
Downloaded 19 times

















CCC[C@@H]
(C)CCCC(C)=CCC2=C(C)C(=O)c1ccccc1C2
=O
OpenEye
CC1=C(C(=O)c2ccccc2C1=O)C/C=C(C)/CC
C[C@H](C)CCC[C@H](C)CCCC(C)C
ChEMBL
CC(C)CCC[C@@H](C)CCC[C@@H]
(C)CCCC(=CCC1=C(C)C(=O)c2ccccc2C1=](https://image.slidesharecdn.com/madisonmaterialsworkshop-150209093716-conversion-gate02/75/Hosting-public-domain-chemicals-data-online-for-the-community-the-challenges-of-handling-materials-30-2048.jpg)



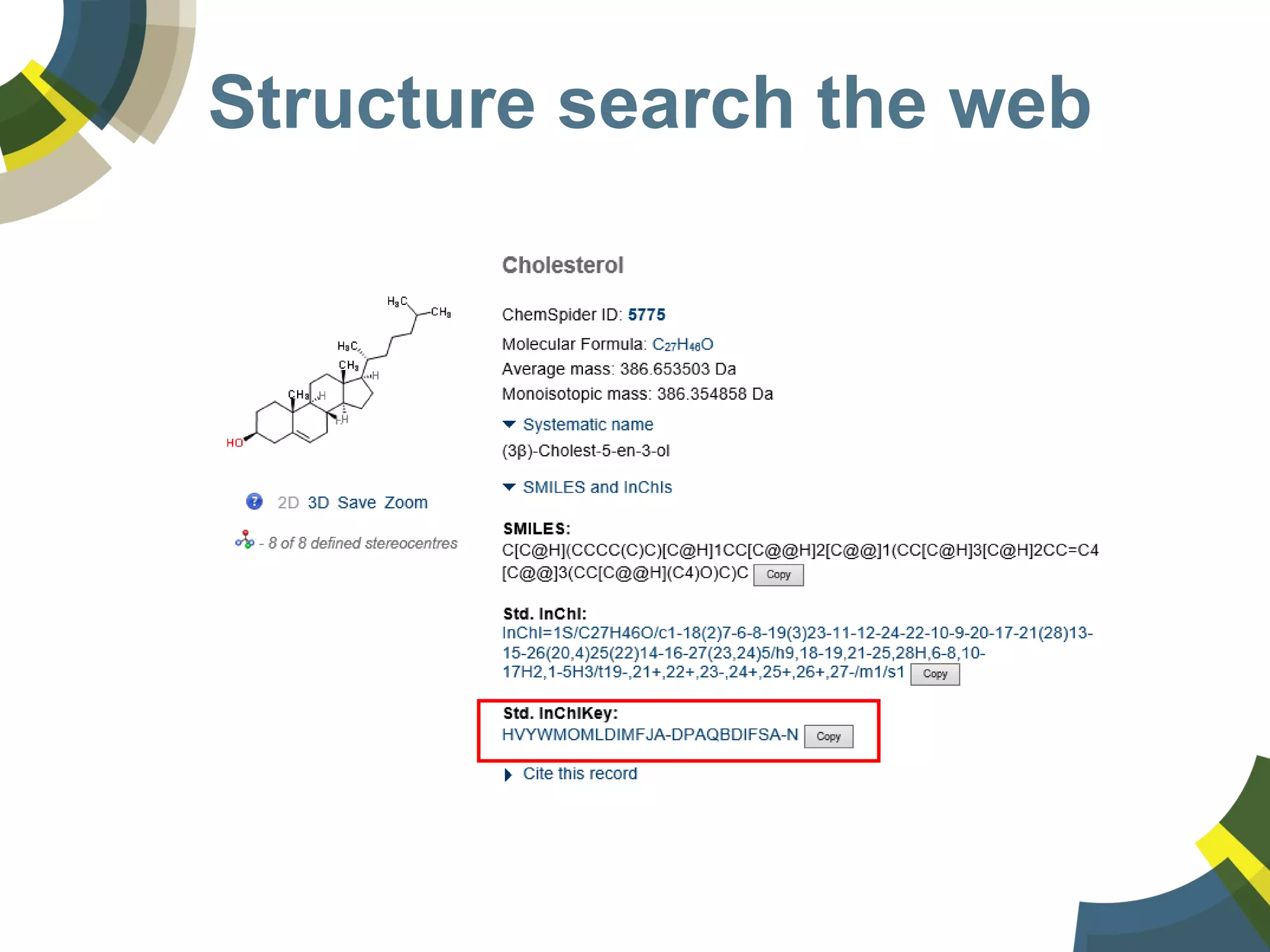
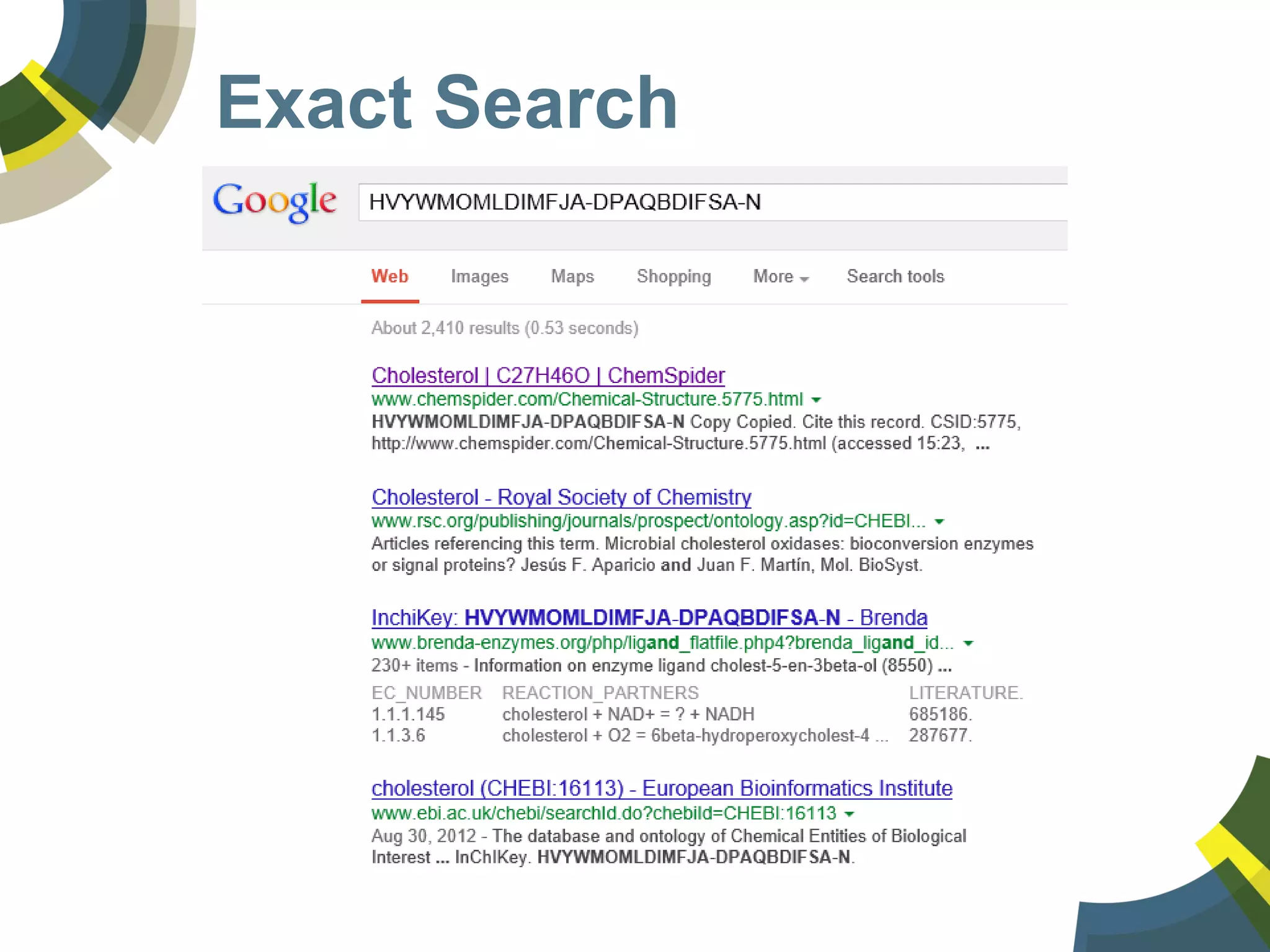
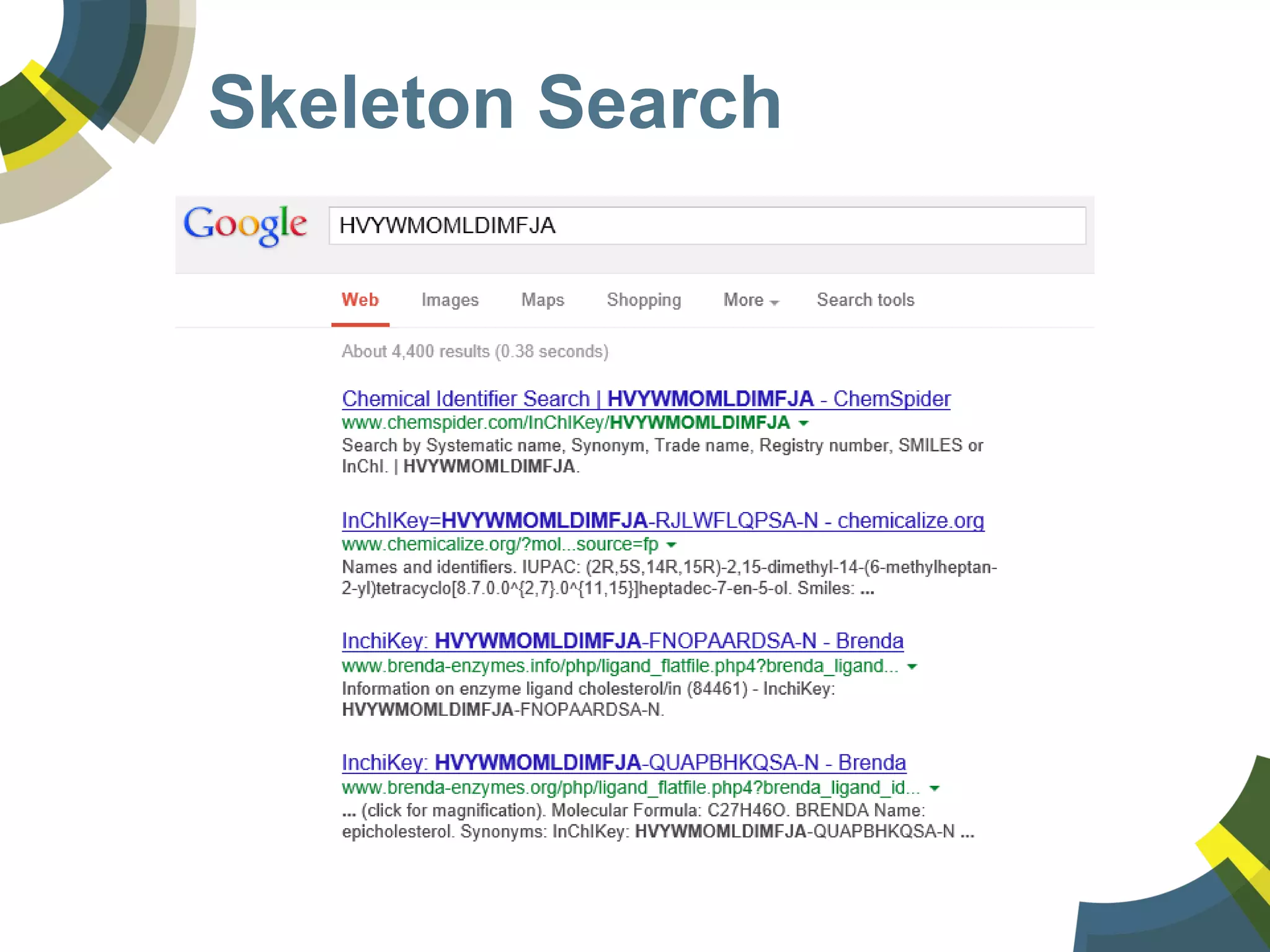


