Download as PDF, PPTX



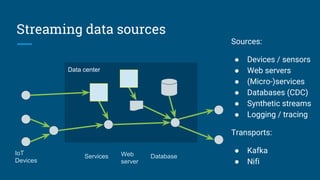
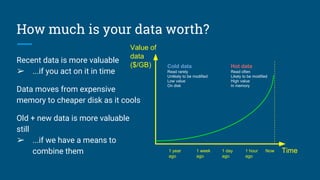









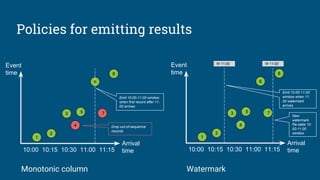




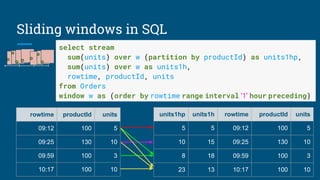




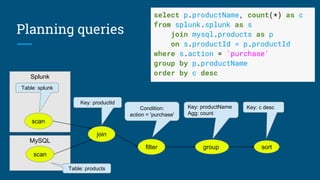
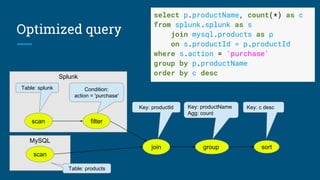

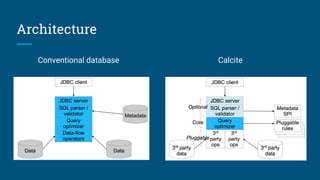










The document discusses the significance and features of streaming SQL, emphasizing its role in querying streams and managing real-time data analytics. It highlights the need for a standardized approach to streaming SQL, as well as various SQL functionalities that facilitate the combination of streaming and relational data. The presentation also covers the architecture and optimization techniques relevant to streaming queries, supported by technologies like Apache Calcite and various streaming frameworks.





































































































