Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
NVIDIA Japan
3,037 views
エヌビディアのディープラーニング戦略 TESLA P100 & NVIDIA DGX-1
2016年7月22日(金)名古屋にて開催の、NVIDIA のイベント Deep Learning Day #NVDLD 2016 Summer の資料です。
Technology
◦
Related topics:
Deep Learning
•
Deep Neural Network
•
Read more
2
Save
Share
Embed
Embed presentation
Download
Downloaded 83 times
1
/ 21
2
/ 21
3
/ 21
4
/ 21
5
/ 21
6
/ 21
7
/ 21
8
/ 21
9
/ 21
10
/ 21
11
/ 21
12
/ 21
13
/ 21
14
/ 21
15
/ 21
16
/ 21
17
/ 21
18
/ 21
19
/ 21
20
/ 21
21
/ 21
More Related Content
PDF
DIGITS による物体検出入門
by
NVIDIA Japan
PDF
GTC 2016 基調講演からディープラーニング関連情報のご紹介
by
NVIDIA Japan
PDF
DIGITSによるディープラーニング画像分類
by
NVIDIA Japan
PDF
20161122 gpu deep_learningcommunity#02
by
ManaMurakami1
PDF
エヌビディアが加速するディープラーニング~進化するニューラルネットワークとその開発方法について~
by
NVIDIA Japan
PPTX
人工知能 AI 時代の幕開け~新たなコンピューティング モデル、GPU ディープラーニングが火付け役に~
by
NVIDIA Japan
PDF
GTC 2017 ディープラーニング最新情報
by
NVIDIA Japan
PDF
ハンズオン セッション 3: リカレント ニューラル ネットワーク入門
by
NVIDIA Japan
DIGITS による物体検出入門
by
NVIDIA Japan
GTC 2016 基調講演からディープラーニング関連情報のご紹介
by
NVIDIA Japan
DIGITSによるディープラーニング画像分類
by
NVIDIA Japan
20161122 gpu deep_learningcommunity#02
by
ManaMurakami1
エヌビディアが加速するディープラーニング~進化するニューラルネットワークとその開発方法について~
by
NVIDIA Japan
人工知能 AI 時代の幕開け~新たなコンピューティング モデル、GPU ディープラーニングが火付け役に~
by
NVIDIA Japan
GTC 2017 ディープラーニング最新情報
by
NVIDIA Japan
ハンズオン セッション 3: リカレント ニューラル ネットワーク入門
by
NVIDIA Japan
What's hot
PDF
エヌビディアのディープラーニング戦略
by
NVIDIA Japan
PDF
GTC 2016 ディープラーニング最新情報
by
NVIDIA Japan
PDF
ハンズオン1: DIGITS によるディープラーニング入門
by
NVIDIA Japan
PDF
JETSON 最新情報 & 自動外観検査事例紹介
by
NVIDIA Japan
PDF
GPU と PYTHON と、それから最近の NVIDIA
by
NVIDIA Japan
PDF
これから始める人の為のディープラーニング基礎講座
by
NVIDIA Japan
PDF
エヌビディア GPU が加速するディープラーニング
by
NVIDIA Japan
PDF
HELLO AI WORLD - MEET JETSON NANO
by
NVIDIA Japan
PDF
ハードウェア進化についていけ 〜 実用化が進む GPU、そして注目が集まる Edge TPU の威力に迫る 〜
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
2020年10月29日 Jetson活用によるAI教育
by
NVIDIA Japan
PDF
1010: エヌビディア GPU が加速するディープラーニング
by
NVIDIA Japan
PDF
Android/iOS端末におけるエッジ推論のチューニング
by
Deep Learning Lab(ディープラーニング・ラボ)
PPTX
DLLAB Engineer Days:AIチームが履歴やリソース管理で疲弊してたので開発基盤作ってOSS化した話
by
Kamonohashi
PDF
20200326 jetson edge comuputing digital seminar 1 final
by
NVIDIA Japan
PDF
マイクロソフトが考えるAI活用のロードマップ
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
第 1 回 Jetson ユーザー勉強会
by
NVIDIA Japan
PDF
COVID-19 研究・対策に活用可能な NVIDIA ソフトウェアと関連情報
by
NVIDIA Japan
PDF
テレコムのビッグデータ解析 & AI サイバーセキュリティ
by
NVIDIA Japan
PDF
2020年10月29日 Jetson Nano 2GBで始めるAI x Robotics教育
by
NVIDIA Japan
PDF
ディープラーニングの社会実装の鍵となるエッジコンピューティング
by
Deep Learning Lab(ディープラーニング・ラボ)
エヌビディアのディープラーニング戦略
by
NVIDIA Japan
GTC 2016 ディープラーニング最新情報
by
NVIDIA Japan
ハンズオン1: DIGITS によるディープラーニング入門
by
NVIDIA Japan
JETSON 最新情報 & 自動外観検査事例紹介
by
NVIDIA Japan
GPU と PYTHON と、それから最近の NVIDIA
by
NVIDIA Japan
これから始める人の為のディープラーニング基礎講座
by
NVIDIA Japan
エヌビディア GPU が加速するディープラーニング
by
NVIDIA Japan
HELLO AI WORLD - MEET JETSON NANO
by
NVIDIA Japan
ハードウェア進化についていけ 〜 実用化が進む GPU、そして注目が集まる Edge TPU の威力に迫る 〜
by
Deep Learning Lab(ディープラーニング・ラボ)
2020年10月29日 Jetson活用によるAI教育
by
NVIDIA Japan
1010: エヌビディア GPU が加速するディープラーニング
by
NVIDIA Japan