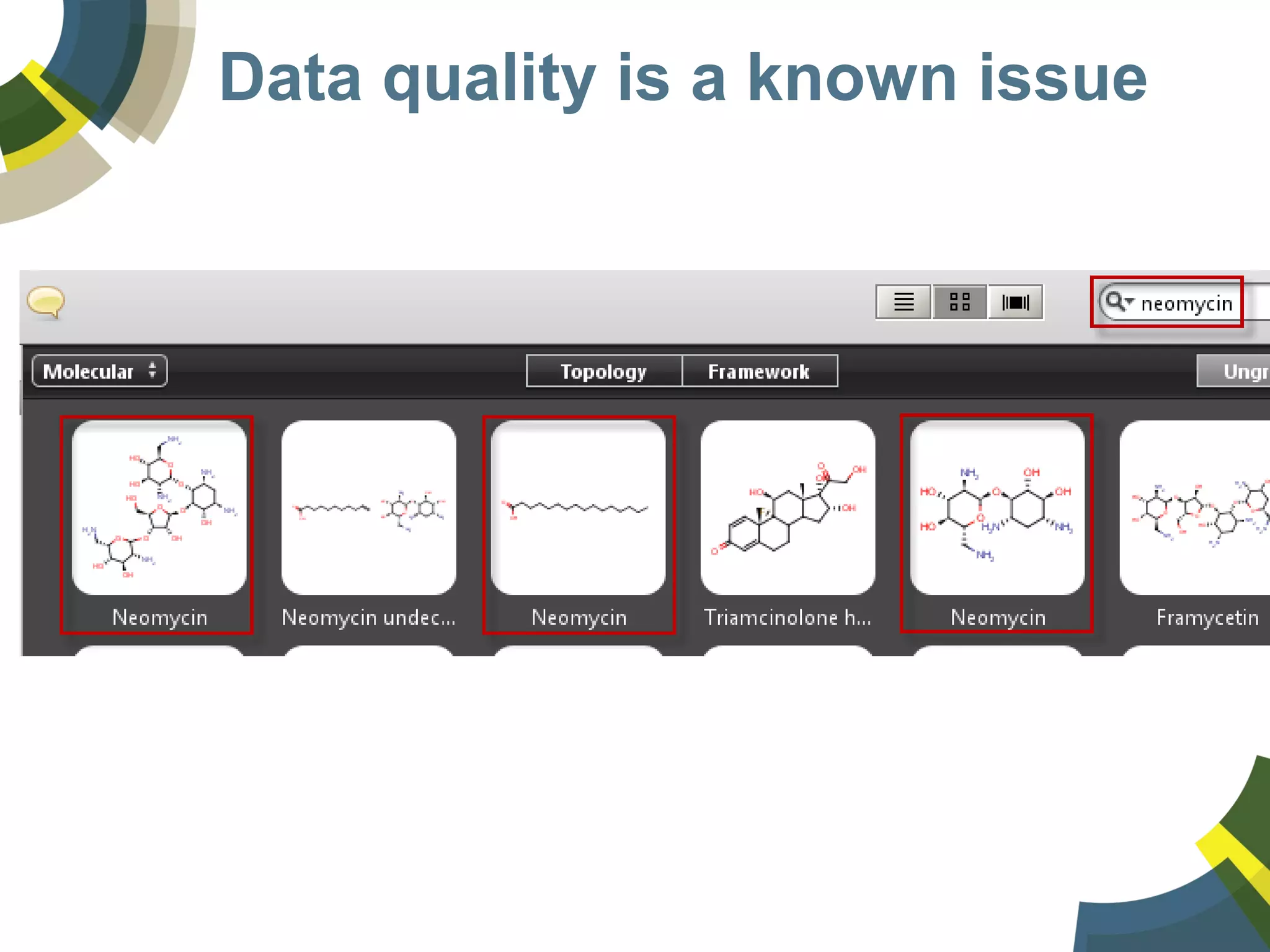
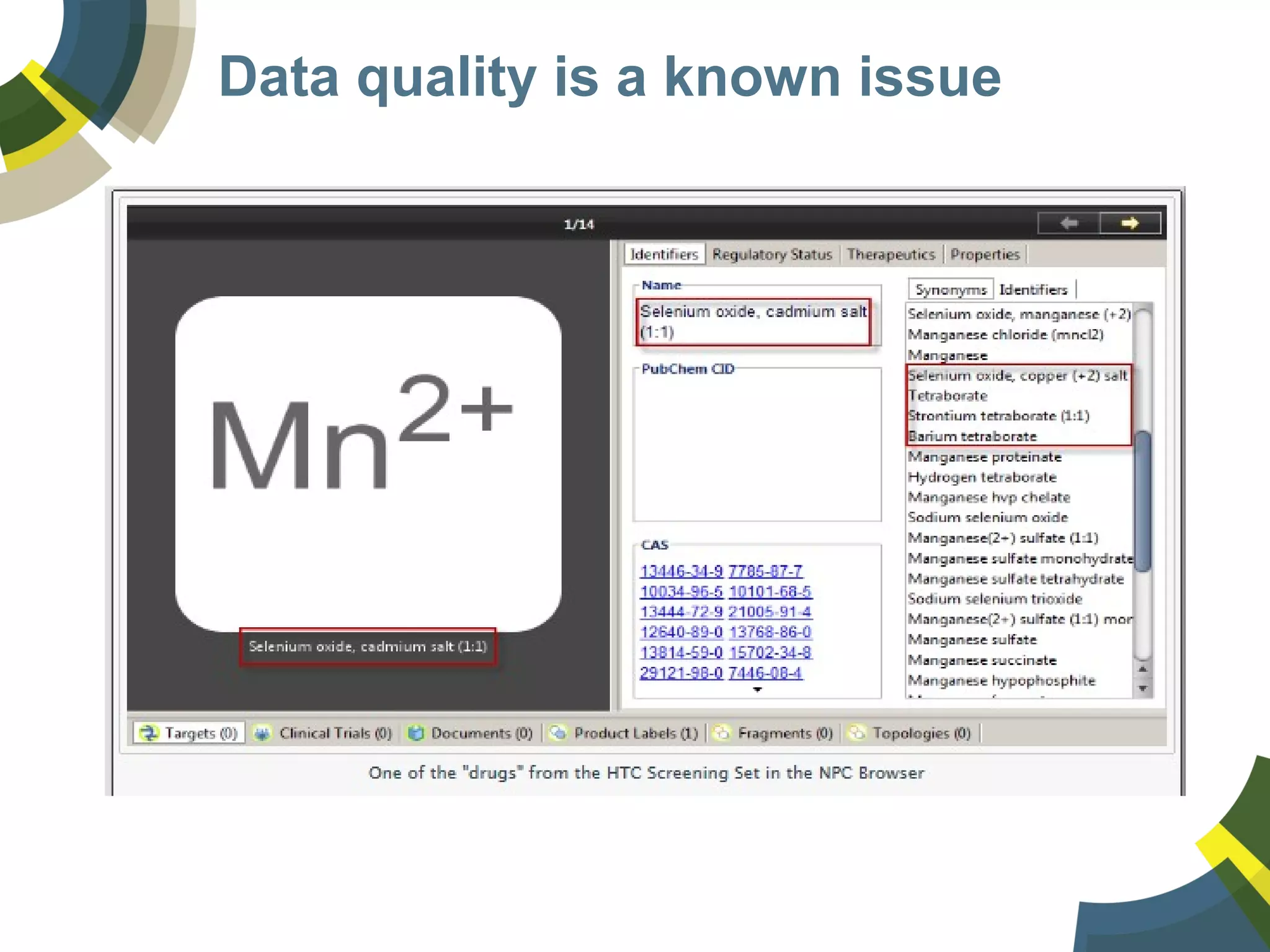
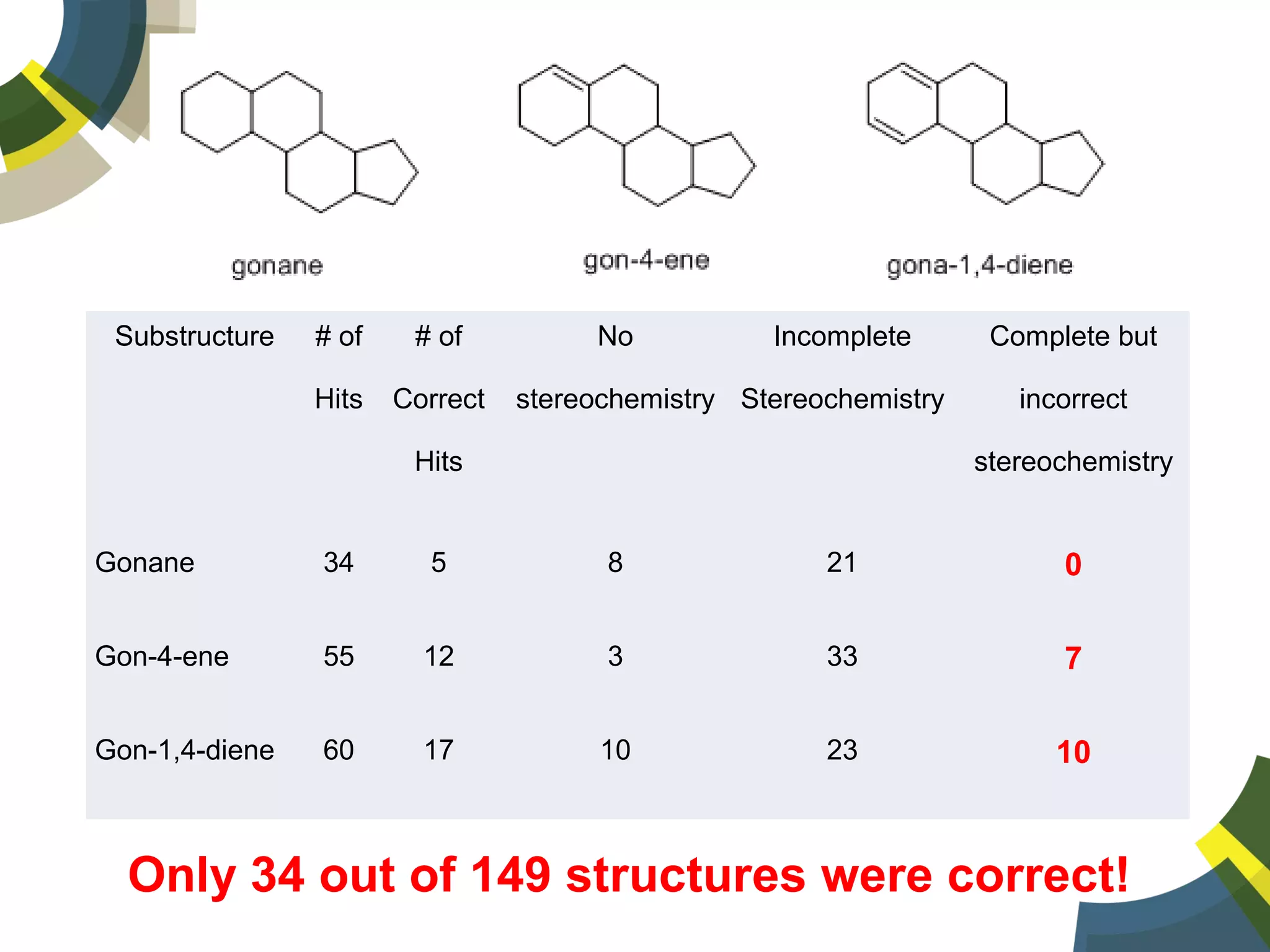
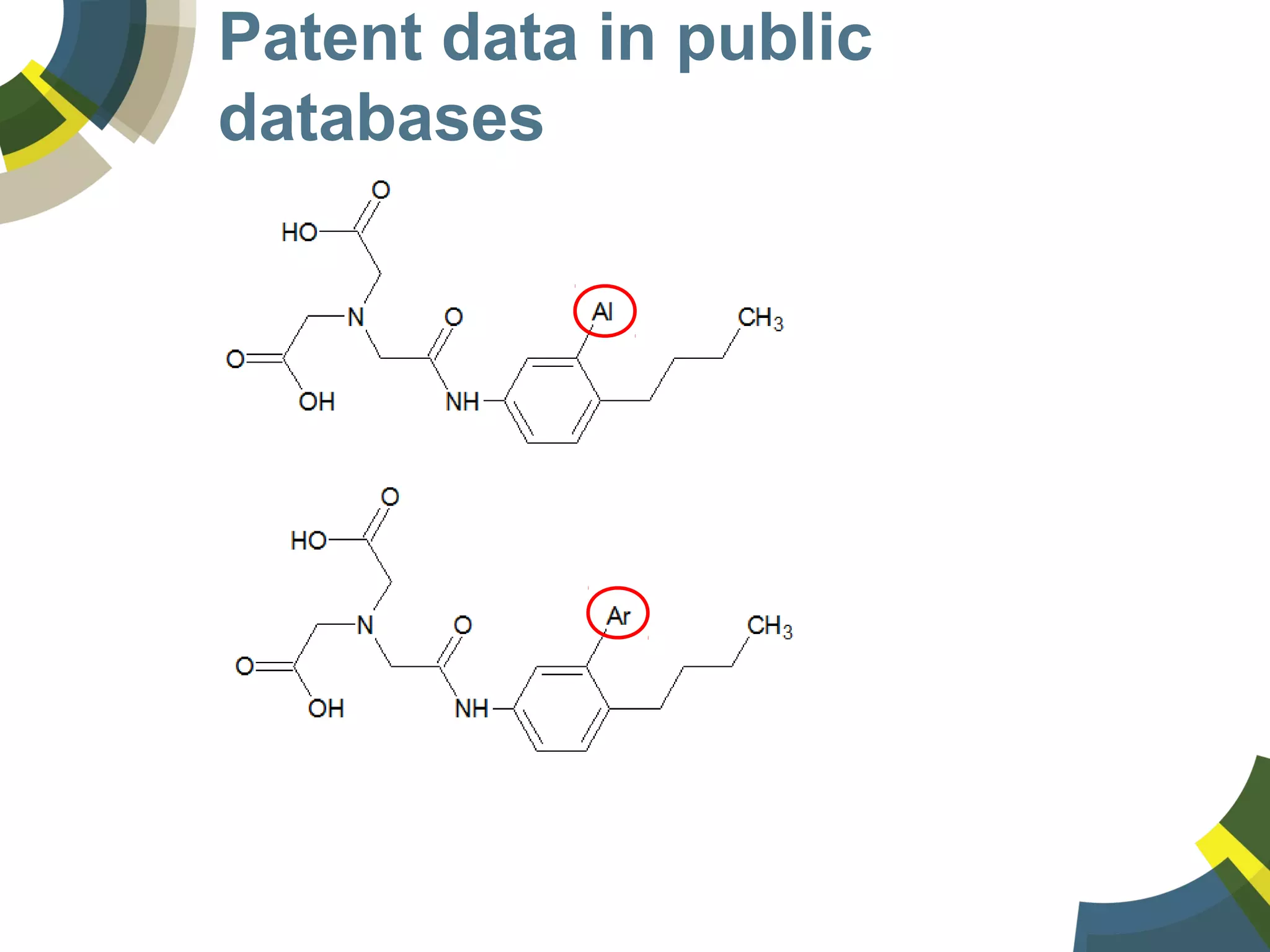
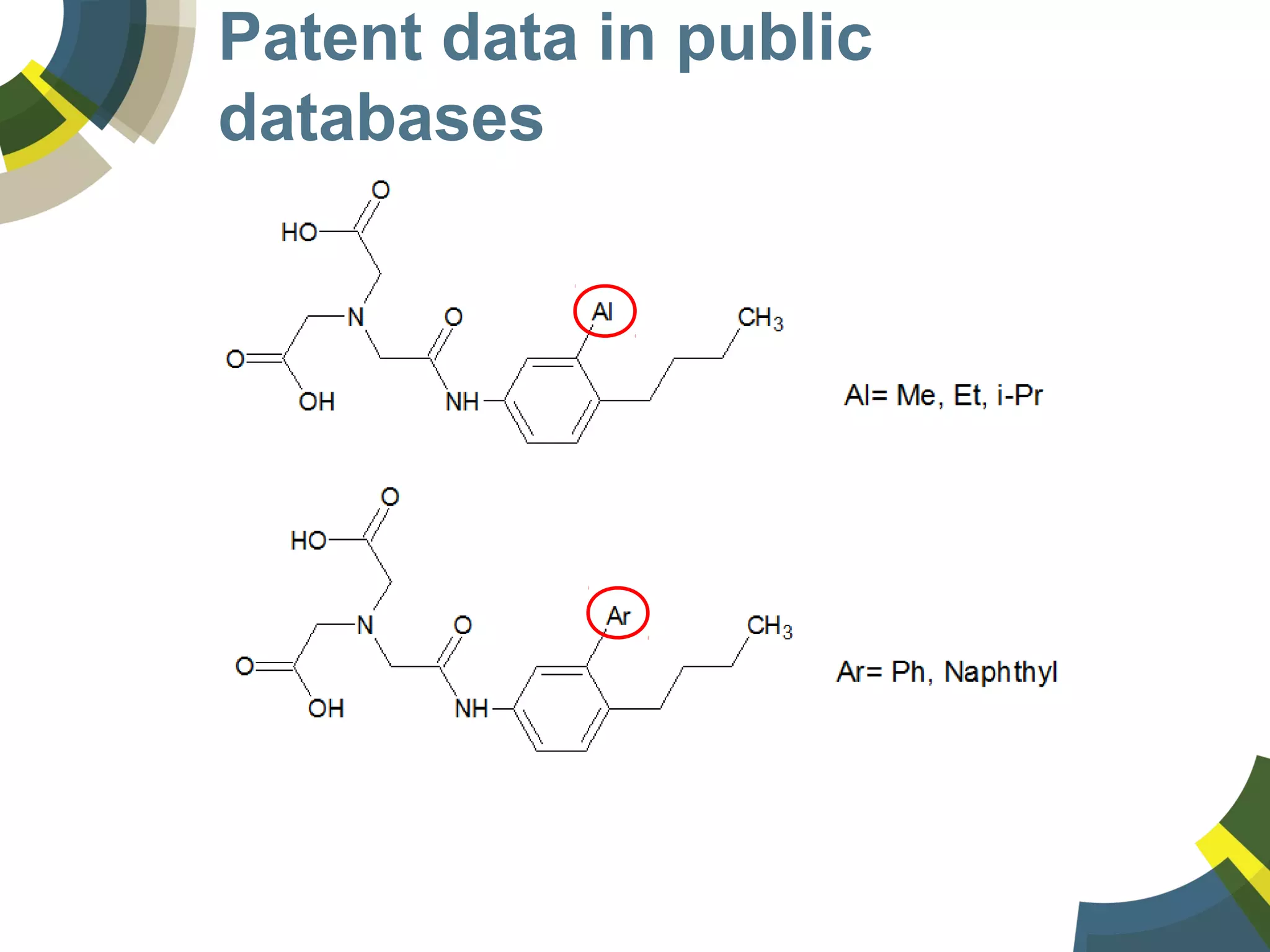


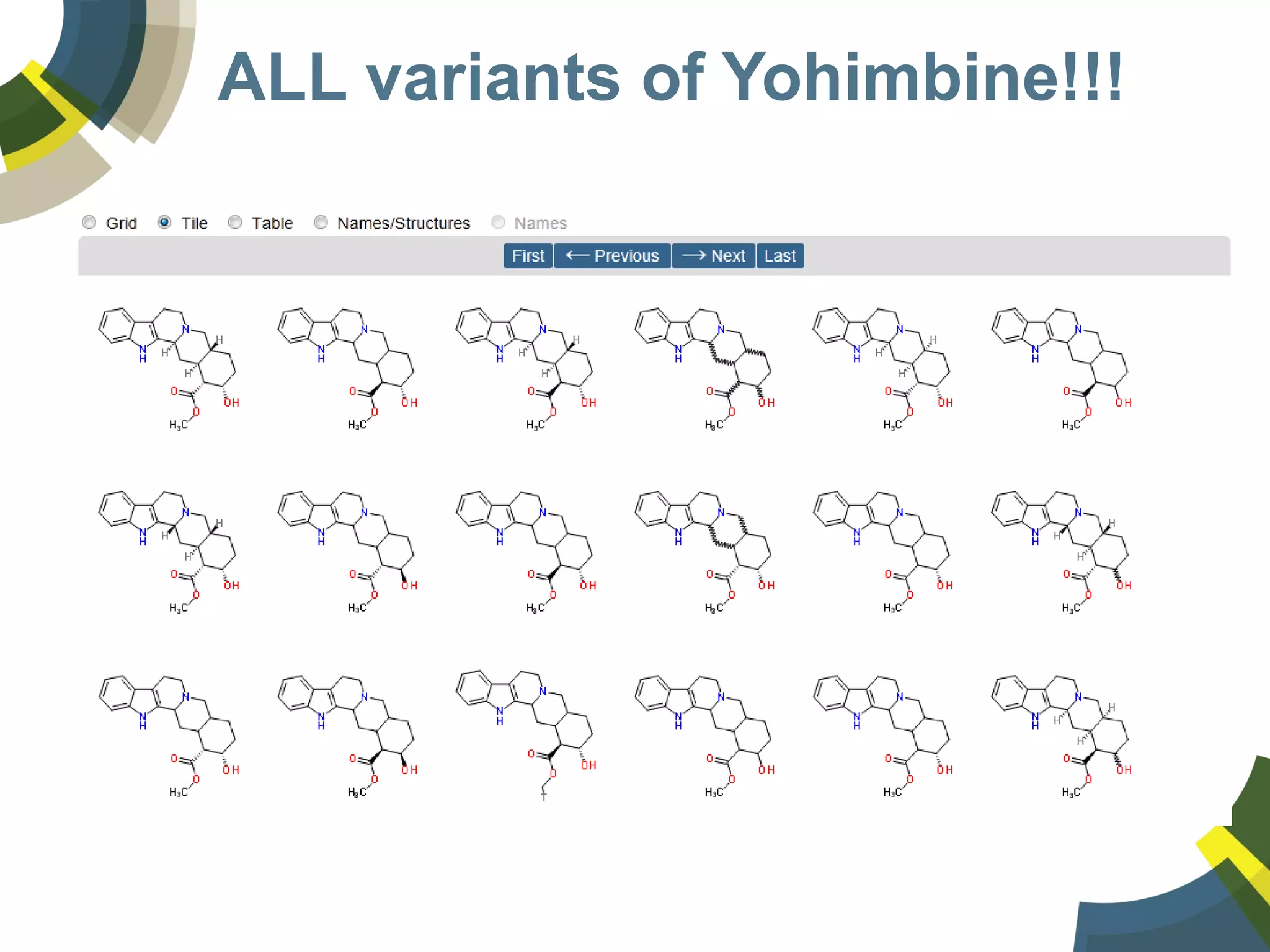
