More Related Content

PDF

PPTX

PDF

PDF

PDF

PDF

PDF

PDF
What's hot

PDF

PPTX

PDF

PDF

PDF

PDF
トピックモデルの評価指標 Perplexity とは何なのか? 
PPTX

PDF

PPTX

PDF

PDF
基礎からのベイズ統計学 輪読会資料 第4章 メトロポリス・ヘイスティングス法 
PDF

PDF

PDF

PPTX
![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX

PDF

PDF

PDF
状態空間モデルの考え方・使い方 - TokyoR #38 
PDF
Similar to Survival analysis0702

PDF

PDF

PDF

PDF

PDF

PDF
Analysis of clinical trials using sas 勉強用 isseing333 
PDF
統計モデリングで癌の5年生存率データから良い病院を探す 
PPTX

PDF
分類分析 (taxometric analysis) 
PDF

PPT

PPTX

PPTX
No55 tokyo r_presentation 
PDF

PDF

PDF
LET2015 National Conference Seminar 
PPT
Model seminar shibata_100710 
PDF

PPTX
An introduction to statistical learning 4 logistic regression manu 
PDF
論文輪読会 - A Multi-level Trend-Renewal Process for Modeling Systems with Recurre... More from Nobuaki Oshiro

PDF
10分で分かるr言語入門ver2.10 14 1101 
PDF
10分で分かるr言語入門ver2.15 15 1010 
PDF
10分で分かるr言語入門ver2.8 14 0712 
PDF
20181117_データ分析プロジェクトの流れを理解する_PDCAとKPIツリー 
PDF

PDF
10分で分かるr言語入門ver2.9 14 0920 
PPTX

PDF
10分で分かるr言語入門ver2 upload用 
PDF
10分で分かるr言語入門ver2.14 15 0905 
PDF
20170312 r言語環境構築&dplyr ハンズオン 
PPTX
20161127 doradora09 japanr2016_lt 
PDF

PDF
20170909 reafletでお手軽可視化 on_r_20分ver_up用 
PDF

PDF

PDF

PDF
15 0117 kh-coderご紹介 for R users 
PDF
10分で分かるr言語入門 短縮バージョン 15-0117_upload用 
PDF

PPTX
20170826 fukuoka.r告知_reafletでお手軽可視化_on_r Recently uploaded

PDF
100年後の知財業界-生成AIスライドアドリブプレゼン イーパテントYouTube配信 
PDF
Starlink Direct-to-Cell (D2C) 技術の概要と将来の展望 
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 3C Analysis 
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 Ansoff's Growth Vector 
PDF
2025→2026宙畑ゆく年くる年レポート_100社を超える企業アンケート総まとめ!!_企業まとめ_1229_3版 
PPTX

