Download as PDF, PPTX





























![Thank you!
@julianhyde
@ApacheCalcite
http://calcite.apache.org
http://calcite.apache.org/docs/stream.html
“Data in Flight”, Communications of the ACM, January 2010 [article]](https://image.slidesharecdn.com/calcite-streaming-sql-kafka-summit-2016-160427165819/85/Streaming-SQL-36-320.jpg)

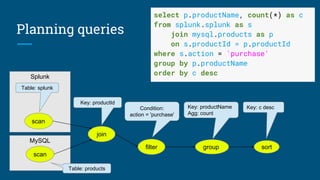
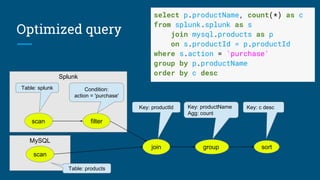
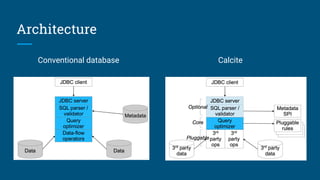
The document discusses Streaming SQL, emphasizing its role in managing and querying streaming data alongside traditional relational data. It details query planning, the duality of streams and tables, and the importance of time-sensitive data, while also covering different windowing techniques and aggregation methods. Additionally, it highlights the need for optimizing streaming queries to achieve high-quality results in real-time applications.











































































