Android/iOS端末におけるエッジ推論のチューニング
by
Deep Learning Lab(ディープラーニング・ラボ)
DLLAB Engineer Days:AIチームが履歴やリソース管理で疲弊してたので開発基盤作ってOSS化した話
by
Kamonohashi
20200326 jetson edge comuputing digital seminar 1 final
by
NVIDIA Japan
マイクロソフトが考えるAI活用のロードマップ
by
Deep Learning Lab(ディープラーニング・ラボ)
第 1 回 Jetson ユーザー勉強会
by
NVIDIA Japan
COVID-19 研究・対策に活用可能な NVIDIA ソフトウェアと関連情報
by
NVIDIA Japan
テレコムのビッグデータ解析 & AI サイバーセキュリティ
by
NVIDIA Japan
2020年10月29日 Jetson Nano 2GBで始めるAI x Robotics教育
by
NVIDIA Japan
ディープラーニングの社会実装の鍵となるエッジコンピューティング
by
Deep Learning Lab(ディープラーニング・ラボ)
Viewers also liked
PDF
LT@Chainer Meetup
by
Shunta Saito
PDF
Chainer meetup20151014
by
Jiro Nishitoba
PPTX
Chainer Meetup LT (Alpaca)
by
Jun-ya Norimatsu
PDF
A Chainer MeetUp Talk
by
Yusuke Oda
PDF
Towards Chainer v1.5
by
Seiya Tokui
PPTX
Chainer meetup
by
kikusu
PDF
NVIDIA 更新情報: Tesla P100 PCIe/cuDNN 5.1
by
NVIDIA Japan
PDF
Chainer Update v1.8.0 -> v1.10.0+
by
Seiya Tokui
PPTX
Chainerを使って細胞を数えてみた
by
samacoba1983
PDF
On the benchmark of Chainer
by
Kenta Oono
PDF
深層学習ライブラリの環境問題Chainer Meetup2016 07-02
by
Yuta Kashino
PDF
俺のtensorが全然flowしないのでみんなchainer使おう by DEEPstation
by
Yusuke HIDESHIMA
PDF
ヤフー音声認識サービスでのディープラーニングとGPU利用事例
by
Yahoo!デベロッパーネットワーク
PDF
Chainer Development Plan 2015/12
by
Seiya Tokui
PDF
深層学習ライブラリのプログラミングモデル
by
Yuta Kashino
PPTX
Capitalicoでのchainer 1.1 → 1.5 バージョンアップ事例
by
Jun-ya Norimatsu
PDF
Chainer, Cupy入門
by
Yuya Unno
PDF
マシンパーセプション研究におけるChainer活用事例
by
nlab_utokyo
PDF
ボケるRNNを学習したい (Chainer meetup 01)
by
Motoki Sato
PDF
Chainer Contribution Guide
by
Kenta Oono
LT@Chainer Meetup
by
Shunta Saito
Chainer meetup20151014
by
Jiro Nishitoba
Chainer Meetup LT (Alpaca)
by
Jun-ya Norimatsu
A Chainer MeetUp Talk
by
Yusuke Oda
Towards Chainer v1.5
by
Seiya Tokui
Chainer meetup
by
kikusu
NVIDIA 更新情報: Tesla P100 PCIe/cuDNN 5.1
by
NVIDIA Japan
Chainer Update v1.8.0 -> v1.10.0+
by
Seiya Tokui
Chainerを使って細胞を数えてみた
by
samacoba1983
On the benchmark of Chainer
by
Kenta Oono
深層学習ライブラリの環境問題Chainer Meetup2016 07-02
by
Yuta Kashino
俺のtensorが全然flowしないのでみんなchainer使おう by DEEPstation
by
Yusuke HIDESHIMA
ヤフー音声認識サービスでのディープラーニングとGPU利用事例
by
Yahoo!デベロッパーネットワーク
Chainer Development Plan 2015/12
by
Seiya Tokui
深層学習ライブラリのプログラミングモデル
by
Yuta Kashino
Capitalicoでのchainer 1.1 → 1.5 バージョンアップ事例
by
Jun-ya Norimatsu
Chainer, Cupy入門
by
Yuya Unno
マシンパーセプション研究におけるChainer活用事例
by
nlab_utokyo
ボケるRNNを学習したい (Chainer meetup 01)
by
Motoki Sato
Chainer Contribution Guide
by
Kenta Oono
Similar to エヌビディアのディープラーニング戦略 TESLA P100 & NVIDIA DGX-1
PDF
NVIDIA deep learning最新情報in沖縄
by
Tak Izaki
PDF
IEEE ITSS Nagoya Chapter NVIDIA
by
Tak Izaki
PDF
20170518 eureka dli
by
ManaMurakami1
PDF
20161210 jawsai
by
ManaMurakami1
PDF
MII conference177 nvidia
by
Tak Izaki
PDF
GTC 2017 オートモーティブ最新情報
by
NVIDIA Japan
PPTX
NVIDIA 最近の動向
by
NVIDIA Japan
PDF
NVIDIA ディープラーニング最新情報
by
Hirono Jumpei
PDF
NVIDIA GPU 技術最新情報
by
IDC Frontier
PDF
NGC でインフラ環境整備の時間短縮!素早く始めるディープラーニング
by
NVIDIA Japan
PDF
GTC 2017 基調講演からディープラーニング関連情報のご紹介
by
NVIDIA Japan
PDF
2016nov22 gdlc02 nvidia
by
Tomokazu Kanazawa
PDF
NVIDIA ディープラーニング入門
by
Seong-Hun Choe
PDF
ディープラーニングをいつやるか?~今でしょ!
