Downloaded 54 times




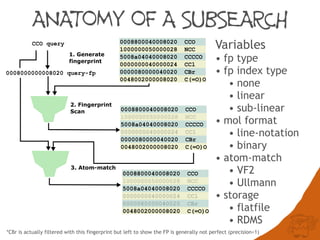






![QUERIES
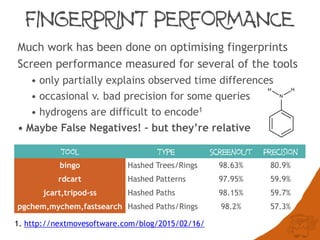
Duplicates due to aromaticity or hydrogens
[H]C1=CN=CN=C1[H] pyrimidine
[H]C1=CN=CN=C1 pyrimidine
C1=CN=CN=C1 pyrimidine
C1=CC=CC=C1 benzene
c1ccccc1 benzene
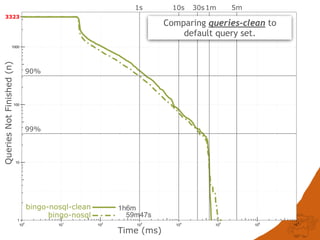
3,140/3,342 unique - but used the non-unique set:
- Hydrogens change semantics of match
- Queries run unmodified but standardised* to queries-clean
when needed, tools that expect “SMARTS”
*aromatised, suppressed-H, atom-stereo removed](https://image.slidesharecdn.com/substructuresearchfaceoff-150528105320-lva1-app6892/85/Substructure-Search-Face-off-11-320.jpg)
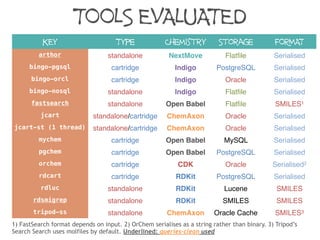





![EXCLUDED QueRIES
19 queries skipped in one or more tools
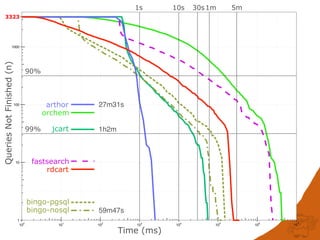
3,323/3,342 that were executed by all
2 Non-terminal hydrogens
C1N[H]OC[H]1
1 Invalid stereochemistry
CC[C@@H]
10 Atom classes
C1C[N:1]CNC1
6 Bond stereo not-implemented (should have cleaned)
N
1
HN
H2
C
NH
H
O
H2C
H
H3
C CH](https://image.slidesharecdn.com/substructuresearchfaceoff-150528105320-lva1-app6892/85/Substructure-Search-Face-off-18-320.jpg)
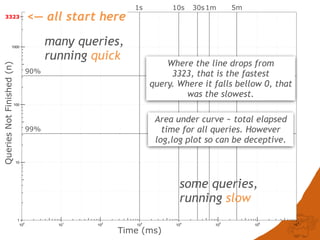
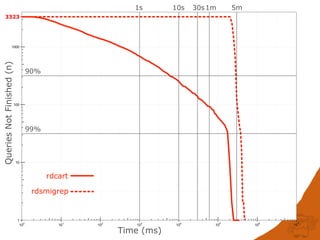
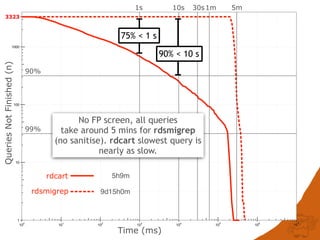
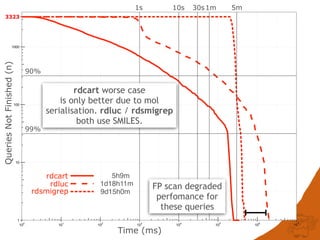
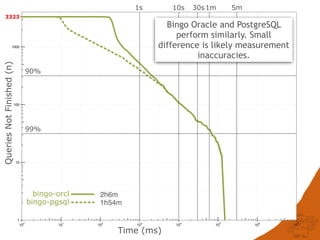
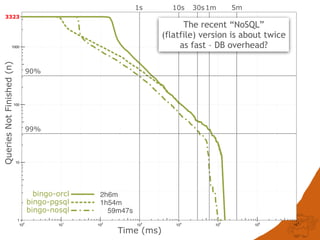
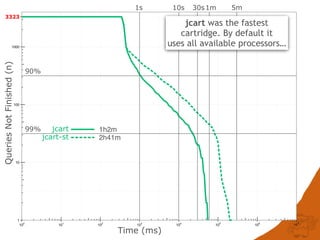

