Downloaded 66 times


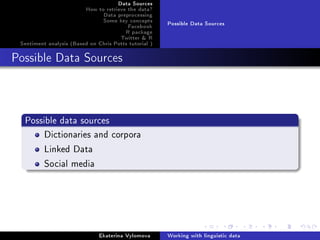




![Data Sources
How to retrieve the data?
Data preprocessing
Some key concepts
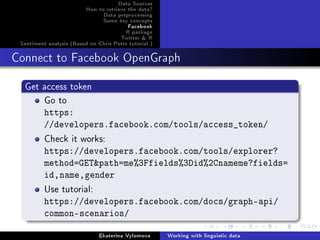
Facebook
R package
Twitter R
Sentiment analysis (Based on Chris Potts tutorial )
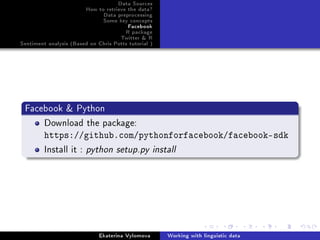
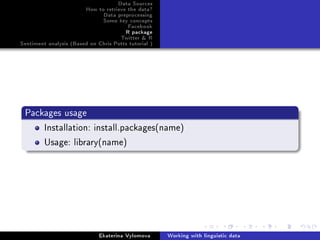
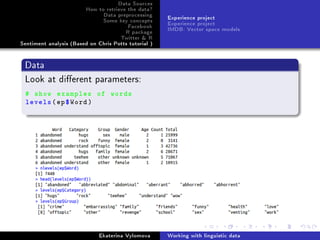
Facebook Python
Get names and gender of your friends. Possible project: prediction
of gender according to the names
import facebook
token='your_token '
graph = facebook.GraphAPI(token)
profile = graph.get_object(me)
friends = graph.get_connections(me, friends)
friend_list = [friend['id'] for friend in friends['data']]
for friend_id in friend_list:
data=graph.get_object(friend_id)
if 'gender ' in data.keys():
print data['name'], data['gender ']
Ekaterina Vylomova Working with linguistic data](https://image.slidesharecdn.com/lingsources-140418121012-phpapp01/85/Working-with-text-data-14-320.jpg)

