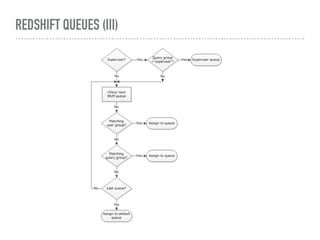
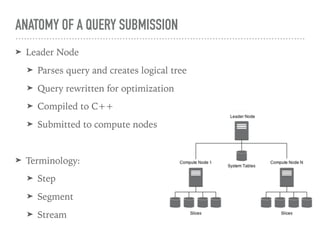
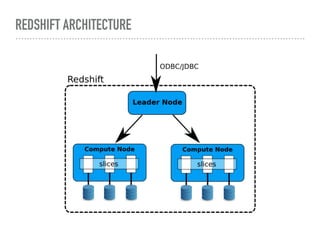
This document discusses performance tuning in Redshift. It covers factors to consider like database design, execution queues, and query tips. For database design, it recommends usage of sort keys and distribution keys, as well as column compression. It also discusses query diagnosis using EXPLAIN and provides tips on common performance issues like unoptimized queries, disk I/O, memory limits, and table fragmentation.












![PREVENTING FRAGMENTATION (II)
select tbl as tbl_id, stv_tbl_perm.name as table_name,
col, interleaved_skew, last_reindex
from svv_interleaved_columns, stv_tbl_perm
where svv_interleaved_columns.tbl = stv_tbl_perm.id
and interleaved_skew is not null;
tbl_id | table_name | col | interleaved_skew | last_reindex
--------+------------+-----+------------------+--------------------
100048 | customer | 0 | 3.65 | 2015-04-22 22:05:45
100068 | lineorder | 1 | 2.65 | 2015-04-22 22:05:45
100072 | part | 0 | 1.65 | 2015-04-22 22:05:45
100077 | supplier | 1 | 1.00 | 2015-04-22 22:05:45
(4 rows)
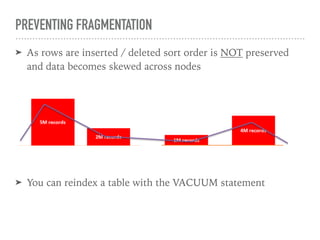
VACUUM [ FULL | SORT ONLY | DELETE ONLY | REINDEX ]
[ table_name ]](https://image.slidesharecdn.com/redshifttuning-160224164507/85/Redshift-performance-tuning-17-320.jpg)