by
Tak Izaki
PDF
GPUディープラーニング最新情報
by
ReNom User Group
PPTX
ディープラーニング 今週の事例 Top 5
by
NVIDIA Japan
PPTX
不足するAI人材に対する「パソナテックの人材育成ソリューション」
by
Natsutani Minoru
PDF
GTC 2018 の基調講演から
by
NVIDIA Japan
PPTX
Deep Learning Abstract
by
Ryousuke Wayama
PDF
Dat002 ディープラーニン
by
Tech Summit 2016
NVIDIA deep learning最新情報in沖縄
by
Tak Izaki
IEEE ITSS Nagoya Chapter NVIDIA
by
Tak Izaki
20170518 eureka dli
by
ManaMurakami1
20161210 jawsai
by
ManaMurakami1
MII conference177 nvidia
by
Tak Izaki
GTC 2017 オートモーティブ最新情報
by
NVIDIA Japan
NVIDIA 最近の動向
by
NVIDIA Japan
NVIDIA ディープラーニング最新情報
by
Hirono Jumpei
NVIDIA GPU 技術最新情報
by
IDC Frontier
NGC でインフラ環境整備の時間短縮!素早く始めるディープラーニング
by
NVIDIA Japan
GTC 2017 基調講演からディープラーニング関連情報のご紹介
by
NVIDIA Japan
2016nov22 gdlc02 nvidia
by
Tomokazu Kanazawa
NVIDIA ディープラーニング入門
by
Seong-Hun Choe
ディープラーニングをいつやるか?~今でしょ!
by
Tak Izaki
GPUディープラーニング最新情報
by
ReNom User Group
ディープラーニング 今週の事例 Top 5
by
NVIDIA Japan
不足するAI人材に対する「パソナテックの人材育成ソリューション」
by
Natsutani Minoru
GTC 2018 の基調講演から
by
NVIDIA Japan
Deep Learning Abstract
by
Ryousuke Wayama
Dat002 ディープラーニン
by
Tech Summit 2016
More from NVIDIA Japan
PDF
HPC 的に H100 は魅力的な GPU なのか?
by
NVIDIA Japan
PDF
NVIDIA cuQuantum SDK による量子回路シミュレーターの高速化
by
NVIDIA Japan
PDF
Physics-ML のためのフレームワーク NVIDIA Modulus 最新事情
by
NVIDIA Japan
PDF
20221021_JP5.0.2-Webinar-JP_Final.pdf
by
NVIDIA Japan
PDF
開発者が語る NVIDIA cuQuantum SDK
by
NVIDIA Japan
PDF
NVIDIA Modulus: Physics ML 開発のためのフレームワーク
by
NVIDIA Japan
PDF
NVIDIA HPC ソフトウエア斜め読み
by
NVIDIA Japan
PDF
HPC+AI ってよく聞くけど結局なんなの
by
NVIDIA Japan
PDF
Magnum IO GPUDirect Storage 最新情報
by
NVIDIA Japan
PDF
データ爆発時代のネットワークインフラ
by
NVIDIA Japan
PDF
Hopper アーキテクチャで、変わること、変わらないこと
by
NVIDIA Japan
PDF
GTC November 2021 – テレコム関連アップデート サマリー
by
NVIDIA Japan
PDF
必見!絶対におすすめの通信業界セッション 5 つ ~秋の GTC 2020~
by
NVIDIA Japan
PDF
2020年10月29日 プロフェッショナルAI×Roboticsエンジニアへのロードマップ
by
NVIDIA Japan
PDF
Jetson Xavier NX クラウドネイティブをエッジに
by
NVIDIA Japan
PDF
GTC 2020 発表内容まとめ
by
NVIDIA Japan
PDF
NVIDIA Jetson導入事例ご紹介
by
NVIDIA Japan
PDF
Final 20200326 jetson edge comuputing digital seminar 1 final (1)
by
NVIDIA Japan
PDF
20200326 jetson edge comuputing digital seminar 1 final
by
NVIDIA Japan
PDF
20200326 jetson edge comuputing digital seminar 2
by
NVIDIA Japan
HPC 的に H100 は魅力的な GPU なのか?
by
NVIDIA Japan
NVIDIA cuQuantum SDK による量子回路シミュレーターの高速化
by
NVIDIA Japan
Physics-ML のためのフレームワーク NVIDIA Modulus 最新事情
by
NVIDIA Japan
20221021_JP5.0.2-Webinar-JP_Final.pdf
by
NVIDIA Japan
開発者が語る NVIDIA cuQuantum SDK
by
NVIDIA Japan
NVIDIA Modulus: Physics ML 開発のためのフレームワーク
by
NVIDIA Japan
NVIDIA HPC ソフトウエア斜め読み
by
NVIDIA Japan
HPC+AI ってよく聞くけど結局なんなの
by
NVIDIA Japan
Magnum IO GPUDirect Storage 最新情報
by
NVIDIA Japan
データ爆発時代のネットワークインフラ
by
NVIDIA Japan
Hopper アーキテクチャで、変わること、変わらないこと
by
NVIDIA Japan
GTC November 2021 – テレコム関連アップデート サマリー
by
NVIDIA Japan
必見!絶対におすすめの通信業界セッション 5 つ ~秋の GTC 2020~
by
NVIDIA Japan
2020年10月29日 プロフェッショナルAI×Roboticsエンジニアへのロードマップ
by
NVIDIA Japan
Jetson Xavier NX クラウドネイティブをエッジに
by
NVIDIA Japan
GTC 2020 発表内容まとめ
by
NVIDIA Japan
NVIDIA Jetson導入事例ご紹介
by
NVIDIA Japan
Final 20200326 jetson edge comuputing digital seminar 1 final (1)
by
NVIDIA Japan
20200326 jetson edge comuputing digital seminar 1 final
by
NVIDIA Japan
20200326 jetson edge comuputing digital seminar 2
by
NVIDIA Japan
エヌビディアのディープラーニング戦略 TESLA P100 & NVIDIA DGX-1
1.
