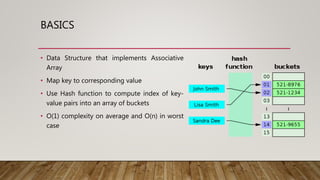
This document discusses hash tables, which are data structures that use a hash function to map keys to values in an array of buckets. Hash tables provide O(1) time performance for operations like insertion, search and deletion on average by distributing entries uniformly across the buckets. Collisions, where two keys hash to the same value, are resolved using techniques like separate chaining or open addressing. The document covers topics like choosing good hash functions, collision resolution methods, dynamic resizing, and applications of hash tables.










![COLLISION RESOLUTION
OPEN ADDRESSING
Types:
• Linear probing: Linearly probe for next slot
index = [hash(x) + i] % S](https://image.slidesharecdn.com/hashtable-180306034052/85/Hash-table-12-320.jpg)
![COLLISION RESOLUTION
OPEN ADDRESSING
Types:
• Linear probing: Linearly probe for next slot => Clustering
index = [hash(x) + i] % S](https://image.slidesharecdn.com/hashtable-180306034052/85/Hash-table-13-320.jpg)
![COLLISION RESOLUTION
OPEN ADDRESSING
Types:
• Linear probing: Linearly probe for next slot => Clustering
index = [hash(x) + i] % S
• Quadratic probing: Look for i^2 slot in ith iteration
index = [hash(x) + i^2] % S](https://image.slidesharecdn.com/hashtable-180306034052/85/Hash-table-14-320.jpg)
![COLLISION RESOLUTION
OPEN ADDRESSING
Types:
• Linear probing: Linearly probe for next slot => Clustering
index = [hash(x) + i] % S
• Quadratic probing: Look for i^2 slot in ith iteration
index = [hash(x) + i^2] % S
• Double hashing: Use another hash function hash2(x) and look for i*hash2(x) in ith
iteration
index = [hash(x) + i*hash2(x)] % S](https://image.slidesharecdn.com/hashtable-180306034052/85/Hash-table-15-320.jpg)









































































