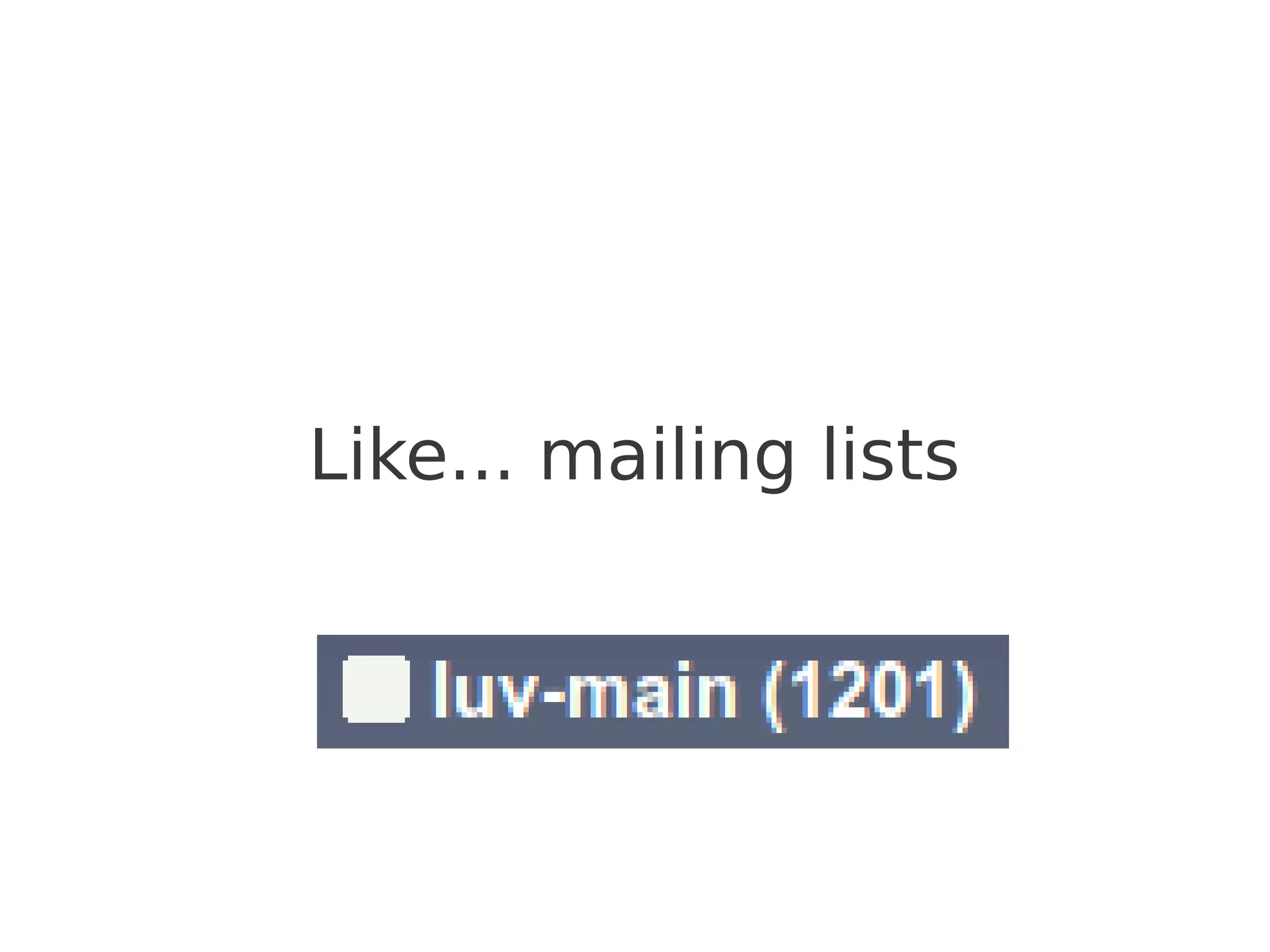
Downloaded 19 times
![Language Sleuthing HOWTO
or
Discovering Interesting Things
with Python's
Natural Language Tool Kit
Brianna Laugher
modernthings.org
brianna[@.]laugher.id.au](https://image.slidesharecdn.com/talk-slides-redacted-100804085209-phpapp01/75/Language-Sleuthing-HOWTO-with-NLTK-1-2048.jpg)

















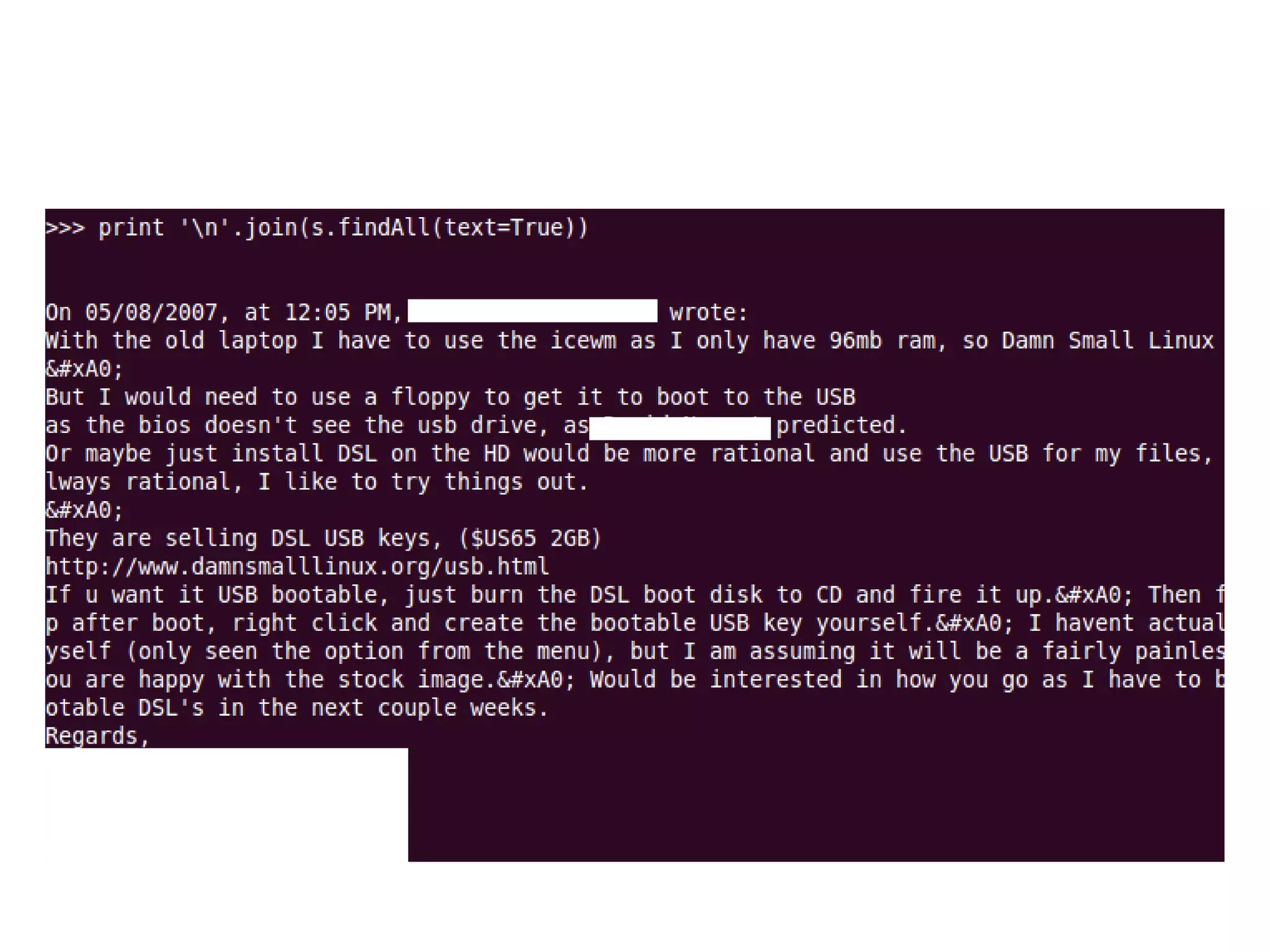

![What about blockquotes?
>>> bqs = s.findAll('blockquote')
>>> [bq.extract() for bq in bqs]
>>> print 'n'.join(s.findAll(text=True))
On 05/08/2007, at 12:05 PM, [...] wrote:
If u want it USB bootable, just burn the DSL boot disk to CD and fire it
up.  Then from the desktop after boot, right click and create the
bootable USB key yourself.  I havent actually done this myself (only
seen the option from the menu), but I am assuming it will be a fairly painless
process if you are happy with the stock image.  Would be interested in
how you go as I have to build 50 USB bootable DSL's in the next couple weeks.