エヌビディア合同会社 マーケティング本部 部長
林 憲一 エヌビディアのディープラーニング戦略 TESLA P100 & NVIDIA DGX-1
2.
人工知能にとって驚くべき一年 AlphaGo 世界チャンピオンを倒す マイクロソフトとグーグルが 画像認識で人間を超える マイクロソフト スーパーディープネットワーク バークレーのブレット 全てのロボットを 一つのネットワークで Deep Speech 2 二つの言語を 一つのネットワークで 新コンピューティングモデル がポップカルチャーにも
3.
拡がり続けるモダンAIの地平 1000以上のAIベンチャー 5000億円調達
4.
ディープラーニングは新しいコンピューティングモデル ディープラーニングによる物体認識 DNN + データ
+ HPC 従来からのコンピュータービジョン 専門家 + 時間 ディープラーニングが 人間を超える成果を達成 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% 2009 2010 2011 2012 2013 2014 2015 2016 Traditional CV Deep Learning ImageNet
5.
エヌビディア ディープラーニング プラットフォーム コンピュータ
ビジョン 会話と音 振る舞い Object Detection Voice Recognition Translation Recommendation Engines Sentiment Analysis cuDNN cuBLAS cuSPARSE NCCL cuFFT Mocha.jl Image Classification ディープラーニングSDK フレームワーク アプリケーション GPU プラットフォーム クラウド GPU Tesla P100 Tesla K80/M40/M4 Jetson TX1 サーバー DGX-1 GIE DRIVEPX2 ディープラーニング 数学ライブラリ マルチ GPU 間通信
6.
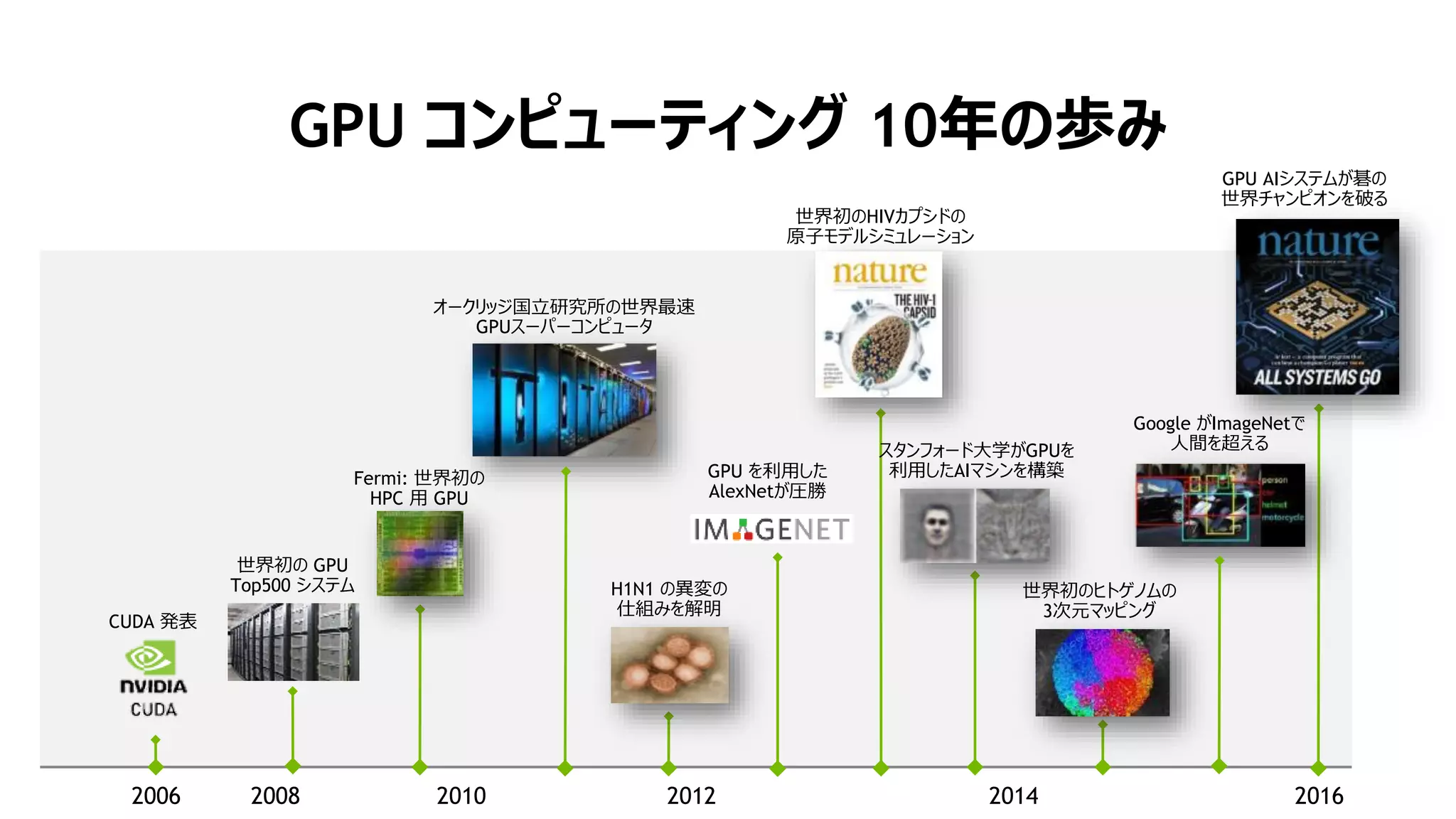
GPU コンピューティング 10年の歩み 2006
2008 2012 20162010 2014 Fermi: 世界初の HPC 用 GPU オークリッジ国立研究所の世界最速 GPUスーパーコンピュータ 世界初のHIVカプシドの 原子モデルシミュレーション GPU AIシステムが碁の 世界チャンピオンを破る スタンフォード大学がGPUを 利用したAIマシンを構築 世界初のヒトゲノムの 3次元マッピング CUDA 発表 世界初の GPU Top500 システム Google がImageNetで 人間を超える H1N1 の異変の 仕組みを解明 GPU を利用した AlexNetが圧勝
7.
