Downloaded 108 times

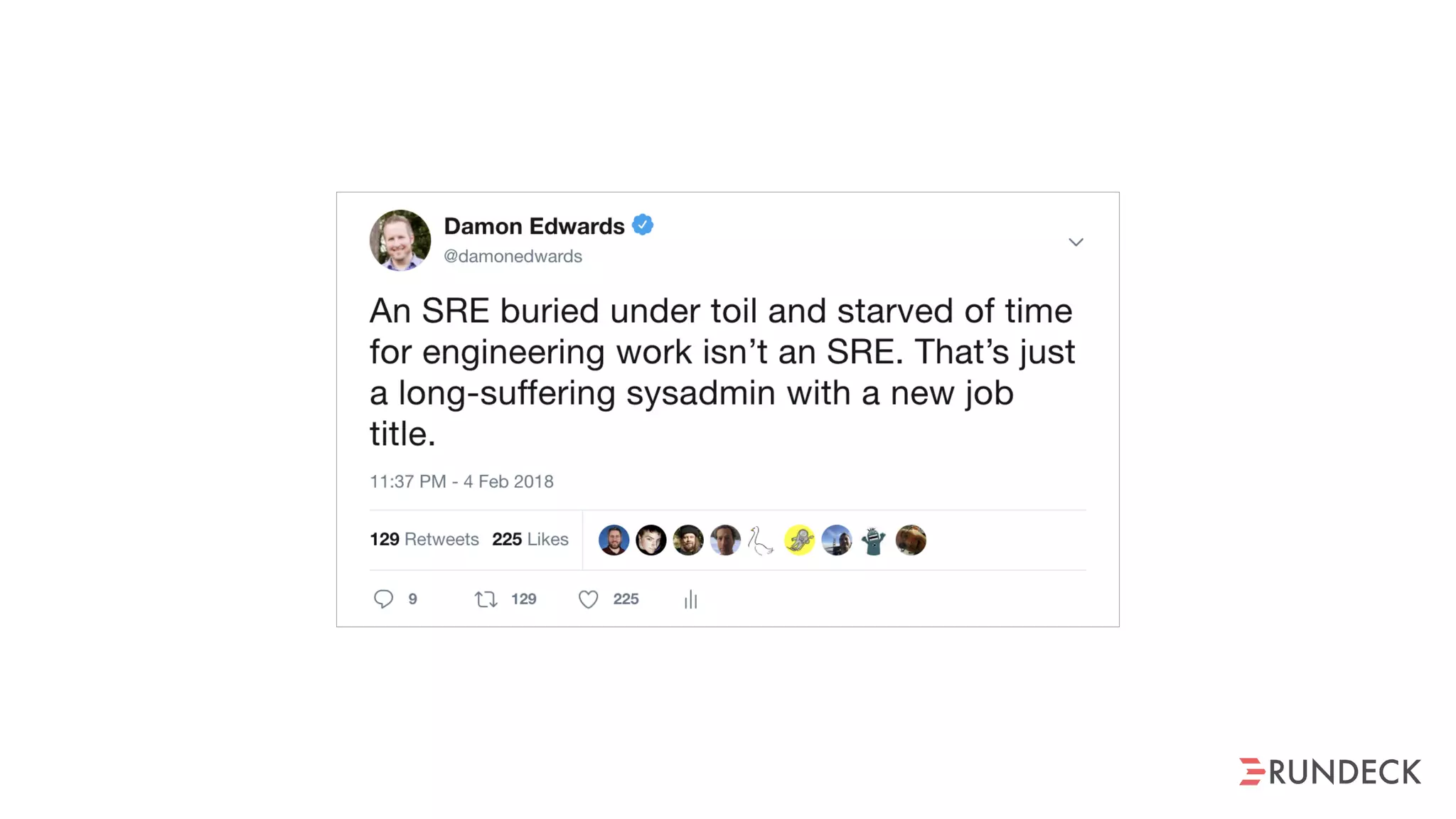

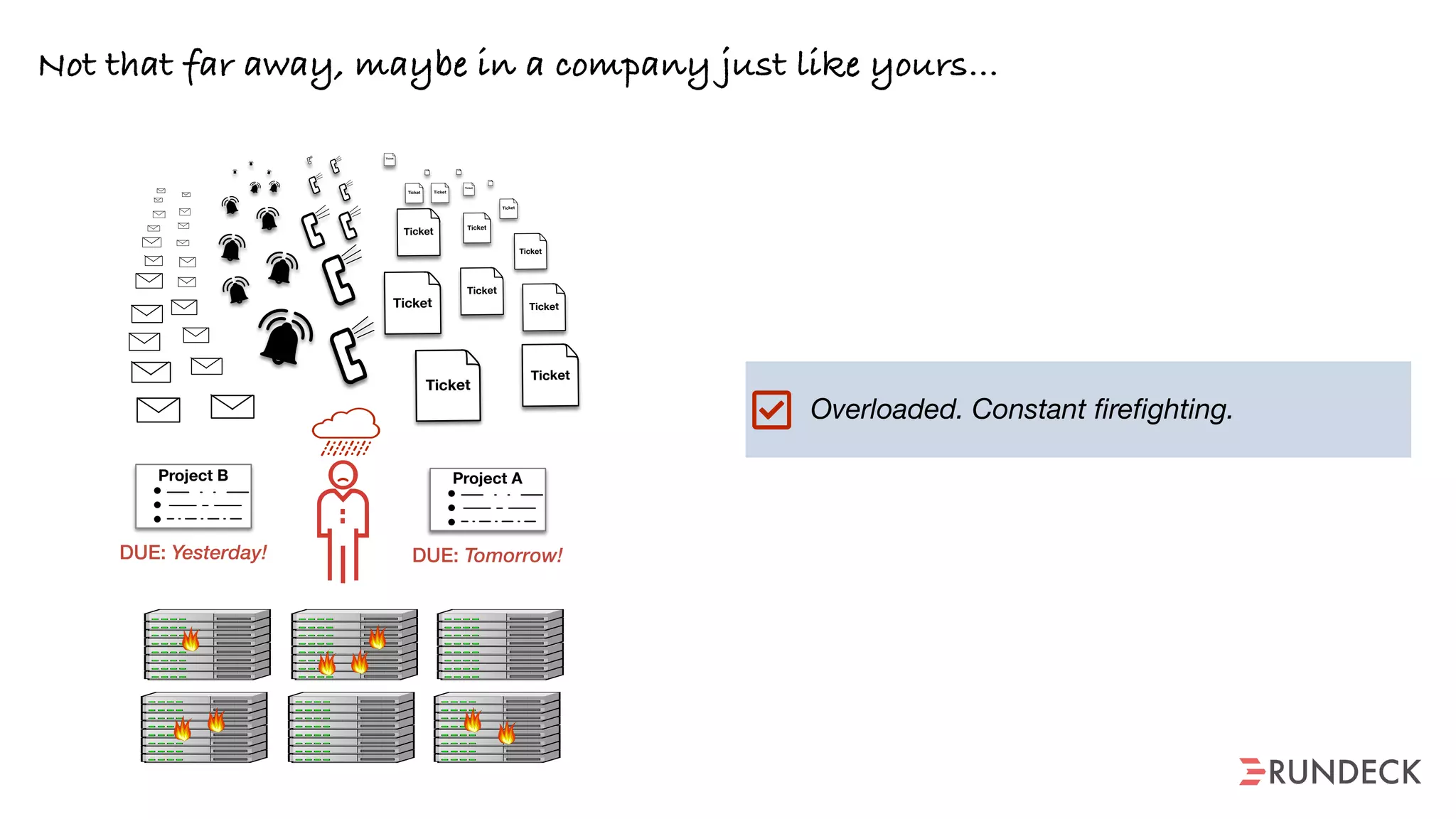



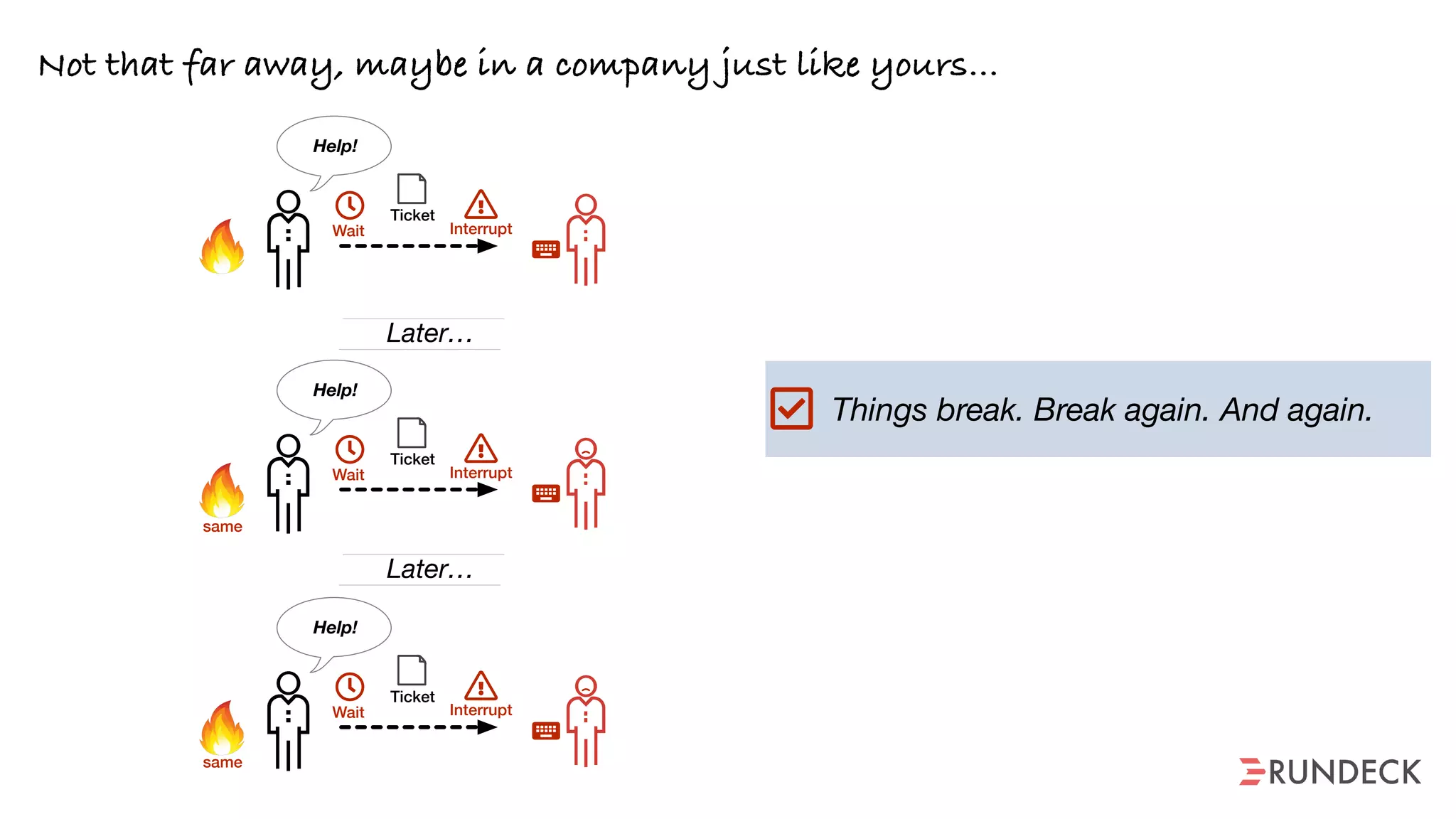