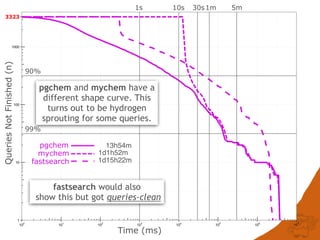
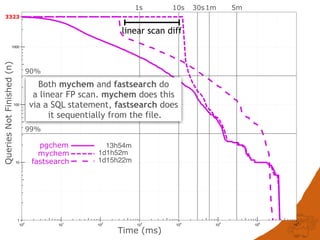
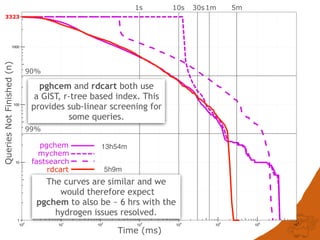
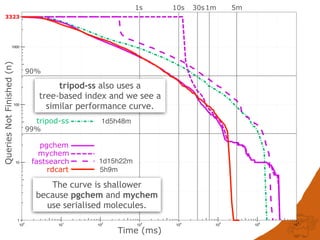

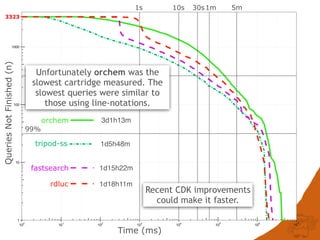




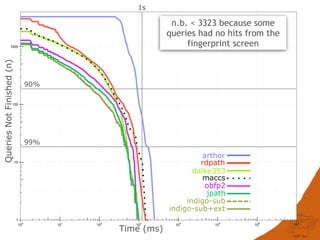
![CONCLUSIONS
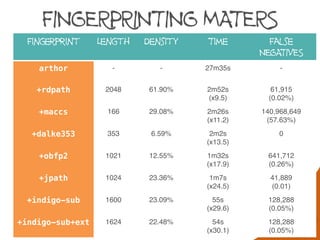
Fast searching depends on many factors
• index data-structure
• fingerprint type
• molecule representation
• atom-match algorithm
Fingerprint optimisation does mater but is not the
performance bottleneck and can’t always help:
Generic patterns, a-a
Hydrogens, [H]N([H])C](https://image.slidesharecdn.com/substructuresearchfaceoff-150528105320-lva1-app6892/85/Substructure-Search-Face-off-44-320.jpg)


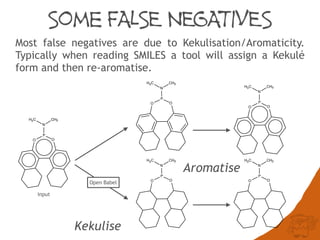
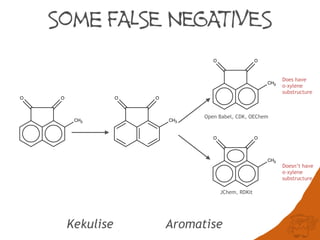

The document discusses the performance and efficiency of various cheminformatics tools for substructure searching, particularly focusing on challenges like query speed and accuracy. It provides benchmarks from different search algorithms across multiple databases and highlights the differences in retrieval efficiency based on method and database type. Key findings suggest that while most tools perform adequately for common queries, they exhibit significant performance disparities under specific circumstances, particularly with complex or pathological queries.







































![RDKit: Six Not-So-Easy Pieces [RDKit UGM 2016]](https://cdn.slidesharecdn.com/ss_thumbnails/rdkittautomersbasel16-161031122400-thumbnail.jpg?width=640&height=640&fit=bounds)






















































![Polymer [ बहुलक ] Chemistry Notes PDF - Irfanullah Mehar - JJ Sir Chemistry.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/polymerchemistrynotespdf-irfanullahmehar-jjsirchemistry-260210172118-3f9b37f7-thumbnail.jpg?width=640&height=640&fit=bounds)











