Download as PDF, PPTX



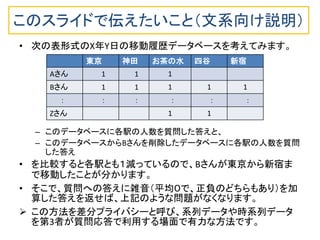

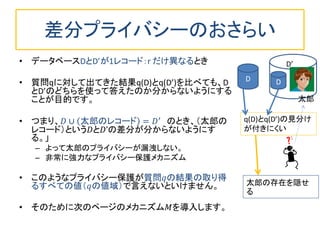




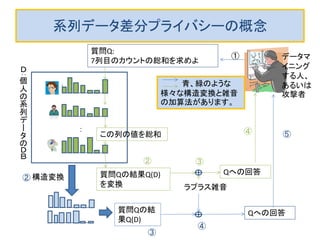


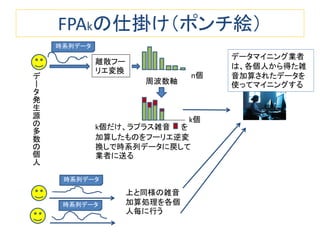









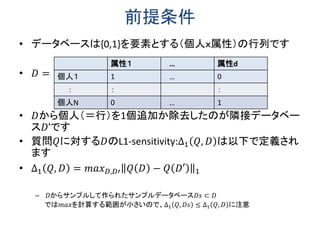

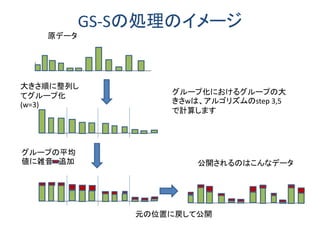














パーソナルデータの入ったデータベースを匿名化して第3者に渡す場合の議論が巷では多いようです。しかし、ビッグデータが超ビッグになり、時間的に累積してくる時系列データのような場合、データベース全体を第3者に渡す方法はだんだん現実的でなくなります。 データベースへ利用者が質問する使い方だと、質問への回答から個人情報が漏れなければ、安全性が高いわけです。そのための技術として使えそうなのが、ここで述べる差分プライバシーです。 このスライドでは、(1)差分プライバシーの基礎入門と、(2)差分プライバシーを時系列データに適用する方法に関する最近の4本の論文を紹介します。

































![Differential privacy without sensitivity [NIPS2016読み会資料]](https://cdn.slidesharecdn.com/ss_thumbnails/nipsyomi2016slideshare-170122091905-thumbnail.jpg?width=640&height=640&fit=bounds)










![[DL Hacks]Deep Learning with Differential Privacy Martin Abadi et al](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks2018101koga-181010051914-thumbnail.jpg?width=640&height=640&fit=bounds)




