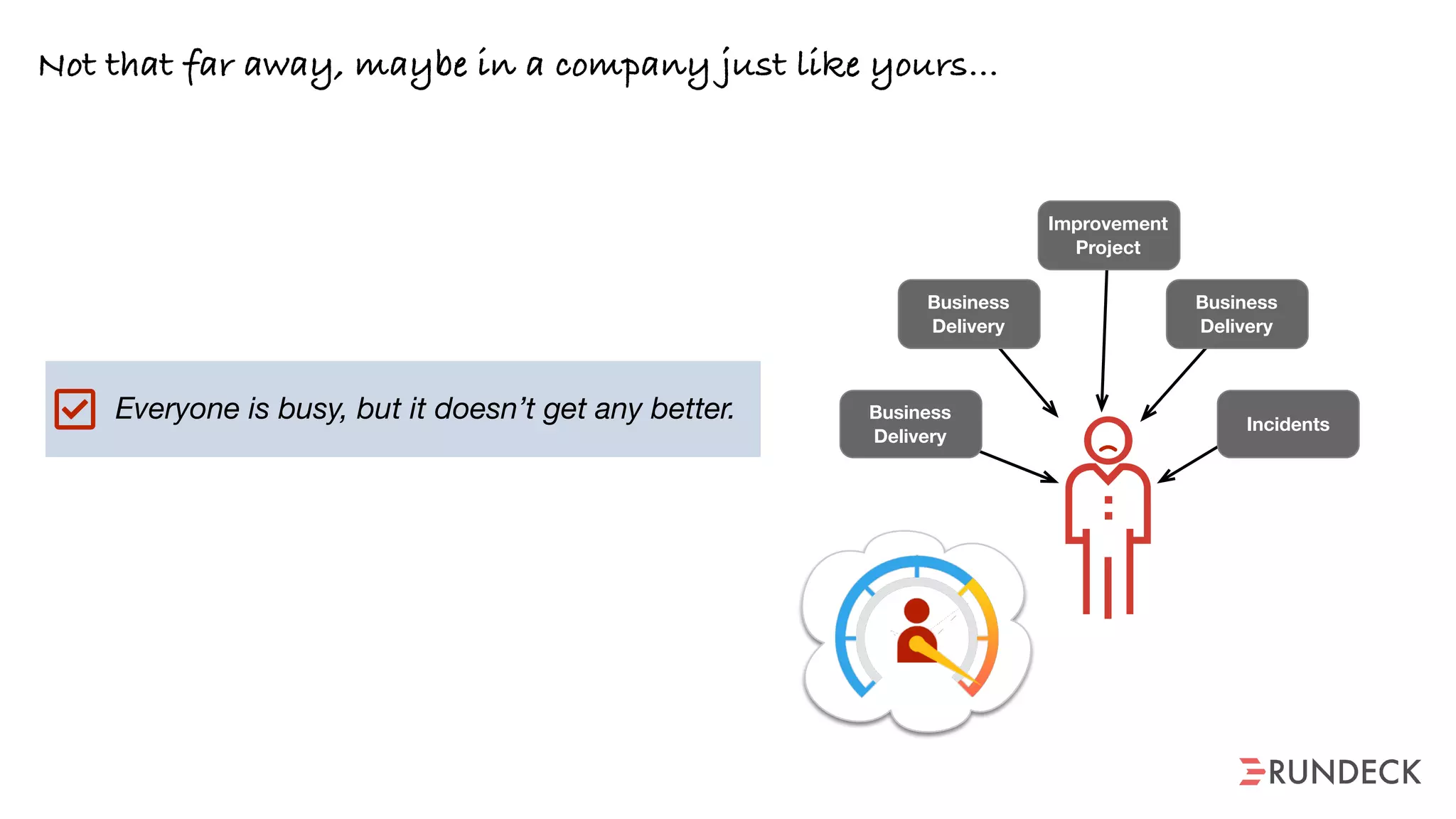


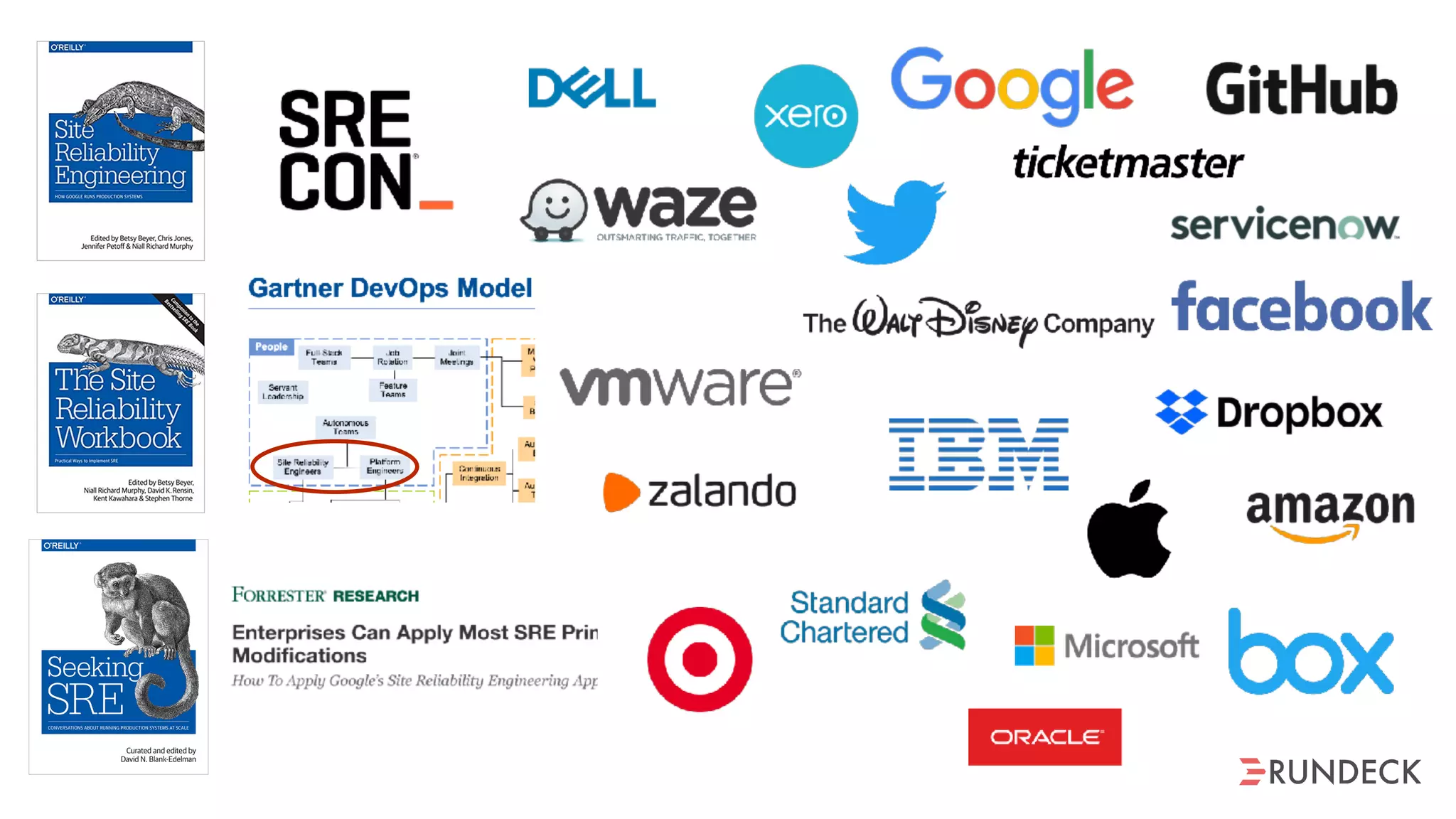
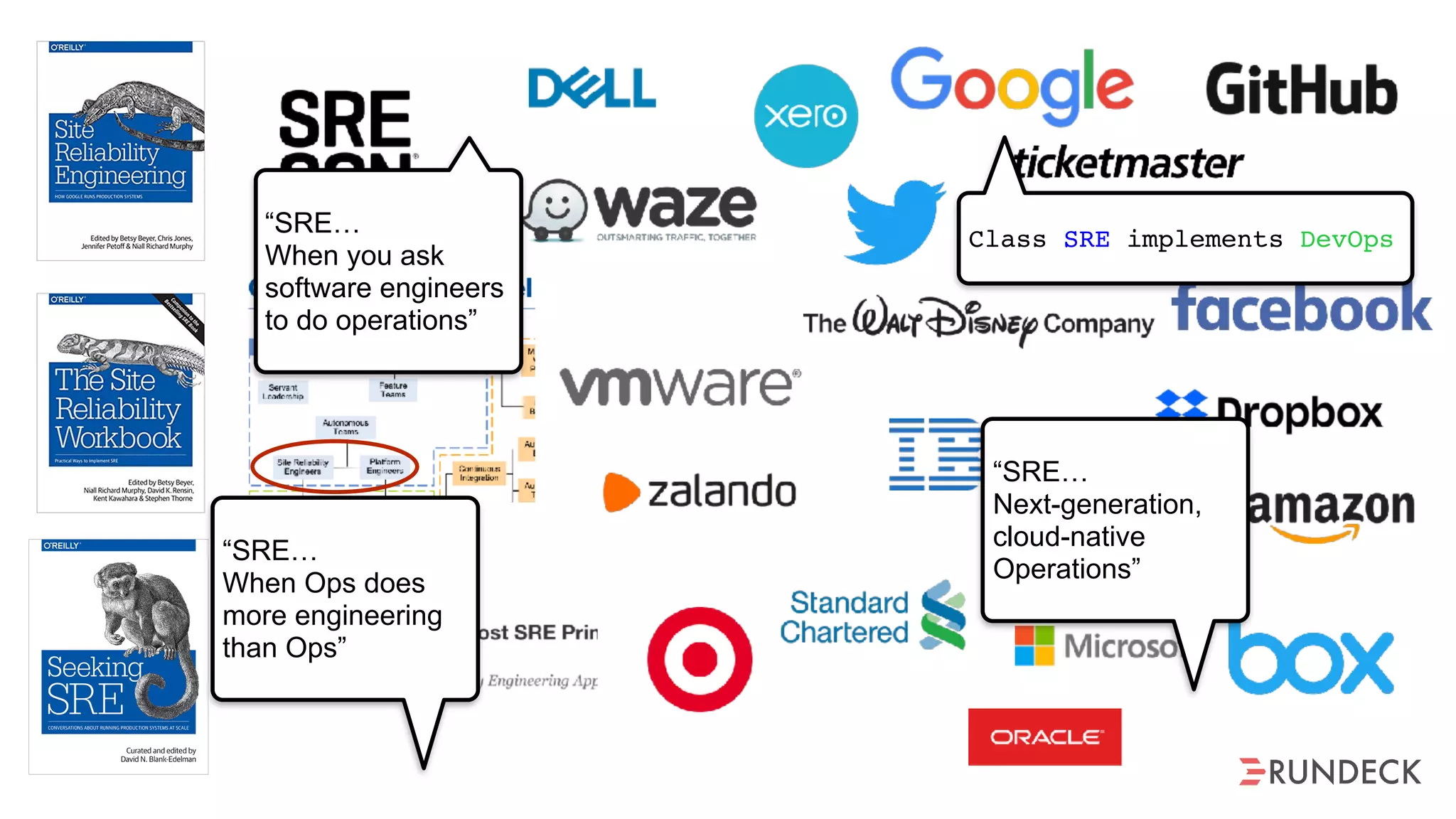
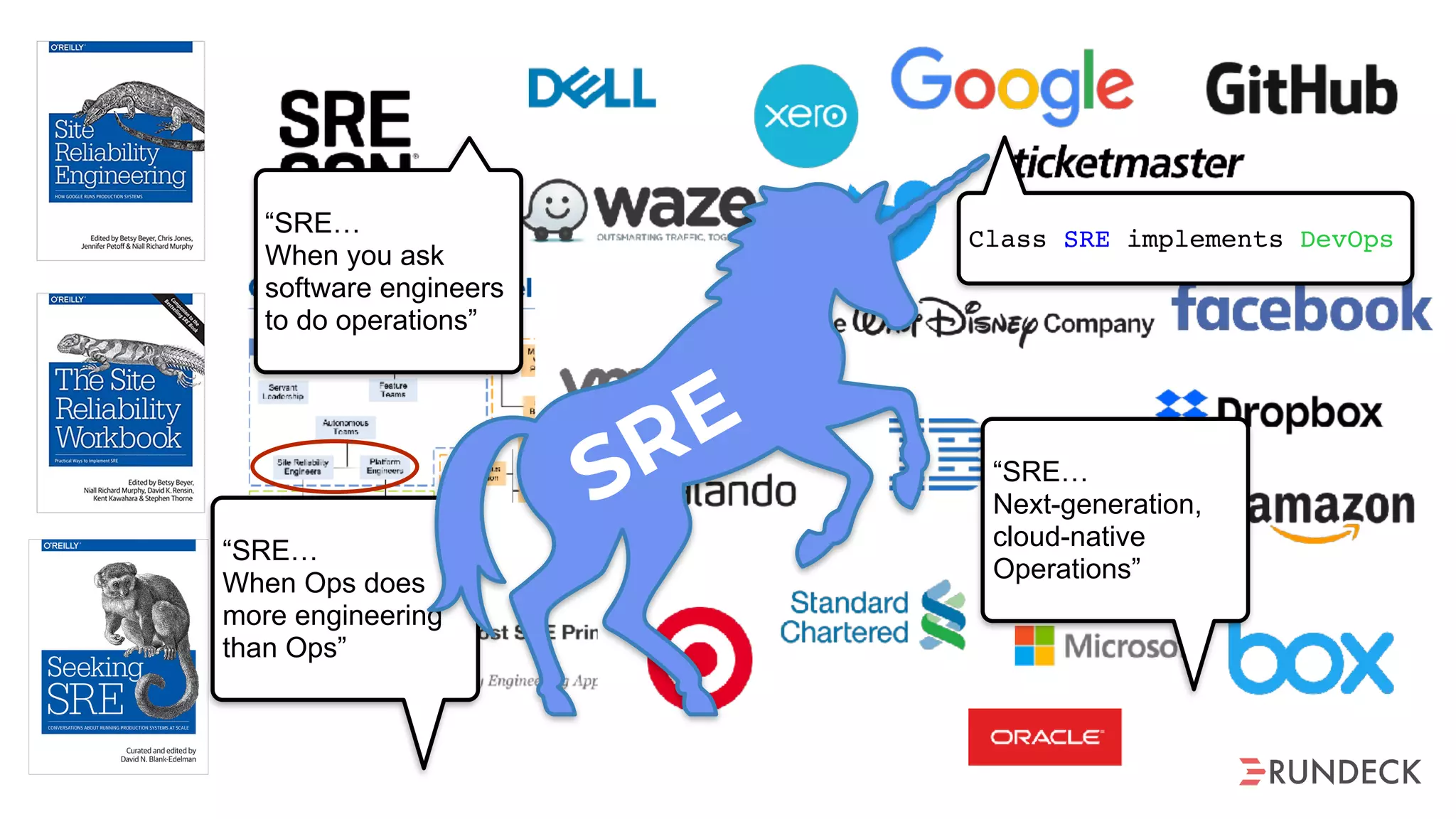