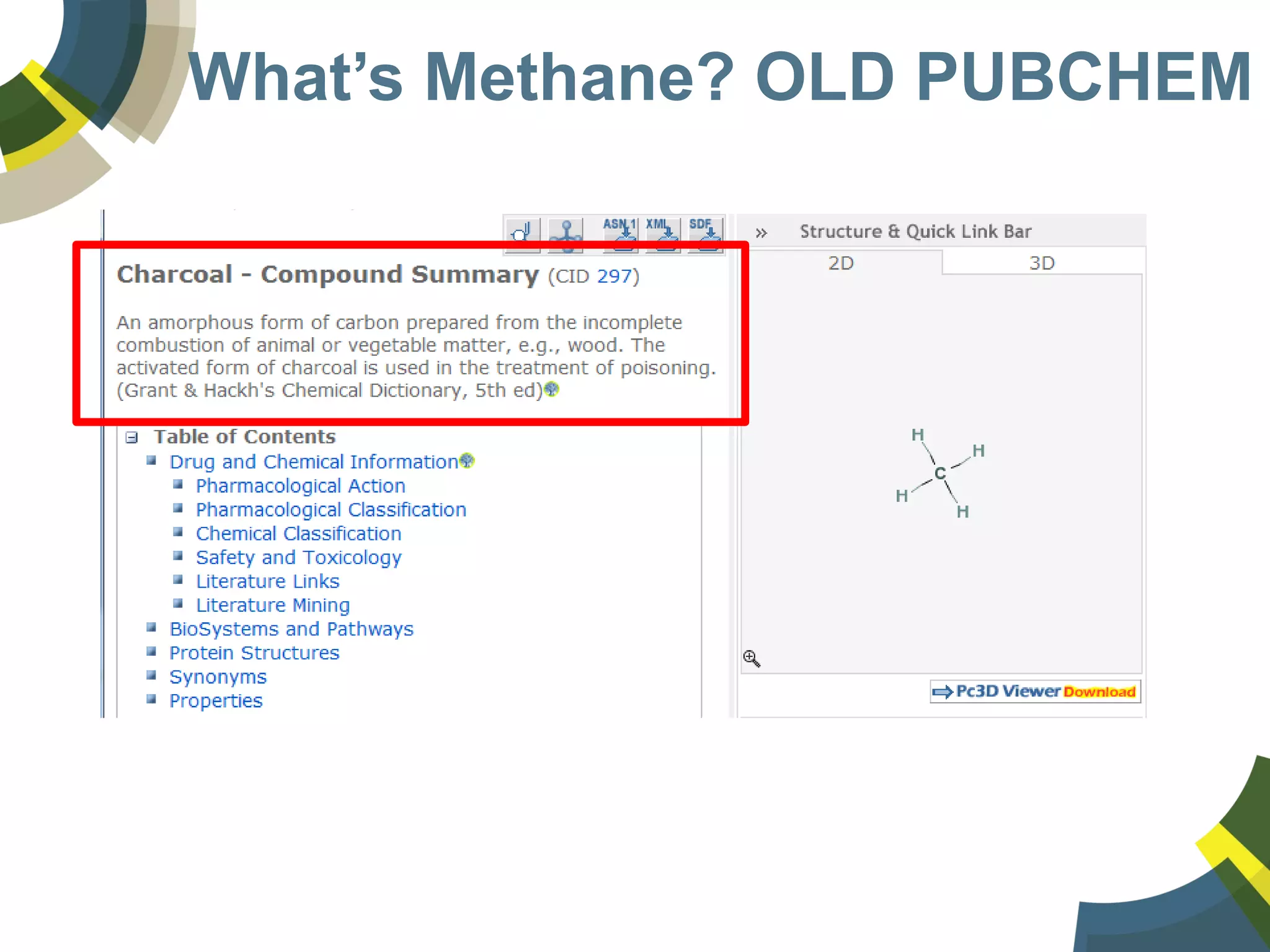


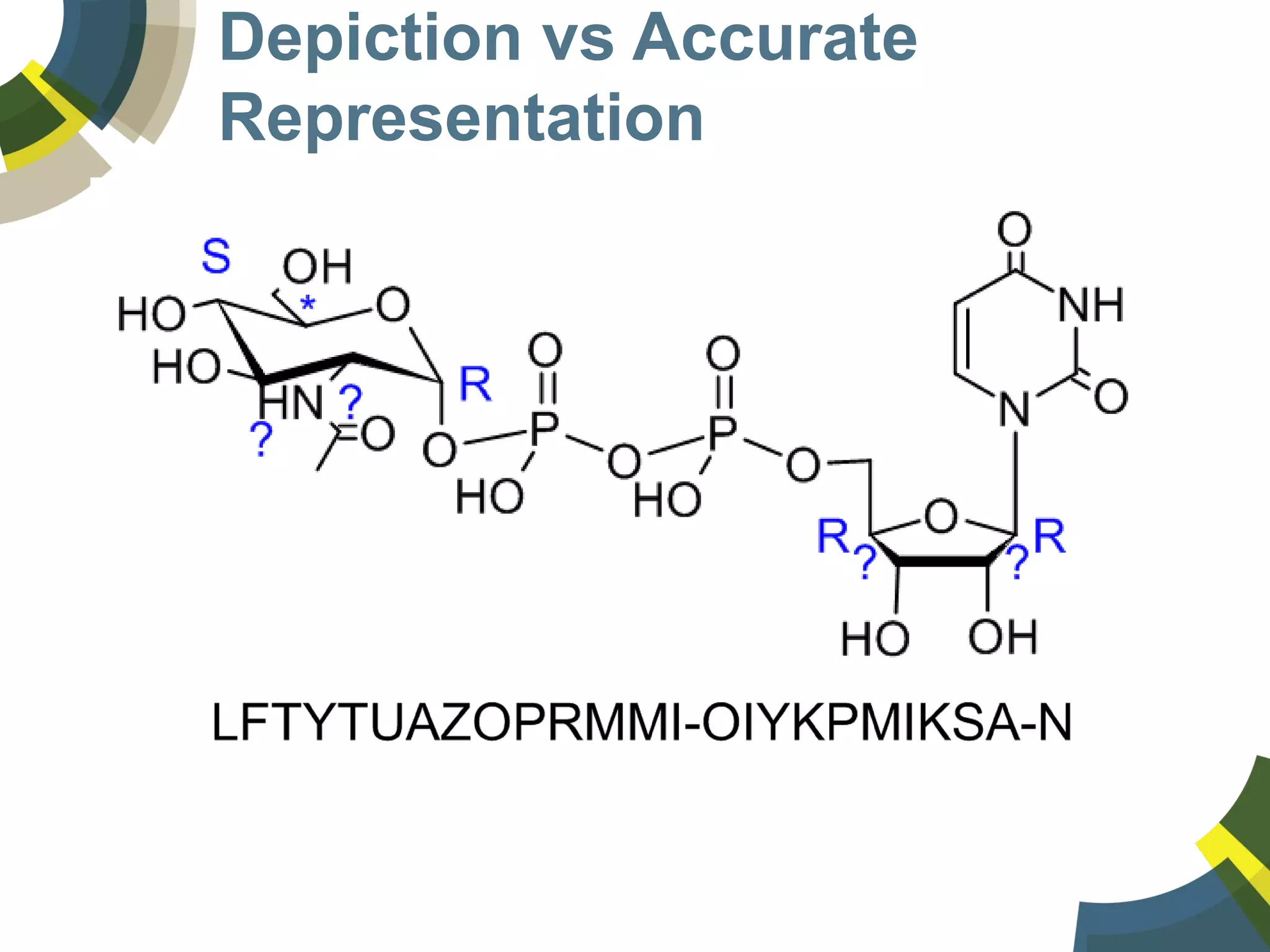
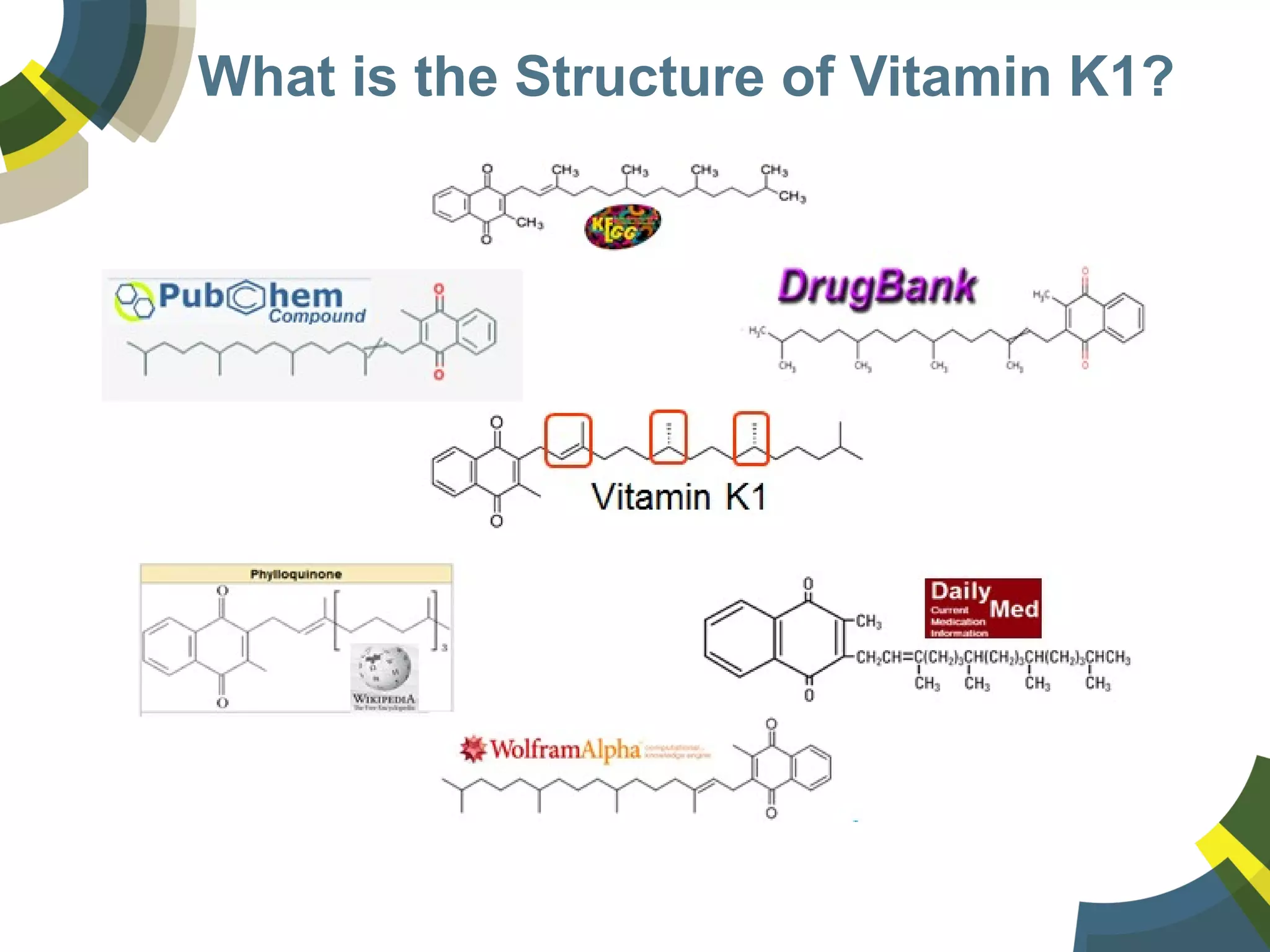






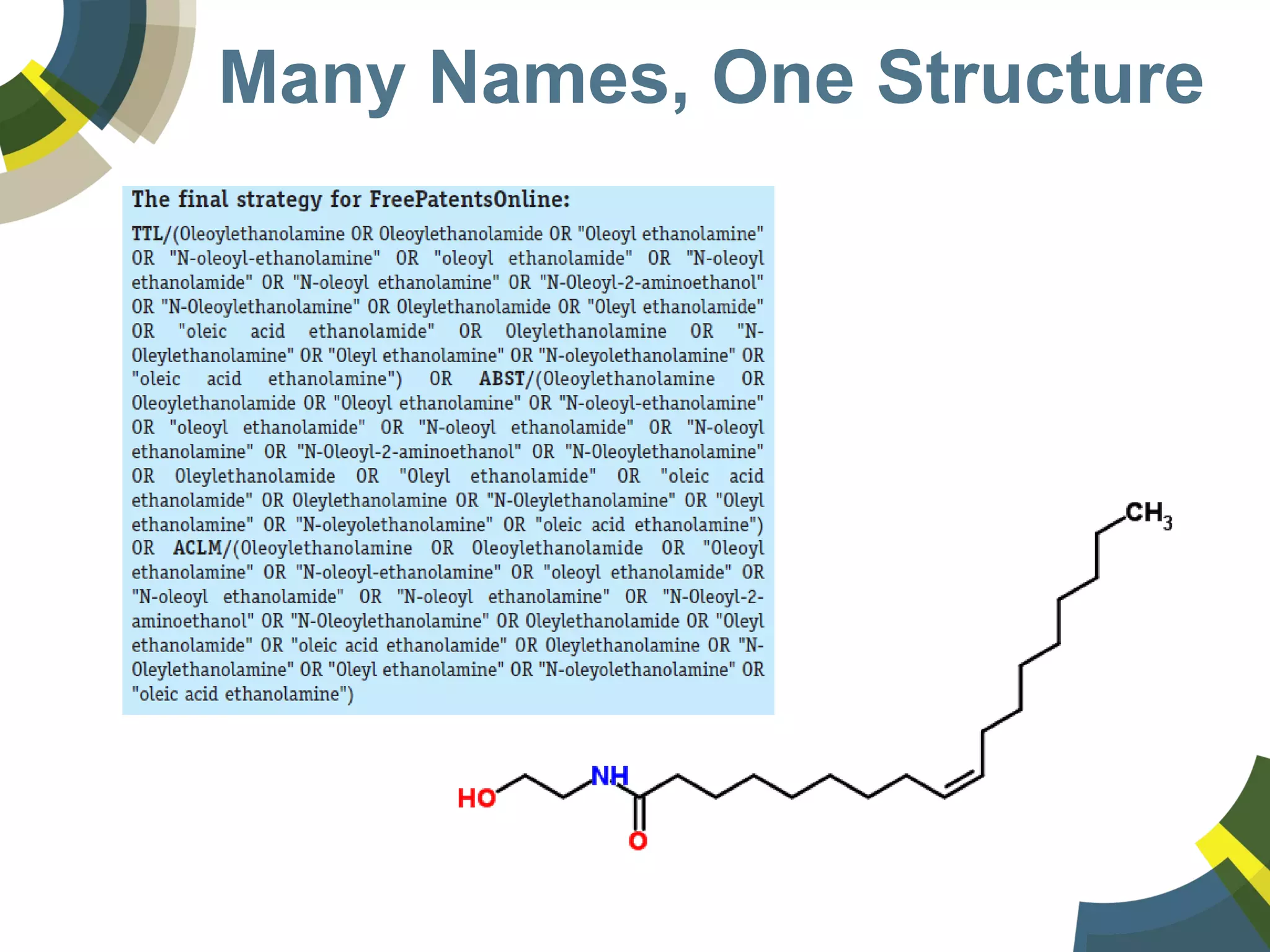
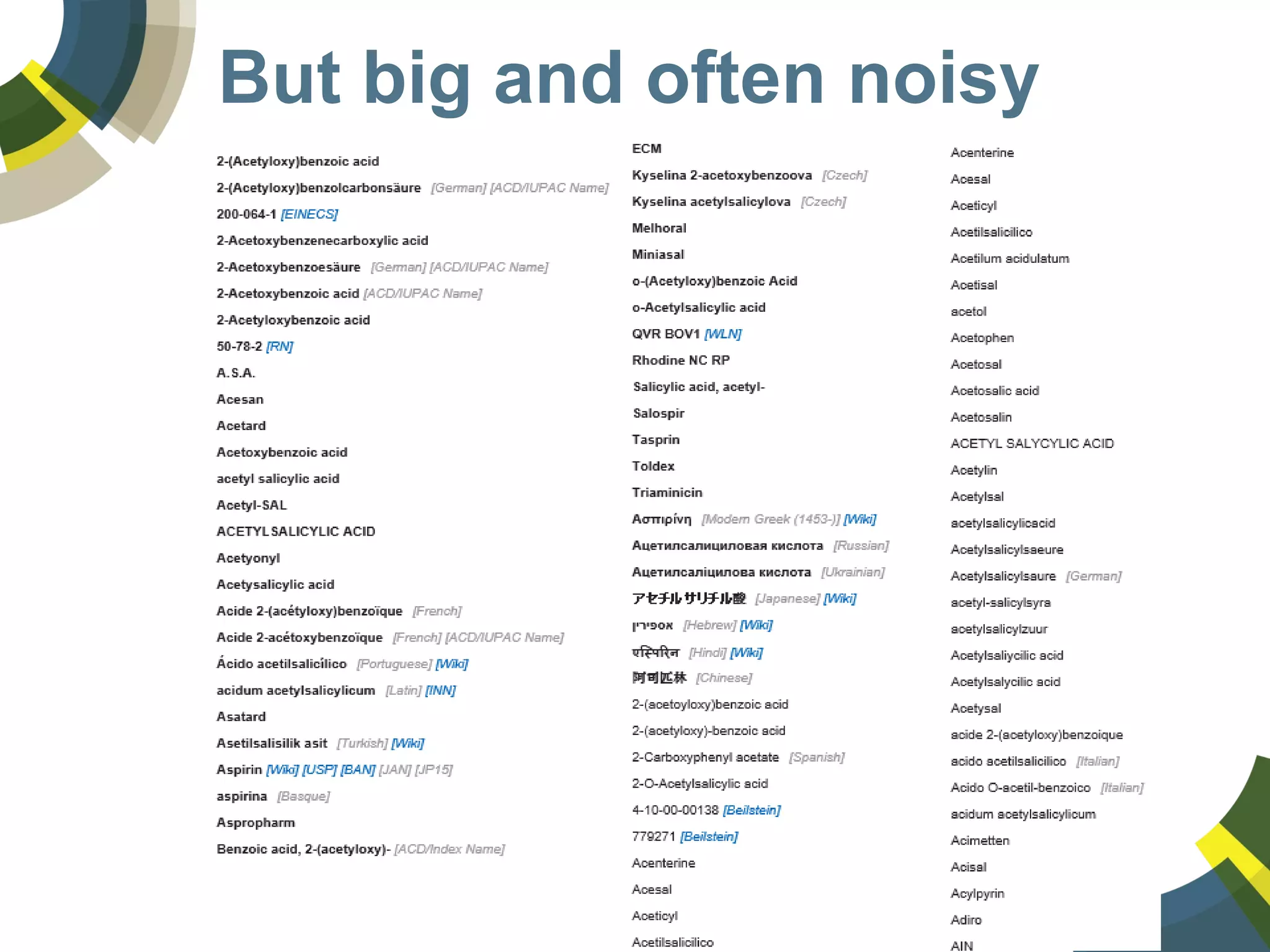
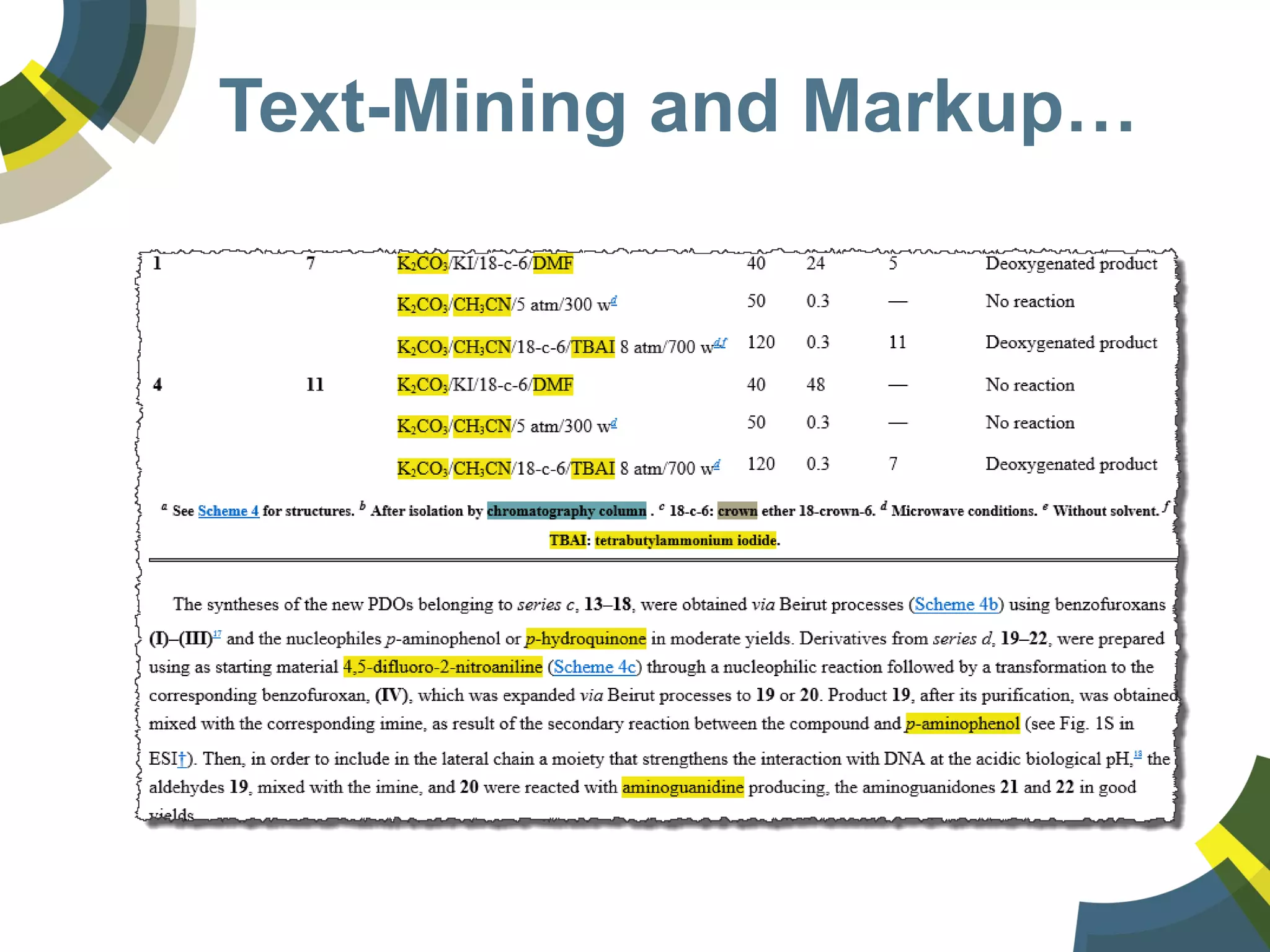

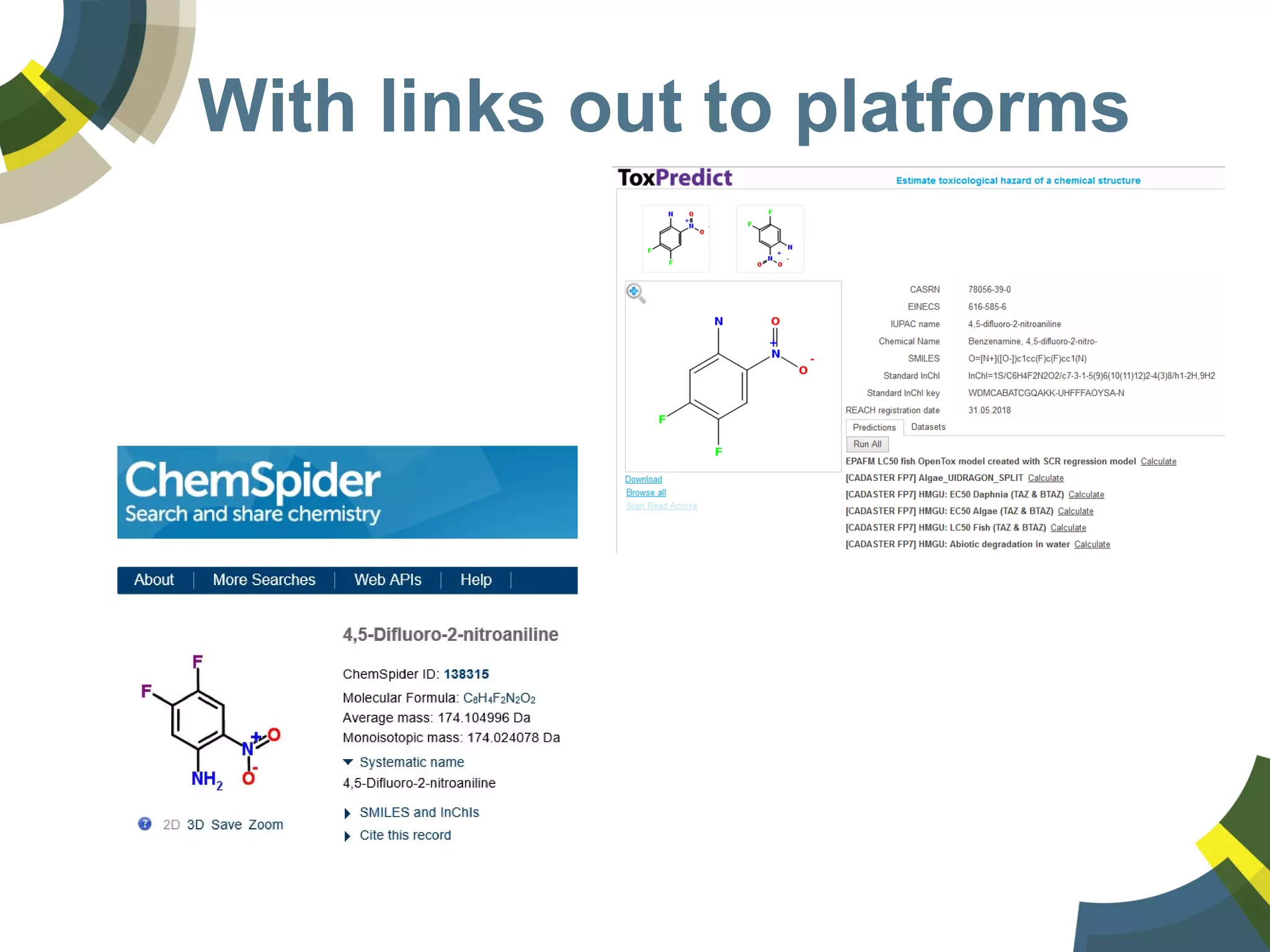



