Download as PDF, PPTX



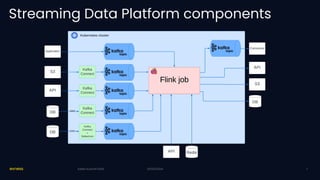

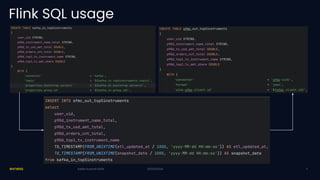

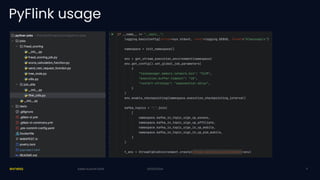


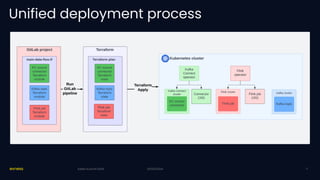





Exness has developed a self-service streaming data platform using Apache Flink to enhance their event-driven architecture, addressing challenges such as scalability, security, and resource management. The platform leverages Flink SQL for simple processing and has faced challenges with support for complex business logic and tracing. Key outcomes include significant improvements in trading data processing times and real-time fraud prevention.



































