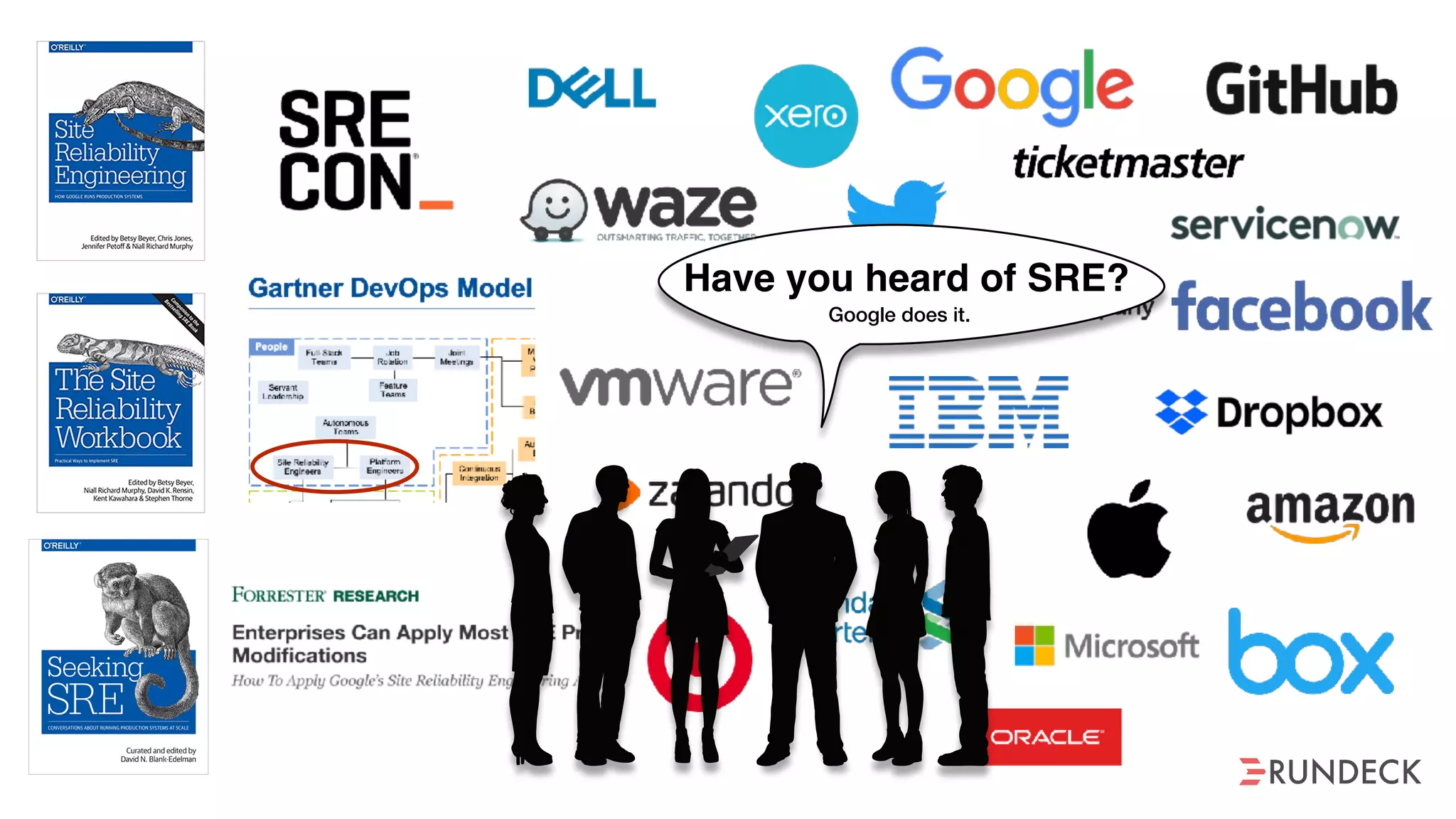






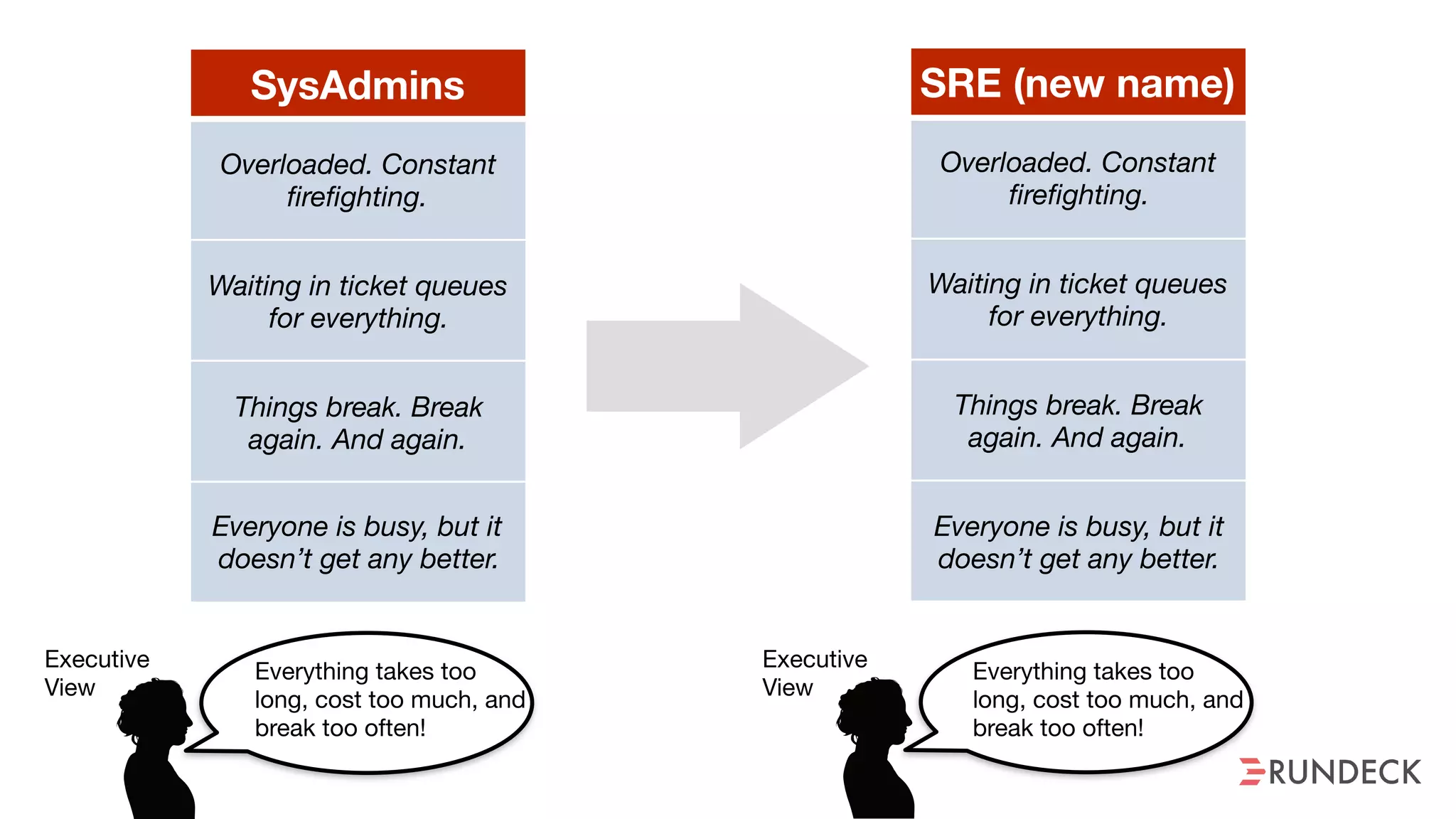


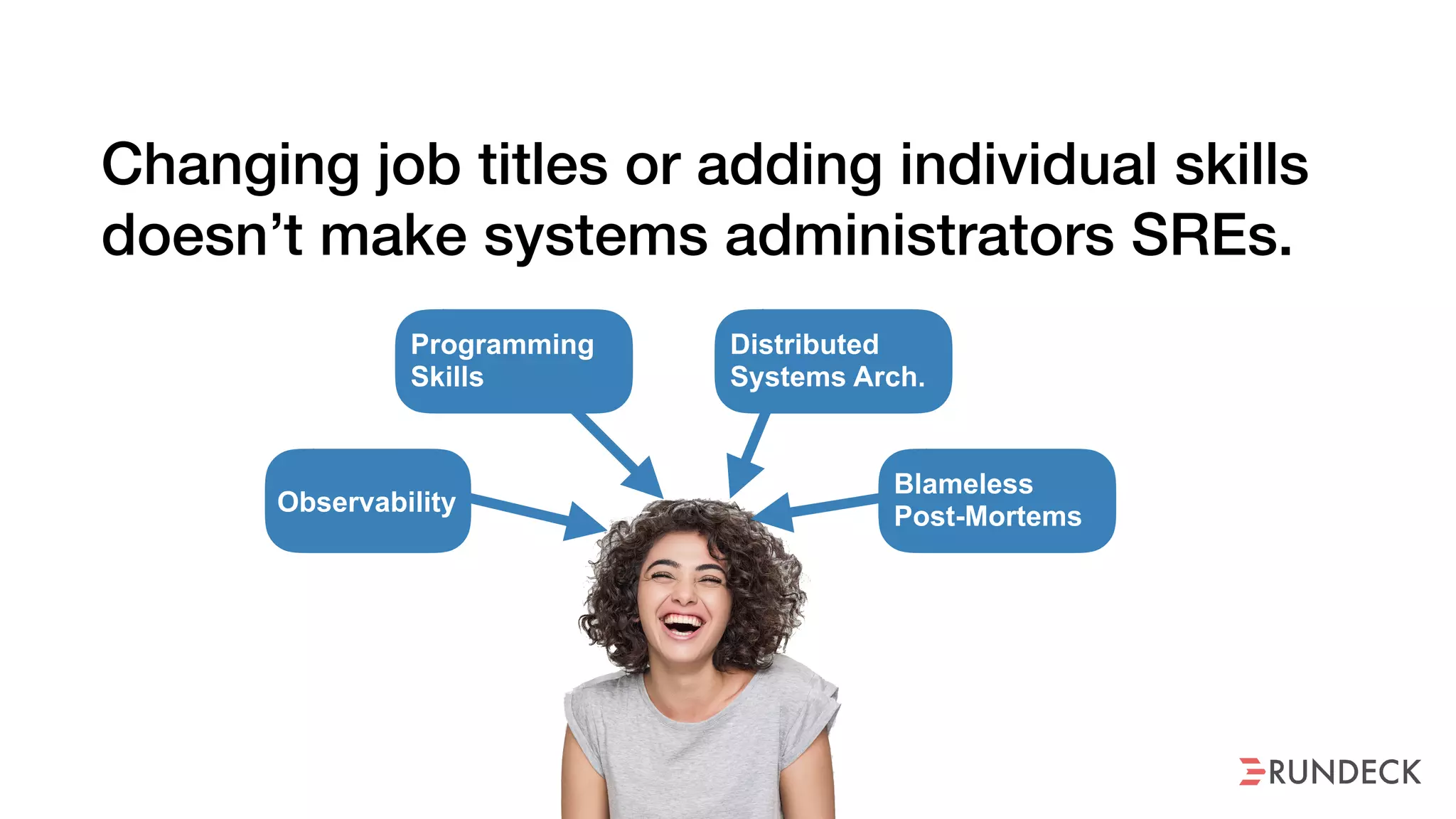
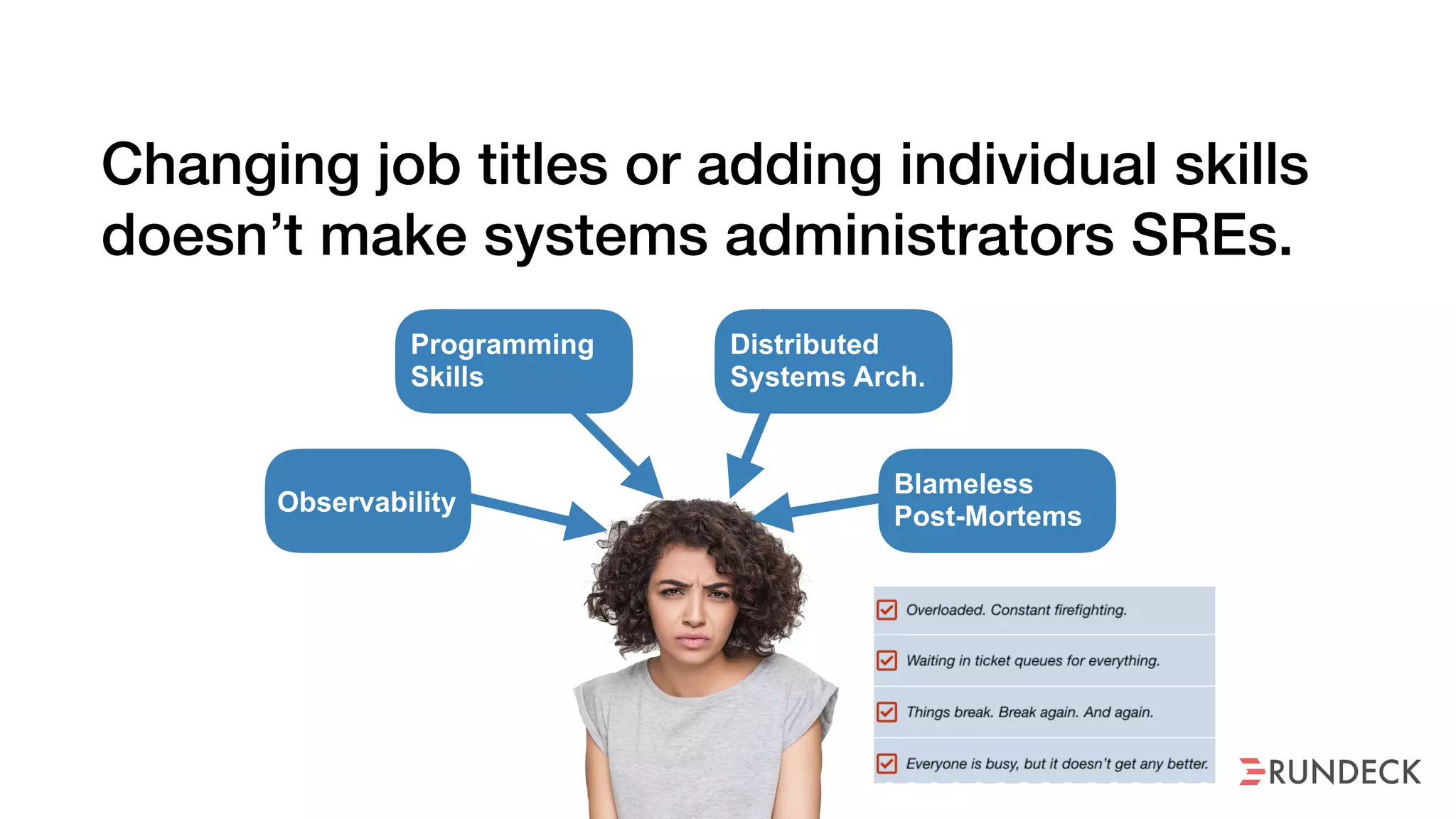
