Downloaded 69 times









![Conceptual algorithm
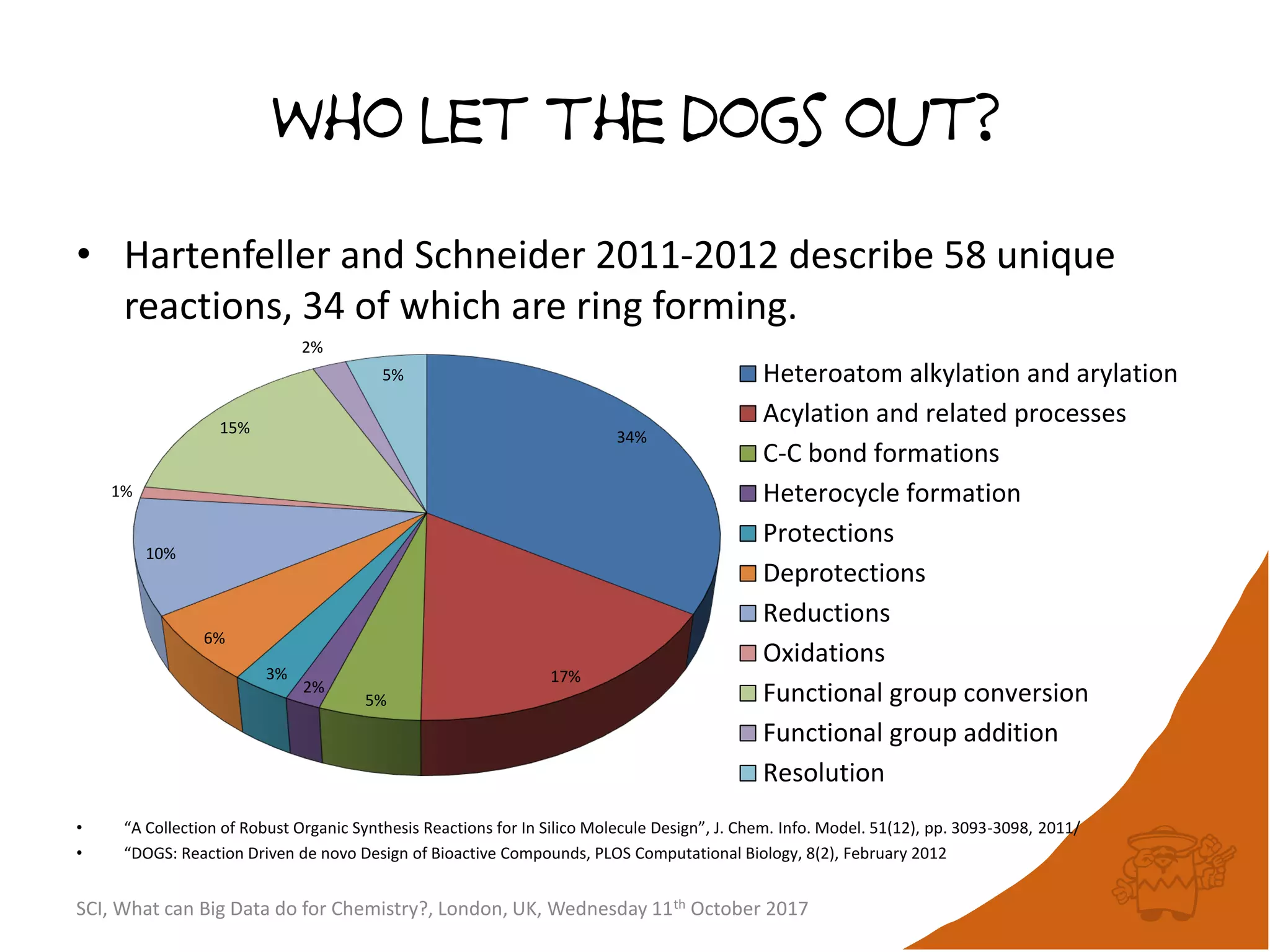
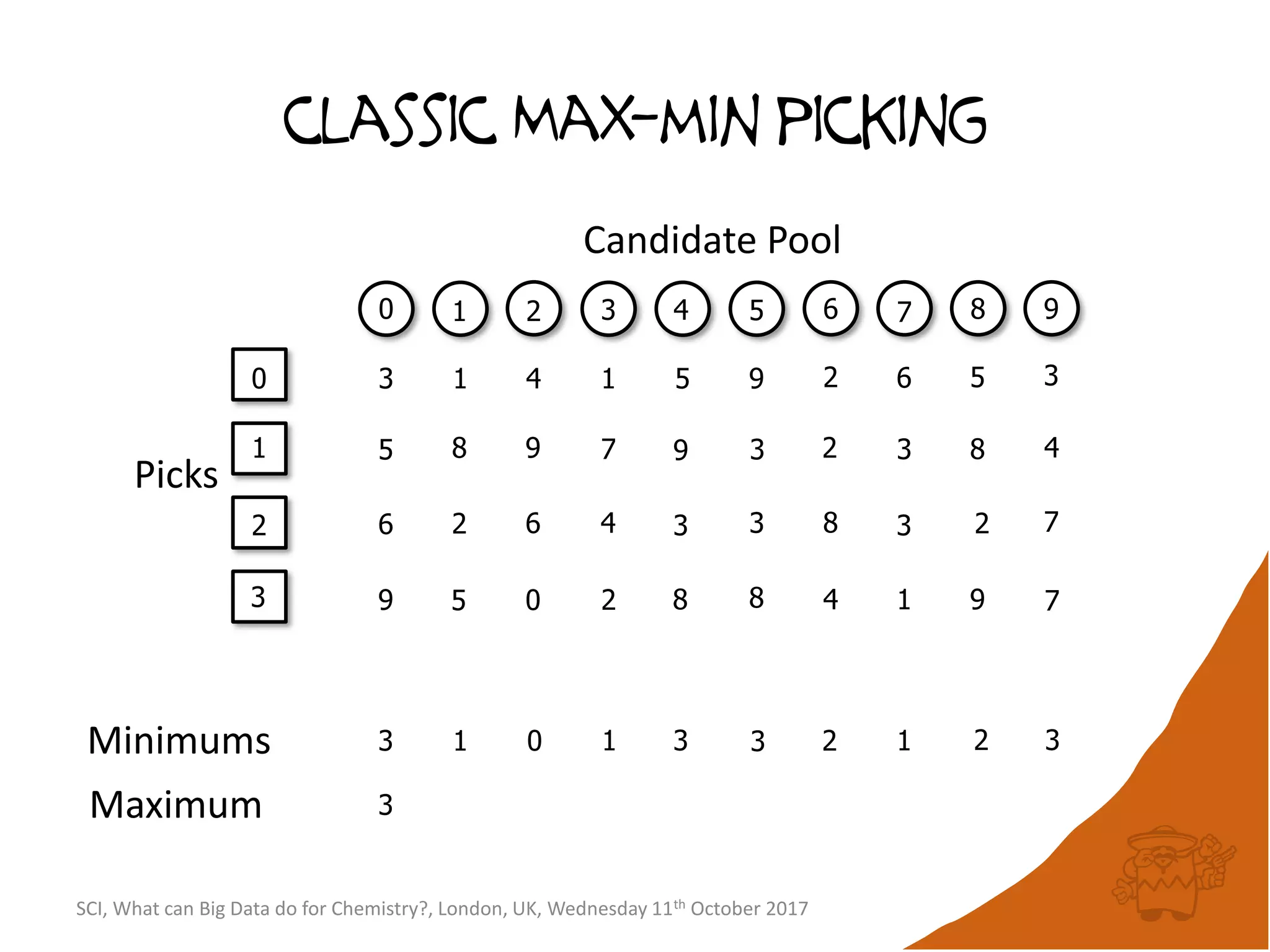
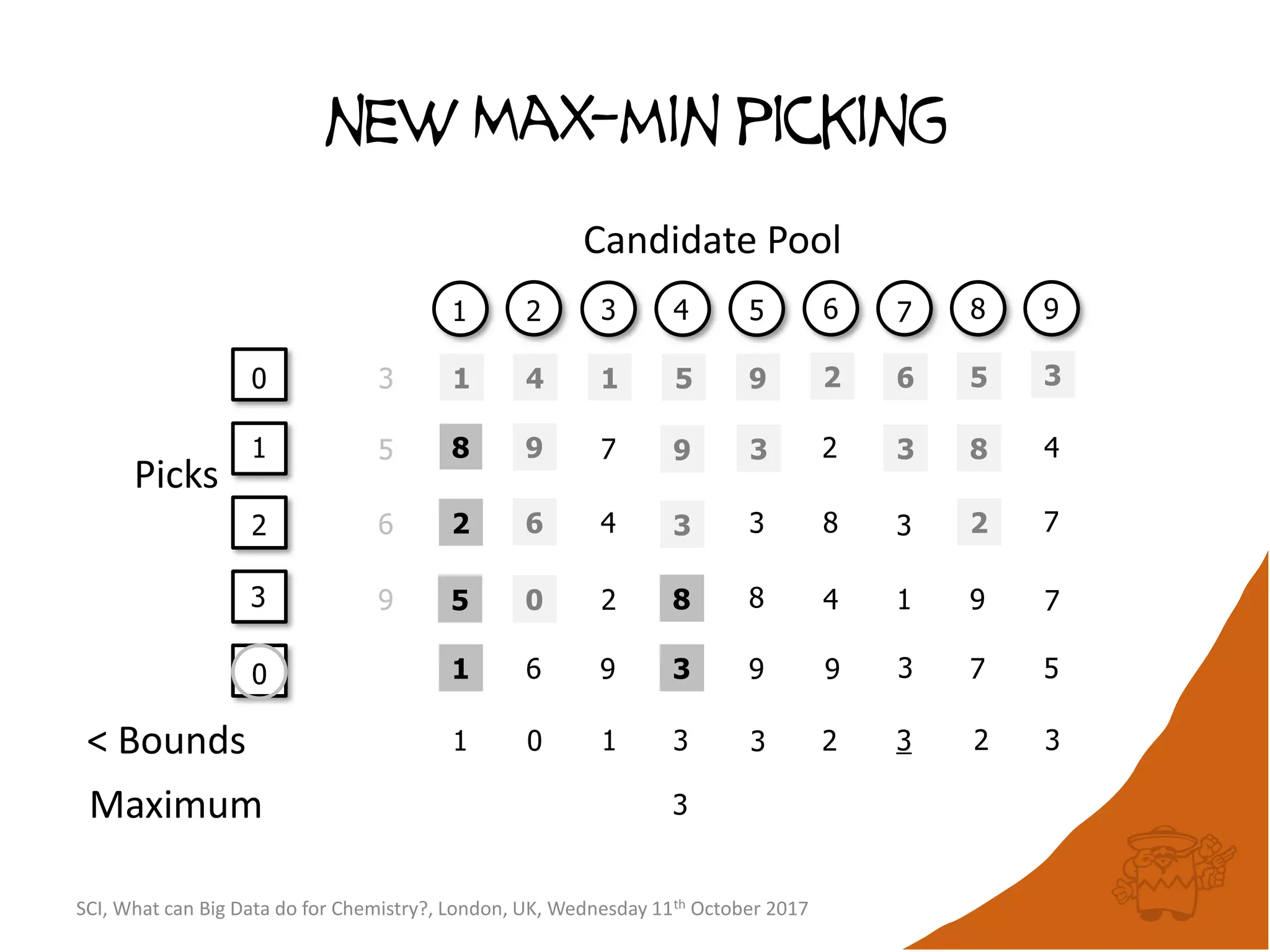
• If no compounds have been picked so far, choose the
first picked compound at random.
• Repeatedly select the compound furthest from it’s
nearest picked compound [hence the name
maximum-minimum distance].
• Continue until the desired number of picked
compounds has been selected (or the pool of
