Download to read offline














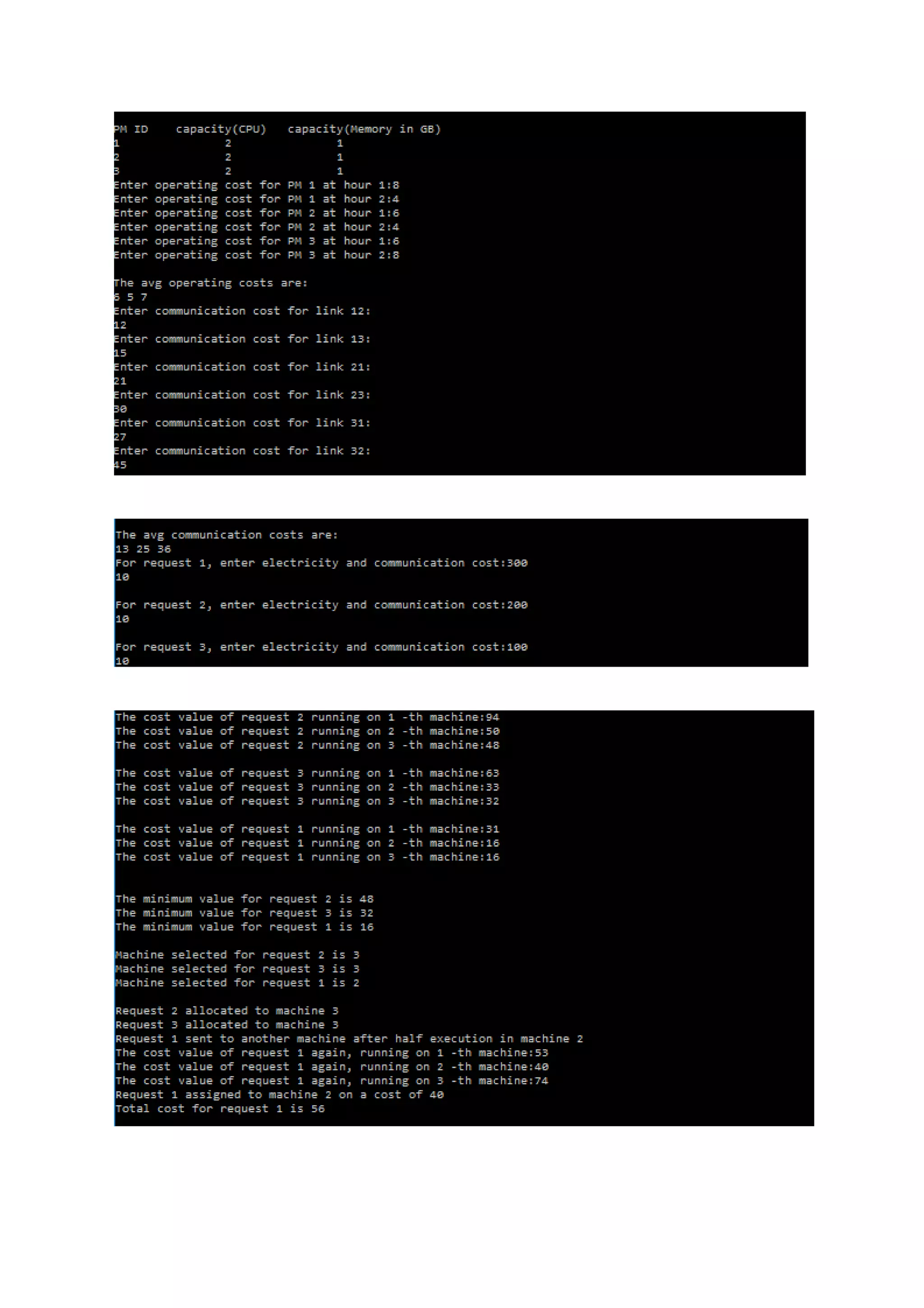
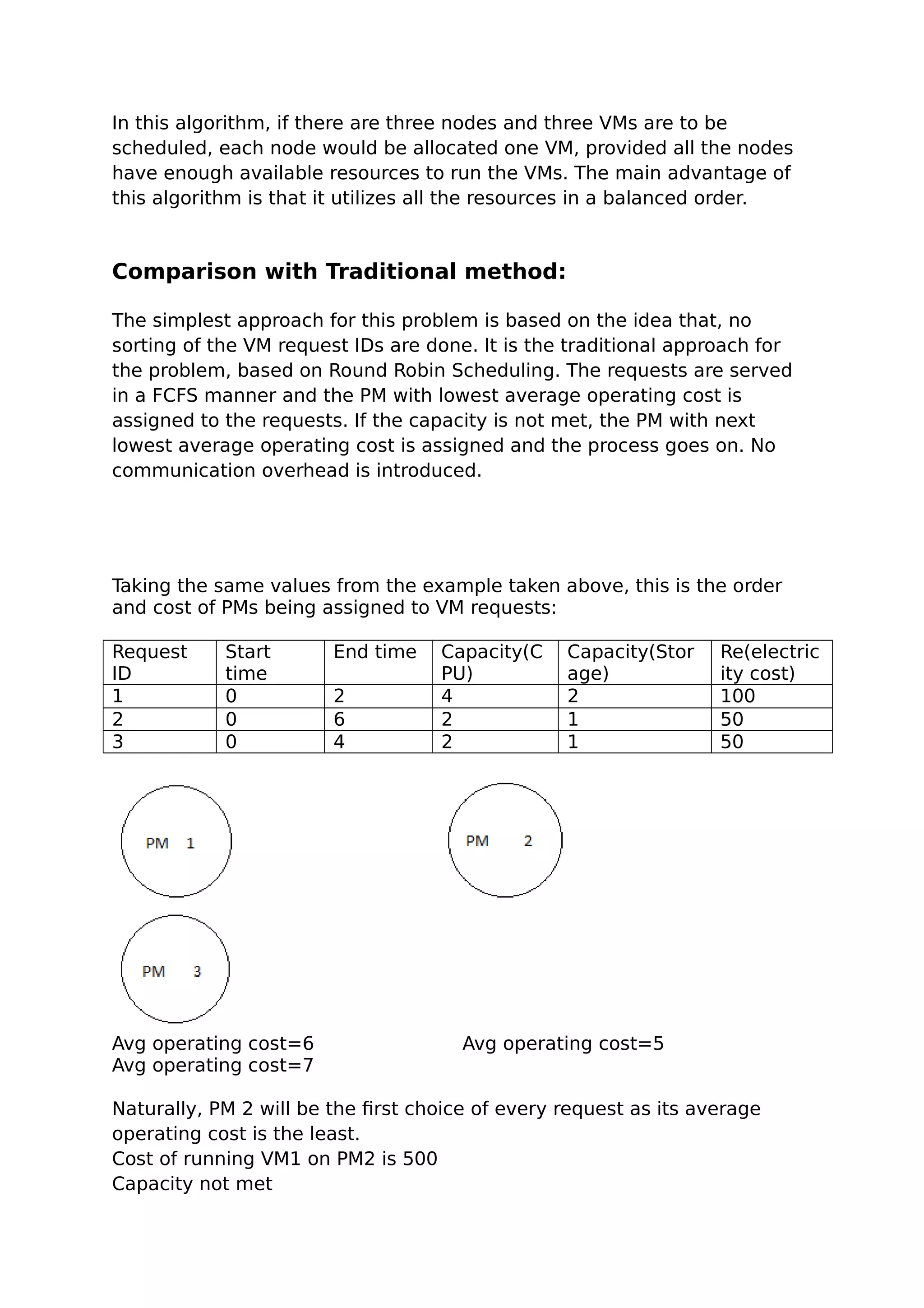
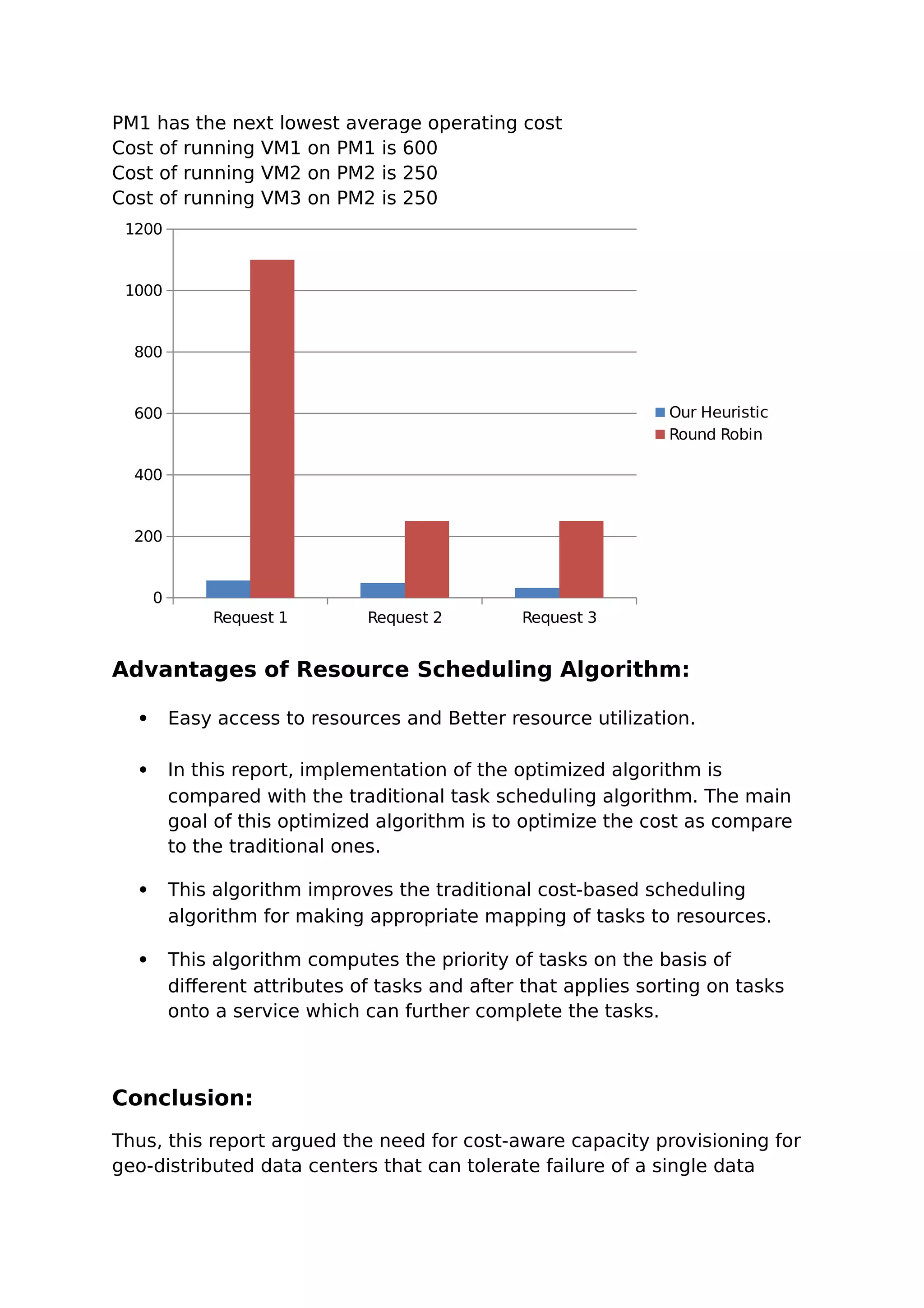


This document summarizes a student report on optimizing virtual machine placement across geo-distributed data centers to minimize costs. It proposes using an optimization model to determine the optimal spare capacity allocation across data centers while considering electricity costs, demand variability, and other factors. It also describes using a heuristic algorithm to place VMs on physical machines across data centers in a way that minimizes operating costs like electricity and communication costs.



































![Server Virtualization With VMware_Project Doc [Latest Updated]](https://cdn.slidesharecdn.com/ss_thumbnails/3de82ad6-6121-43b3-b5b7-27f28f1c7987-150614064651-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)












![ARCHITECTURAL_DESIGN_OF_COMPUTE_AND_STORAGE_CLOUDS[1] - Read-Only.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/architecturaldesignofcomputeandstorageclouds1-read-only-250804065357-787adba1-thumbnail.jpg?width=640&height=640&fit=bounds)


