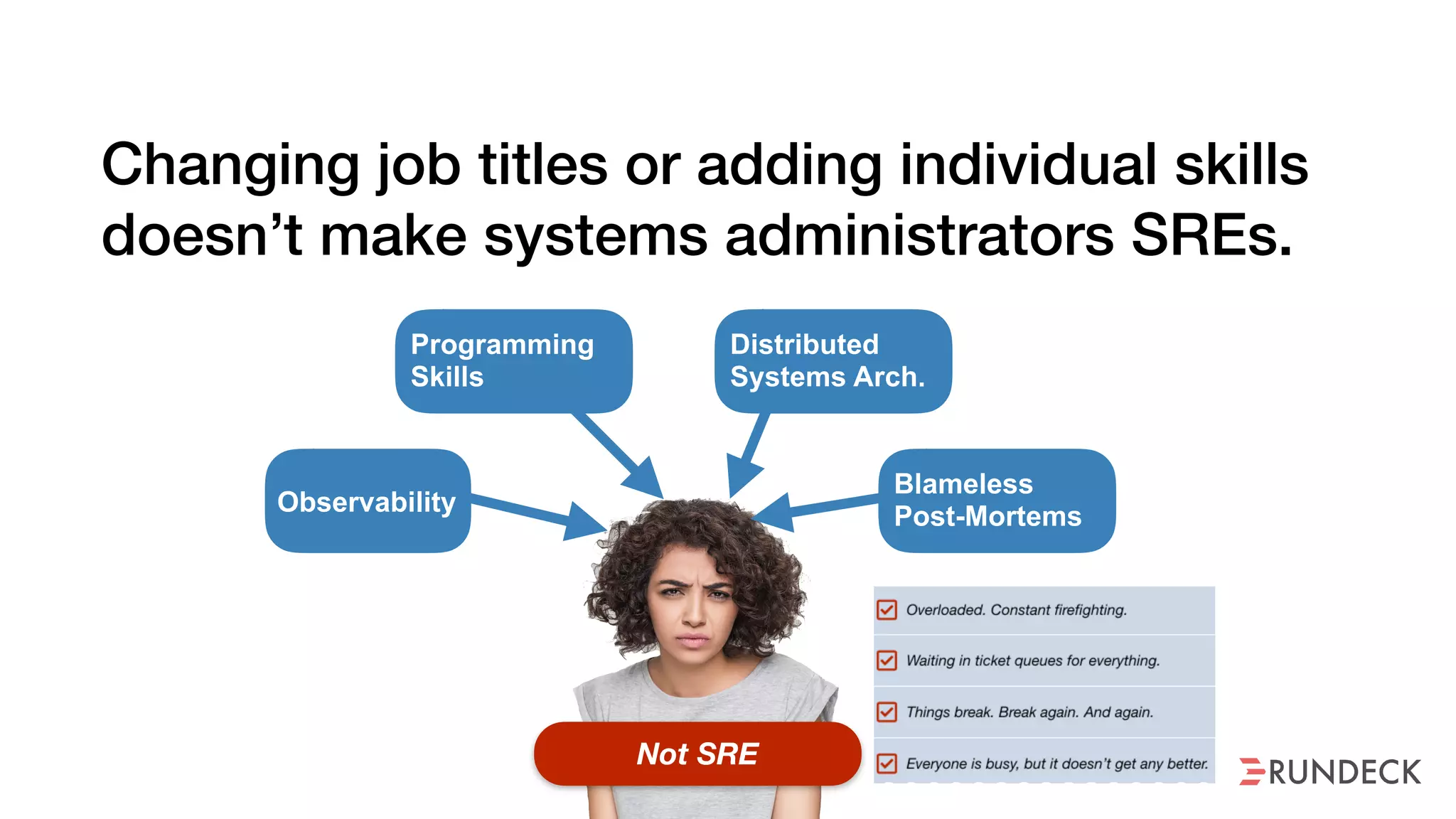





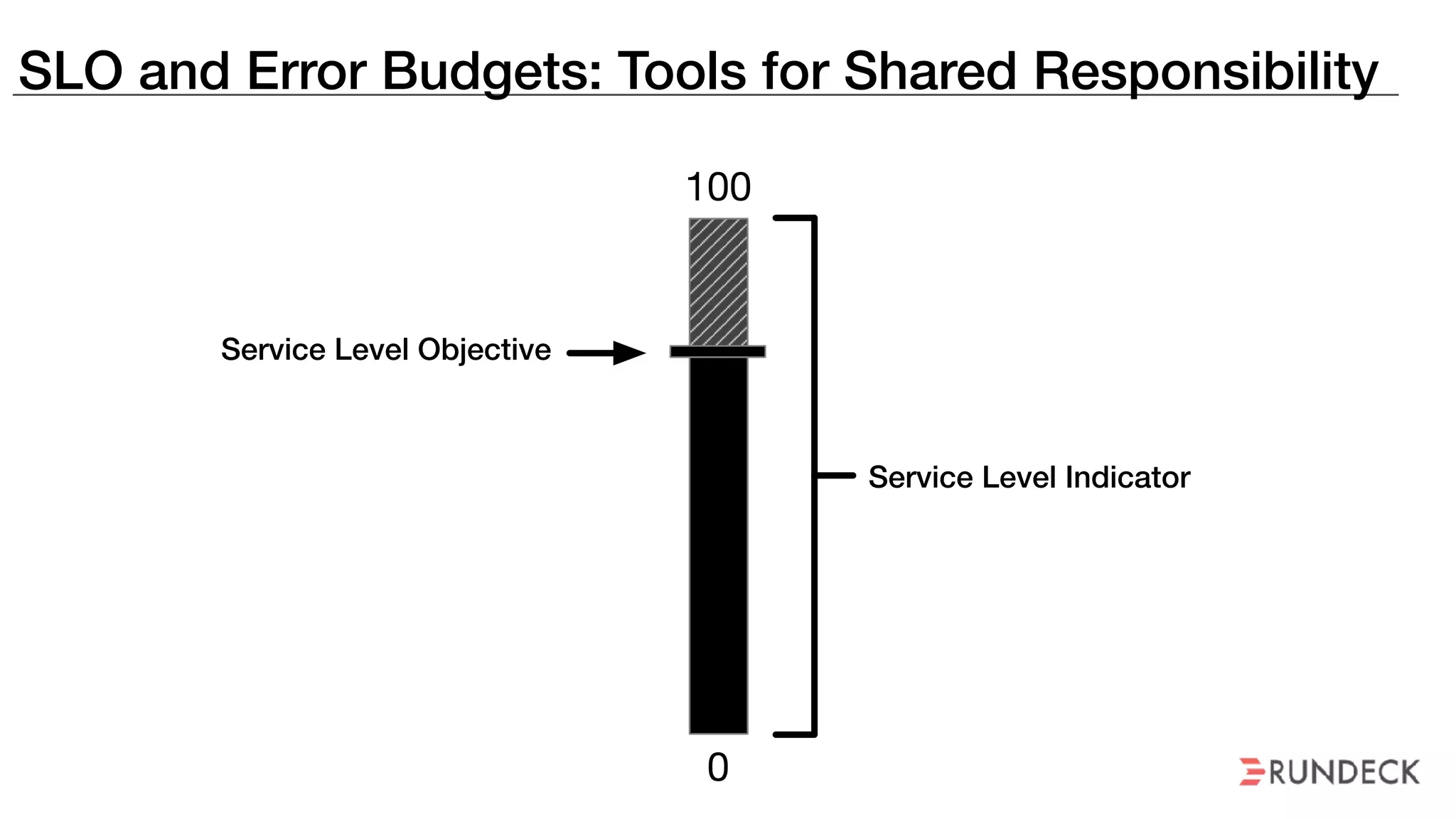
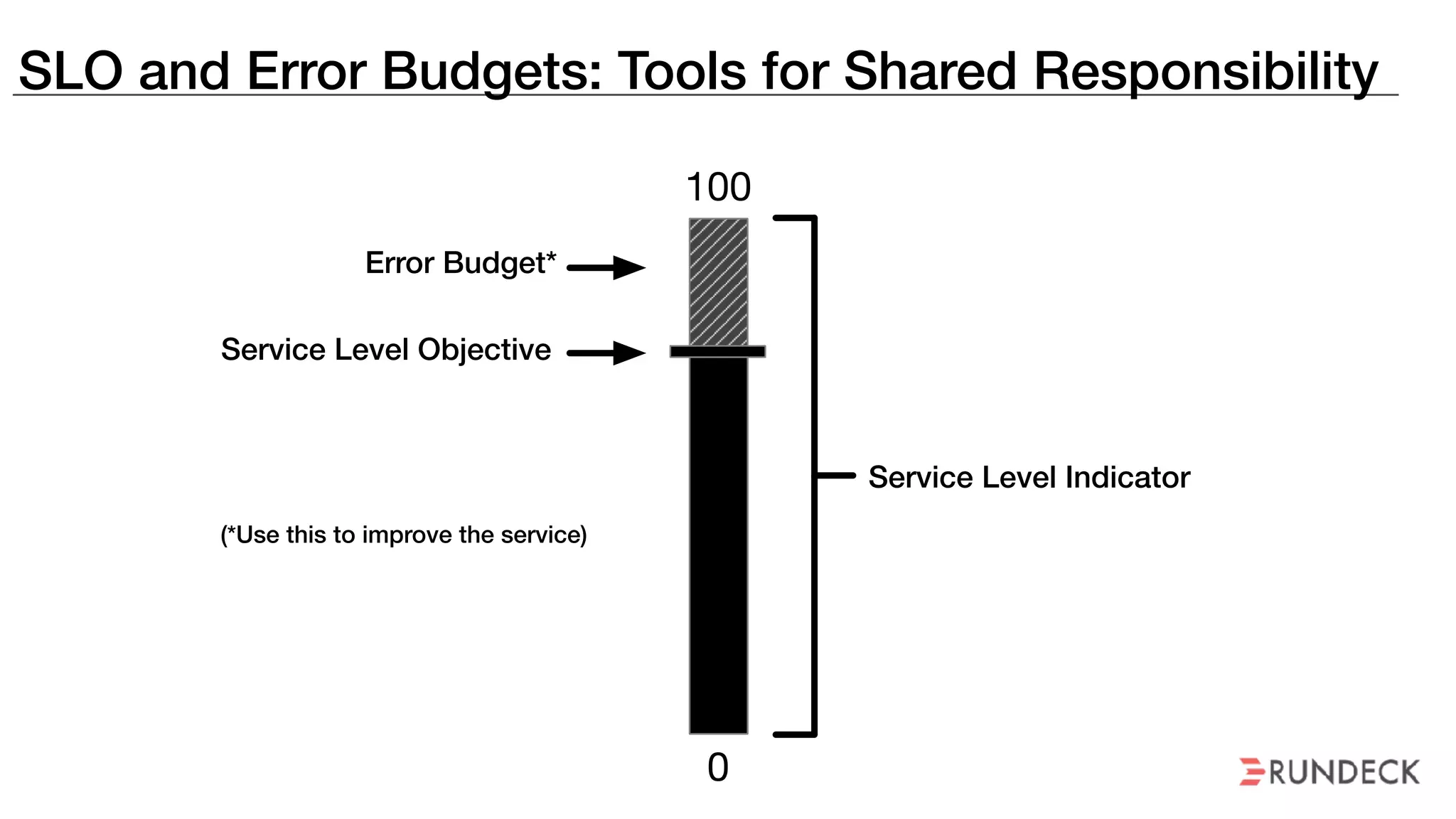
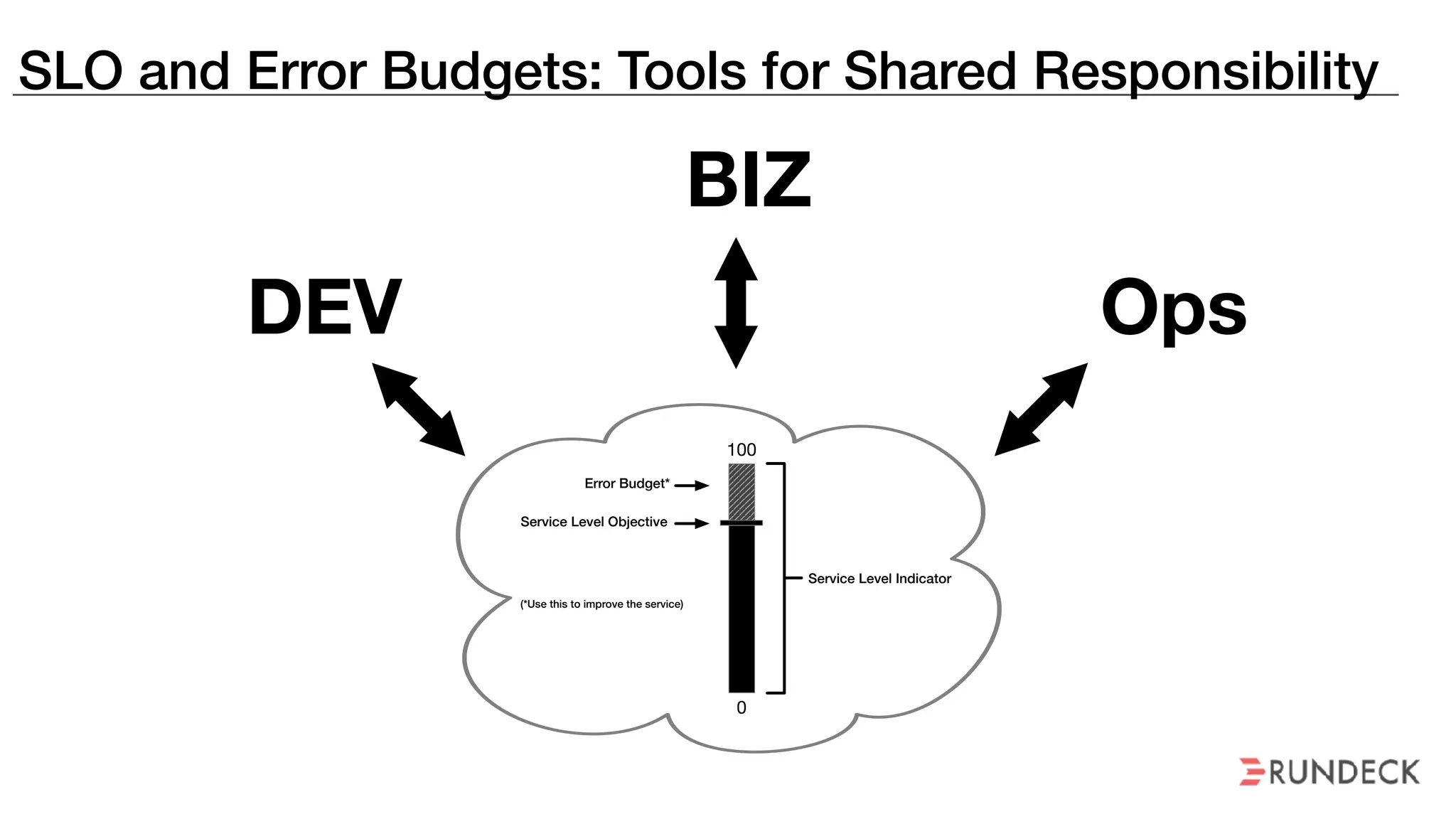