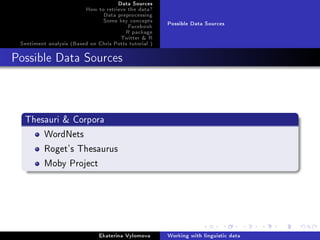
![Data Sources
How to retrieve the data?
Data preprocessing
Some key concepts
Facebook
R package
Twitter R
Sentiment analysis (Based on Chris Potts tutorial )
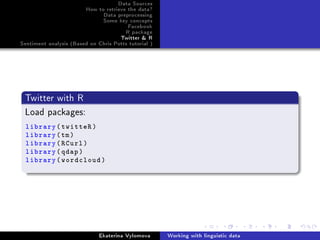
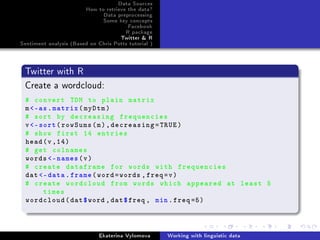
Twitter with R
Get the data and convert to corpus:
# search by hashtag , you may also search by plain words. Get
n=1000 entries
gglTweets - searchTwitter('#sochi2014 ', n=1000)
n - length(gglTweets)
# show first 3 entries
gglTweets [1:3]
# put it in a data frame
df - do.call(rbind,
lapply(gglTweets , as.data.frame))
# get dimenstionality
dim(df)
# create a corpus
myCorpus - Corpus(VectorSource(df$text))
Ekaterina Vylomova Working with linguistic data](https://image.slidesharecdn.com/lingsources-140418121012-phpapp01/85/Working-with-text-data-19-320.jpg)
![Data Sources
How to retrieve the data?
Data preprocessing
Some key concepts
Facebook
R package
Twitter R
Sentiment analysis (Based on Chris Potts tutorial )
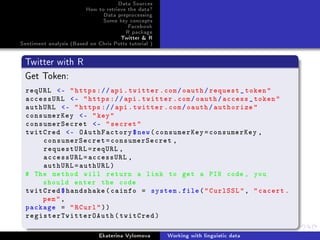
Twitter with R
Stem the documents:
dictCorpus - myCorpus
# apply stemming for normalization , you may use
lemmatization instead
myCorpus - tm_map(myCorpus , stemDocument)
inspect(myCorpus [1:3])
myCorpus - tm_map(myCorpus ,
stemCompletion , dictionary=dictCorpus)
inspect(myCorpus [1:3])
Ekaterina Vylomova Working with linguistic data](https://image.slidesharecdn.com/lingsources-140418121012-phpapp01/85/Working-with-text-data-21-320.jpg)
![Data Sources
How to retrieve the data?
Data preprocessing
Some key concepts
Facebook
R package
Twitter R
Sentiment analysis (Based on Chris Potts tutorial )
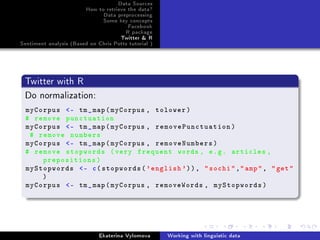
Twitter with R
Create TDM:
# create term -document matrix , you may use TF or TFIDF
metric
myDtm - TermDocumentMatrix(myCorpus , control =
list(minWordLength = 1,
weighting = weightTfIdf))
inspect(myDtm [66:70 ,11:20])
# frequent terms and associations
findFreqTerms(myDtm , lowfreq =10)
Ekaterina Vylomova Working with linguistic data](https://image.slidesharecdn.com/lingsources-140418121012-phpapp01/85/Working-with-text-data-22-320.jpg)


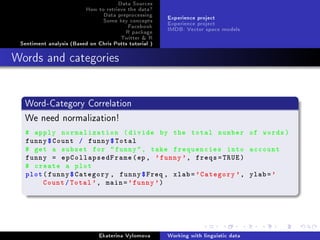
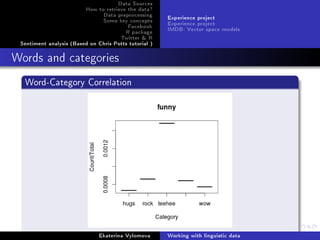


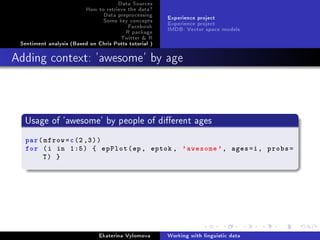

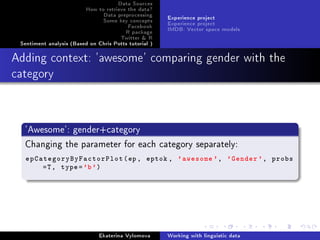
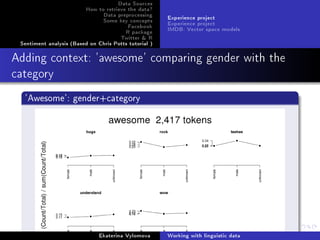