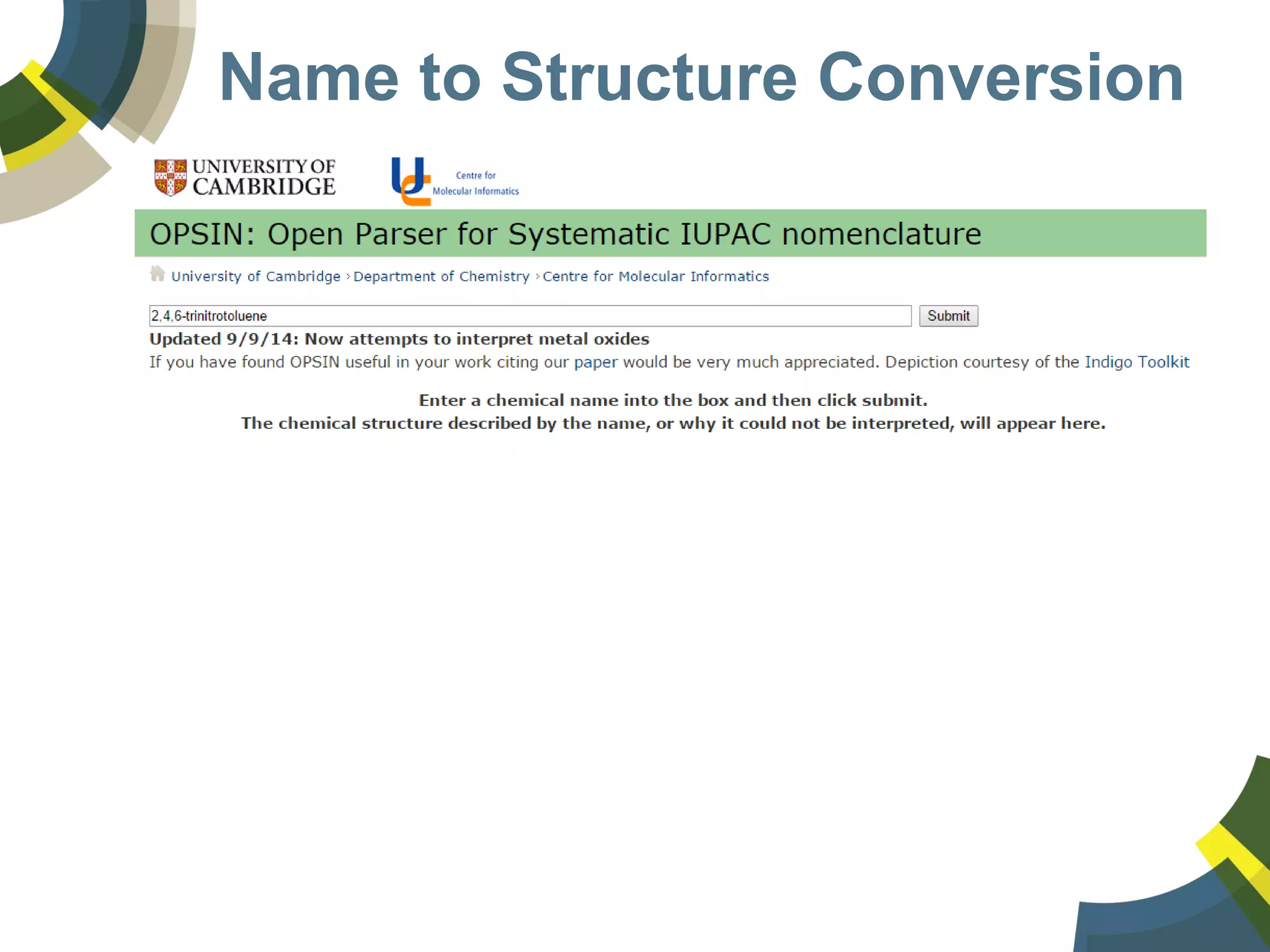



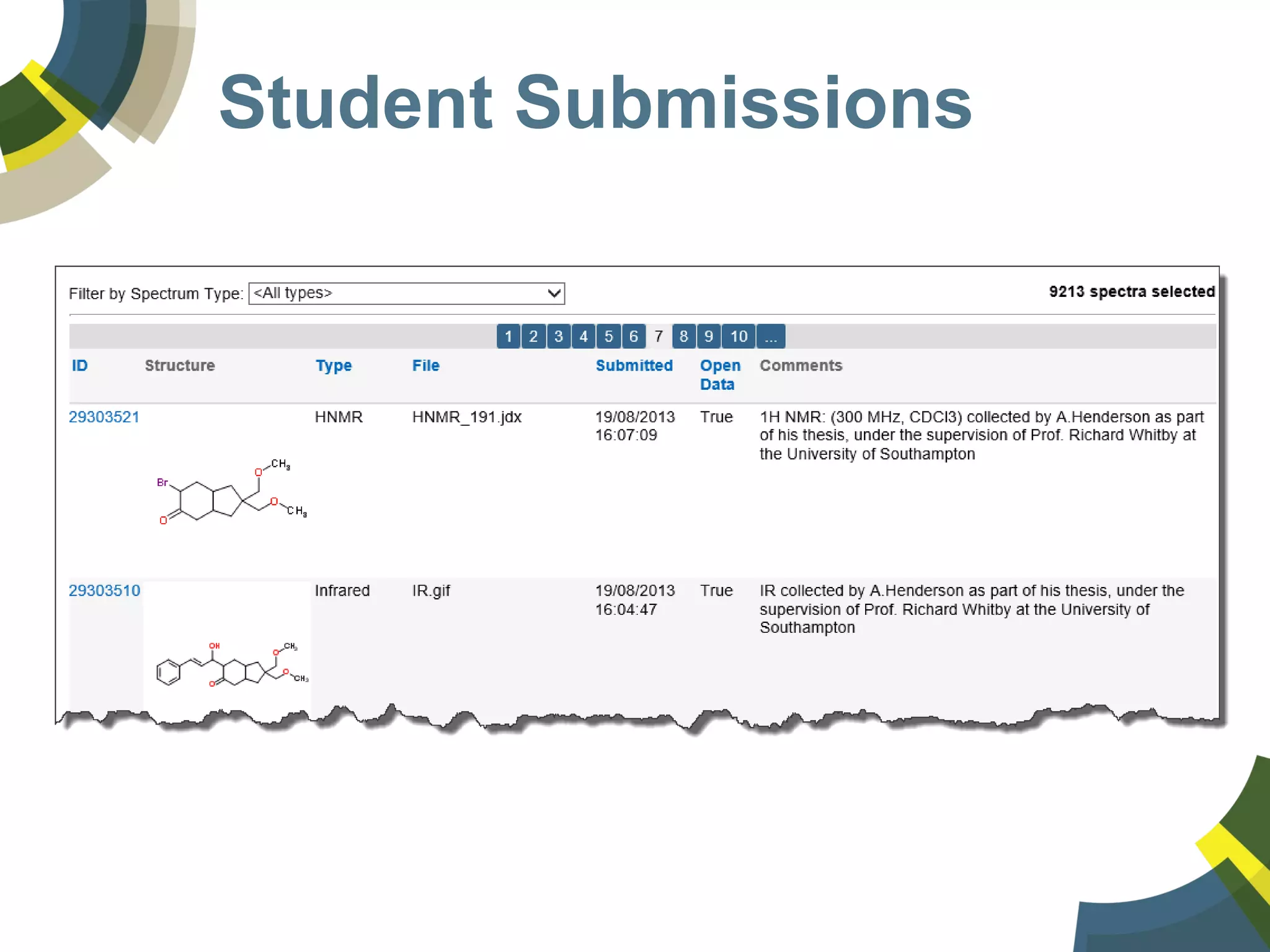
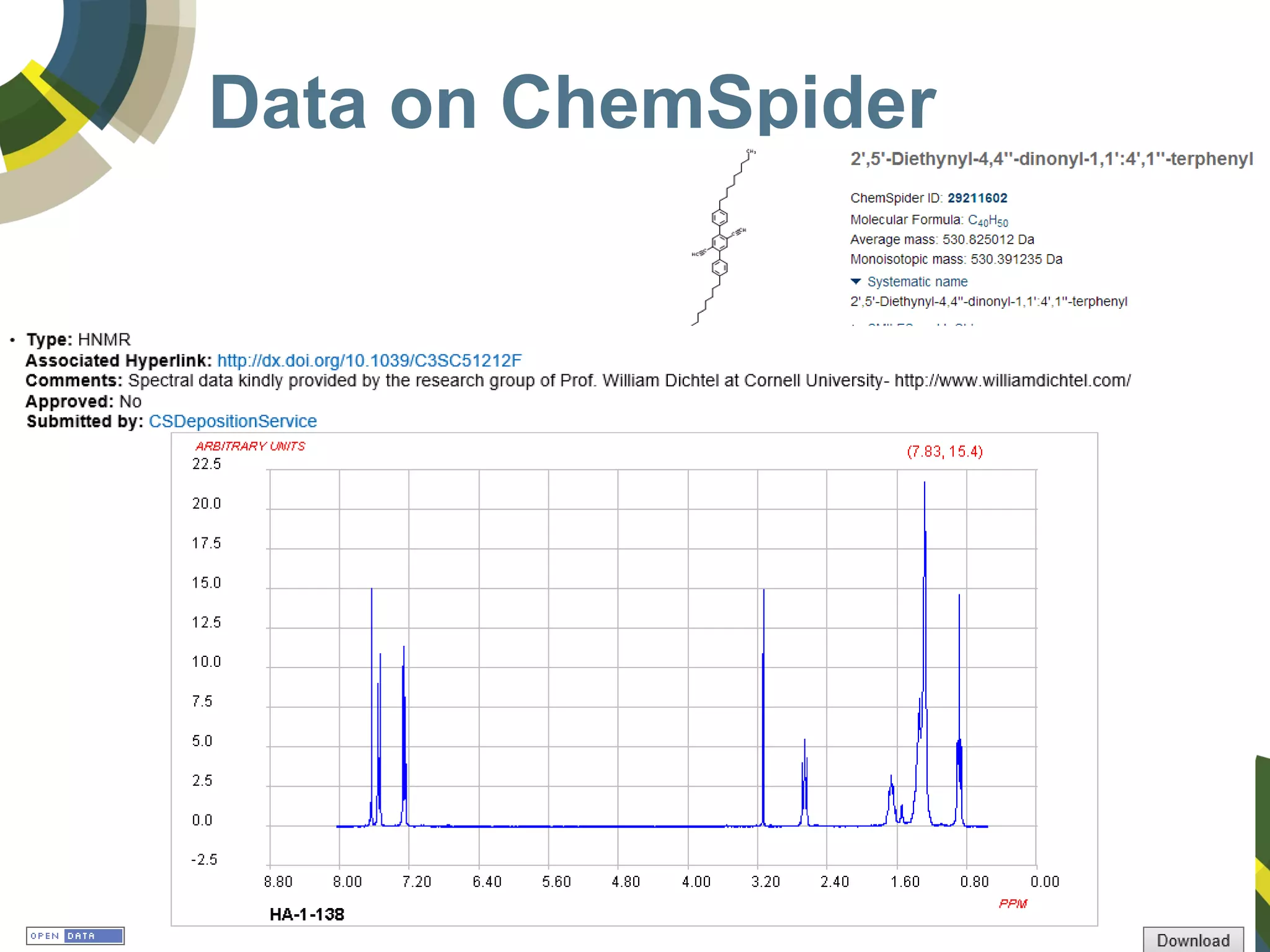
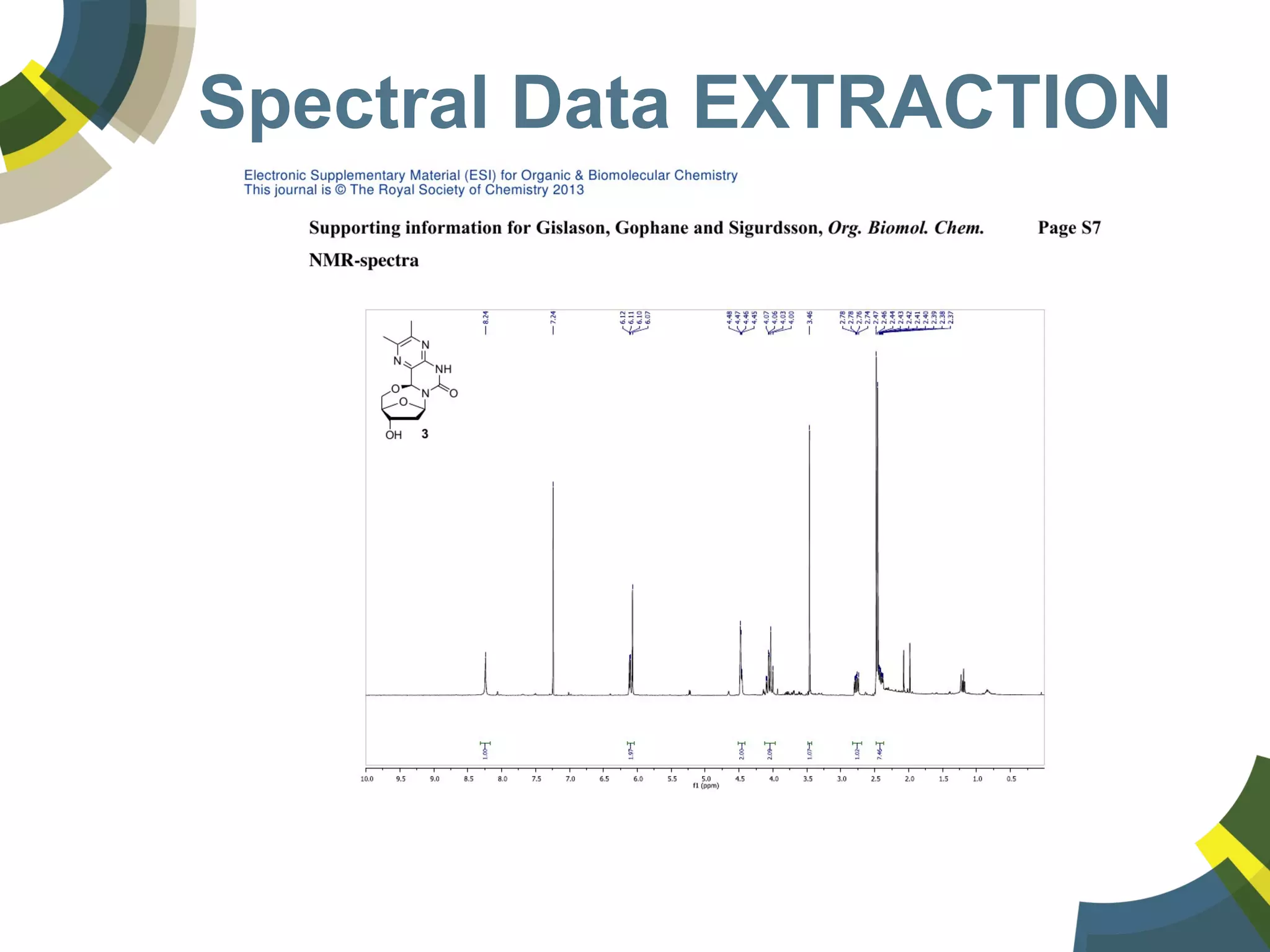
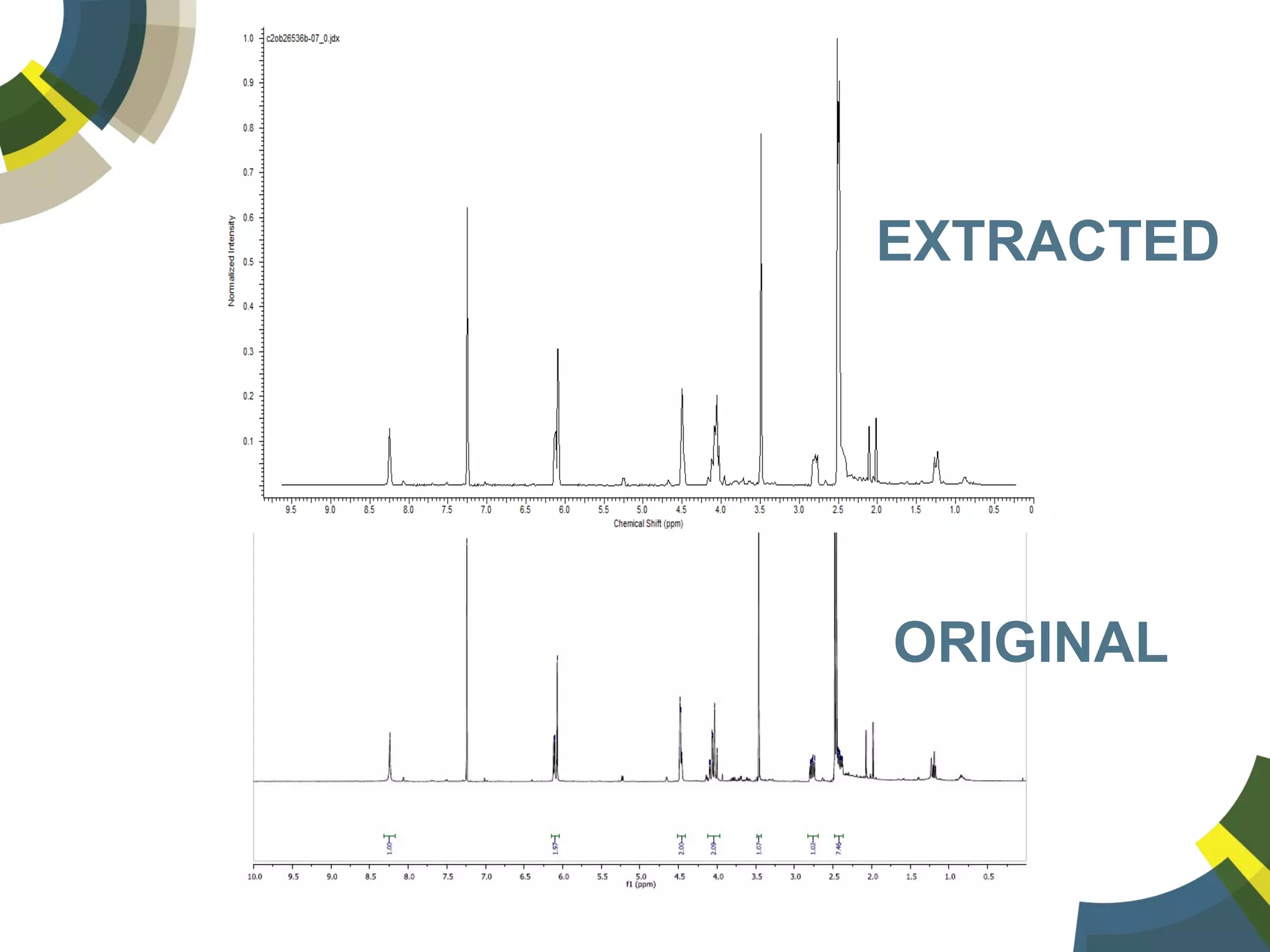



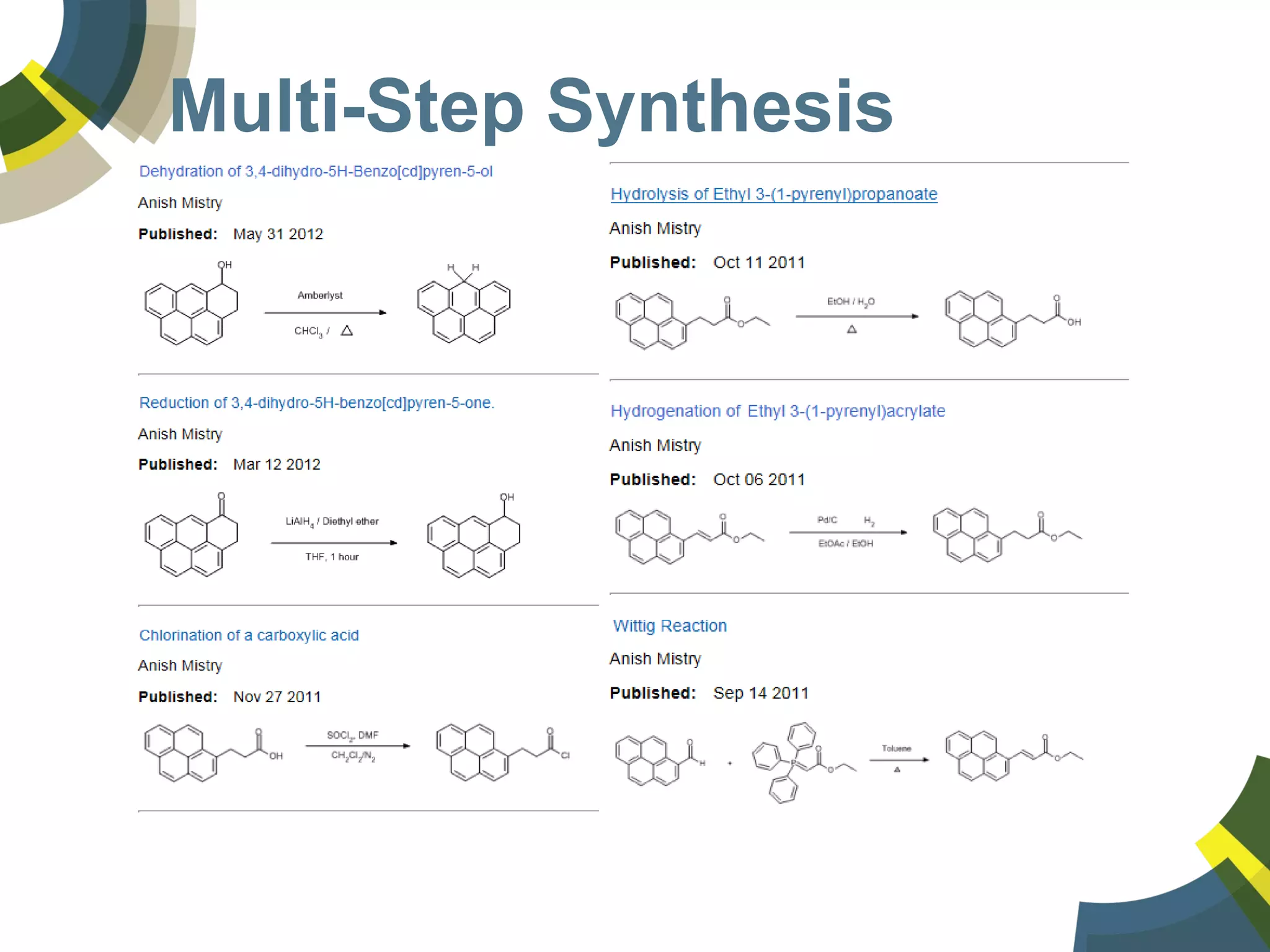