Regards,
[...]](https://image.slidesharecdn.com/talk-slides-redacted-100804085209-phpapp01/75/Language-Sleuthing-HOWTO-with-NLTK-27-2048.jpg)


![What about our metadata?
Create a Python dictionary that maps filenames to
categories
e.g.
categories={}
categories['2008-12/msg00226.html'] =
['year-2008',
'month-12',
'author-BM<bm@xxxxx>'
]
....etc
then...
import nltk
path = 'path/to/files/'
corpus =
nltk.corpus.CategorizedPlaintextCorpusReader(path,
'.*.html', cat_map=categories)](https://image.slidesharecdn.com/talk-slides-redacted-100804085209-phpapp01/75/Language-Sleuthing-HOWTO-with-NLTK-30-2048.jpg)
![Simple categories
cats = corpus.categories()
authorcats=[c for c in cats if c.startswith('author')]
#>>> len(authorcats)
#608
yearcats=[c for c in cats if c.startswith('year')]
monthcats=[c for c in cats if c.startswith('month')]](https://image.slidesharecdn.com/talk-slides-redacted-100804085209-phpapp01/75/Language-Sleuthing-HOWTO-with-NLTK-31-2048.jpg)
![...who are the top posters?
posts = [(len(corpus.fileids(author)), author) for author in
authorcats]
posts.sort(reverse=True)
for count, author in posts[:10]:
print "%5dt%s" % (count, author)
→
1304 author-JW
1294 author-RC
1243 author-CS
1030 author-JH
868 author-DP
752 author-TWB
608 author-CS#2
556 author-TL
452 author-BM
412 author-RM
(email me if you're curious to know if you're on it...)](https://image.slidesharecdn.com/talk-slides-redacted-100804085209-phpapp01/75/Language-Sleuthing-HOWTO-with-NLTK-32-2048.jpg)
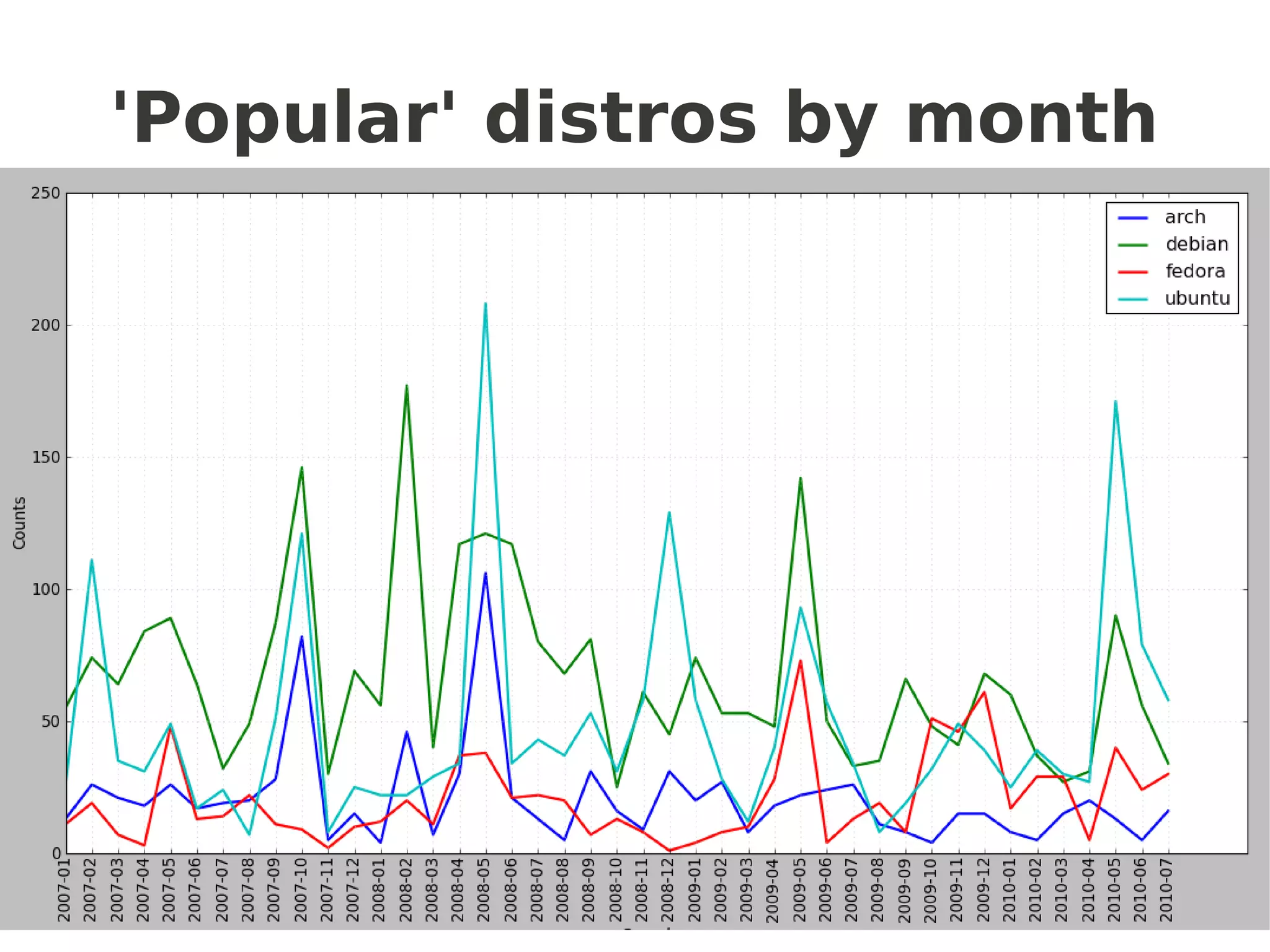
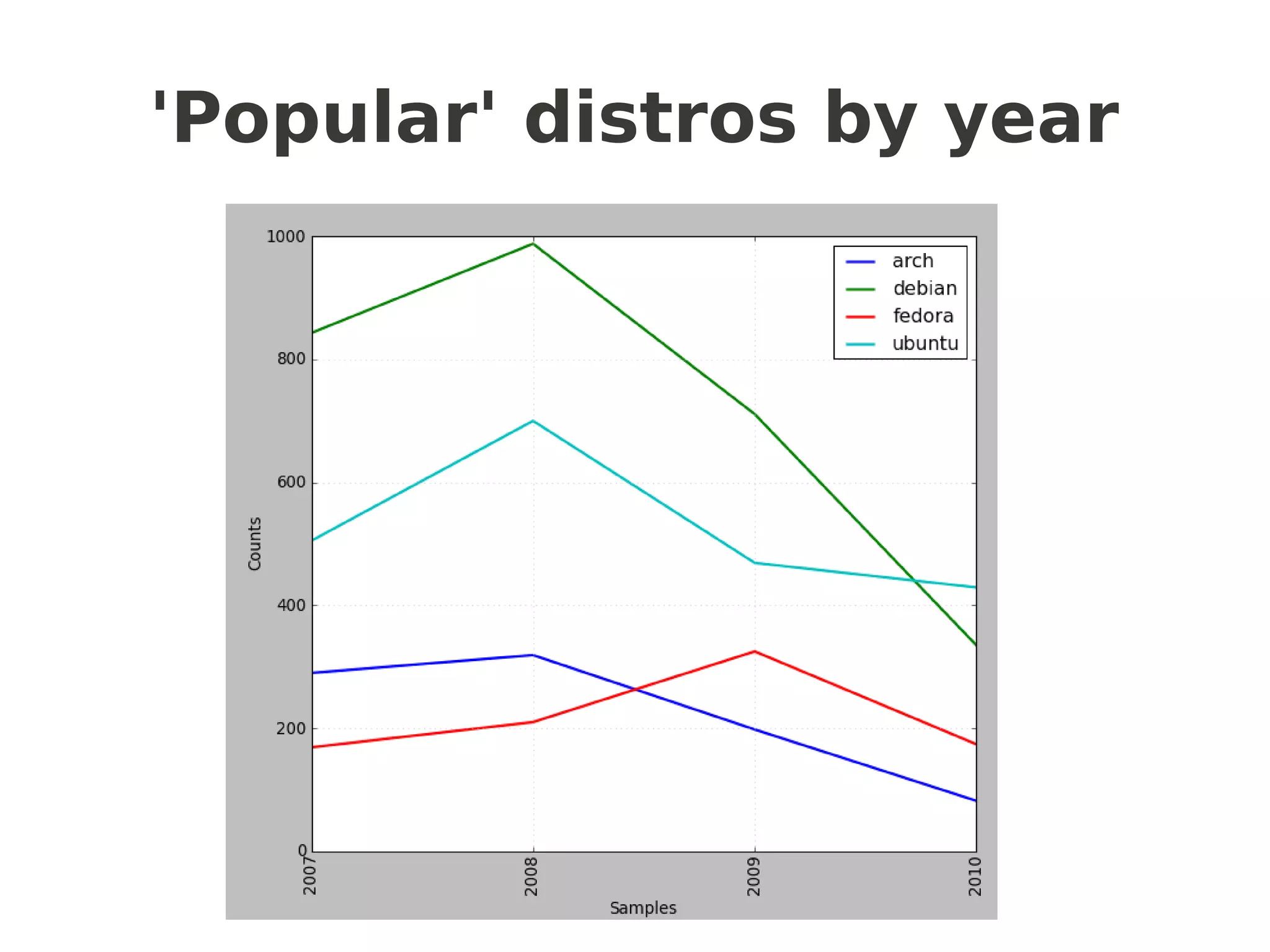
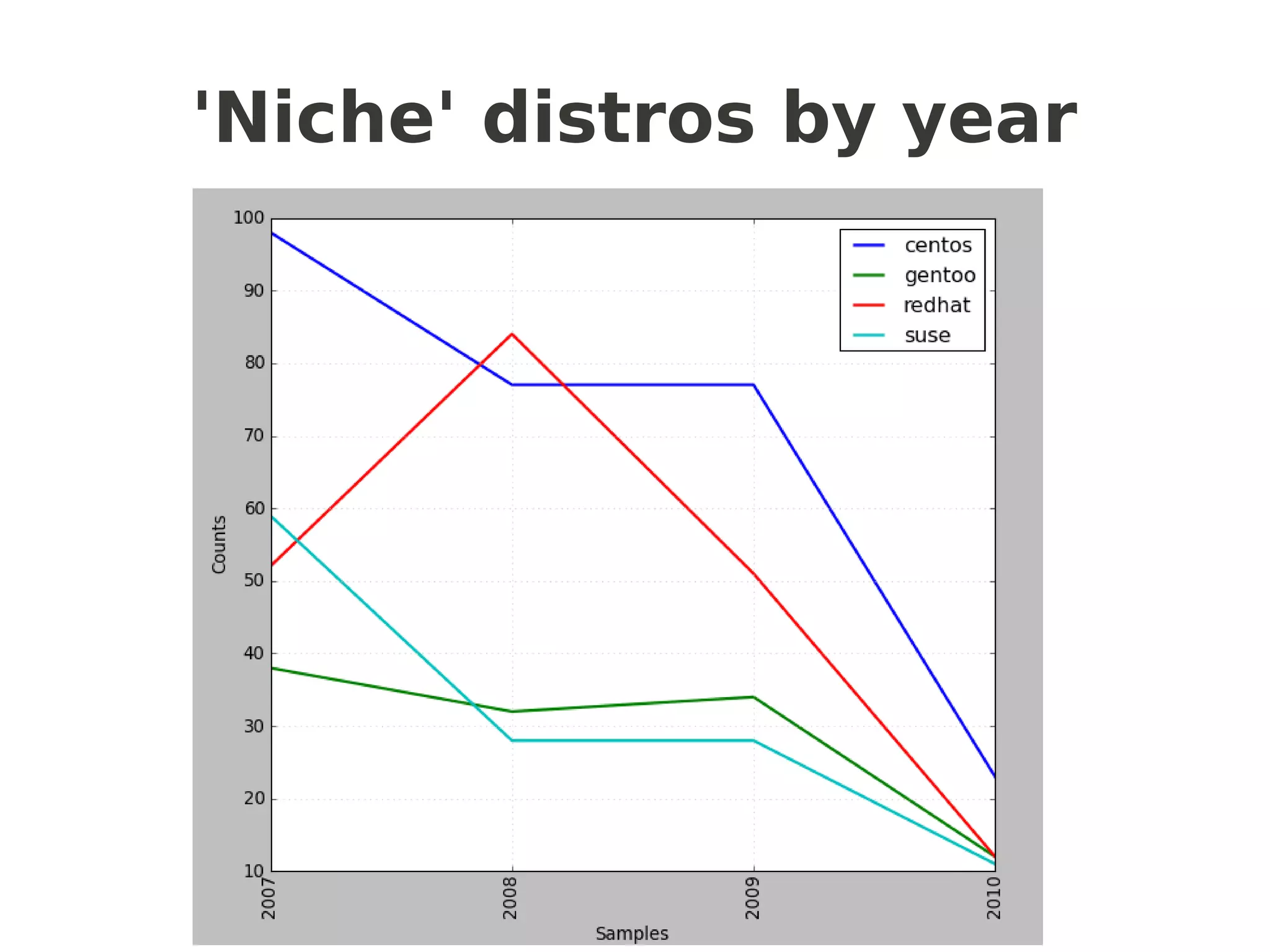
![Frequency distributions
popular =['ubuntu','debian','fedora','arch']
niche = ['gentoo','suse','centos','redhat']
def getcfd(distros,limit):
cfd = nltk.ConditionalFreqDist(
(distro, fileid[:limit])
for fileid in corpus.fileids()
for w in corpus.words(fileid)
for distro in distros
if w.lower().startswith(distro))
return cfd
popularcfd = getcfd(popular,4) # or 7 for months