倍精度 5.3TF |
単精度 10.6TF | 半精度 21.2TF TESLA P100 ハイパースケールデータセンターのための 世界で最も先進的な GPU
8.
TESLA P100 の先進テクノロジー 16nm
FinFETPascal アーキテクチャ HBM2 積層メモリ NVLink システム インターコネクト
9.
あらゆる面で大きな飛躍 3倍のメモリバンド幅3倍の演算性能 5倍のGPU間通信速度 Teraflops(FP32/FP16) 5 10 15 20 K40 P100 (FP32) P100 (FP16) M40 K40 Bandwidth(GB/Sec) 40 80 120 160 P100 M40 K40 Bandwidth 1x 2x 3x P100 M40
10.
TESLA P100 for
PCIe-based Servers 世界最先端のデータセンターアクセラレータ
11.
TESLA P100 アクセラレータ Tesla
P100 for NVLink-enabled Servers Tesla P100 for PCIe-Based Servers 倍精度 5.3 TF 単精度 10.6 TF 半精度 21.2 TF メモリ容量 16 GB メモリバンド幅 720 GB/S 倍精度 4.7 TF 単精度 9.3 TF 半精度 18.7 TF Config 1: メモリ容量 16 GB メモリバンド幅 720 GB/S Config 2: メモリ容量 12 GB メモリバンド幅 540 GB/S
12.