available compounds has been exhausted).
SCI, What can Big Data do for Chemistry?, London, UK, Wednesday 11th October 2017](https://image.slidesharecdn.com/smallworldlondon2017-171011105127/75/Chemical-similarity-using-multi-terabyte-graph-databases-68-billion-nodes-and-counting-13-2048.jpg)

![Screening library enhancement #1
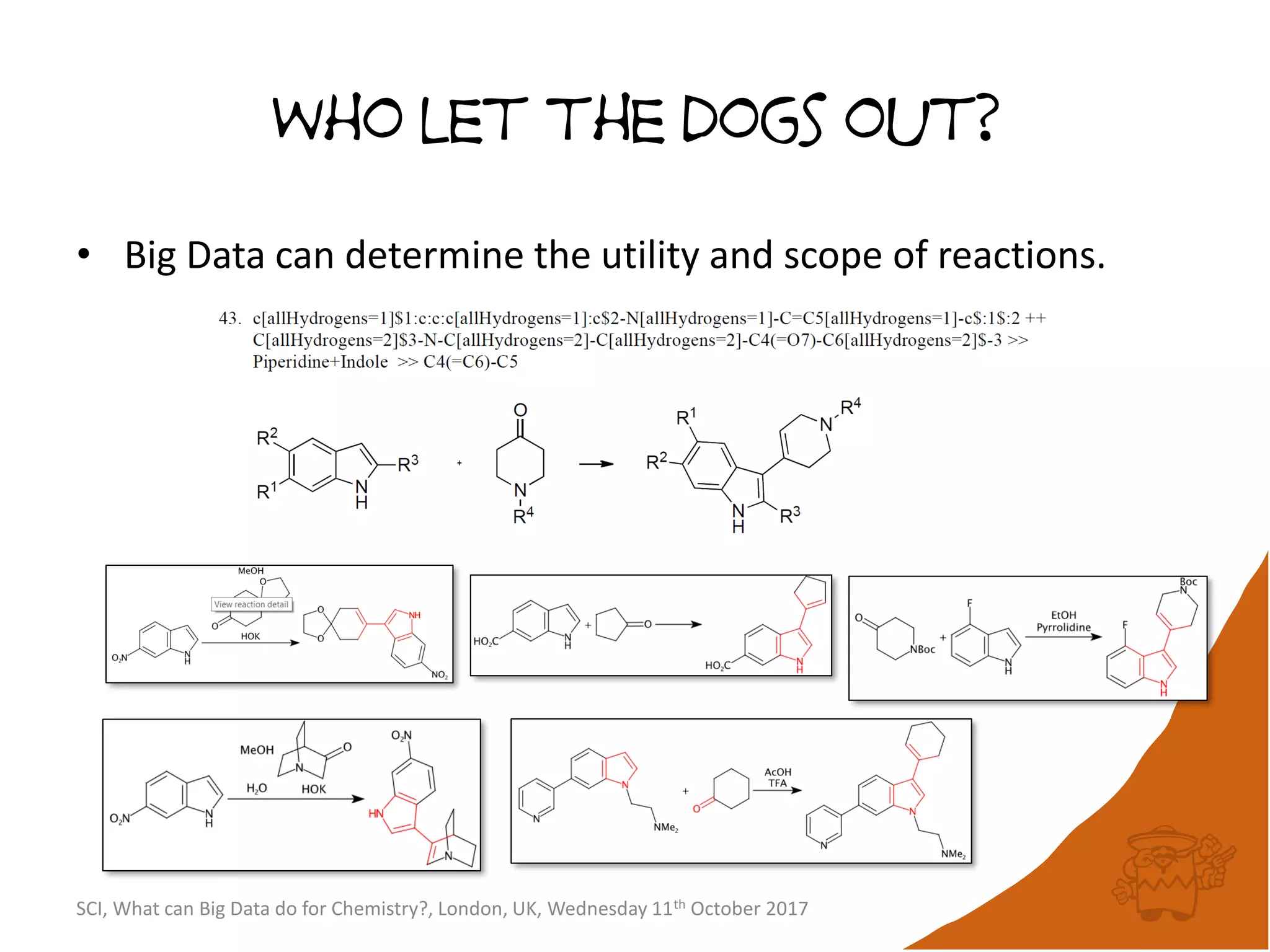
• Selecting 1K compounds for purchase from
eMolecules (14M) to enhance ChEMBL 23 (1.7M).