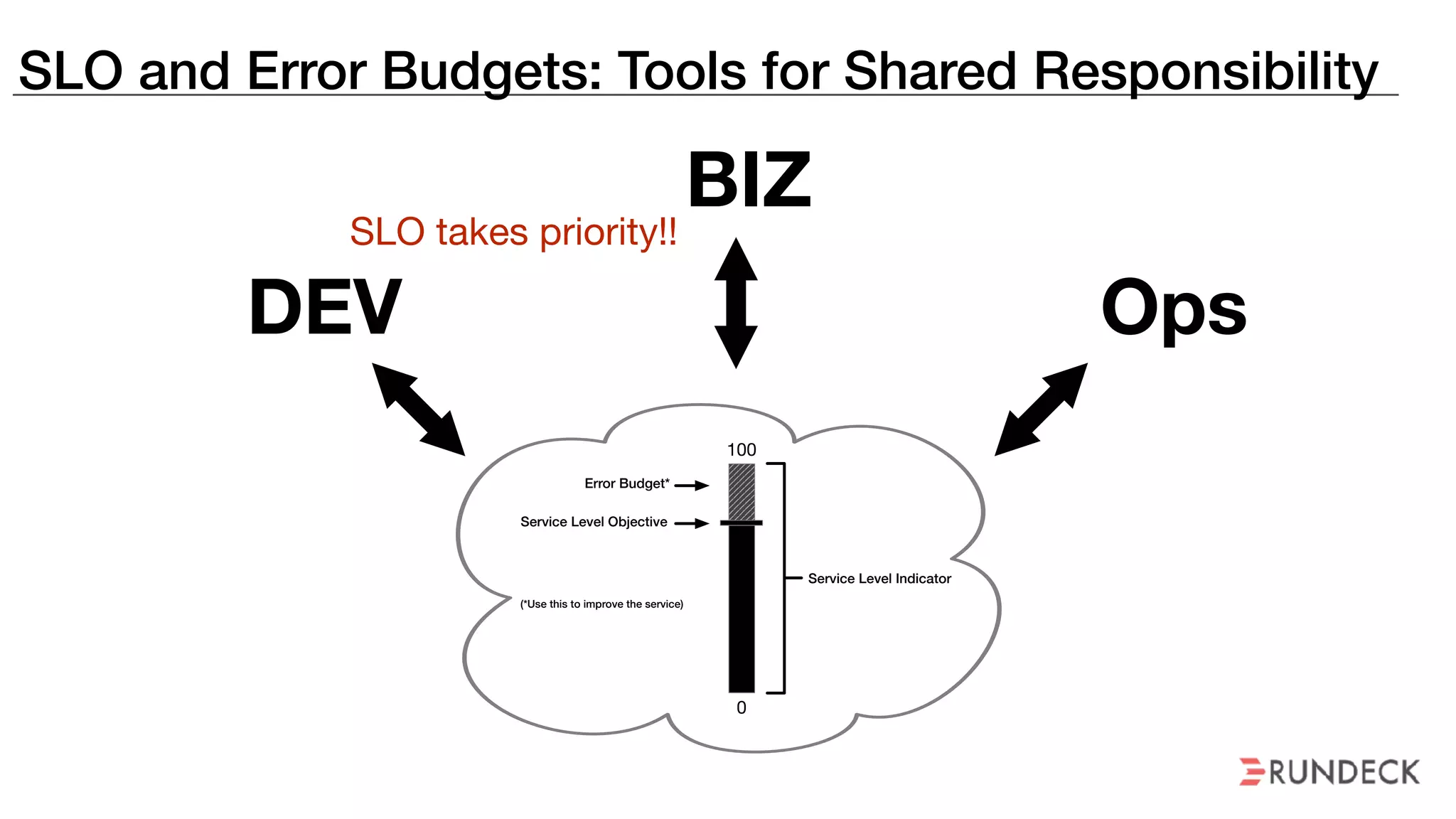





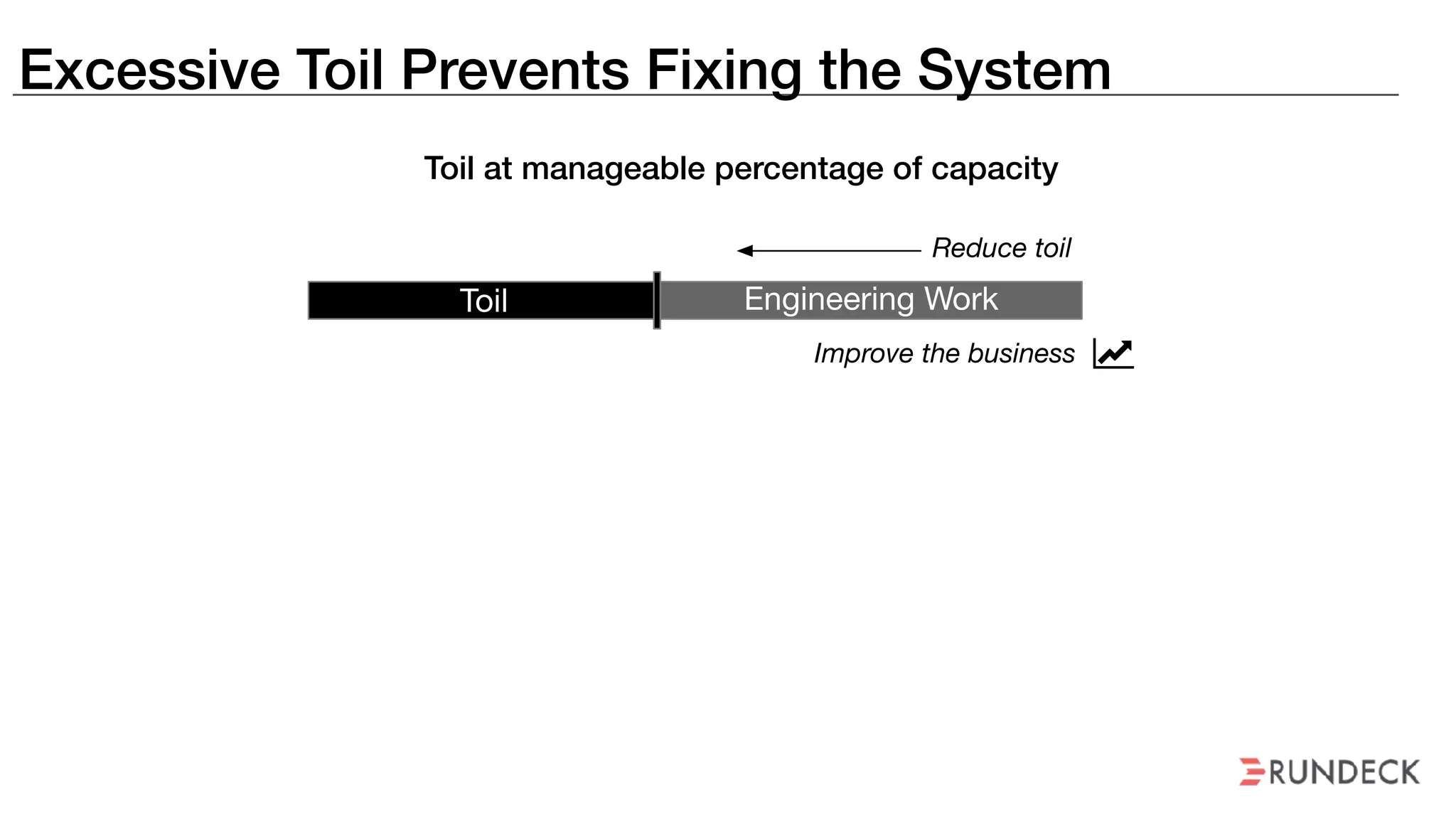
































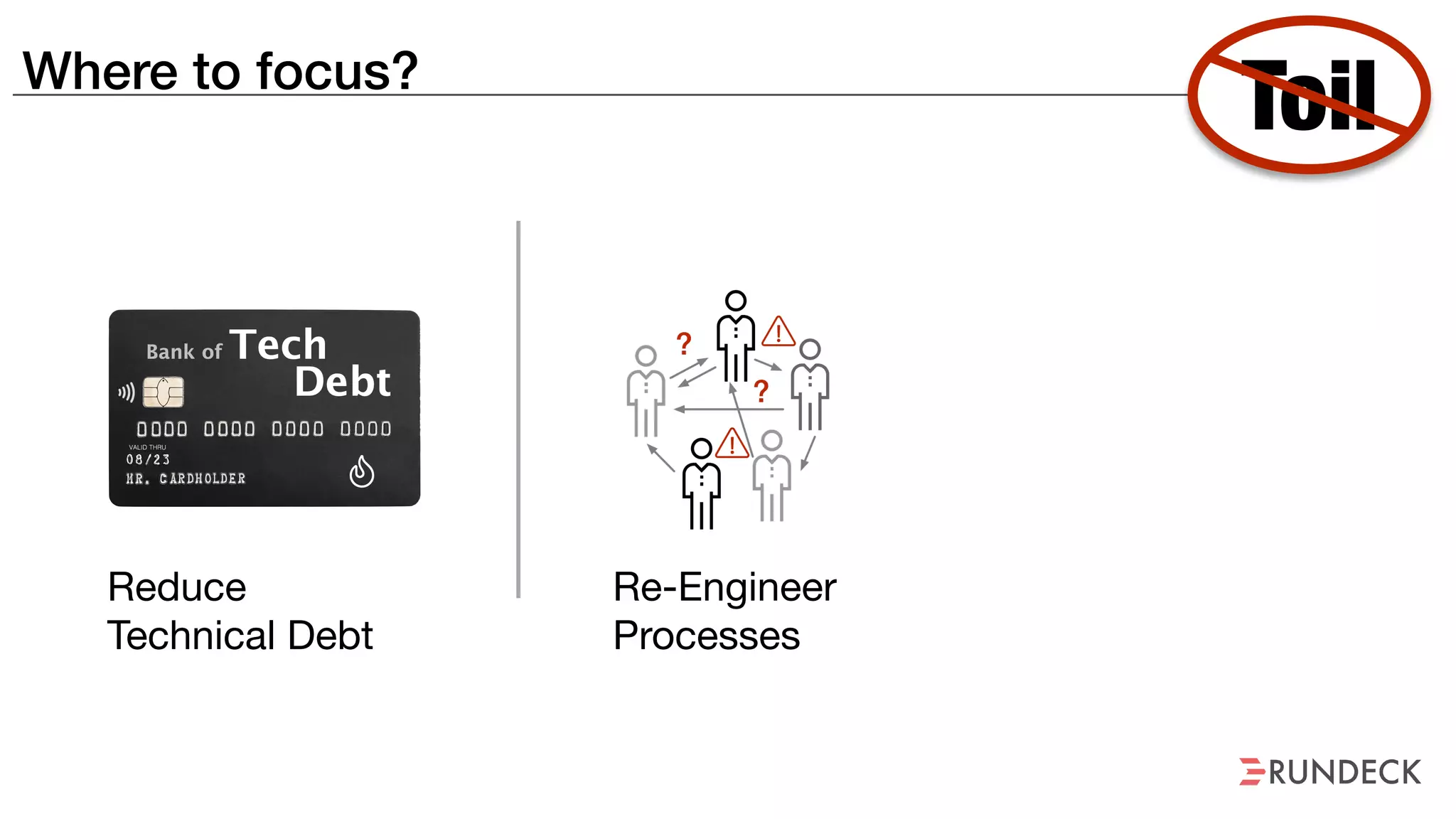
