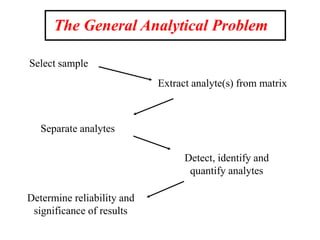
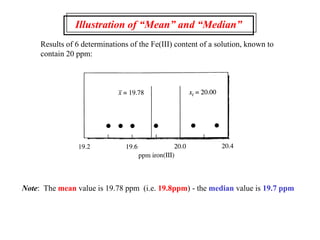
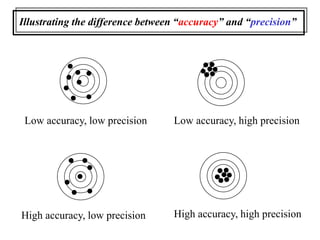
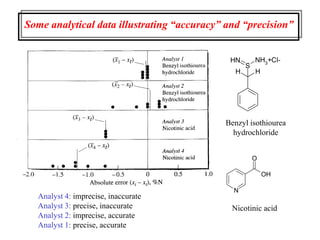
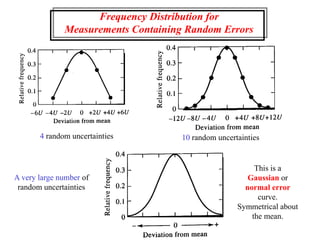
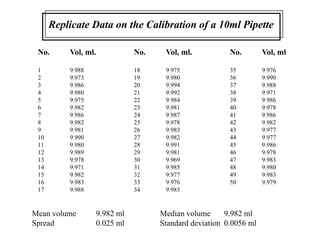
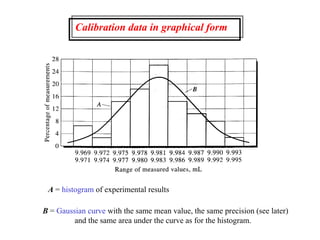
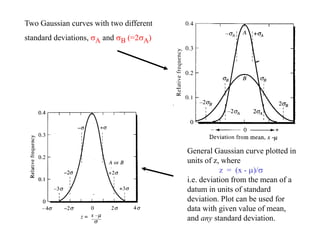
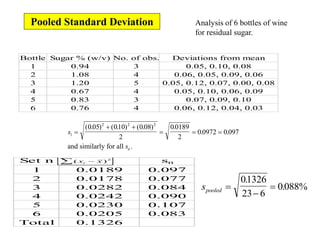
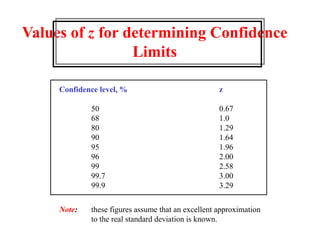
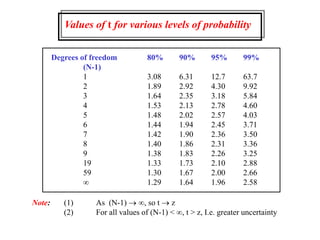
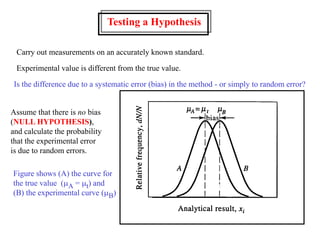
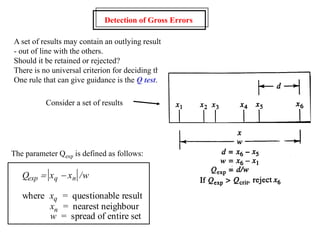
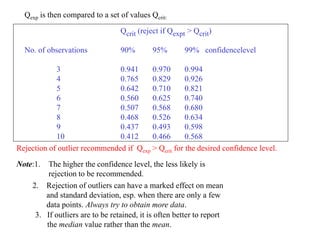
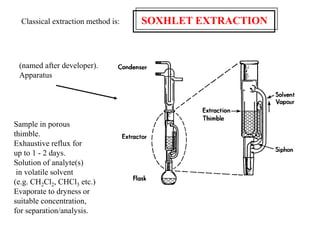
This document provides lecture notes on statistics for analytical chemistry. It begins by recommending textbooks on the subject. It then discusses various applications of analytical chemistry and outlines the general analytical problem of selecting a sample, extracting and detecting analytes, and determining the reliability of results. The notes explain the concepts of errors, precision, accuracy, and how to quantify them using statistical measures like the mean, median, and standard deviation. It provides examples of how to calculate these measures and illustrates the differences between random and systematic errors. Finally, it discusses pooling data from multiple samples to better approximate the population standard deviation.