– Reading eMolecules: 4780s
– Reading ChEMBL: 821s
– Generating FPs: 1456s
– MaxMinPicker: 42773s[80B FP cmps]
• Selecting the first 18 compounds takes only 399s
[715M FP cmps].
• Fazit: Large scale diversity selection can be run
overnight on a single CPU core.
SCI, What can Big Data do for Chemistry?, London, UK, Wednesday 11th October 2017](https://image.slidesharecdn.com/smallworldlondon2017-171011105127/75/Chemical-similarity-using-multi-terabyte-graph-databases-68-billion-nodes-and-counting-19-2048.jpg)










![Recent Rsc/GDB example
• Bizzini et al., “Synthesis of trinorborane”, Chemical
Communications, 26 September 2017.
– “This new rigid structural type was found to be present in the computer
generated GDB and has until now no real-world counterpart”.
Tetracyclo[5.2.2.01,6.04,9]undecane 1-Azonia-tetracyclo[5.2.2.01,6.04,9]undecane
PubChem CID90865661 (not in GDB!)
Substructure of Dapniglucin A and B
Org. Lett. 5(10):1733-1736, 2003.
SCI, What can Big Data do for Chemistry?, London, UK, Wednesday 11th October 2017](https://image.slidesharecdn.com/smallworldlondon2017-171011105127/75/Chemical-similarity-using-multi-terabyte-graph-databases-68-billion-nodes-and-counting-32-2048.jpg)


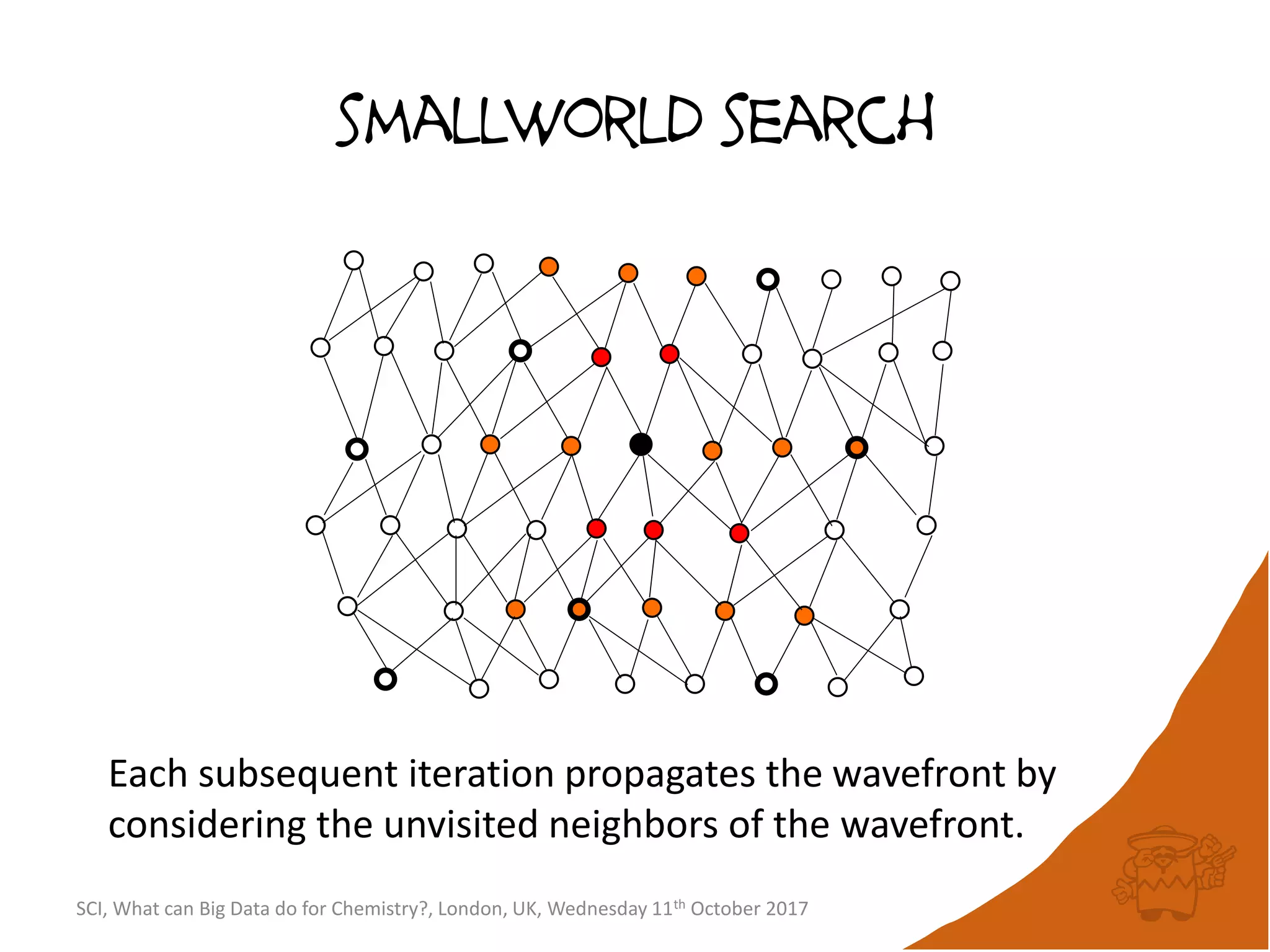

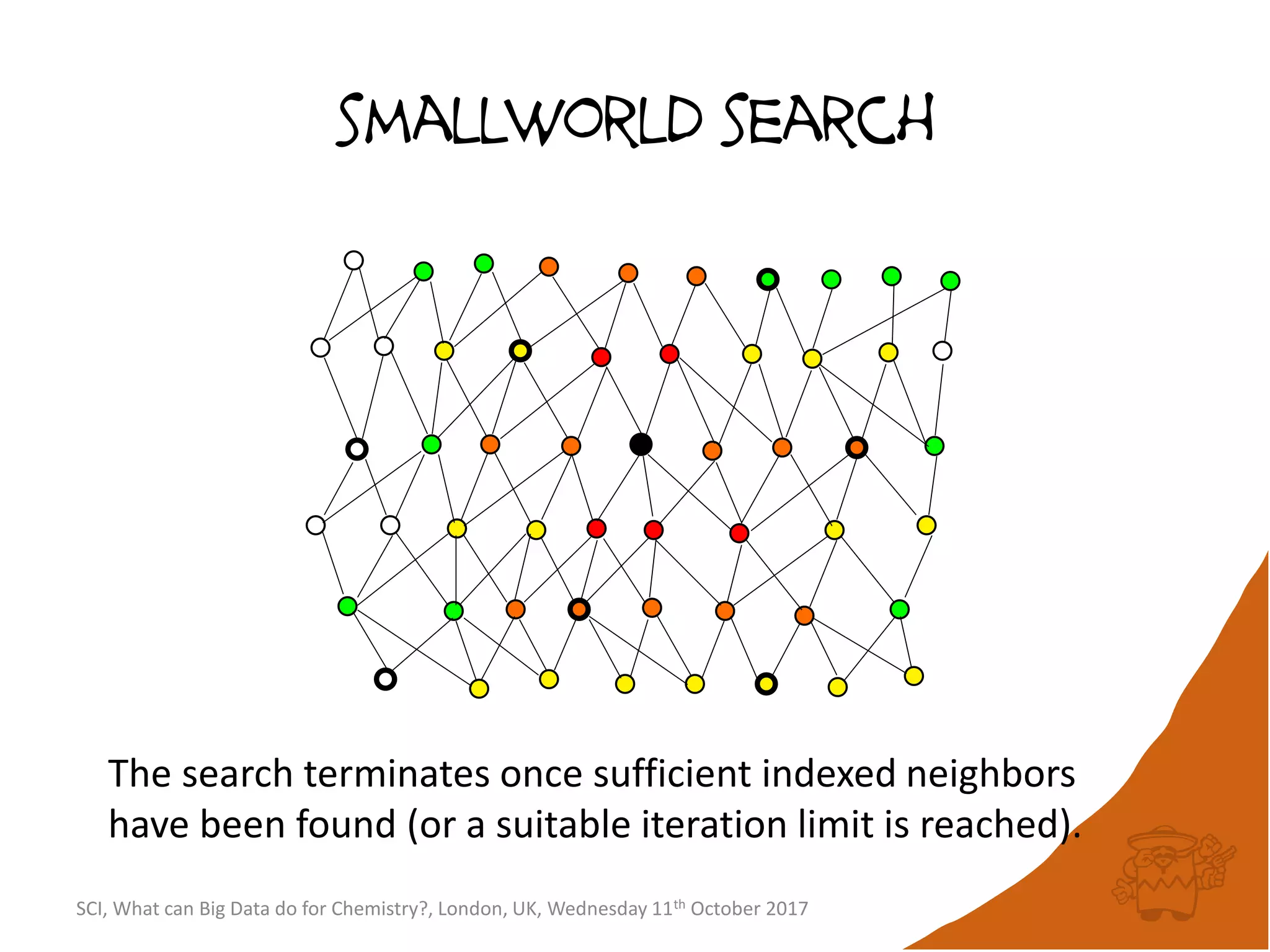


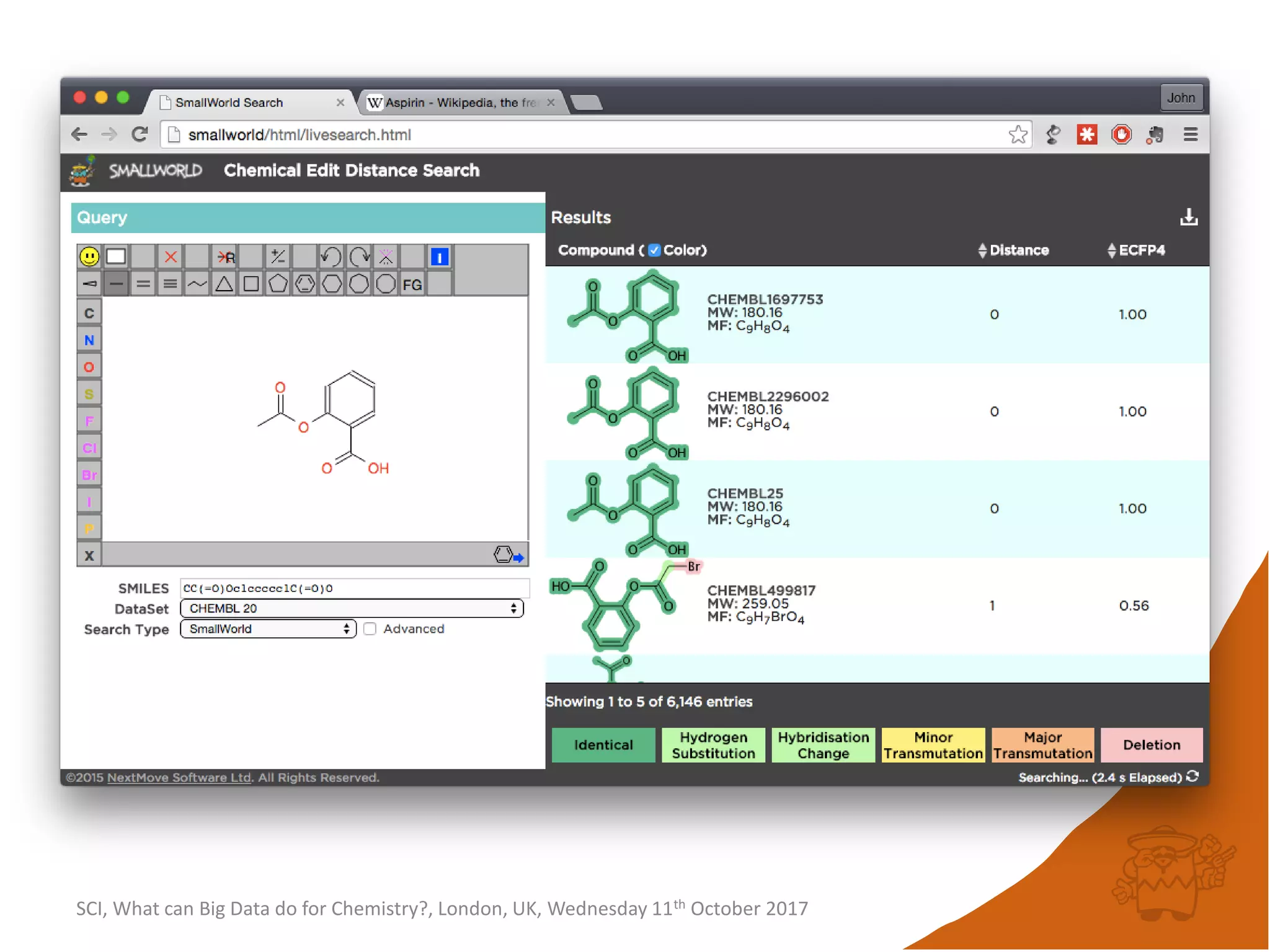
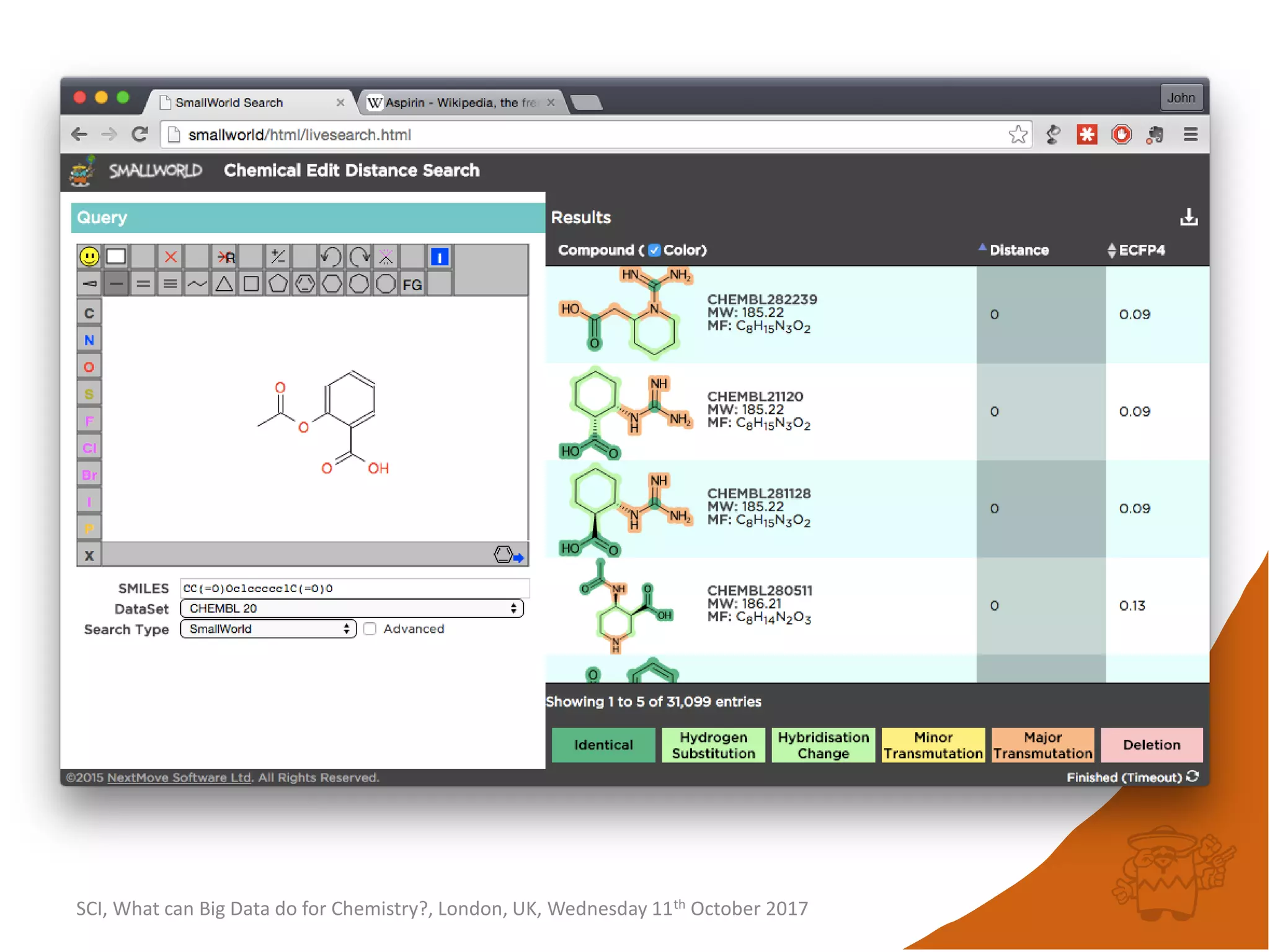
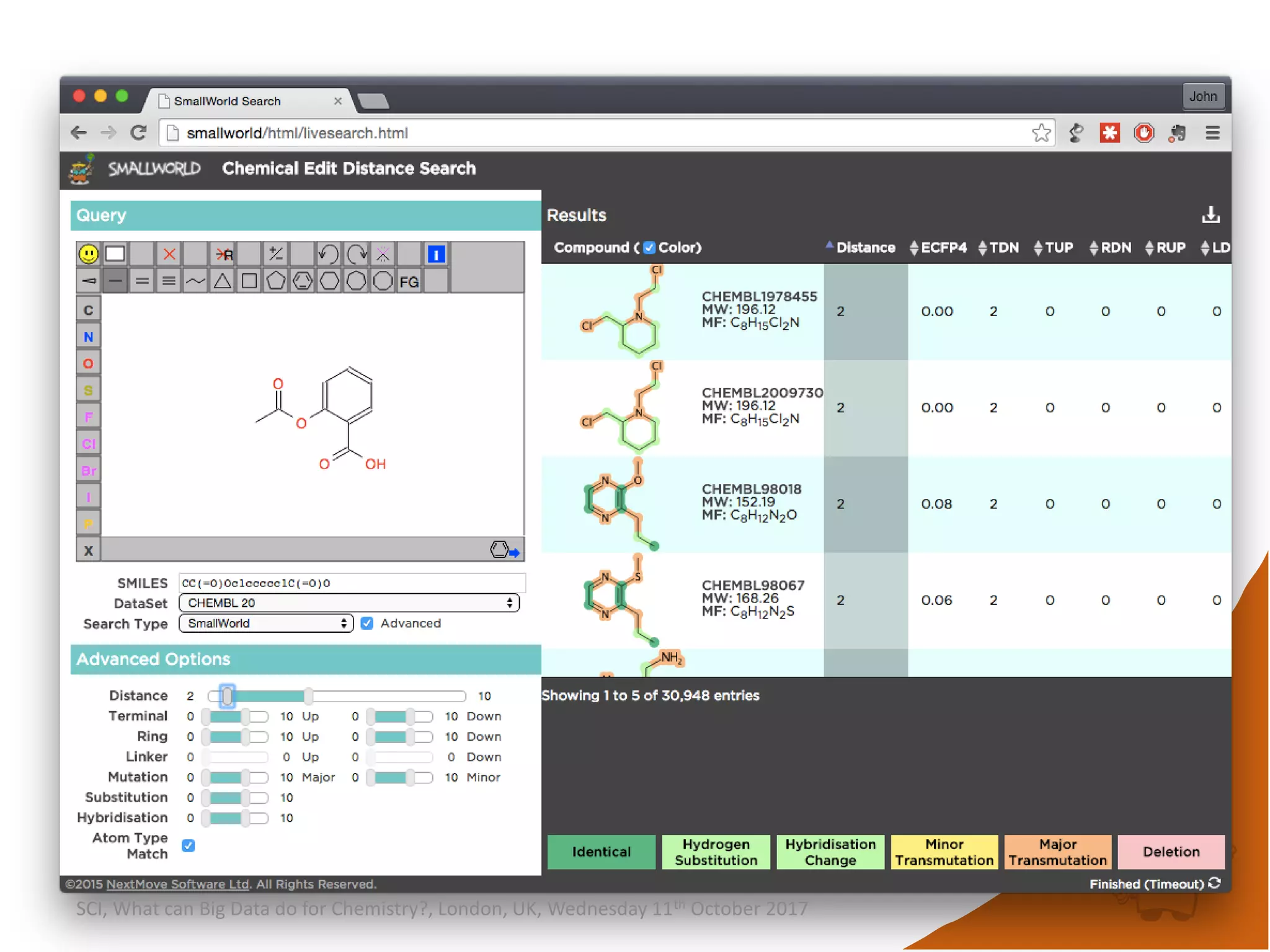




![integer indices and DB mapping
• Inside each partition, each node is assigned a unique
sequential integer index.
