Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Toshinori Hanya
PPTX, PDF
18,455 views
Deep Learningで似た画像を見つける技術 | OHS勉強会#5
Deep Learningで画像間の類似度を扱う技術を勉強しました。Chainerによる実験も行っています。
Technology
◦
Related topics:
Computer Vision Insights
•
Deep Learning
•
Read more
12
Save
Share
Embed
Embed presentation
Download
Downloaded 85 times
1
/ 25
2
/ 25
3
/ 25
4
/ 25
5
/ 25
6
/ 25
7
/ 25
8
/ 25
9
/ 25
10
/ 25
11
/ 25
12
/ 25
13
/ 25
14
/ 25
15
/ 25
16
/ 25
17
/ 25
18
/ 25
19
/ 25
20
/ 25
21
/ 25
22
/ 25
23
/ 25
24
/ 25
25
/ 25
More Related Content
PPTX
Active Convolution, Deformable Convolution ―形状・スケールを学習可能なConvolution―
by
Yosuke Shinya
PDF
【メタサーベイ】Neural Fields
by
cvpaper. challenge
PDF
実装レベルで学ぶVQVAE
by
ぱんいち すみもと
PDF
Attentionの基礎からTransformerの入門まで
by
AGIRobots
PDF
【メタサーベイ】Video Transformer
by
cvpaper. challenge
PPTX
Swin Transformer (ICCV'21 Best Paper) を完璧に理解する資料
by
Yusuke Uchida
PDF
SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜
by
SSII
PPTX
[DL輪読会]Object-Centric Learning with Slot Attention
by
Deep Learning JP
Active Convolution, Deformable Convolution ―形状・スケールを学習可能なConvolution―
by
Yosuke Shinya
【メタサーベイ】Neural Fields
by
cvpaper. challenge
実装レベルで学ぶVQVAE
by
ぱんいち すみもと
Attentionの基礎からTransformerの入門まで
by
AGIRobots
【メタサーベイ】Video Transformer
by
cvpaper. challenge
Swin Transformer (ICCV'21 Best Paper) を完璧に理解する資料
by
Yusuke Uchida
SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜
by
SSII
[DL輪読会]Object-Centric Learning with Slot Attention
by
Deep Learning JP
What's hot
PDF
Domain Adaptation 発展と動向まとめ(サーベイ資料)
by
Yamato OKAMOTO
PDF
Sift特徴量について
by
la_flance
PPTX
【DL輪読会】ViT + Self Supervised Learningまとめ
by
Deep Learning JP
PPTX
Curriculum Learning (関東CV勉強会)
by
Yoshitaka Ushiku
PPTX
You Only Look One-level Featureの解説と見せかけた物体検出のよもやま話
by
Yusuke Uchida
PPTX
[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
by
Deep Learning JP
PDF
自己教師学習(Self-Supervised Learning)
by
cvpaper. challenge
PDF
グラフィカルモデル入門
by
Kawamoto_Kazuhiko
PPTX
画像キャプションの自動生成
by
Yoshitaka Ushiku
PDF
3D CNNによる人物行動認識の動向
by
Kensho Hara
PPTX
畳み込みニューラルネットワークの高精度化と高速化
by
Yusuke Uchida
PDF
【メタサーベイ】数式ドリブン教師あり学習
by
cvpaper. challenge
PPTX
強化学習アルゴリズムPPOの解説と実験
by
克海 納谷
PDF
画像認識の初歩、SIFT,SURF特徴量
by
takaya imai
PDF
Deep Learningによる超解像の進歩
by
Hiroto Honda
PDF
ドメイン適応の原理と応用
by
Yoshitaka Ushiku
PPTX
【DL輪読会】言語以外でのTransformerのまとめ (ViT, Perceiver, Frozen Pretrained Transformer etc)
by
Deep Learning JP
PPTX
[DL輪読会]Dense Captioning分野のまとめ
by
Deep Learning JP
PPTX
【DL輪読会】DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Dri...