PDF
第21回 Gen AI 勉強会「NotebookLMで60ページ超の スライドを作成してみた」 
PDF

PDF
さくらインターネットの今 法林リージョン:さくらのAIとか GPUとかイベントとか 〜2026年もバク進します!〜 Survival analysis0702
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
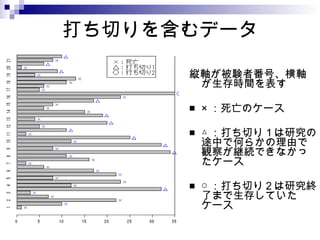
例: 新薬の効果を分析 6-MP という薬を投与した場合とそうでない場合の白血病患者の生存時間のグラフ 縦軸が生存率 横軸が時間 新薬を投与した方が生存確率が高い - 18.
- 19.
- 20.
- 21.
- 22.
生存関数とハザード関数 生存関数S (t)累積確率分布関数 F(t) で表すと、イベントがある時点tまで生起していない生存関数S (t) は S(t) = Pr(T > t) = 1 - Pr(t ≦ T) = 1 – F(t) で表される。 ハザード関数 イベントがある時点 t までに生起していないという条件の下で、次の瞬間にイベントが生起する瞬間死亡率 危険度とも呼ばれている。 生存関数とハザード関数は、どちらか片方が分かればもう片方も分かる関係。 ( 数式の詳細は p185 参照 ) - 23.
- 24.
- 25.
- 26.
補足:パラメトリックとノンパラメトリック パラメトリックな手法 母集団の特性を規定する母数についてある仮説を設けるもので, 平均値の差の検定 (t 検定と略称されることが多い)や 分散分析 (F 検定と略称されることがある)などがこれに該当する。これらの検定手法では,母集団の正規性や 等分散性 が仮定される。 ノンパラメトリックな手法 母集団の分布型(母数)について一切の仮定を設けない。 このため, 分布によらない手法 と呼ばれることもある。 特に, 標本サイズが小さい場合には,それから求められた統計量の分布型は不正確なことが多く,パラメトリックな手法を適用することは不適切になりやすい。 しかし,ノンパラメトリックな手法は常に適用可能である。 - 27.
- 28.
- 29.
- 30.
- 31.
解析: Surv, survfit関数 Surv(time, event) time: 生存時間 event: イベント survfit(formula, data, type=“ “, …) formula : Surv オブジェクト形式の目的変数と説明変数をセットする data : 解析対象のデータ type : 推定方法。デフォルトはカプラン - マイヤー推定法。他にフレミング - ハリントン推定法、 fh2 推定法がある メモ: R からヘルプを出す場合はパッケージ名も指定する ?survival::Surv ?survival::survfit - 32.
解析結果 ge.sf <- survfit(Surv(time,cens)~treat, data=gehan); ge.sf; Call: survfit(formula = Surv(time, cens) ~ treat, data =gehan) records n.max n.start events median 0.95LCL 0.95UCL treat=6-MP 21 21 21 9 23 16 NA treat=control 21 21 21 21 8 4 12 records: 対照郡 , n.max: レコード数 n.start: 開始時の数 , median: 中央値 0.95LCL,0.95UCL : 95% 信頼区間の上下限値 6-MP を投与したグループは生存期間の中央値が 23 と大幅に増えている - 33.
summary(ge.sf) treat=6-MP time n.risk n.event survival std.err lower 95% CI upper 95% CI 6 21 3 0.857 0.0764 0.720 1.000 7 17 1 0.807 0.0869 0.653 0.996 10 15 1 0.753 0.0963 0.586 0.968 13 12 1 0.690 0.1068 0.510 0.935 16 11 1 0.627 0.1141 0.439 0.896 22 7 1 0.538 0.1282 0.337 0.858 23 6 1 0.448 0.1346 0.249 0.807 解析結果詳細 項目左から 生存時間、リスクセット、イベントの数、推定された生存確率、 標準誤差、 95% 信頼区間の上下限値 時間が経つにつれ、推定された生存確率が下がっていく - 34.
- 35.
投薬郡に対する90%信頼区間 信頼区間に納まっている ge2<-subset(gehan,treat=="6-MP"); ge2.s <- survfit(Surv(time, cens)~treat, conf.int=.9, data=ge2); plot(ge2.s, mark.t=F); legend(locator(1), lty=c(1,2), legend=c(" 生存曲線 ", "90% 信頼区間 ")) - 36.
信頼区間の推定法 servfit 関数はconf.type パラメータで信頼区間の推定法を変更することができる 種類は以下の通り plain log log-log conf.int パラメータで信頼区間を設定可能 デフォルトは conf.int=.95 (95% の信頼区間 ) コードはテキスト p189 参照 - 37.
推定法の変更 servfit 関数はconf パラメータで生存期間の推定法を変更することができる 種類は以下の通り デフォルト ( カプラン - マイヤー ) fh ( フレミング - ハリントン ) fh2 コードはテキスト p189 参照 - 38.
検定: servdiff 関数2郡以上の観測値が得られた場合、その優位性の検定が必要する場合がある survdiff (…) 引数 rho=0 でログ・ランク検定 ( デフォルト ) 引数 rho=1 でゲーハン - ウィルコソン検定 - 39.
検定: servdiff 関数実行結果 survdiff(Surv(time)~treat, data=gehan) Call: survdiff(formula = Surv(time) ~ treat, data = gehan) N Observed Expected (O-E)^2/E (O-E)^2/V treat=6-MP 21 21 29.2 2.31 8.97 treat=control 21 21 12.8 5.27 8.97 Chisq= 9 on 1 degrees of freedom, p= 0.00275 ログ・ランク検定の p 値は約 0.003 なので、有意水準 5% とすると 両群の生存曲線には優位な差が認められる。 - 40.
- 41.
- 42.
セミノンパラメトリックモデル 特徴 共変量を導入する分布の仮定をしない イベントに影響を及ぼす複数の因子(共変量)の影響を解析することを前提としたノンパラメトリックモデルのこと 共変量としては、年齢や血圧のような連続変数、性別や結婚の有無のようなカテゴリカル変数、これらの交差項などを含む変数ベクトル モデル コックス比例ハザードモデル が良く用いられる ( 数式はテキスト p191) - 43.