– c1ccccc1 → *1*****1 ↔ B6R1.13
– n1cnccc1 → *1*****1 ↔ B6R1.13
• Each edge is then represented by two integers.
• SmallWorld is a “type domain index” over graphs.
• User database are represented as “mappings”.
– B13R1.834 CC(=O)Oc1ccccc1C(=O)O CHEMBL1697753
– B14R4.107563 C1C[N+]23CCC4C2CC1C3C4 CID90865661
SCI, What can Big Data do for Chemistry?, London, UK, Wednesday 11th October 2017](https://image.slidesharecdn.com/smallworldlondon2017-171011105127/75/Chemical-similarity-using-multi-terabyte-graph-databases-68-billion-nodes-and-counting-51-2048.jpg)
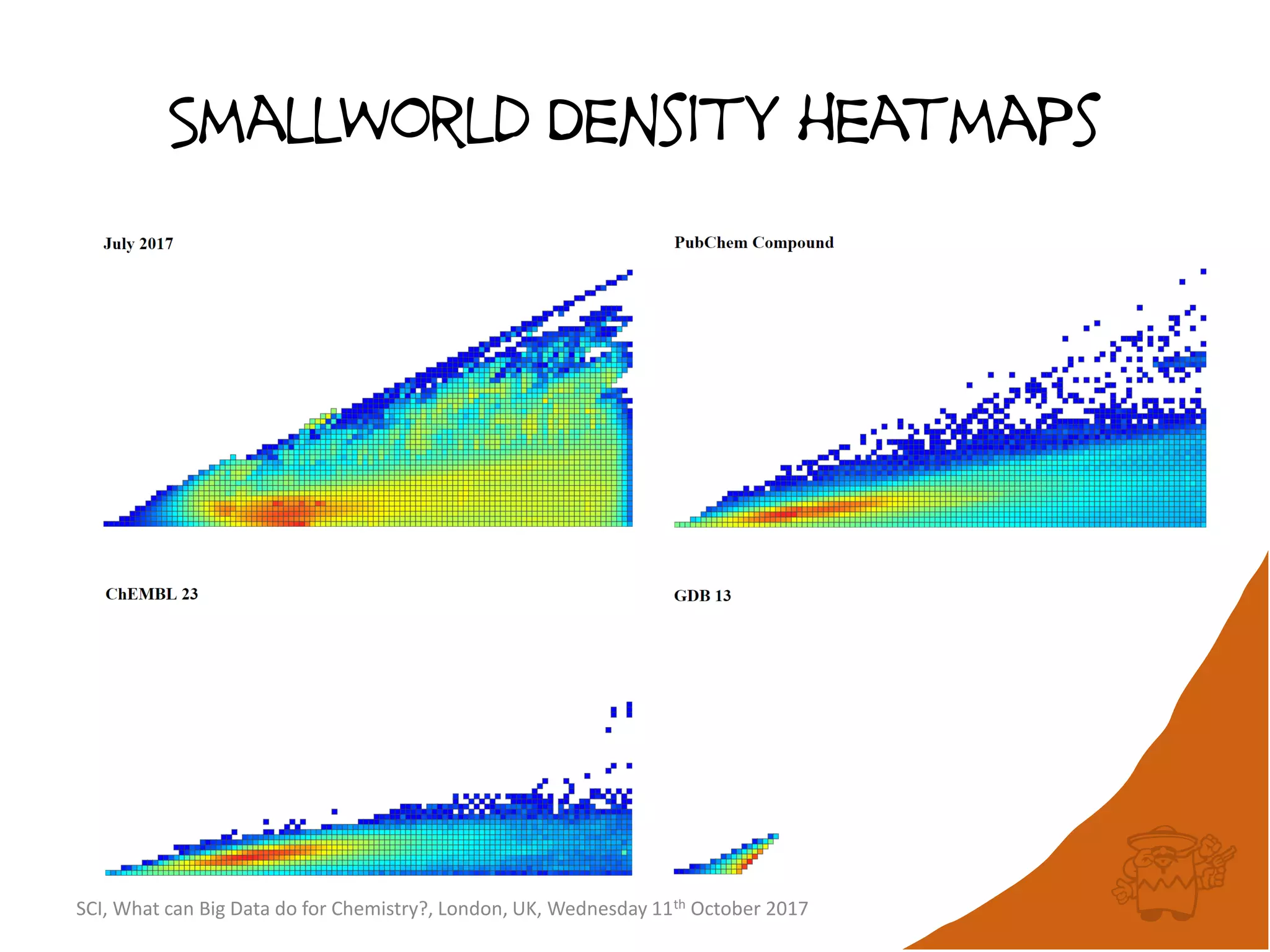




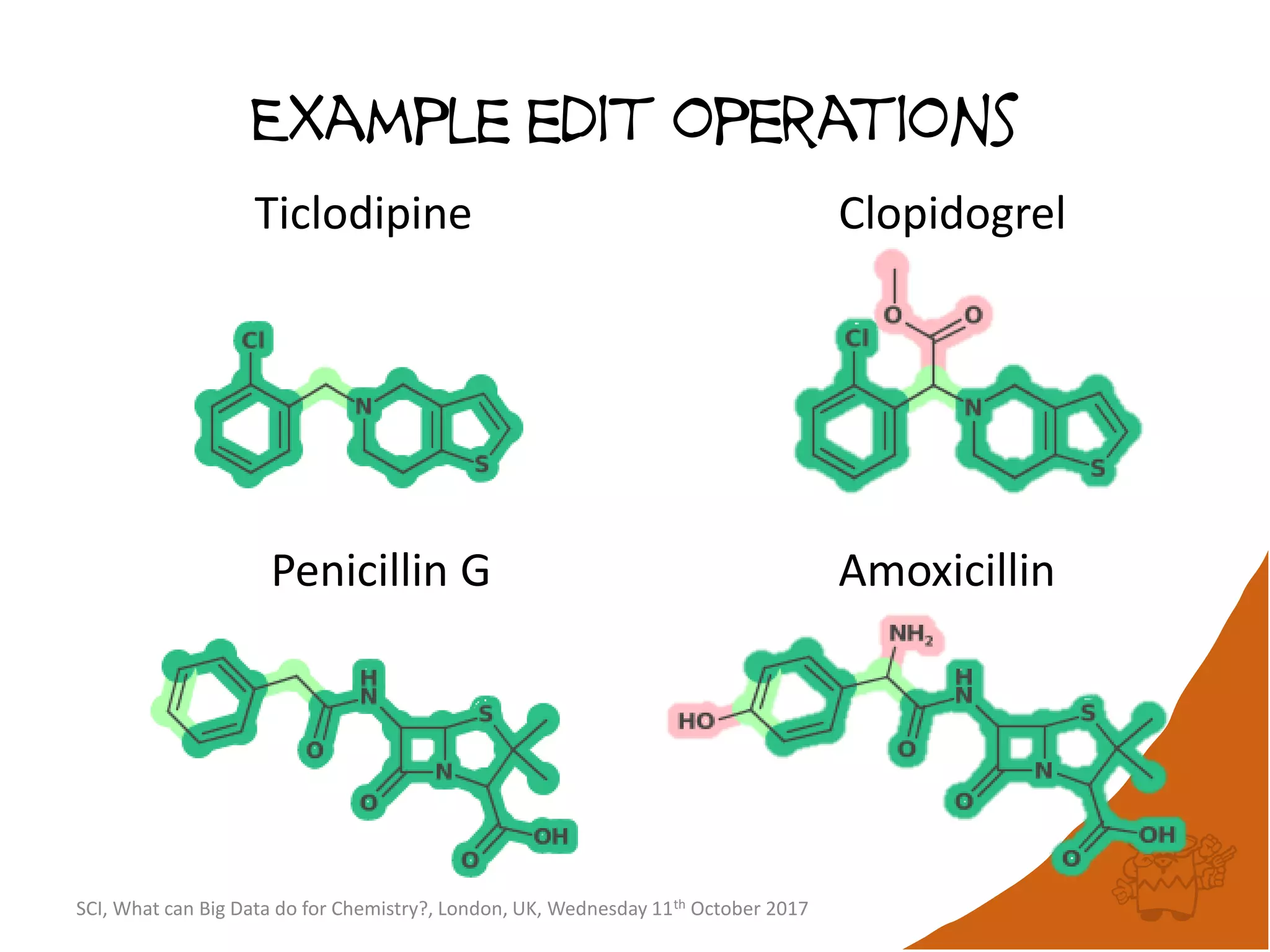
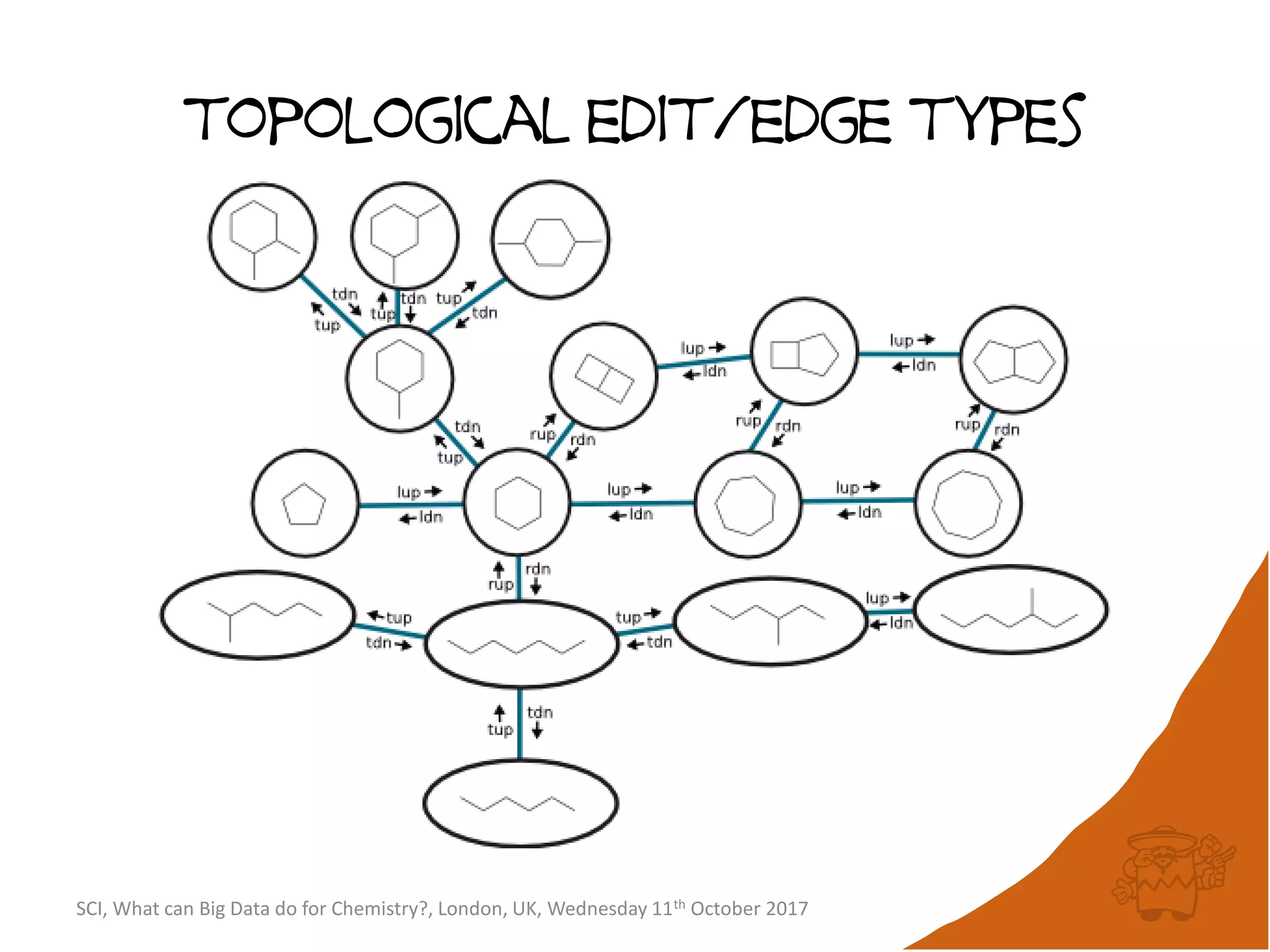
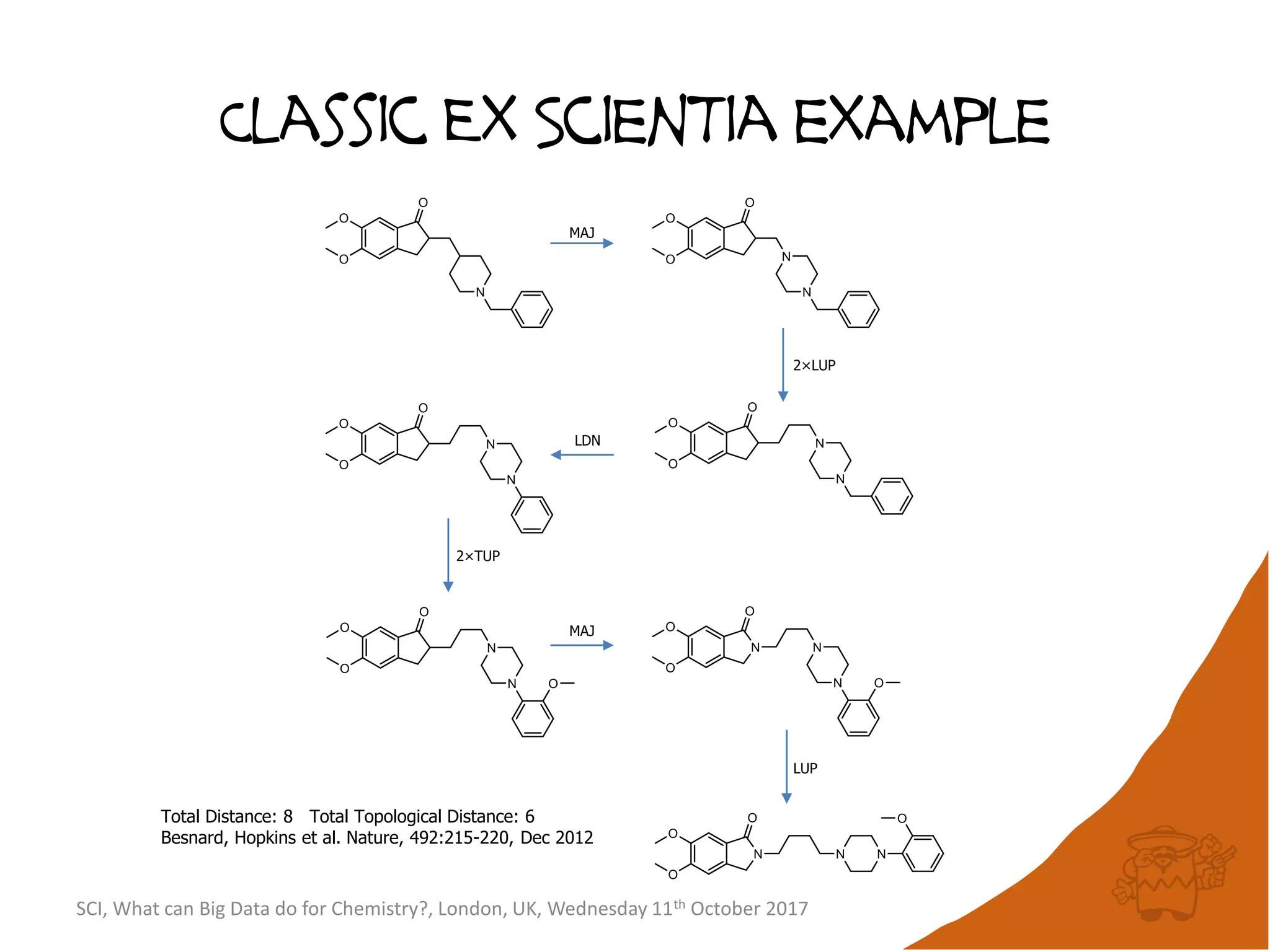
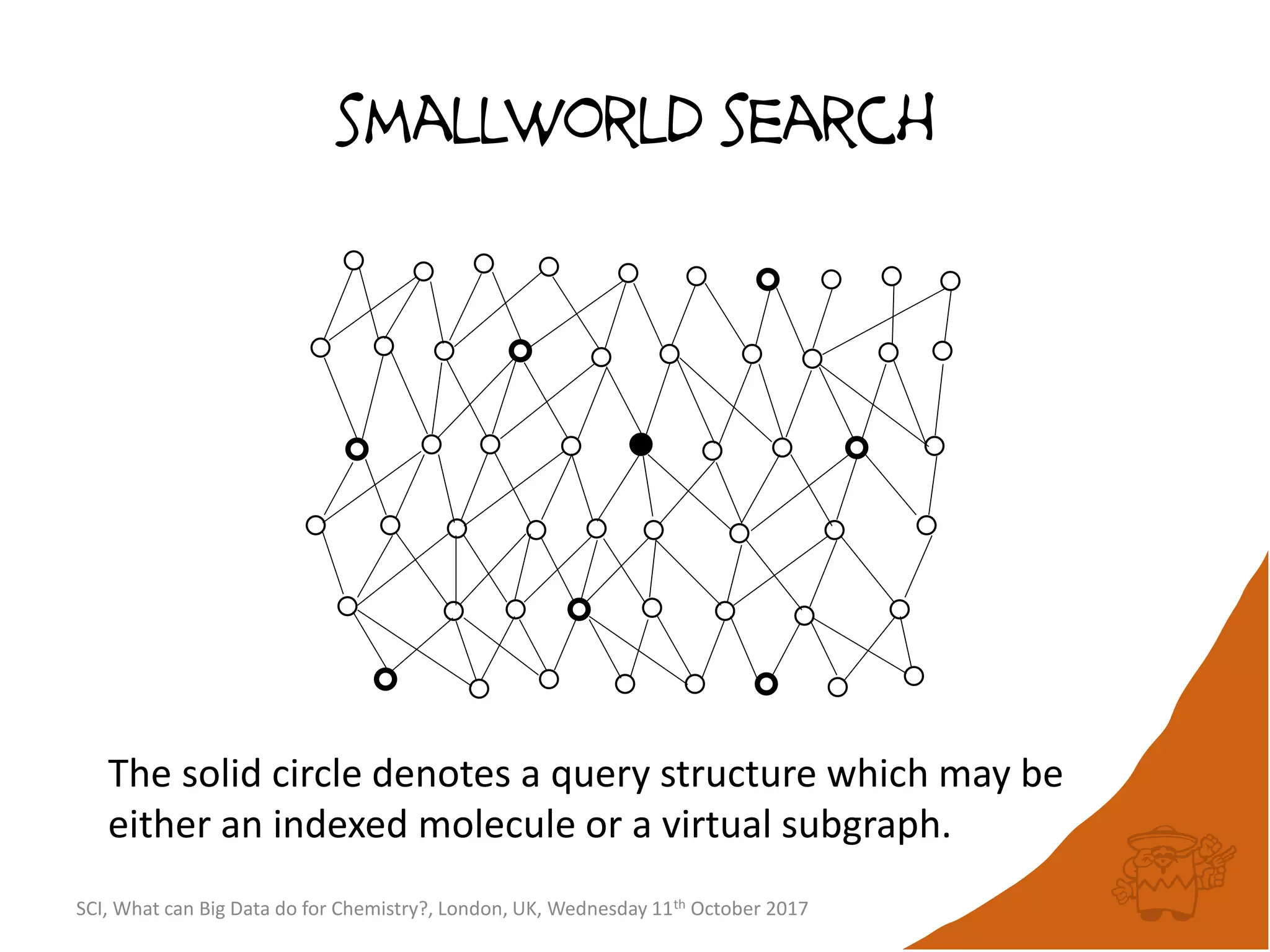
The document summarizes a presentation about using large graph databases for chemical similarity searching. It describes building a graph database of 68 billion molecular substructures from 340 million molecules and using graph edit distance to perform sublinear-scaling searches through the database to identify similar molecules. This approach scales better to large datasets than traditional fingerprint-based similarity methods.



































