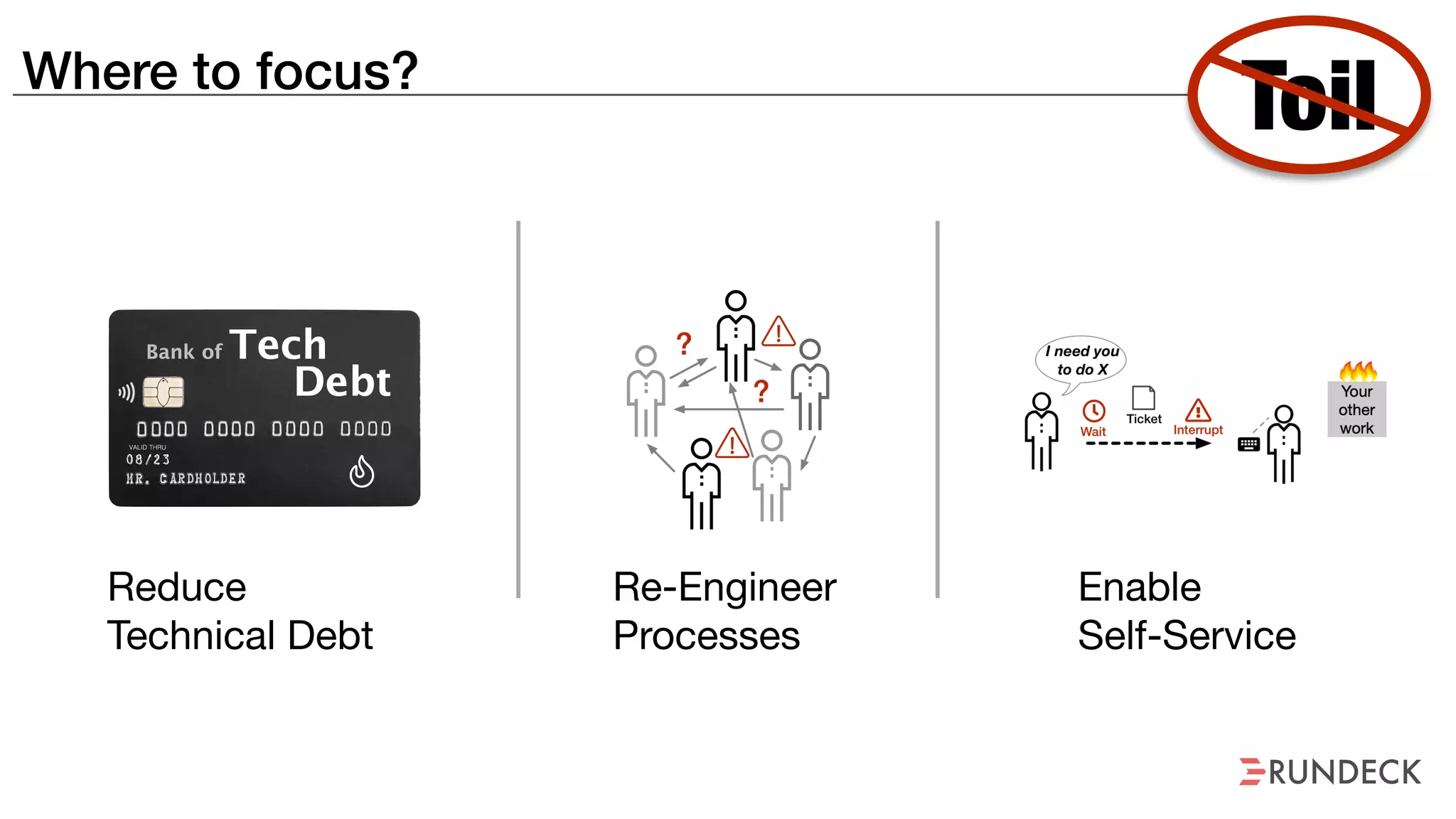
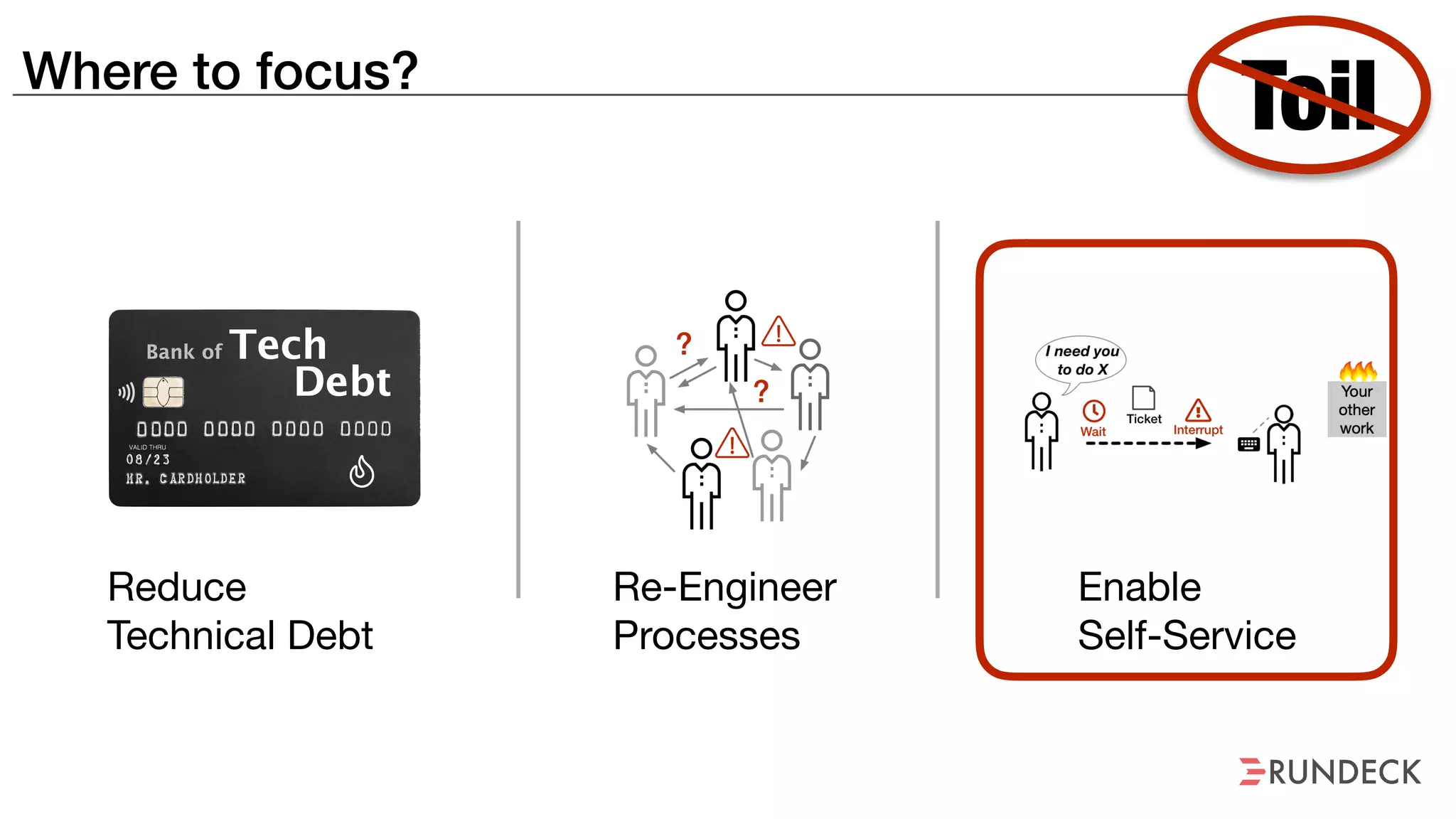
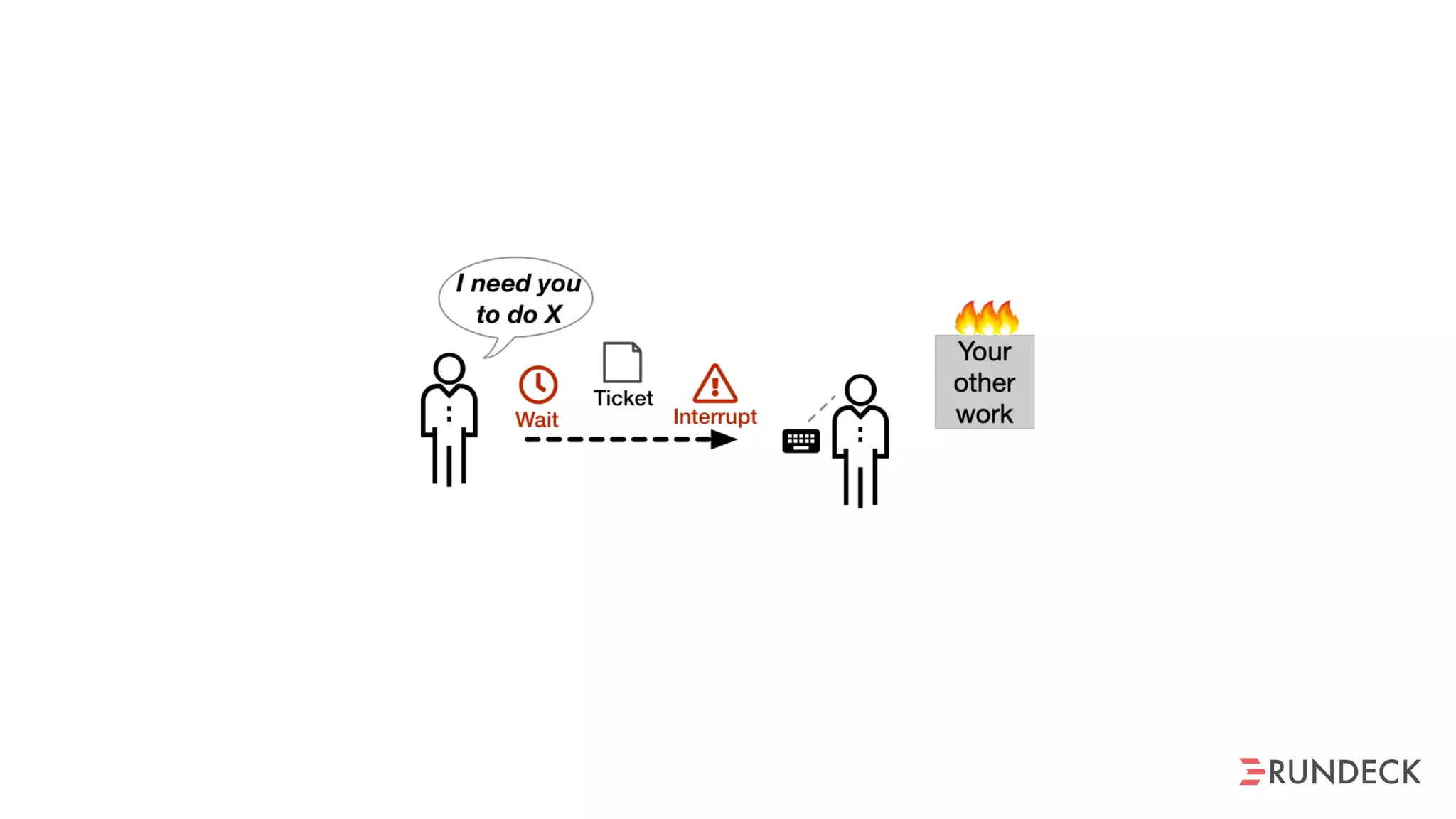
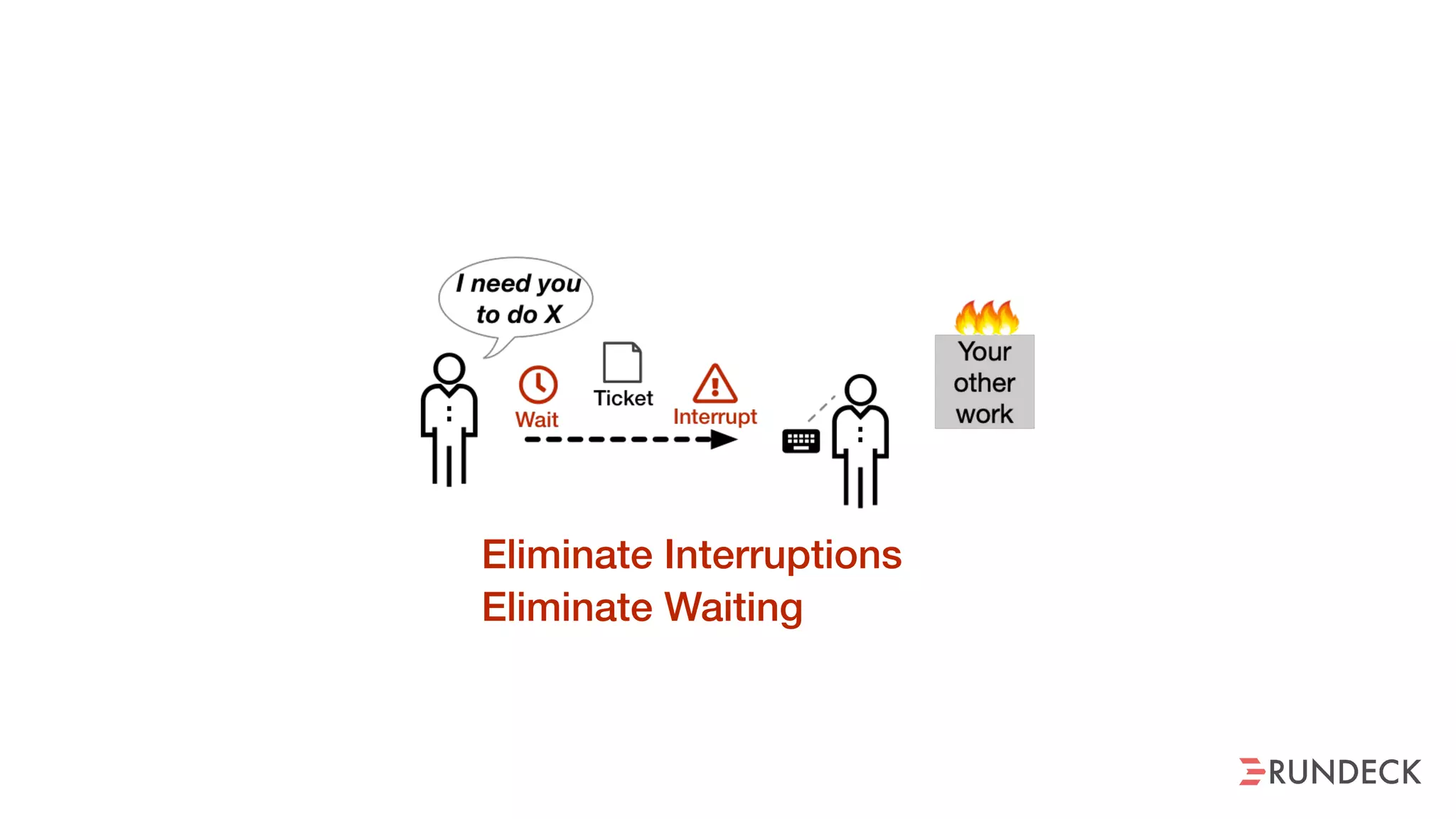