コックス比例ハザードモデル パラメータの推定 直接法ブレスロー (Breslow) の近似法 エフロン (Efron) の近似法 イベントの数が増えると近似法のほうが計算が簡単であるが、同時に起こるイベントの数が多くなった場合妥当性を失うといわれている Survival パッケージには関数 coxph がある - 44.
推定: Coxph 関数coxph(formula, data, method, … ) formula: 共変量など data: データ method : 以下の3種類。デフォルトは’ efron’ efron breslow exact - 45.
- 46.
解析例:コックスハザードモデル 性別 (sex)と病気の種類 (disease) を説明変数とした解析例 data(kidney) kidney.cox<- coxph( Surv(time, status)~sex+disease, data=kidney) summary(kidney.cox); Call: coxph(formula = Surv(time, status) ~ sex + disease, data = kidney) n= 76 coef exp(coef) se(coef) z Pr(>|z|) sex -1.4774 0.2282 0.3569 -4.140 3.48e-05 *** diseaseGN 0.1392 1.1494 0.3635 0.383 0.7017 diseaseAN 0.4132 1.5116 0.3360 1.230 0.2188 diseasePKD -1.3671 0.2549 0.5889 -2.321 0.0203 * --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 - 47.
解析例:コックスハザードモデル 3種類の検定統計量を返す 尤度比の検定、ワルド検定、スコア検定exp(coef) exp(-coef) lower .95 upper .95 sex 0.2282 4.3815 0.11339 0.4594 diseaseGN 1.1494 0.8700 0.56368 2.3437 diseaseAN 1.5116 0.6616 0.78245 2.9202 diseasePKD 0.2549 3.9238 0.08035 0.8084 Rsquare= 0.206 (max possible= 0.993 ) Likelihood ratio test= 17.56 on 4 df, p=0.001501 Wald test = 19.77 on 4 df, p=0.0005533 Score (logrank) test = 19.97 on 4 df, p=0.0005069 - 48.
生存時間の推定: survfit 構築したモデルによる生存時間の当てはめは、関数survfit を用いると便利 kidney.fit<-survfit(kidney.cox); summary(kidney.fit); Call: survfit(formula = kidney.cox) time n.risk n.event survival std.err lower 95% CI upper 95% CI 2 76 1 0.99018 0.00985 0.971059 1.000 7 71 2 0.96856 0.01831 0.933335 1.000 ・・・ 536 2 1 0.01224 0.01383 0.001336 0.112 562 1 1 0.00318 0.00613 0.000073 0.139 - 49.
- 50.
残差分析 打ち切りデータがあるため、残差分析が少々複雑になる 提案されている残差( カッコ内は指定パラメータ ) マルチンゲール残差 ( デフォルト ) 良く使われている シェーンフィールド残差 (type=“schoen-feld”) スコア残差 (type=“score”) デヴィアンス残差 (type=“deviance”) 関数 coxph のモデルの残差は residuals.coxph( 略して residuals) 関数で呼び出す パラメータ type を変えることで残差の種類を切り替えられる - 51.
- 52.
- 53.
- 54.
比例性の分析: cox.zph kidney.zph<-cox.zph(kidney.cox); kidney.zph rho chisq p sex 0.18839 2.60676 0.106 diseaseGN -0.01392 0.01123 0.916 diseaseAN 0.06162 0.20036 0.654 diseasePKD 0.00701 0.00438 0.947 GLOBAL NA 4.20781 0.379 - 55.
- 56.
- 57.
- 58.
- 59.
パラメトリックモデル 特徴 共変量を導入する分布の仮定をする コックス比例ハザードモデルに比べると計算速度が速い ただし、制約のため応用範囲が限定される 生存時間が確率分布に従うという仮定の下で構築したモデル survreg(formula=formula(data), dist=“weibull”, …) 分布 指数分布 (dist=exponential) ワイブル (dist= デフォルト ) 対数正規 (dist=log-normal) ロジスティック (dist=logistic) 対数ロジスティック (dist=log-logistic) ( 数式はテキスト p198 参照 ) - 60.
解析: survreg 関数survreg(Surv(time, status)~ sex+disease, kidney, dist="lognormal"); Call: survreg(formula = Surv(time, status) ~ sex + disease, data = kidney, dist = "lognormal") Coefficients: (Intercept) sex diseaseGN diseaseAN diseasePKD 1.7923643 1.5062960 -0.3334601 -0.5321264 0.6810495 Scale= 1.129394 Loglik(model)= -329.1 Loglik(intercept only)= -340 Chisq= 21.8 on 4 degrees of freedom, p= 0.00022 n= 76 - 61.
- 62.
- 63.





























![gehanデータの中身 library(survival);library(MASS); data(gehan);dim(gehan); [1] 42 4 gehan[1:6,] pair time cens treat 1 1 1 1 control 2 1 10 1 6-MP 3 2 22 1 control 4 2 7 1 6-MP 5 3 3 1 control 6 3 32 0 6-MP pair : 投薬と比較対象のペア time: 生存時間 cens :打ち切りか否か (1 が打ち切り ) treat:6-PM( 抑癌薬 ) の投与か否か](https://image.slidesharecdn.com/survivalanalysis0702-110702000903-phpapp02/85/Survival-analysis0702-30-320.jpg)
































