Download as PDF, PPTX
















![アルゴリズムの補遺と説明
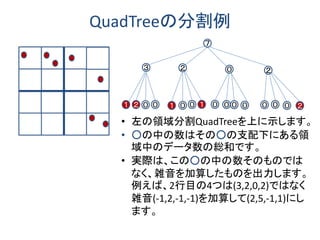
•DBSCANは文献[Ester et al. KDD 1996]で提案された点密度の高さ に基づくクラスタ抽出(=近い点を集めたもの)を行うモジュールで す。抽出されたクラスタはRiです。
–クラスタRi内の点は{Lat(i),Lon(i)}つまり経度と緯度と組です
•line 6: クラスタRj内の滞留点の数を|Rj|とします。これに分散휎푗cts のラプラス分布から生成された雑音Lap(휎푗cts)を加算し、Cts’としま す。
• line 7,8,9: Cts’が予め与えられた閾値r’より大きい、つまり多数の 滞留点を含むクラスタなら、その重心Cgj’を計算します。
•line 9: Cgj’の経度成分と緯度成分の各々に分散휎푗cgのラプラス分 布から生成された雑音Lap(휎푗cg)を加算し、Cg’とします。
•このようにして計算されたCg’の集合I、およびIの要素であるクラス タ内の滞留点数(雑音が加算されています)を結果とします。](https://image.slidesharecdn.com/location-privavy2014-140915012812-phpapp01/85/slide-20-320.jpg)















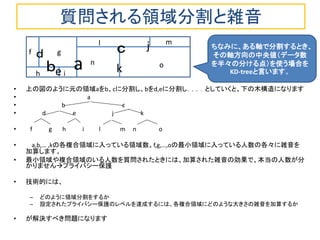
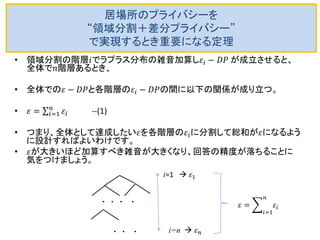
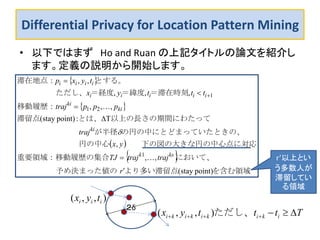
スマホなどの携帯端末のGPS機能によって、個人の居場所(ある時刻における滞在位置情報)を容易にアプリ提供業者が収集できます。そして、個人の居場所情報は様々なビジネスで有用な情報です。多数の業者が使いたい情報であり、収集した業者から第3の業者への転売も起こりえます。 しかし、このような情報を含む個人データのデータベース自体が転売されるとなると、悪用される危険がつきまといます。 データベース自体を転売するのではなく、データベースへの質問をさせ、統計情報を回答する使い方が安全で使いやすいかもしれません。データベース自体が時々刻々と変化しています からなおさらです。 そこでこのスライドでは、多数の人の滞在場所情報のデータベース質問への答えに雑音を加算してプライバシーを保護する差分プライバシー技術について最近の論文を紹介します。 膨大な滞在情報データベースを直接扱うのではなく、適宜、階層的に分割を繰り返し、GqadTreeやKD-treeという木構造にして雑音を加算しする方法と評価について説明しています。

































![Differential privacy without sensitivity [NIPS2016読み会資料]](https://cdn.slidesharecdn.com/ss_thumbnails/nipsyomi2016slideshare-170122091905-thumbnail.jpg?width=640&height=640&fit=bounds)







