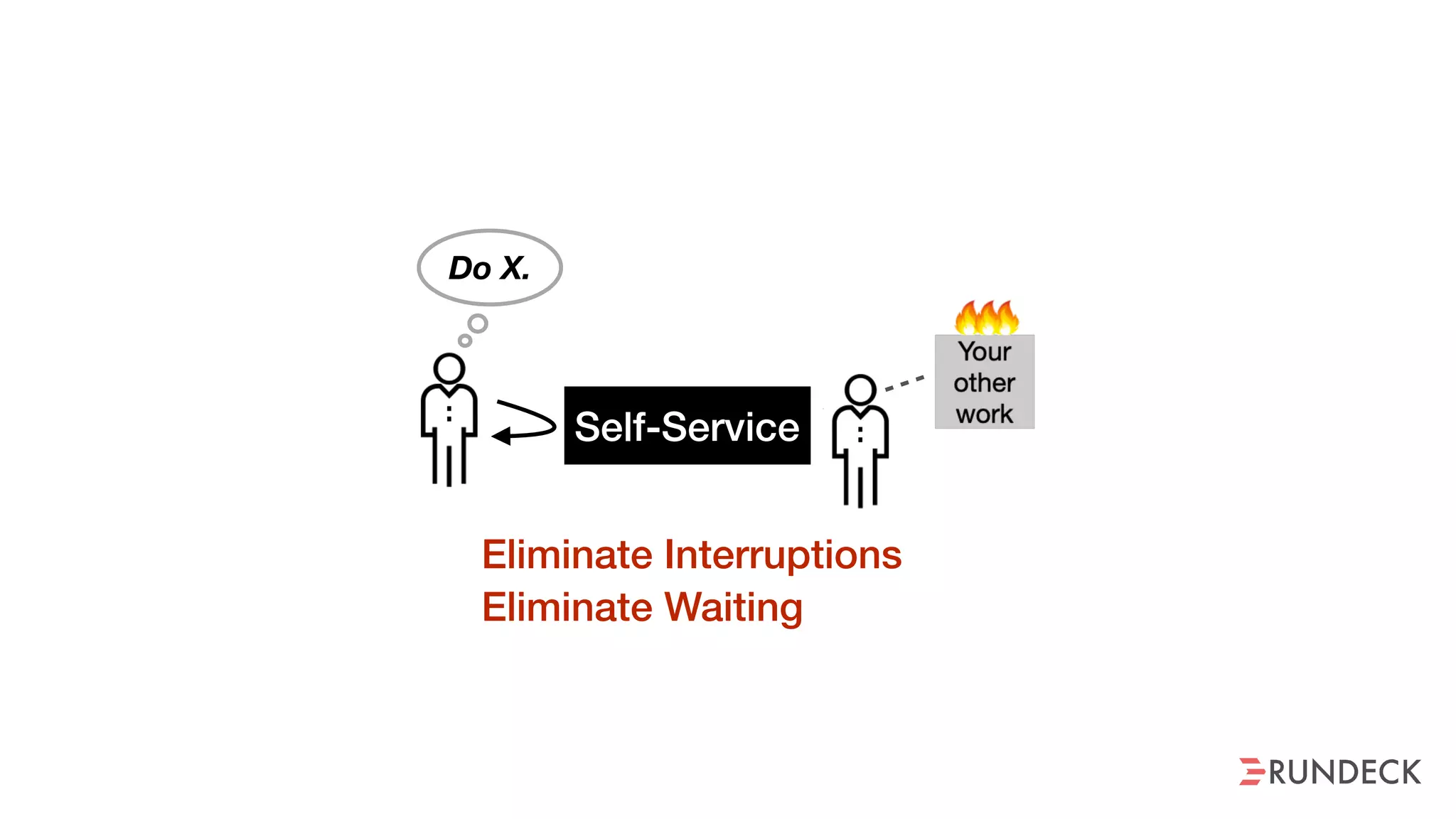
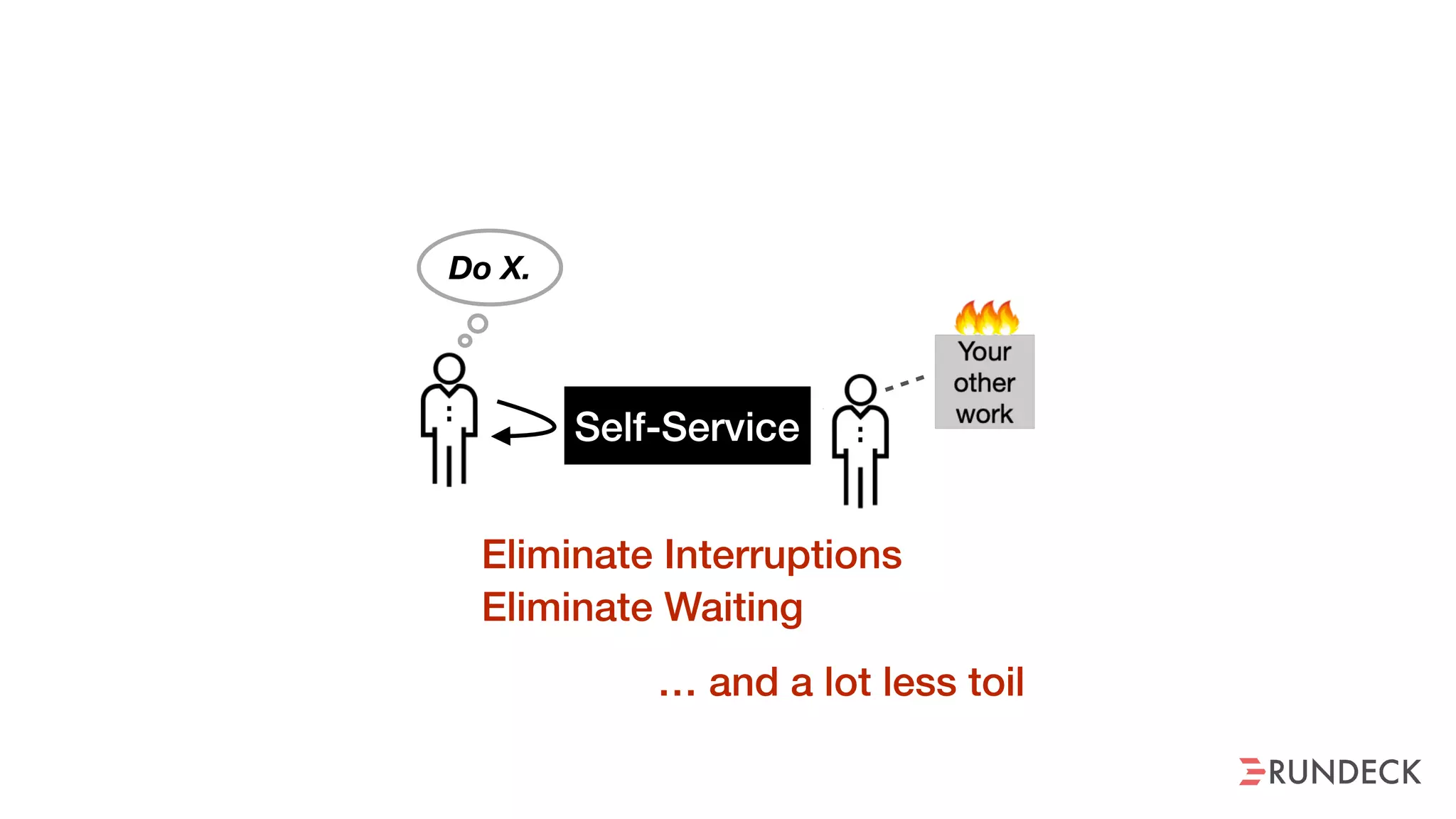

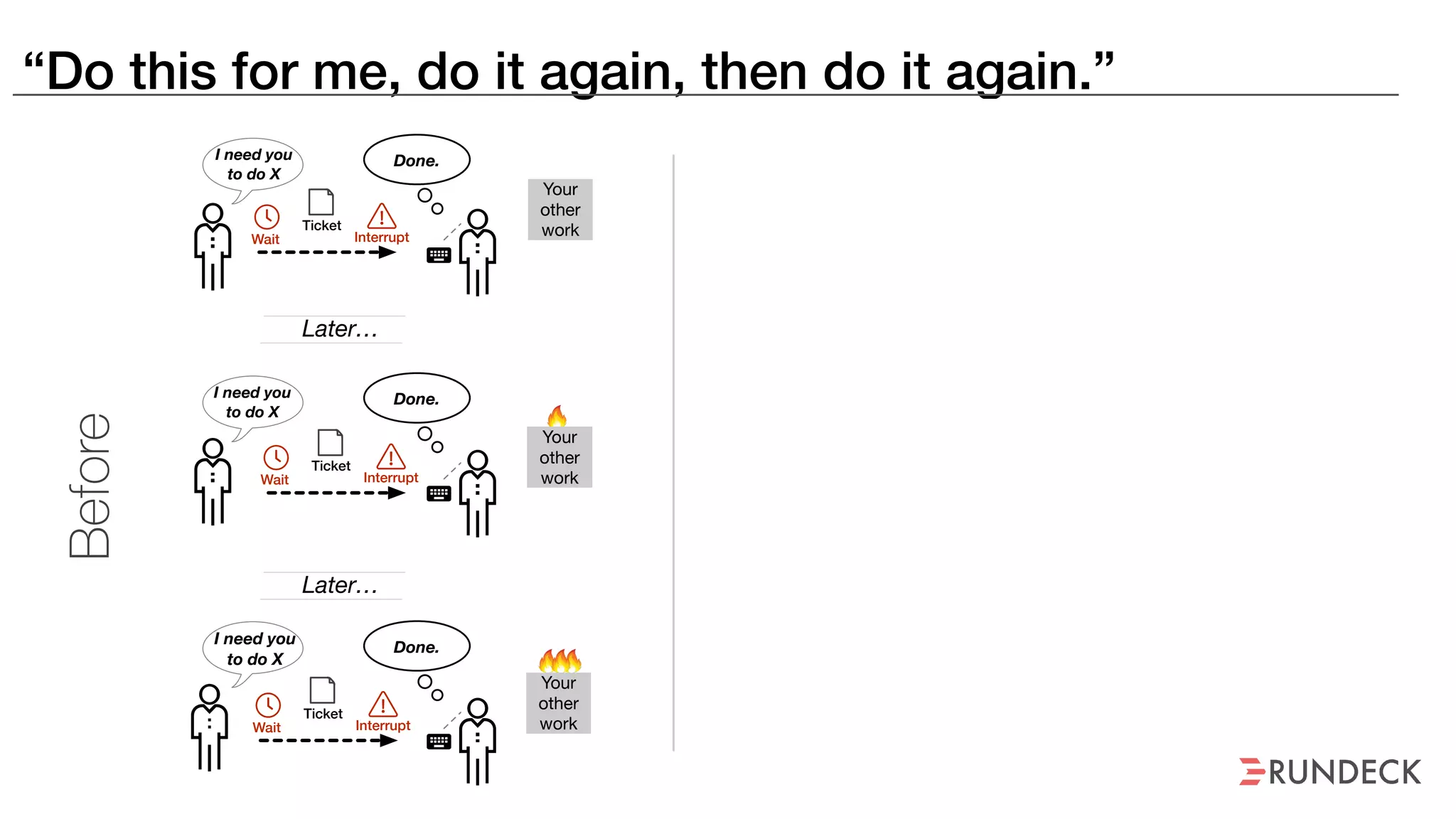
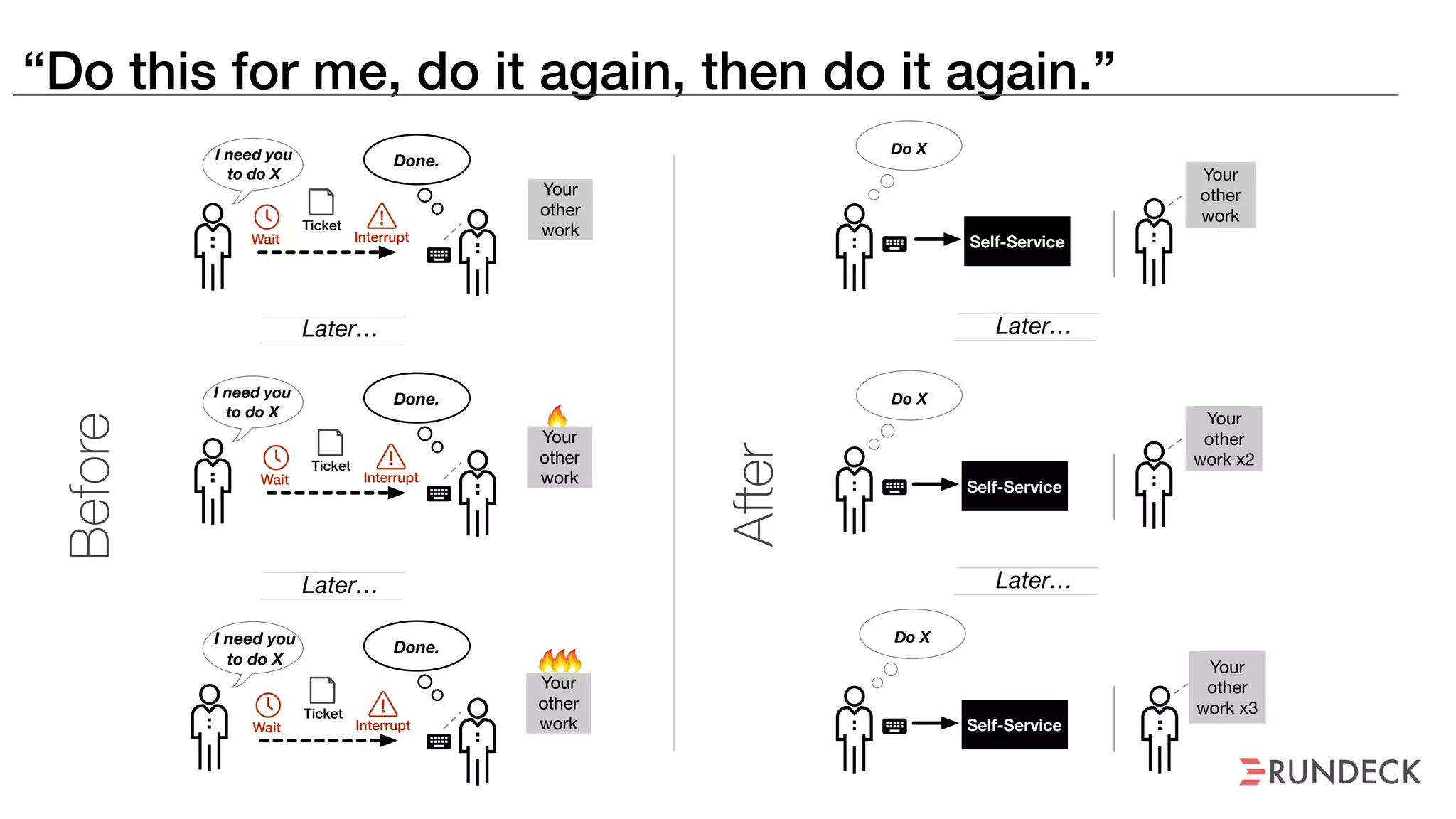