ディープラーニングに最適化 8基の Tesla P100 NVLink
システムインターコネクト 半精度 170 テラフロップス 主要AIフレームワークを加速 NVIDIA DGX-1 世界初のディープラーニング用スーパーコンピュータ
13.
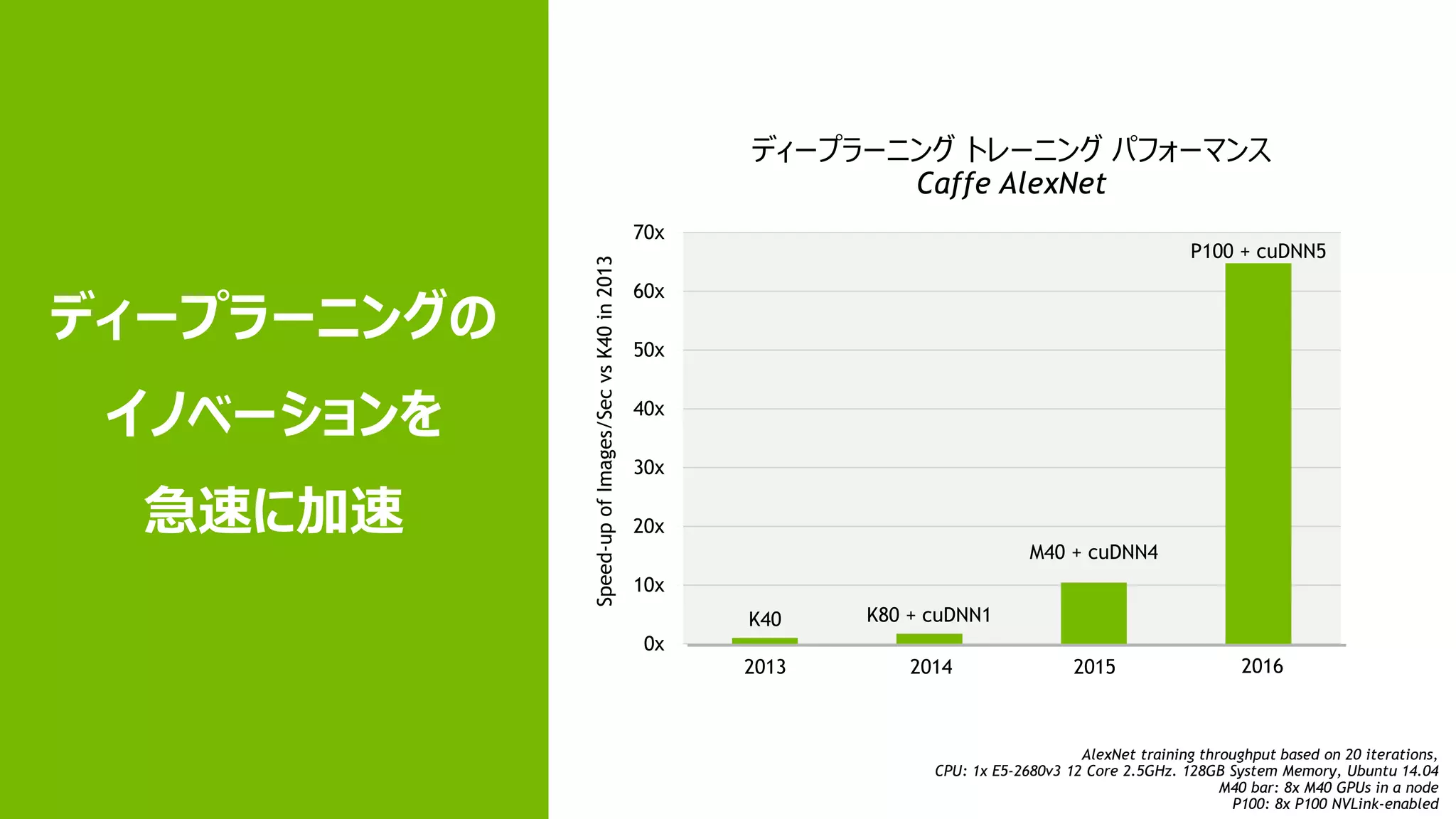
K40 K80 +
cuDNN1 M40 + cuDNN4 P100 + cuDNN5 0x 10x 20x 30x 40x 50x 60x 70x ディープラーニングの イノベーションを 急速に加速 AlexNet training throughput based on 20 iterations, CPU: 1x E5-2680v3 12 Core 2.5GHz. 128GB System Memory, Ubuntu 14.04 M40 bar: 8x M40 GPUs in a node P100: 8x P100 NVLink-enabled ディープラーニング トレーニング パフォーマンス Caffe AlexNet 2013 2014 2015 2016 Speed-upofImages/SecvsK40in2013
14.
日本での販売 NVIDIA DGX-1: 世界初のディープラーニング用スーパーコンピュータ http://www.nvidia.co.jp/DGX1
15.
エヌビディア合同会社 マーケティング本部 エンタープライズ マーケティング
マネージャー 佐々木邦暢
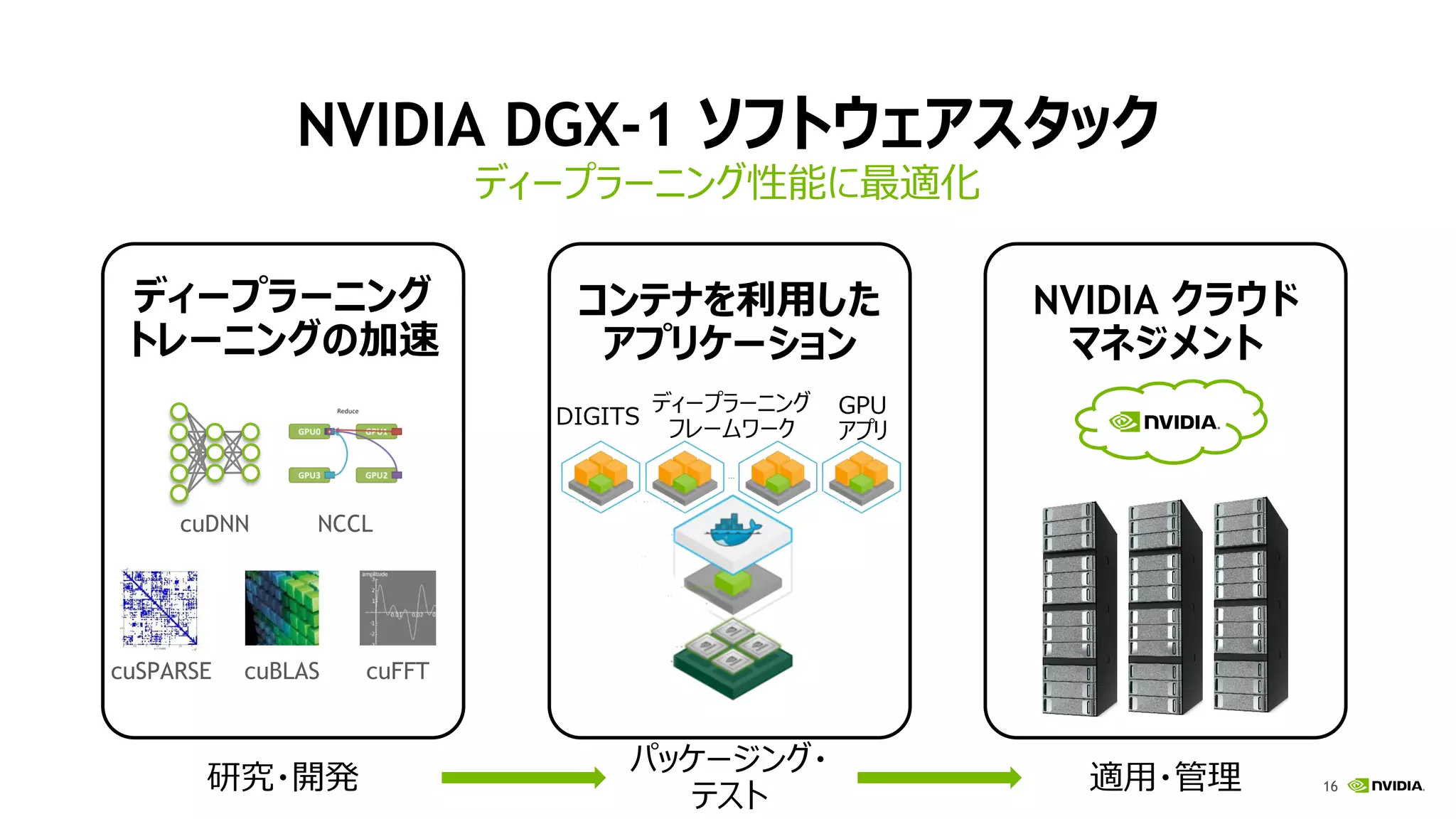
16.
