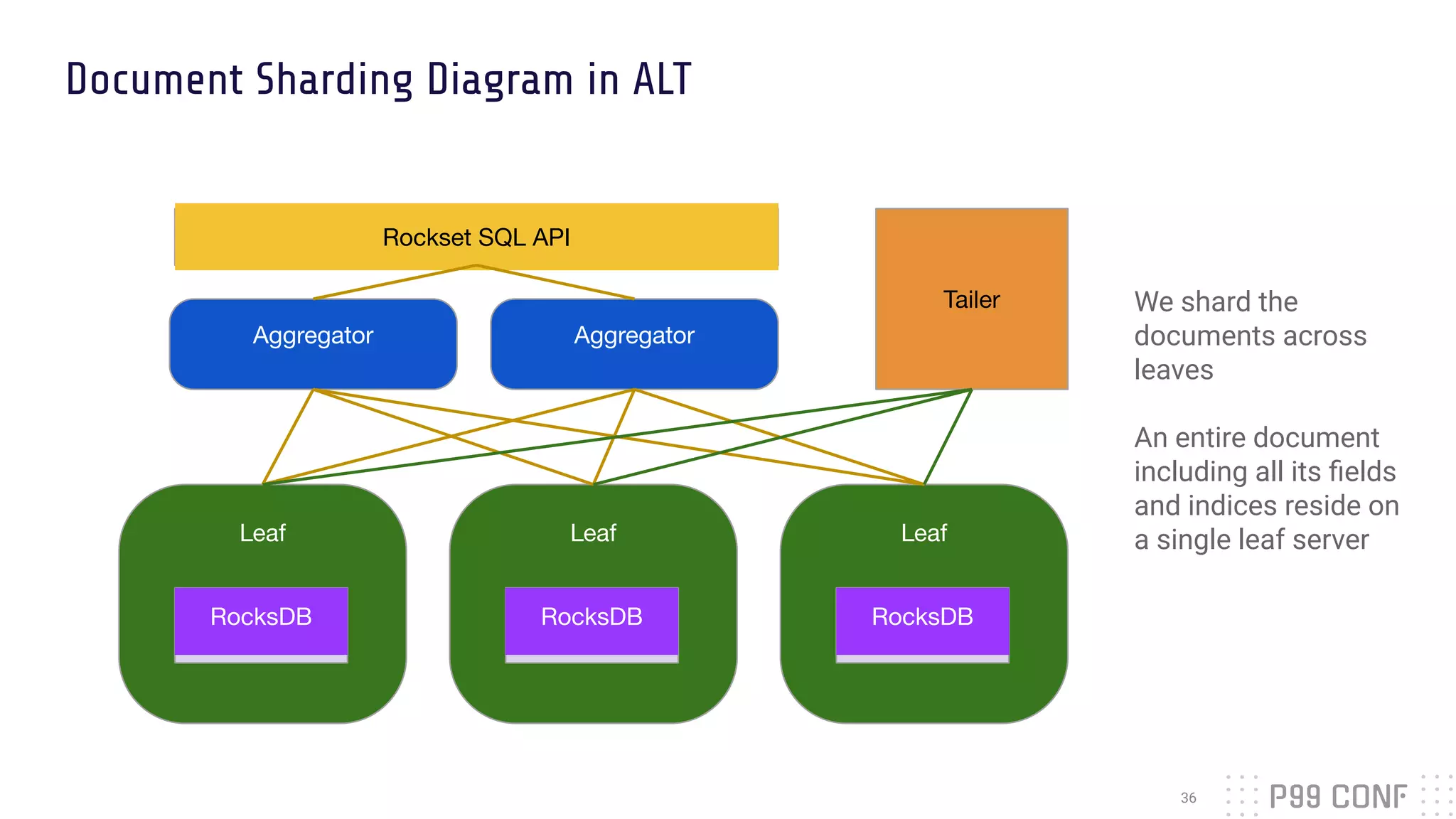
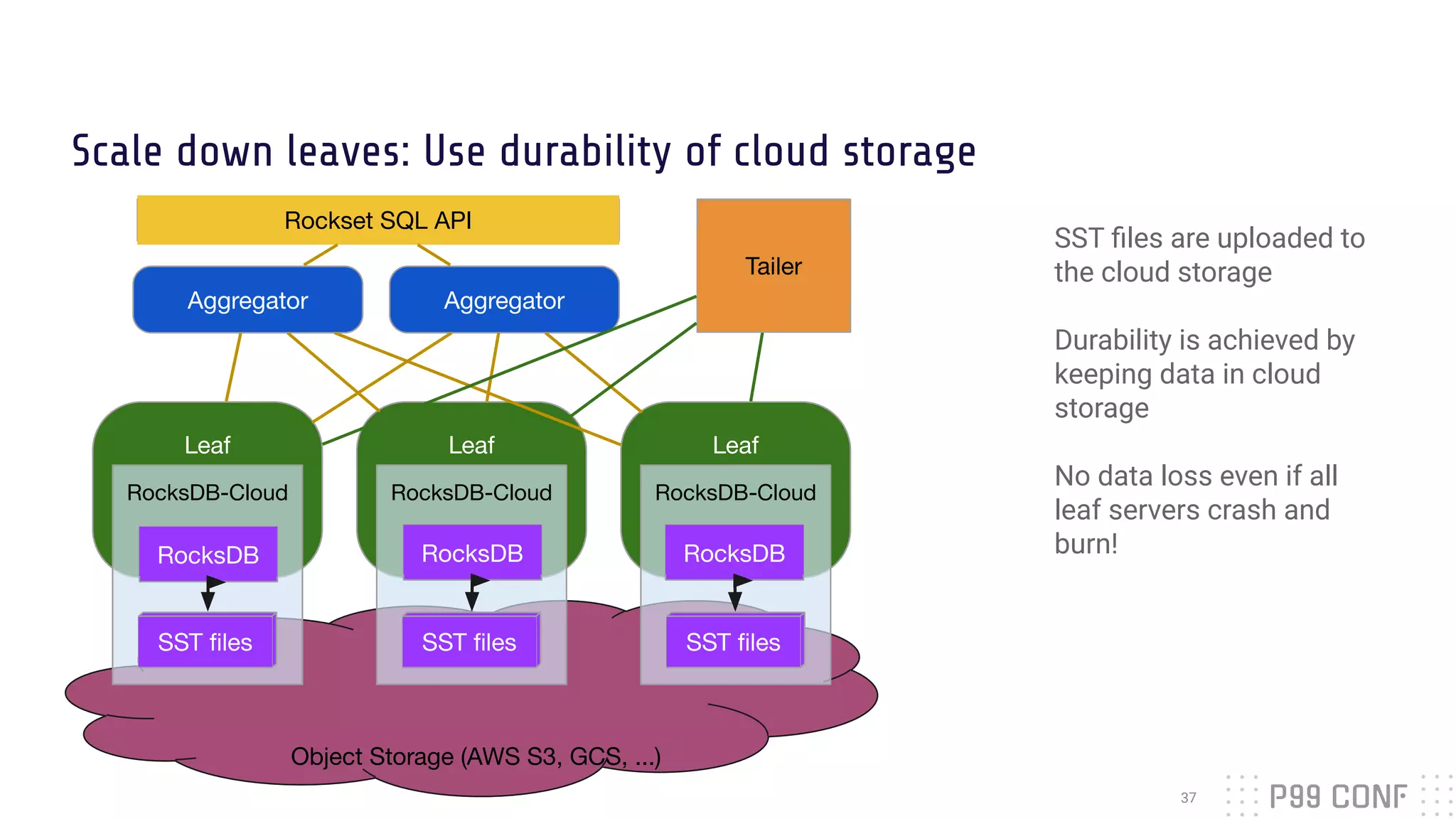
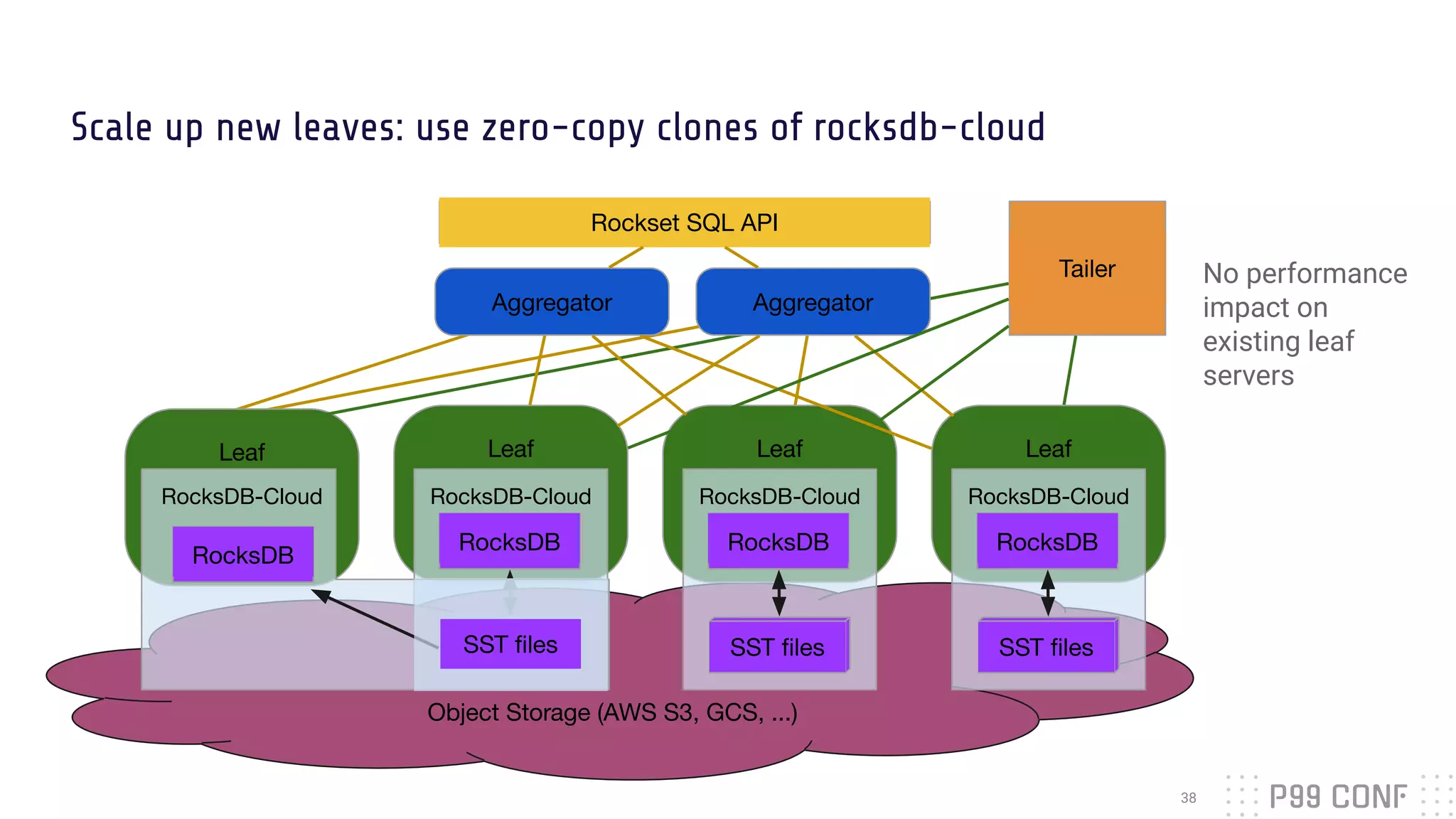





The document presents Rockset's architecture and features for real-time indexing on massive datasets, enabling the building of real-time applications without ETL processes. It highlights key benefits of the Aggregator Leaf Tailer (ALT) architecture, such as fast queries and cost-effective scaling, as well as the concepts of converged indexing and smart schemas for efficient data processing. Additionally, the document emphasizes the importance of cloud scaling to optimize resources dynamically based on current demand.




































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)


