![Data Sources
How to retrieve the data?
Data preprocessing
Some key concepts
Facebook
R package
Twitter R
Sentiment analysis (Based on Chris Potts tutorial )
Experience project
Experience project
IMDB: Vector space models
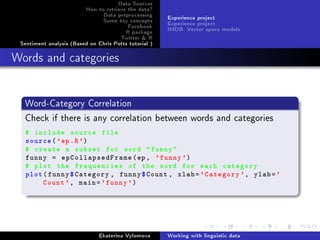
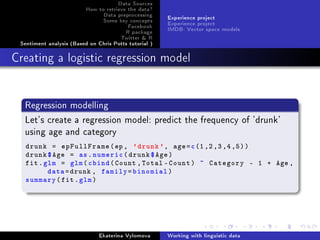
Creating a logistic regression model
Regression modelling
Find a function that predicts a word according to the category and
age of person
FittedGlmFunc = function(fit , category , age) {
coefs = fit$coef
cat.coef = coefs[[ paste('Category ',category , sep='')]]
prediction = plogis(cat.coef + coefs [['Age']]*age)
return(prediction)
}
Calling the function:
FittedGlmFunc(fit.glm , 'wow', 1)
Ekaterina Vylomova Working with linguistic data](https://image.slidesharecdn.com/lingsources-140418121012-phpapp01/85/Working-with-text-data-42-320.jpg)
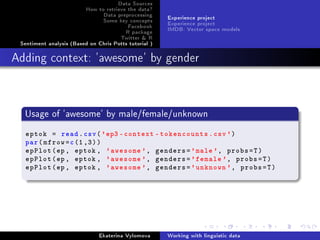
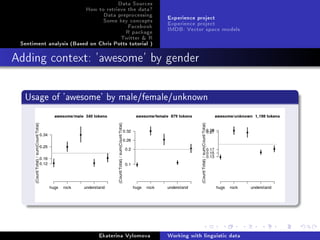
![Data Sources
How to retrieve the data?
Data preprocessing
Some key concepts
Facebook
R package
Twitter R
Sentiment analysis (Based on Chris Potts tutorial )
Experience project
Experience project
IMDB: Vector space models
Creating a logistic regression model
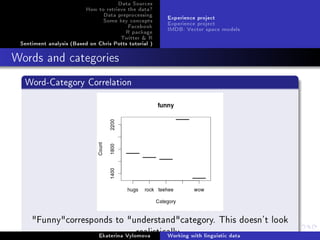
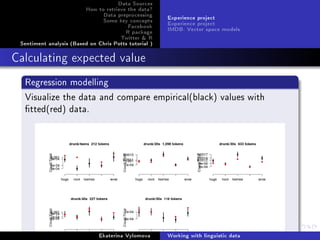
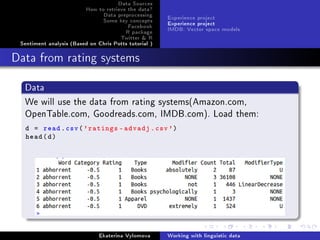
Regression modelling
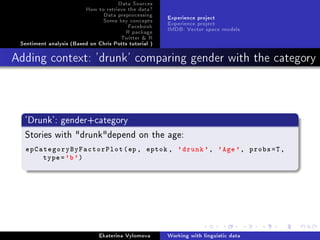
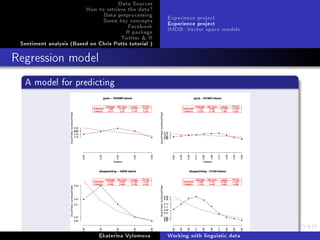
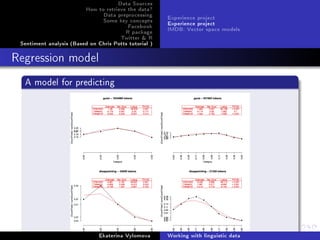
Visualize the data and compare empirical(black) values with
tted(red) data.
par(mfrow=c(2,3))
cats = levels(ep$Category)
for(i in 1:5) {
epPlot(ep , eptok , 'drunk', age=i)
for (j in 1:5) {
val = FittedGlmFunc(fit.glm , cats[j], i)
points(j, val , col='red', pch =19)
}
}
Ekaterina Vylomova Working with linguistic data](https://image.slidesharecdn.com/lingsources-140418121012-phpapp01/85/Working-with-text-data-43-320.jpg)