by
Deep Learning JP
PDF
【DL輪読会】ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders
by
Deep Learning JP
Domain Adaptation 発展と動向まとめ(サーベイ資料)
by
Yamato OKAMOTO
Sift特徴量について
by
la_flance
【DL輪読会】ViT + Self Supervised Learningまとめ
by
Deep Learning JP
Curriculum Learning (関東CV勉強会)
by
Yoshitaka Ushiku
You Only Look One-level Featureの解説と見せかけた物体検出のよもやま話
by
Yusuke Uchida
[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
by
Deep Learning JP
自己教師学習(Self-Supervised Learning)
by
cvpaper. challenge
グラフィカルモデル入門
by
Kawamoto_Kazuhiko
画像キャプションの自動生成
by
Yoshitaka Ushiku
3D CNNによる人物行動認識の動向
by
Kensho Hara
畳み込みニューラルネットワークの高精度化と高速化
by
Yusuke Uchida
【メタサーベイ】数式ドリブン教師あり学習
by
cvpaper. challenge
強化学習アルゴリズムPPOの解説と実験
by
克海 納谷
画像認識の初歩、SIFT,SURF特徴量
by
takaya imai
Deep Learningによる超解像の進歩
by
Hiroto Honda
ドメイン適応の原理と応用
by
Yoshitaka Ushiku
【DL輪読会】言語以外でのTransformerのまとめ (ViT, Perceiver, Frozen Pretrained Transformer etc)
by
Deep Learning JP
[DL輪読会]Dense Captioning分野のまとめ
by
Deep Learning JP
【DL輪読会】DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Dri...
by
Deep Learning JP
【DL輪読会】ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders
by
Deep Learning JP
Viewers also liked
PPTX
CNNの可視化手法Grad-CAMの紹介~CNNさん、あなたはどこを見ているの?~ | OHS勉強会#6
by
Toshinori Hanya
PDF
ごちうサーチ
by
Kazuhiro Sasao
PPTX
Object Detection & Instance Segmentationの論文紹介 | OHS勉強会#3
by
Toshinori Hanya
PPTX
サーベイ論文:画像からの歩行者属性認識
by
Yasutomo Kawanishi
PDF
Kerasを用いた3次元検索エンジン@TFUG
by
Ogushi Masaya
PDF
画像認識モデルを作るための鉄板レシピ
by
Takahiro Kubo
CNNの可視化手法Grad-CAMの紹介~CNNさん、あなたはどこを見ているの?~ | OHS勉強会#6
by
Toshinori Hanya
ごちうサーチ
by
Kazuhiro Sasao
Object Detection & Instance Segmentationの論文紹介 | OHS勉強会#3
by
Toshinori Hanya
サーベイ論文:画像からの歩行者属性認識
by
Yasutomo Kawanishi
Kerasを用いた3次元検索エンジン@TFUG
by
Ogushi Masaya
画像認識モデルを作るための鉄板レシピ
by
Takahiro Kubo
Similar to Deep Learningで似た画像を見つける技術 | OHS勉強会#5
PPTX
3Dモデル類似検索
by
Core Concept Technologies
PDF
社内論文読み会資料 Image-to-Image Retrieval by Learning Similarity between Scene Graphs
by
Kazuhiro Ota
PPTX
Deep sets
by
Tomohiro Takahashi
PDF
大規模画像認識とその周辺
by
n_hidekey
PDF
ディープラーニング徹底活用 -画像認識編-
by
Hideki
PPTX
令和元年度 実践セミナー - Deep Learning 概論 -
by
Yutaka KATAYAMA
PPTX
Image Retrieval Overview (from Traditional Local Features to Recent Deep Lear...
by
Yusuke Uchida
PDF
拡がるディープラーニングの活用
by
NVIDIA Japan
PDF
画像認識における幾何学的不変性の扱い
by
Seiji Hotta
PDF
DeepLearningDay2016Summer
by
Takayoshi Yamashita
PDF
Opencv object detection_takmin
by
Takuya Minagawa
PDF
20130925.deeplearning
by
Hayaru SHOUNO
PDF
先端技術とメディア表現 第4回レポートまとめ
by
Digital Nature Group
PDF
画像認識について
by
yoshimoto koki
PPTX
CVPR2018 pix2pixHD論文紹介 (CV勉強会@関東)
by
Tenki Lee
PDF
20140726 関東cv勉強会
by
M Kimura
PDF
九大_DS実践_画像処理応用
by
RyomaBise1
PDF
20110625 cv 3_3_5(shirasy)
by
Yoichi Shirasawa
PPTX
ディープラーニングでおそ松さんの6つ子は見分けられるのか? FIT2016
by
Yota Ishida
PDF
Tutorial-DeepLearning-PCSJ-IMPS2016
by
Takayoshi Yamashita
3Dモデル類似検索
by
Core Concept Technologies
社内論文読み会資料 Image-to-Image Retrieval by Learning Similarity between Scene Graphs
by
Kazuhiro Ota
Deep sets
by
Tomohiro Takahashi
大規模画像認識とその周辺
by
n_hidekey
ディープラーニング徹底活用 -画像認識編-
by
Hideki
令和元年度 実践セミナー - Deep Learning 概論 -
by
Yutaka KATAYAMA
Image Retrieval Overview (from Traditional Local Features to Recent Deep Lear...