popularcfd.plot()
nichecfd = getcfd(niche,4)
nichecfd.plot()
another “NLTKism”](https://image.slidesharecdn.com/talk-slides-redacted-100804085209-phpapp01/75/Language-Sleuthing-HOWTO-with-NLTK-33-2048.jpg)
![Random text generation
import random
words = [w.lower() for w in corpus.words()]
bigrams = nltk.bigrams(words)
cfd = nltk.ConditionalFreqDist(bigrams)
def generate_model(cfdist, word, num=15):
for i in range(num):
print word,
words = list(cfdist[word])
word = random.choice(words)
text = [w.lower() for w in corpus.words()]
bigrams = nltk.bigrams(text)
cfd = nltk.ConditionalFreqDist(bigrams)
generate_model(cfd, 'hi', num=20)](https://image.slidesharecdn.com/talk-slides-redacted-100804085209-phpapp01/75/Language-Sleuthing-HOWTO-with-NLTK-37-2048.jpg)

![hi from Peter...
text = [w.lower() for w in corpus.words(categories=
[c for c in authorcats if 'PeterL' in c])]
hi everyone , hence the database schema and that run on memberdb on mail
store is 12 . yep ,
hi anita , your favourite piece of cpu cycles , he was thinking i hear the middle
of failure .
hi anita , same vhost b internal ip / nine seem odd occasion i hazard . 25ghz
g4 ibook here
hi everyone , same ) on removes a "-- nicelevel nn " as intended . 00 . main
host basis
hi cameron , no biggie . candidates in to upgrade . ubuntu dom0 install if there
! now ). txt
hi cameron , attribution for 30 seconds , and runs out on linux to on www .
luv , these](https://image.slidesharecdn.com/talk-slides-redacted-100804085209-phpapp01/75/Language-Sleuthing-HOWTO-with-NLTK-39-2048.jpg)
![interesting collocations
...or not
ext = [w.lower() for w in corpus.words() if w.isalpha()]
from nltk.collocations import *
bigram_measures = nltk.collocations.BigramAssocMeasures()
finder = BigramCollocationFinder.from_words(text)
finder.apply_freq_filter(3)
finder.nbest(bigram_measures.pmi, 10)
→
bufnewfile bufread
busmaster speccycle
cellx celly
cheswick bellovin
cread clocal
curtail atl
dmcrs rscem
dmmrbc dmost