16 NVIDIA DGX-1 ソフトウェアスタック ディープラーニング性能に最適化 ディープラーニング トレーニングの加速 cuDNN
NCCL cuSPARSE cuBLAS cuFFT コンテナを利用した アプリケーション NVIDIA クラウド マネジメント DIGITS ディープラーニング フレームワーク GPU アプリ 研究・開発 適用・管理 パッケージング・ テスト
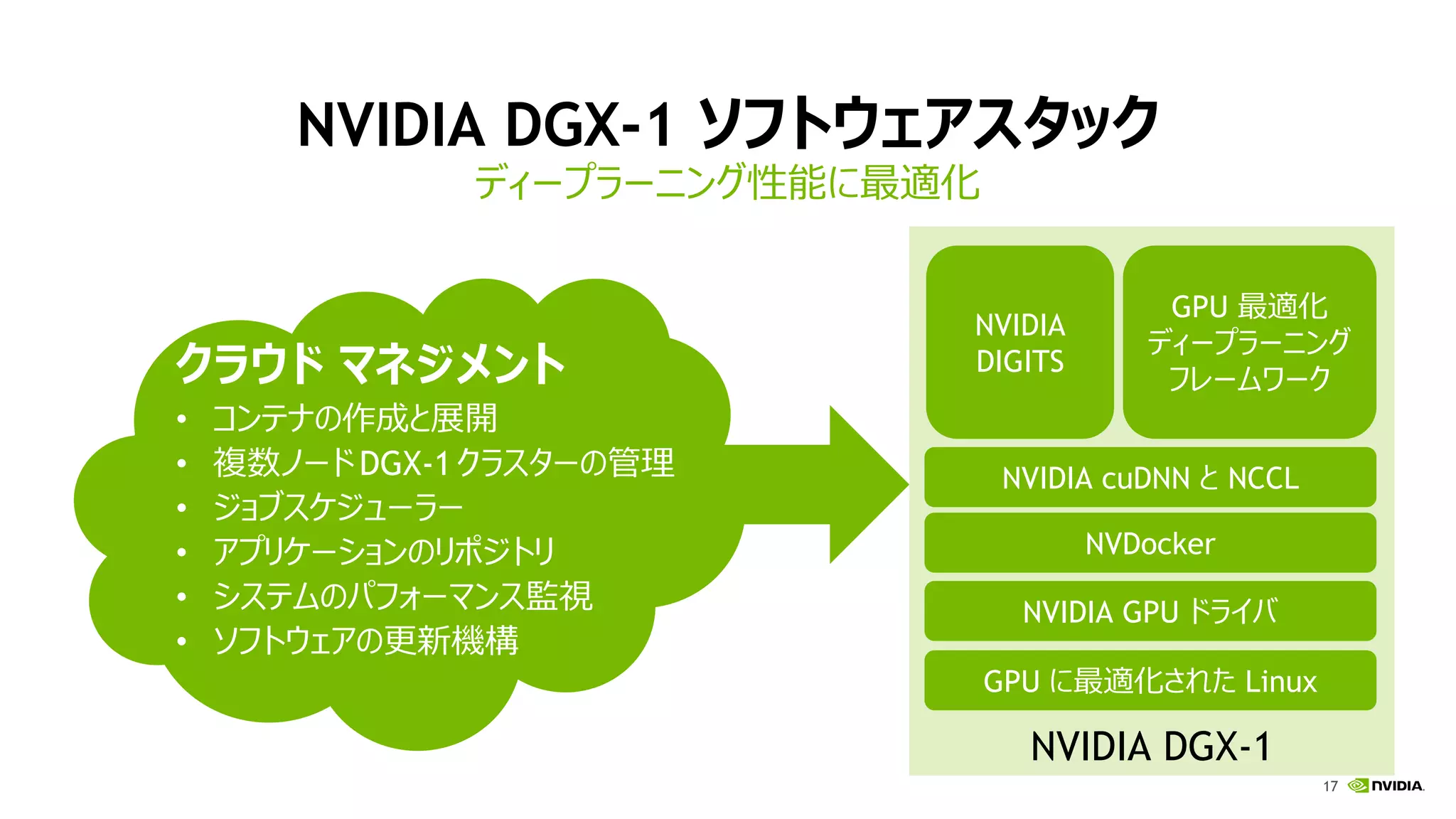
17.
17 NVIDIA DGX-1 ソフトウェアスタック ディープラーニング性能に最適化 NVIDIA
DGX-1 NVIDIA cuDNN と NCCL NVDocker NVIDIA GPU ドライバ GPU に最適化された Linux クラウド マネジメント • コンテナの作成と展開 • 複数ノードDGX-1クラスターの管理 • ジョブスケジューラー • アプリケーションのリポジトリ • システムのパフォーマンス監視 • ソフトウェアの更新機構 NVIDIA DIGITS GPU 最適化 ディープラーニング フレームワーク
18.