by
Yusuke Uchida
拡がるディープラーニングの活用
by
NVIDIA Japan
画像認識における幾何学的不変性の扱い
by
Seiji Hotta
DeepLearningDay2016Summer
by
Takayoshi Yamashita
Opencv object detection_takmin
by
Takuya Minagawa
20130925.deeplearning
by
Hayaru SHOUNO
先端技術とメディア表現 第4回レポートまとめ
by
Digital Nature Group
画像認識について
by
yoshimoto koki
CVPR2018 pix2pixHD論文紹介 (CV勉強会@関東)
by
Tenki Lee
20140726 関東cv勉強会
by
M Kimura
九大_DS実践_画像処理応用
by
RyomaBise1
20110625 cv 3_3_5(shirasy)
by
Yoichi Shirasawa
ディープラーニングでおそ松さんの6つ子は見分けられるのか? FIT2016
by
Yota Ishida
Tutorial-DeepLearning-PCSJ-IMPS2016
by
Takayoshi Yamashita
Deep Learningで似た画像を見つける技術 | OHS勉強会#5
1.
Deep Learningで 似た画像を見つける技術 Open Hyper
Scale勉強会#5 半谷
2.
Contents 1.導入 – 「似ている」について 2.理論
– Deep Learningで類似性を扱うに は 3.実践 – Chainerによる実装
3.
1. 導入 「似ている」について
4.
Introduction • 私たち人間は、画像を見てどれとどれが似ているかを自然と判断できる。 • では機械に似ている、似ていないを判断させるにはどうすれば良いか?
5.
利用例(1) 画像の検索 • 気になるランプの詳細情報を、画像から検索。類似商品もチェック •
商品(椅子)が実際に使われているイメージをみてみる • Pinterestで画像から類似画像を検索する http://www.news.cornell.edu/stories/2016/08/where- can-i-buy-chair-app-will-tell-you https://engineering.pinterest.com/blog/introducing-new- way-visually-search-pinterest
6.
利用例(2) 人物の同定 • 複数の映像中から同じ人を見つける •
顔画像から同じ人かどうか/似ているかどうかを判定 Market-1501 dataset: www.liangzheng.org/Project/project_reid.html https://arxiv.org/abs/1503.03832 数字は画像間の類似度を表したもので、 小さいほど似ている。 「似ている」という情報は 様々な利用用途がある!
7.
2. 理論 Deep Learningで類似性を扱うに は
8.
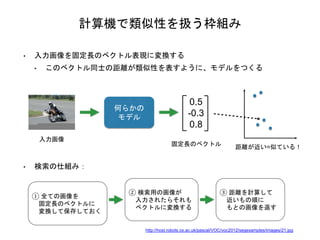
計算機で類似性を扱う枠組み • 入力画像を固定長のベクトル表現に変換する • このベクトル同士の距離が類似性を表すように、モデルをつくる 入力画像 何らかの モデル 0.5 -0.3 0.8 固定長のベクトル
距離が近い=似ている! ① 全ての画像を 固定長のベクトルに 変換して保存しておく ② 検索用の画像が 入力されたらそれも ベクトルに変換する ③ 距離を計算して 近いもの順に もとの画像を返す • 検索の仕組み: http://host.robots.ox.ac.uk/pascal/VOC/voc2012/segexamples/images/21.jpg
9.
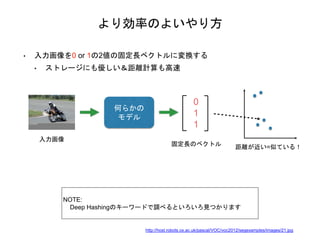
より効率のよいやり方 • 入力画像を0 or
1の2値の固定長ベクトルに変換する • ストレージにも優しい&距離計算も高速 NOTE: Deep Hashingのキーワードで調べるといろいろ見つかります 入力画像 何らかの モデル 0 1 1 固定長のベクトル 距離が近い=似ている! http://host.robots.ox.ac.uk/pascal/VOC/voc2012/segexamples/images/21.jpg
10.