dmost dmcrs
...](https://image.slidesharecdn.com/talk-slides-redacted-100804085209-phpapp01/75/Language-Sleuthing-HOWTO-with-NLTK-40-2048.jpg)
![oblig tag cloud
stopwords =
nltk.corpus.stopwords.words('english')
words = [w.lower() for w in corpus.words()
if w.isalpha()]
words = [w for w in words if w not in stopwords]
word_fd = nltk.FreqDist(words)
wordmax = word_fd[word_fd.max()]
wordmin = 1000 #YMMV
taglist = word_fd.items()
ranges = getRanges(wordmin, wordmax)
writeCloud(taglist, ranges, 'tags.html')](https://image.slidesharecdn.com/talk-slides-redacted-100804085209-phpapp01/75/Language-Sleuthing-HOWTO-with-NLTK-41-2048.jpg)

![another one for Peter :)
cats = [c for c in corpus.categories()
if 'PeterL' in c]
words=[w.lower() for w in corpus.words(categories=cats)
if w.isalpha()]
wordmin = 10
→](https://image.slidesharecdn.com/talk-slides-redacted-100804085209-phpapp01/75/Language-Sleuthing-HOWTO-with-NLTK-43-2048.jpg)


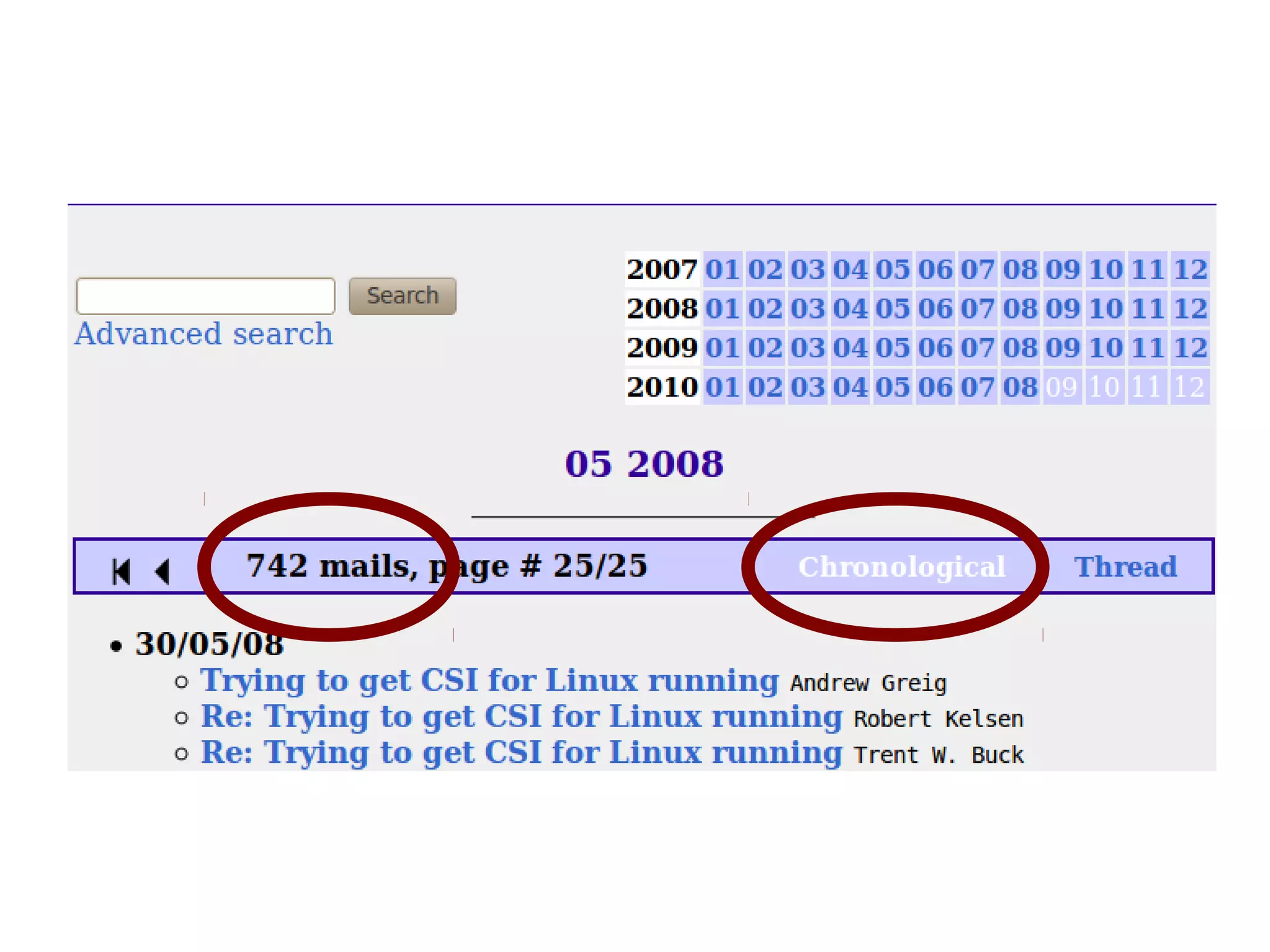