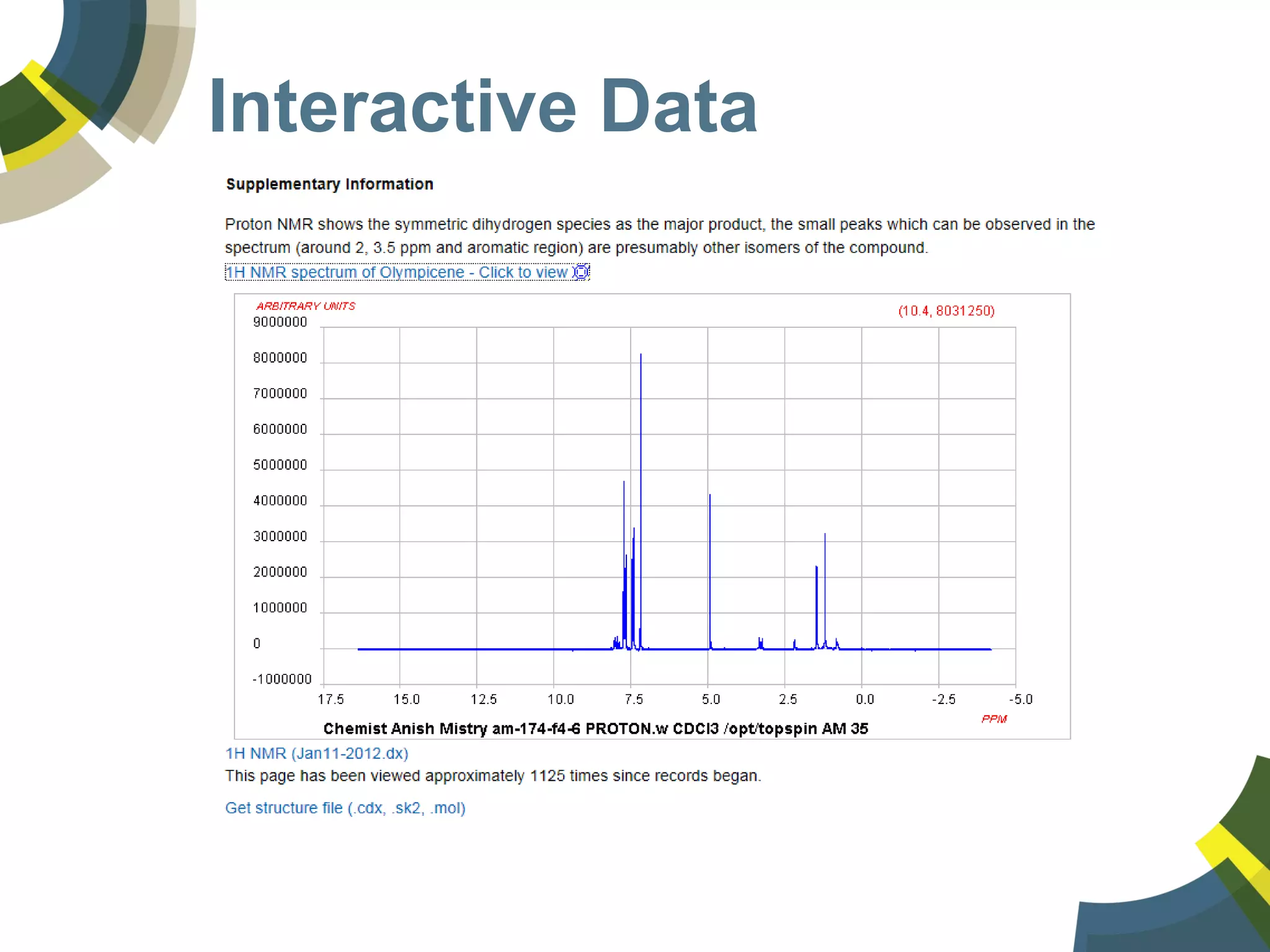





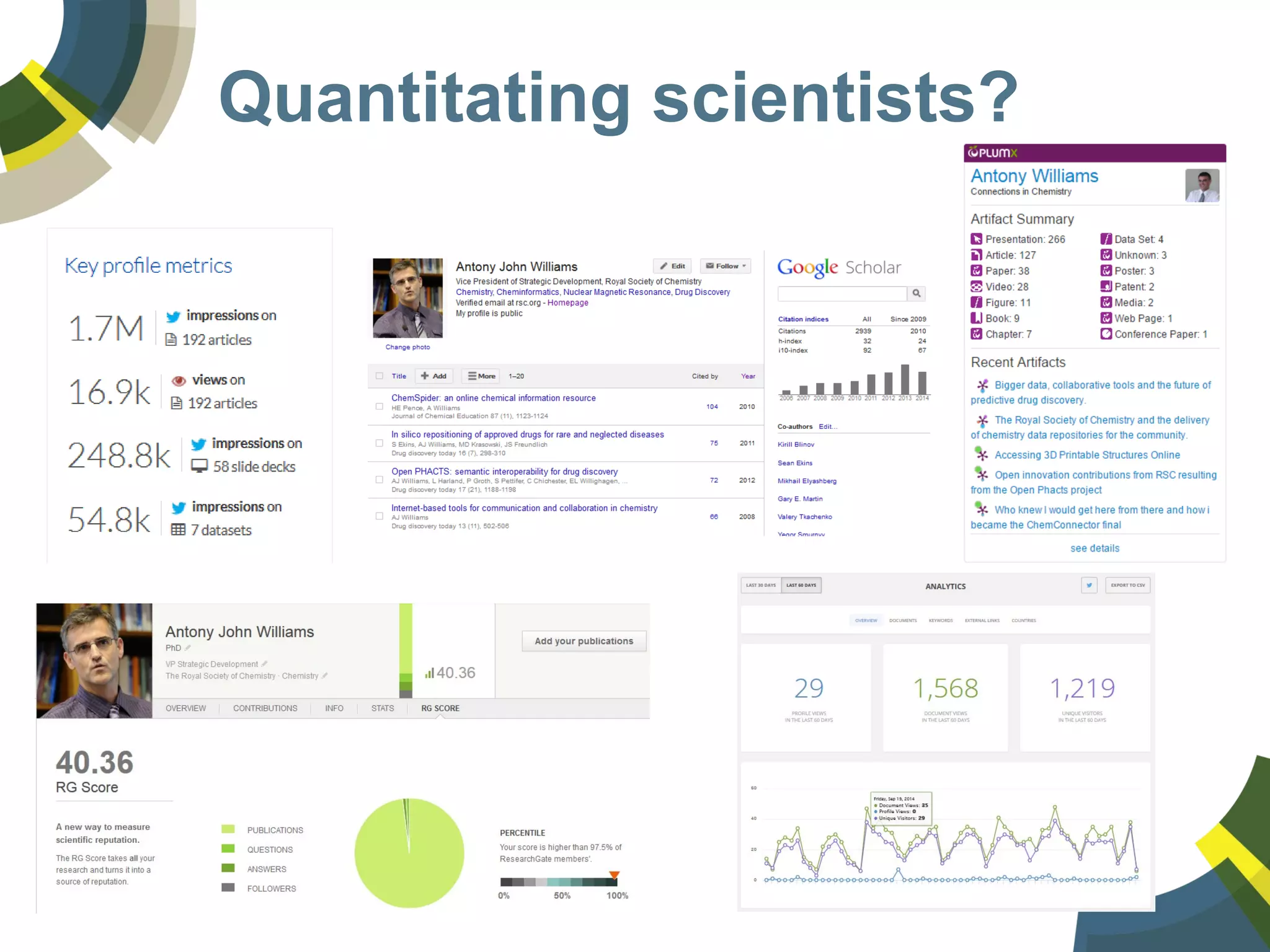



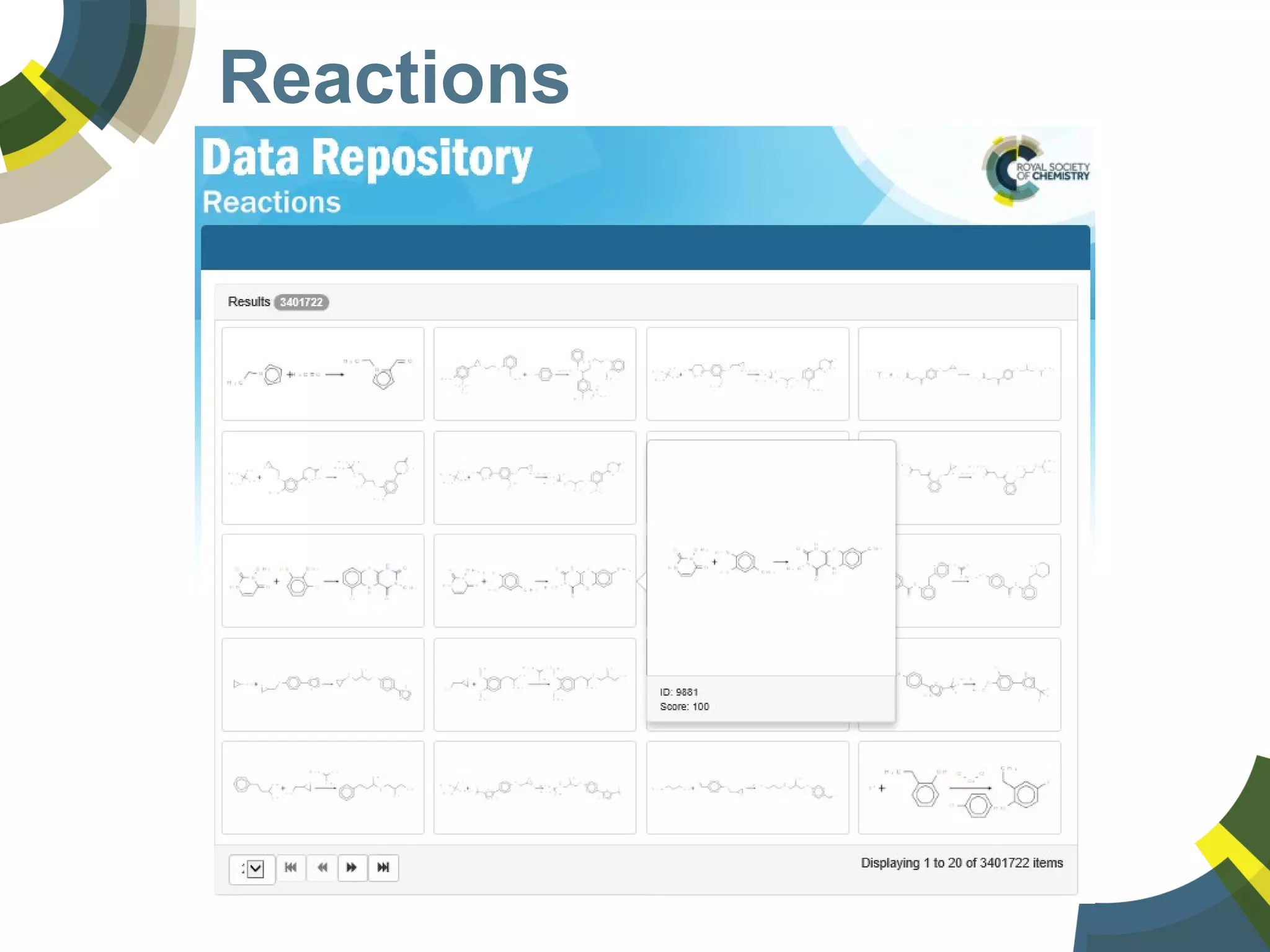







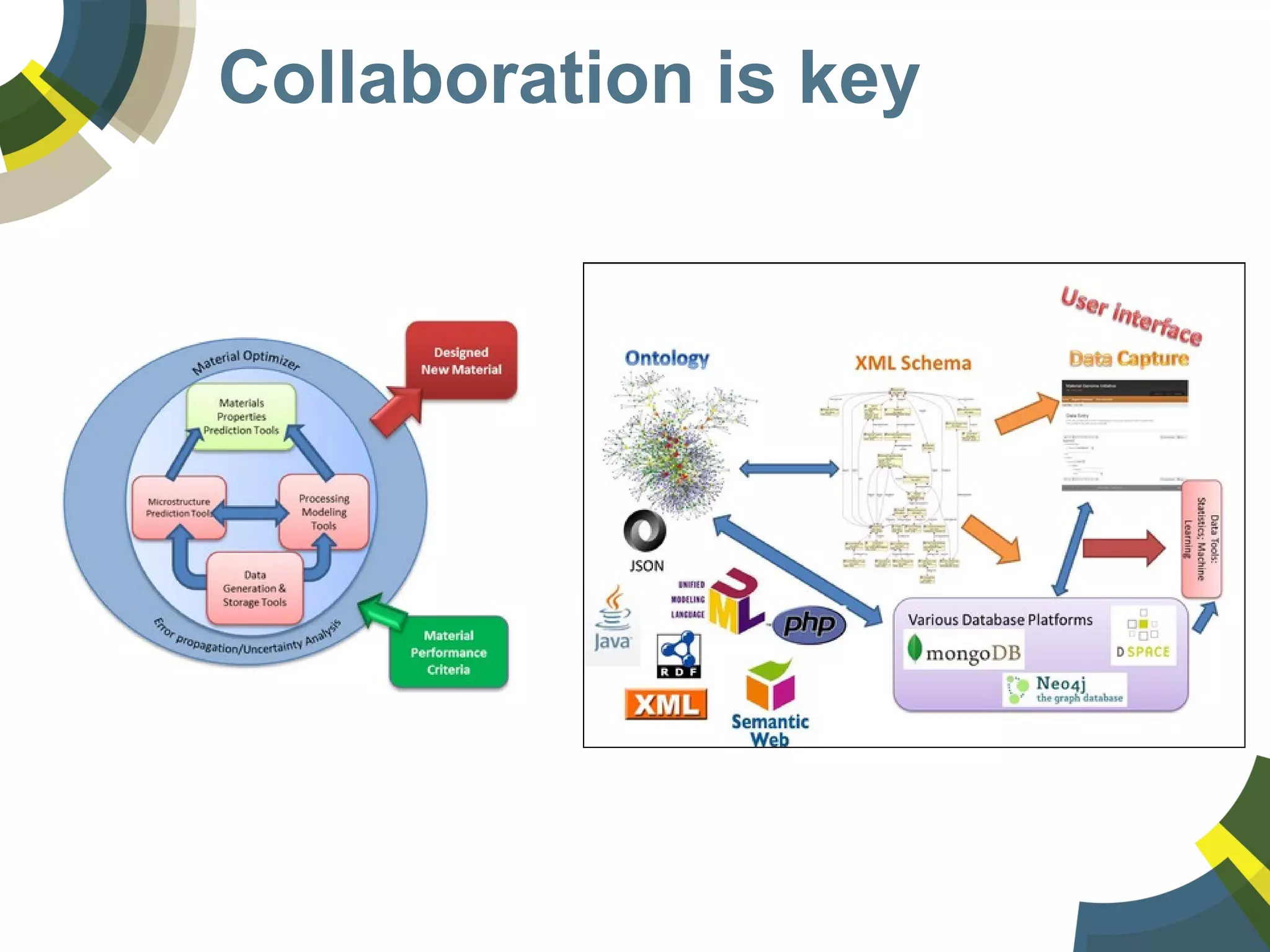
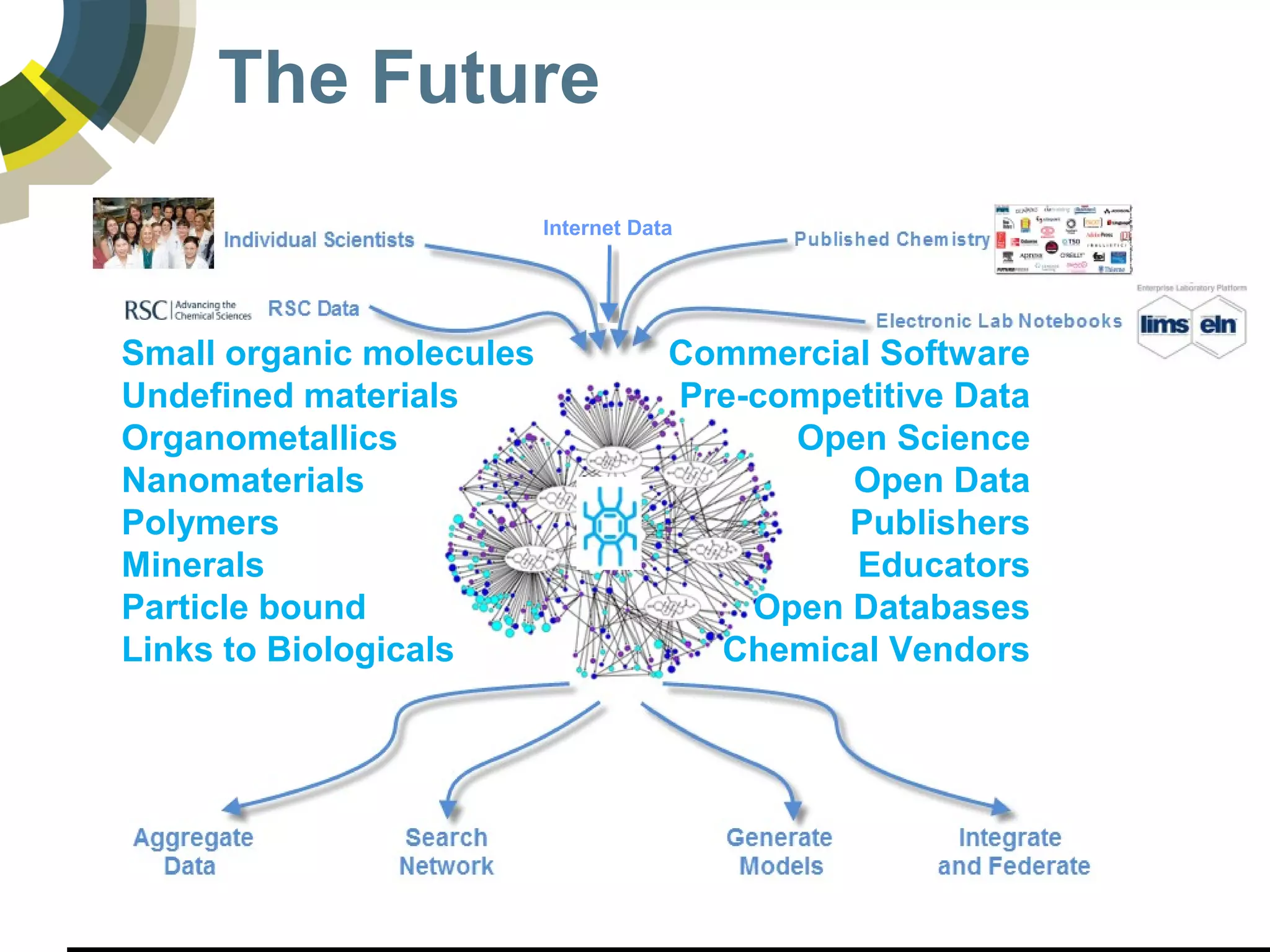

The document discusses challenges and opportunities in managing public domain chemical data online, emphasizing the need for integration and standardization across diverse chemical information sources. It highlights the role of platforms like ChemSpider in crowd-sourced curation and the importance of accurate data representation for effective chemical research and discovery. Additionally, it explores the shift towards open data in science, seeking collaboration and improved data quality to better serve the scientific community.



































