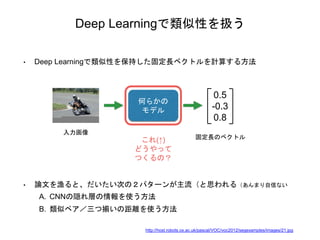
Deep Learningで類似性を扱う • Deep
Learningで類似性を保持した固定長ベクトルを計算する方法 入力画像 何らかの モデル 0.5 -0.3 0.8 固定長のベクトル これ(↑) どうやって つくるの? • 論文を漁ると、だいたい次の2パターンが主流(と思われる(あんまり自信ない A. CNNの隠れ層の情報を使う方法 B. 類似ペア/三つ揃いの距離を使う方法 http://host.robots.ox.ac.uk/pascal/VOC/voc2012/segexamples/images/21.jpg
11.
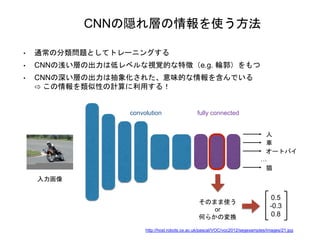
CNNの隠れ層の情報を使う方法 • 通常の分類問題としてトレーニングする • CNNの浅い層の出力は低レベルな視覚的な特徴(e.g.
輪郭)をもつ • CNNの深い層の出力は抽象化された、意味的な情報を含んでいる ⇨ この情報を類似性の計算に利用する! 入力画像 convolution fully connected 人 車 オートバイ … 猫 0.5 -0.3 0.8 そのまま使う or 何らかの変換 http://host.robots.ox.ac.uk/pascal/VOC/voc2012/segexamples/images/21.jpg
12.
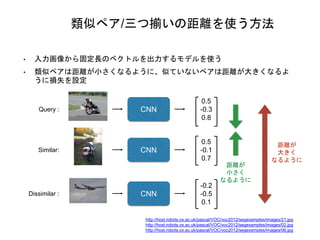
類似ペア/三つ揃いの距離を使う方法 • 入力画像から固定長のベクトルを出力するモデルを使う • 類似ペアは距離が小さくなるように、似ていないペアは距離が大きくなるよ うに損失を設定 Query
: CNN 0.5 -0.3 0.8 Similar: CNN 0.5 -0.1 0.7 Dissimilar : CNN -0.2 -0.5 0.1 距離が 小さく なるように 距離が 大きく なるように http://host.robots.ox.ac.uk/pascal/VOC/voc2012/segexamples/images/21.jpg http://host.robots.ox.ac.uk/pascal/VOC/voc2012/segexamples/images/02.jpg http://host.robots.ox.ac.uk/pascal/VOC/voc2012/segexamples/images/06.jpg
13.
3. 実践 Chainerによる実装
14.
Chainerによる類似度モデルの実装 • ChainerでSSDHモデル(以下の論文)を実装しました。 • Supervised
Learning of Semantics-Preserving Hashing via Deep Neural Networks for Large-Scale Image Search (https://arxiv.org/abs/1507.00101) • CIFAR-10のトレーニングセットで モデルを訓練し、テストセットで 類似画像検索をやってみました。 https://www.cs.toronto.edu/~kriz/cifar.html
15.
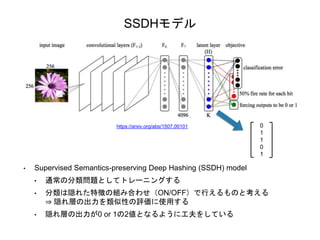
SSDHモデル • Supervised Semantics-preserving
Deep Hashing (SSDH) model • 通常の分類問題としてトレーニングする • 分類は隠れた特徴の組み合わせ(ON/OFF)で行えるものと考える ⇒ 隠れ層の出力を類似性の評価に使用する • 隠れ層の出力が0 or 1の2値となるように工夫をしている https://arxiv.org/abs/1507.00101 0 1 1 0 1
16.