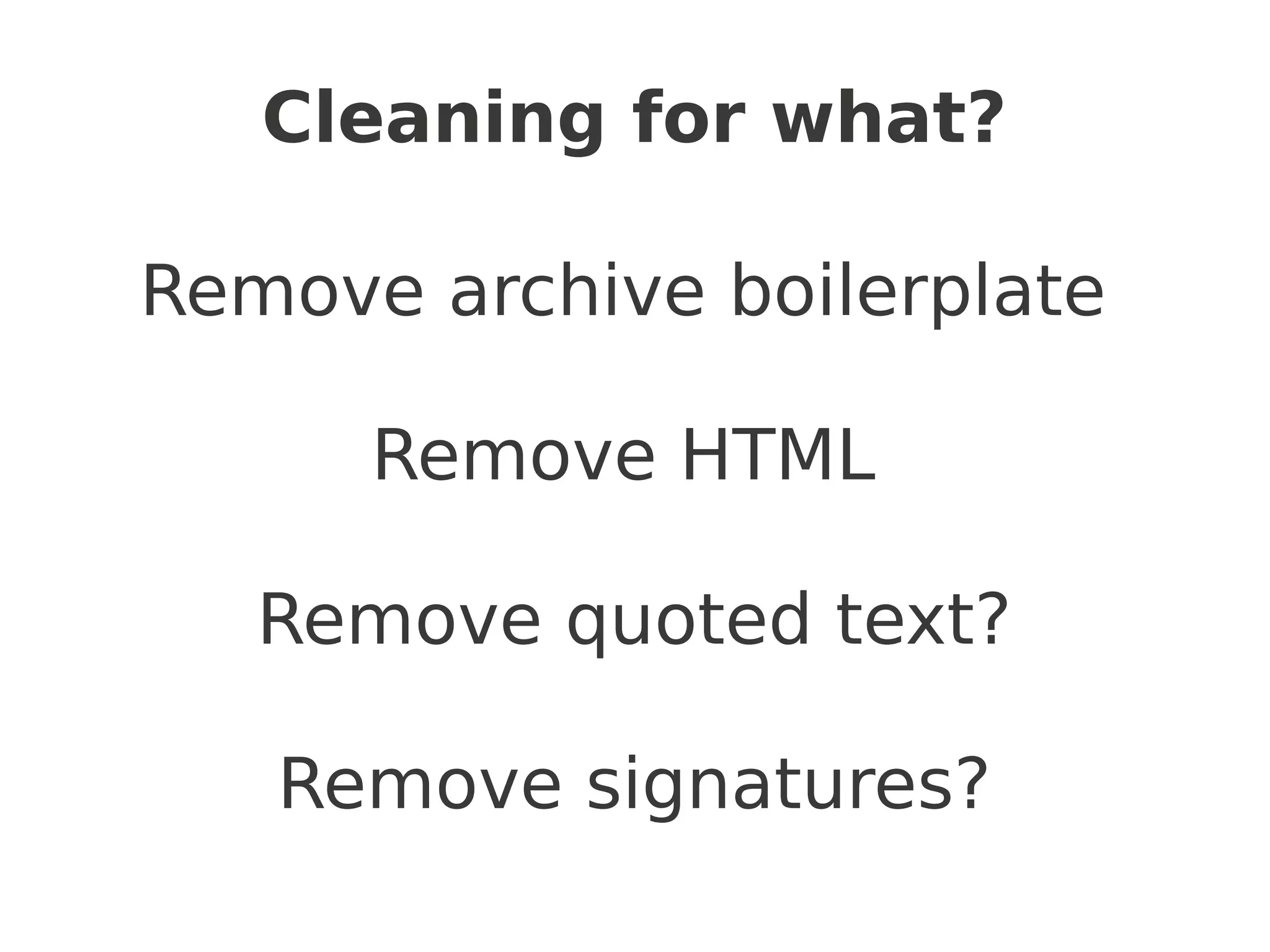
The document provides a guide on utilizing Python's Natural Language Toolkit (NLTK) for corpus linguistics by discussing steps to acquire, clean, and analyze data from web texts. It outlines methods for data gathering using wget and Python scripts, data cleaning, and basic data analysis with frequency distributions for identifying popular topics and authors in email lists. Additionally, it mentions generating random text and visualizing word frequencies, supporting the notion that the web is a rich source of language data.
































































![Wiki[mp]edia data sources & the MediaWiki API](https://cdn.slidesharecdn.com/ss_thumbnails/wikimediadatasources-091106193911-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)











![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)




![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)












![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)