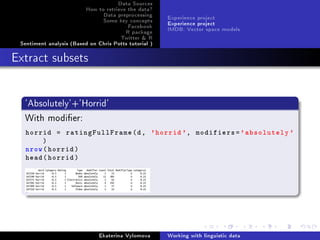
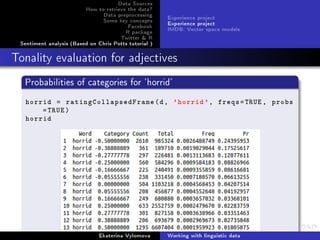

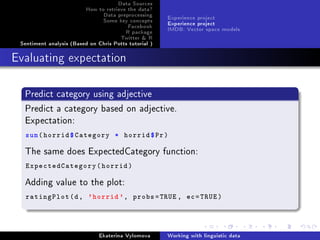
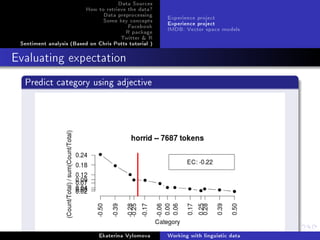

![Data Sources
How to retrieve the data?
Data preprocessing
Some key concepts
Facebook
R package
Twitter R
Sentiment analysis (Based on Chris Potts tutorial )
Experience project
Experience project
IMDB: Vector space models
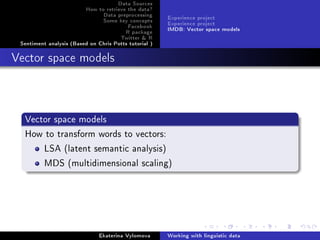
Vector space models
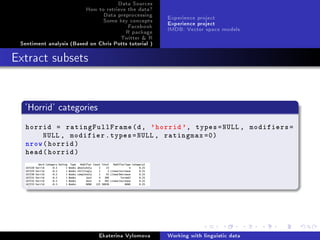
Data from IMDB
Initail data: term x term matrix, xij element of matrix is a
frequency of cooccurrence of termi and termj in context(document,
sentences, etc.)
source('vsm.R')
# co-occurrence matrix(words appearing in the same context(
phrase , sentence , paragraph))
imdb = Csv2Matrix('imdb -wordword.csv')
imdb [100:110 , 100:110]
Ekaterina Vylomova Working with linguistic data](https://image.slidesharecdn.com/lingsources-140418121012-phpapp01/85/Working-with-text-data-59-320.jpg)
![Data Sources
How to retrieve the data?
Data preprocessing
Some key concepts
Facebook
R package
Twitter R
Sentiment analysis (Based on Chris Potts tutorial )
Experience project
Experience project
IMDB: Vector space models
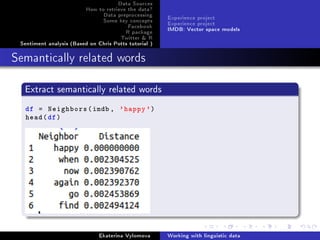
Semantically related words
Problem
a = c(1000 , 2000, 3000)
b = c(1, 2, 3)
a/sum(a)
# 0.1666667 0.3333333 0.5000000
b/sum(b)
# 0.1666667 0.3333333 0.5000000
LengthNorm(a)
# 0.2672612 0.5345225 0.8017837
LengthNorm(b)
[1] 0.2672612 0.5345225 0.801783
Ekaterina Vylomova Working with linguistic data](https://image.slidesharecdn.com/lingsources-140418121012-phpapp01/85/Working-with-text-data-61-320.jpg)



The document discusses various data sources for linguistic analysis, including corpora, dictionaries, social media, and linked open data. It provides details on accessing data from Facebook and Twitter using APIs and R packages. It also covers preprocessing text data through tokenization, lemmatization, stemming and creating term-document matrices. Sentiment analysis on data from sources like Experience Project is demonstrated through exploring word-category correlations.
















![Introduction to R for Data Science :: Session 5 [Data Structuring: Strings in R]](https://cdn.slidesharecdn.com/ss_thumbnails/intrordatasciencesession5eng-160529191417-thumbnail.jpg?width=640&height=640&fit=bounds)























































































