Downloaded 13 times









![Adapter
Implement SchemaFactory interface
Connect to a data source using
parameters
Extract schema - return a list of tables
Push down processing to the data source:
● A set of planner rules
● Calling convention (optional)
● Query model & query generator
(optional)
"schemas": [
{
"name": "HR",
"type": "custom",
"factory":
"org.apache.calcite.adapter.file.FileSchemaFactory",
"operand": {
"directory": "hr-csv"
}
}
]
$ ls -l hr-csv
-rw-r--r-- 1 jhyde staff 62 Mar 29 12:57 DEPTS.csv
-rw-r--r-- 1 jhyde staff 262 Mar 29 12:57 EMPS.csv.gz
$ ./sqlline -u jdbc:calcite:model=hr.json -n scott -p tiger
sqlline> select count(*) as c from emp;
'C'
'5'
1 row selected (0.135 seconds)](https://image.slidesharecdn.com/calcite-pig-adapter-apache-con-2017-170518190246/85/A-smarter-Pig-Building-a-SQL-interface-to-Apache-Pig-using-Apache-Calcite-15-320.jpg)
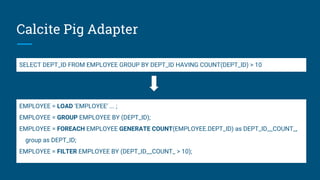





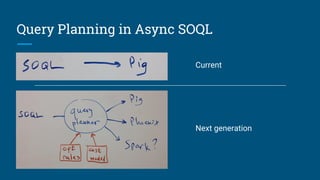
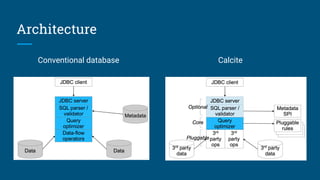
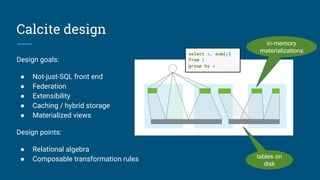
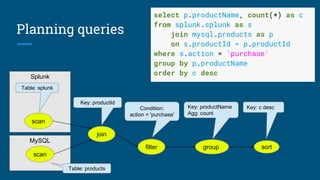
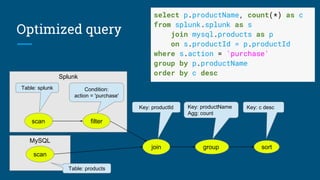
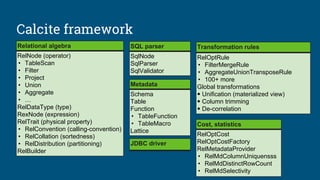
The document discusses the integration of Apache Calcite with Apache Pig to create a SQL interface for analyzing large datasets. It details the architecture and design goals of Calcite, including its features such as federation, extensibility, and support for various physical engines. It also highlights the challenges and lessons learned in building a Pig adapter and the flexibility of Calcite in adapting to different data sources.






















































































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)