18 統合されたプラットフォームとしての DGX-1 柔軟性、パフォーマンス、スケーラビリティ クラウドを 活用 DGX-1 計算ノード DGX-1 クラウド サービス DGX-1 アプリケーション リポジトリ DGX-1のソフトウェアは常に進化を続けます ノードには最小限のソフトウェア すべてのジョブをコンテナで実行 変更に強い柔軟なシステム NVIDIA が最適化したアプリケーション群 常に最新のアプリケーションを追加 パブリック及びプライベート、2種類のリポジトリ ジョブスケジューリング パフォーマンス監視 ノードの管理 ワークロードの分析 サービスとしての
API
19.
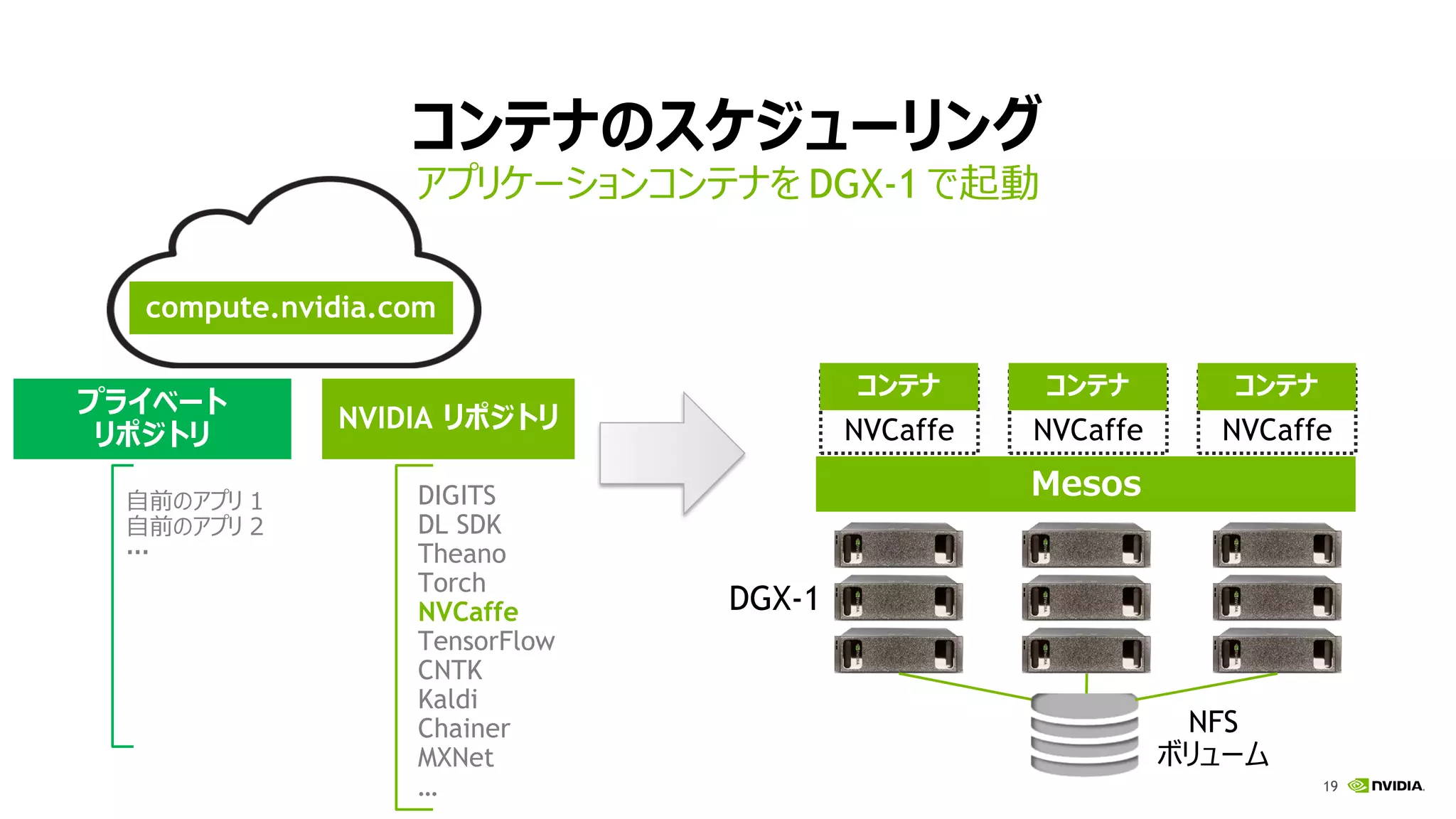
19 コンテナのスケジューリング アプリケーションコンテナを DGX-1 で起動 NVCaffe コンテナ Mesos compute.nvidia.com DIGITS DL
SDK Theano Torch NVCaffe TensorFlow CNTK Kaldi Chainer MXNet … NVIDIA リポジトリ NVCaffe コンテナ NVCaffe コンテナ DGX-1 自前のアプリ 1 自前のアプリ 2 … プライベート リポジトリ NFS ボリューム
20.
20 オンプレミス DGX-1でのコンテナ起動の流れ 管理はクラウドベース ・ データはオンプレミスに Web
ブラウザ ノードの管理 ユーザー認証 Docker イメージのプッシュ・プル ジョブスケジューラーの Web 画面 ハードウェア・ソフトウェアのメトリクス アプリケーションの全データ NFS ストレージ 対話的にアプリケーションを利用 compute.nvidia.com 1. ユーザーがジョブを投入 3. ユーザーが アプリケーションを 利用 DGX-1
Download