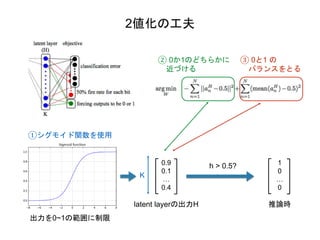
2値化の工夫 ①シグモイド関数を使用 ② 0か1のどちらかに 近づける ③ 0と1
の バランスをとる 0.9 0.1 … 0.4 K latent layerの出力H 出力を0~1の範囲に制限 推論時 1 0 … 0 h > 0.5?
17.
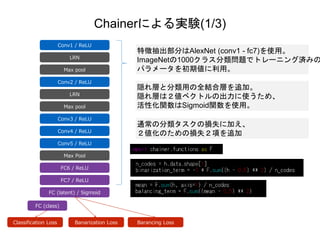
Chainerによる実験(1/3) Conv1 / ReLU LRN Max
pool Conv2 / ReLU LRN Max pool Conv3 / ReLU Conv4 / ReLU Conv5 / ReLU Max Pool FC6 / ReLU FC7 / ReLU FC (latent) / Sigmoid FC (class) 特徴抽出部分はAlexNet (conv1 - fc7)を使用。 ImageNetの1000クラス分類問題でトレーニング済みの パラメータを初期値に利用。 Classification Loss Banarization Loss Barancing Loss 隠れ層と分類用の全結合層を追加。 隠れ層は2値ベクトルの出力に使うため、 活性化関数はSigmoid関数を使用。 通常の分類タスクの損失に加え、 2値化のための損失2項を追加
18.
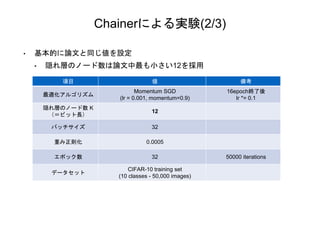
Chainerによる実験(2/3) 項目 値 備考 最適化アルゴリズム Momentum
SGD (lr = 0.001, momentum=0.9) 16epoch終了後 lr *= 0.1 隠れ層のノード数 K (=ビット長) 12 バッチサイズ 32 重み正則化 0.0005 エポック数 32 50000 iterations データセット CIFAR-10 training set (10 classes - 50,000 images) • 基本的に論文と同じ値を設定 • 隠れ層のノード数は論文中最も小さい12を採用
19.
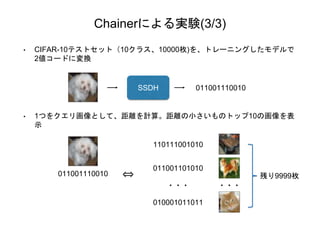
Chainerによる実験(3/3) • CIFAR-10テストセット(10クラス、10000枚)を、トレーニングしたモデルで 2値コードに変換 • 1つをクエリ画像として、距離を計算。距離の小さいものトップ10の画像を表 示 011001110010SSDH 011001110010 011001101010 010001011011 110111001010 ⇔
残り9999枚 ・・・ ・・・
20.
結果 クエリ画像 検索結果(Top10)
21.
まとめ
22.
まとめ • 画像の類似性はいろいろなアプリケーションに応用できる。 • 類似性をシステムで扱う場合には、固定サイズのベクトルに変換するのが通例。 •
ベクトル間の距離が小さいほど似ていると考える。 • Deep Learningで類似性を扱う枠組みを調査した。 • CNNの隠れ層の情報を使う方法 • 類似ペアの出力の距離が近くなるように訓練する方法 (似ていないものは遠くなるように。) • ChainerでSSDHを実装した。 • 類似画像検索を動作させることができた。 • 分類用のデータセットで学習させることができるので、色々試してみたい。 ⇒ Githubにアップしました:https://github.com/t-hanya/chainer-SSDH
23.
ご清聴ありがとうございました
24.
付録
25.
t-SNEで可視化 CIFAR-10のテストセット 画像(10000枚)の2値化コードを t-SNEで2次元空間に可視化
Download






















![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Object-Centric Learning with Slot Attention](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0717-200717023021-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://cdn.slidesharecdn.com/ss_thumbnails/swintransformer-210514020542-thumbnail.jpg?width=640&height=640&fit=bounds)











![[DL輪読会]Dense Captioning分野のまとめ](https://cdn.slidesharecdn.com/ss_thumbnails/dlseminar-201202012355-thumbnail.jpg?width=640&height=640&fit=bounds)



