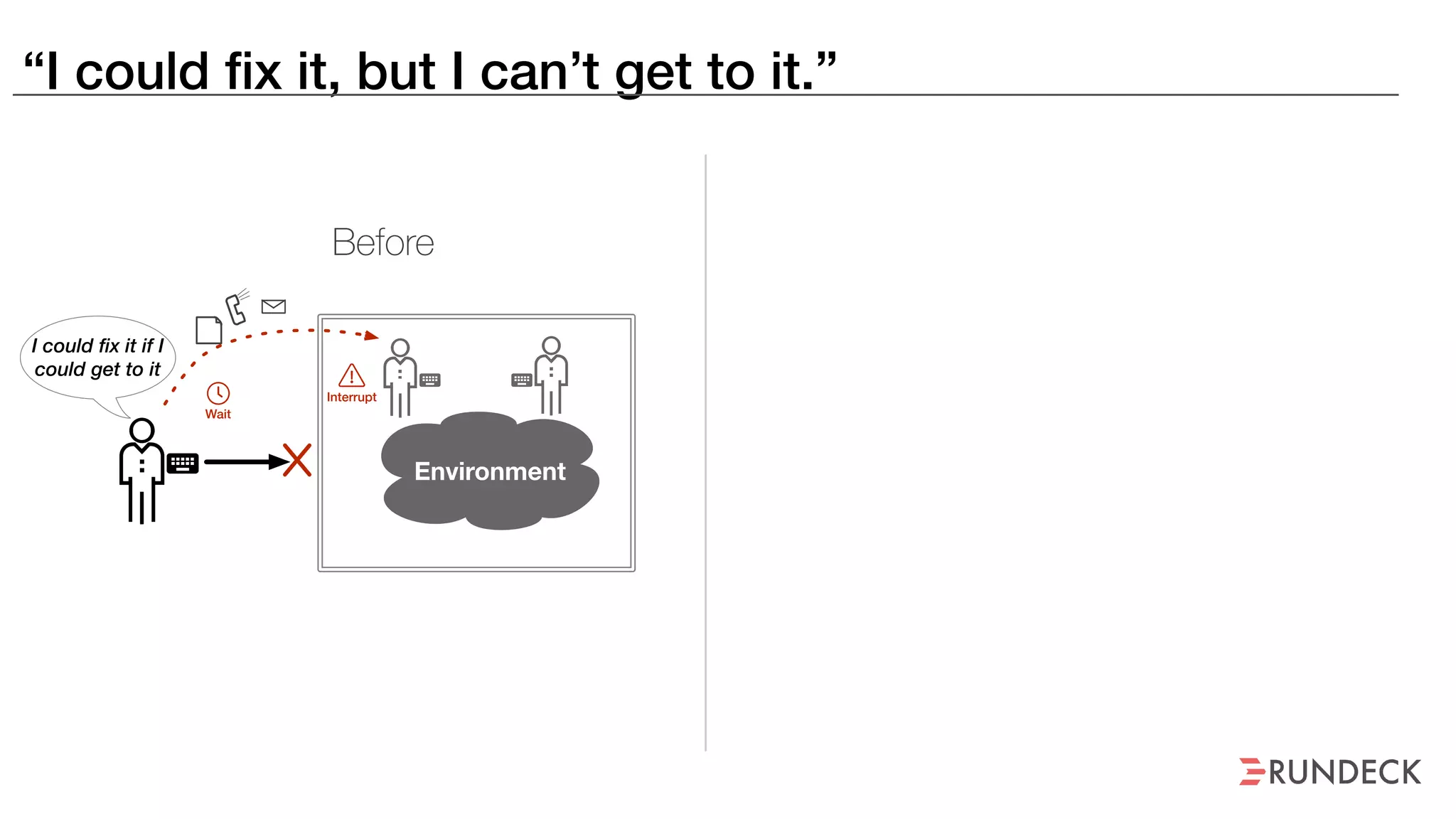
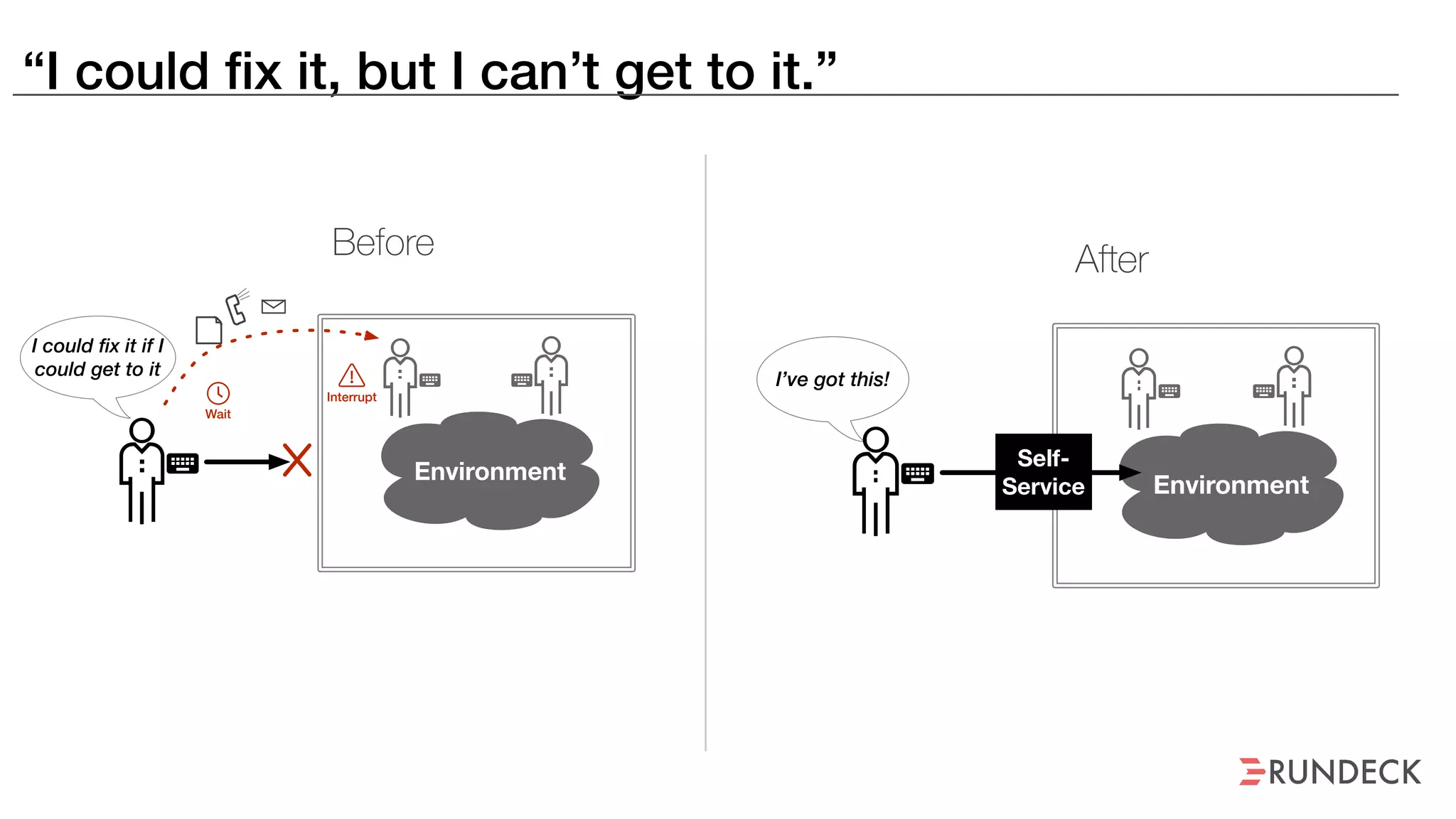
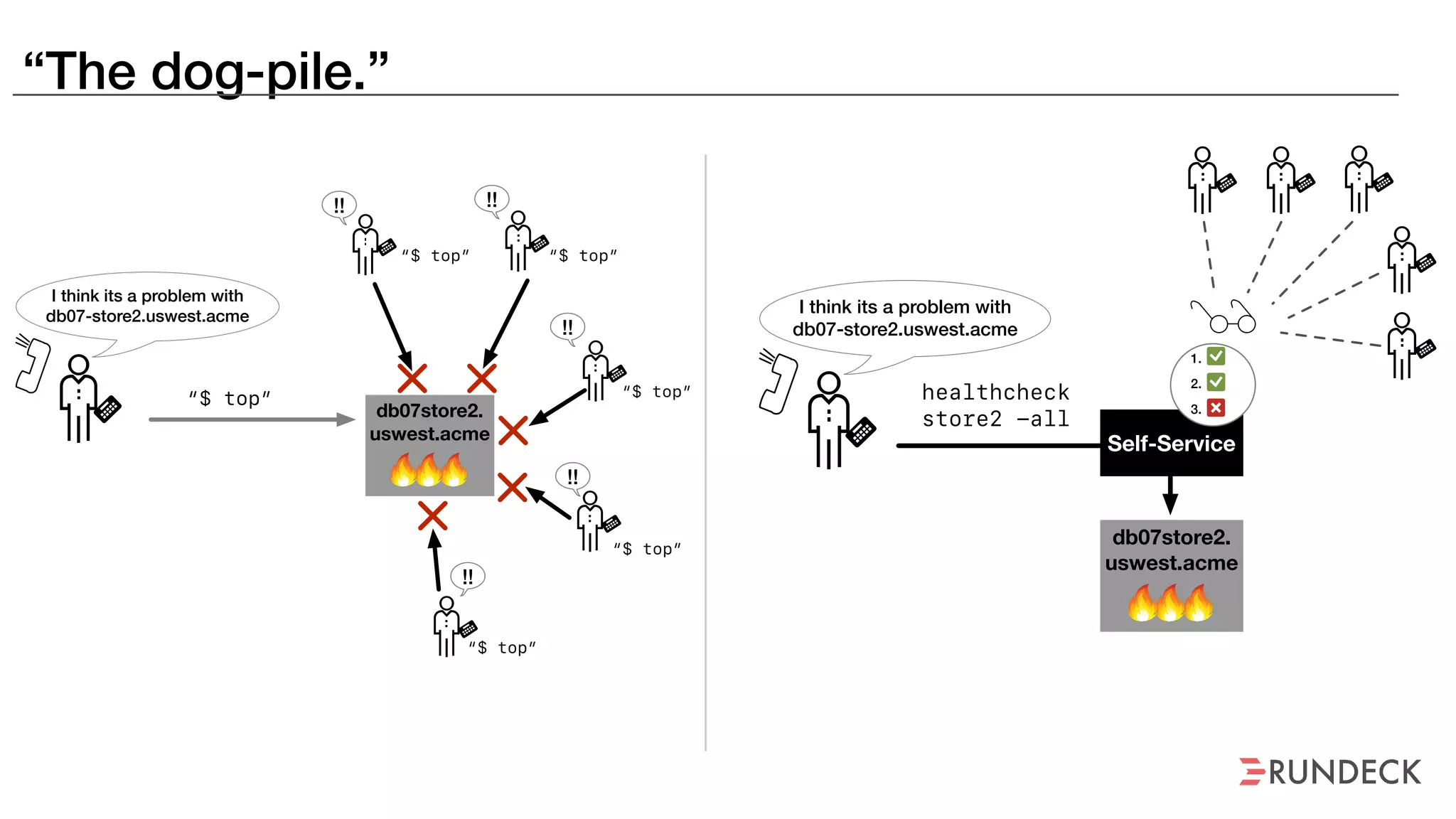
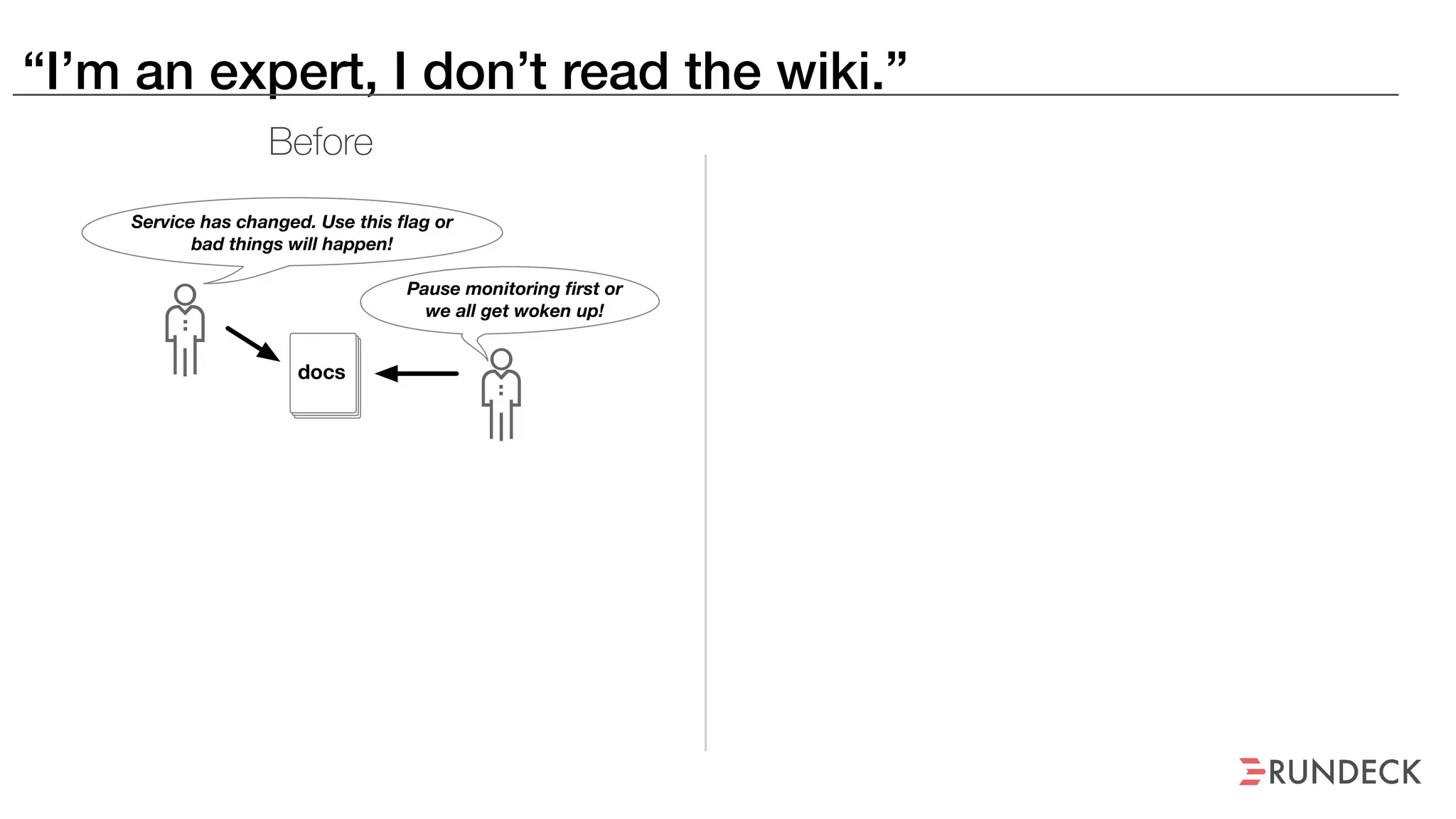
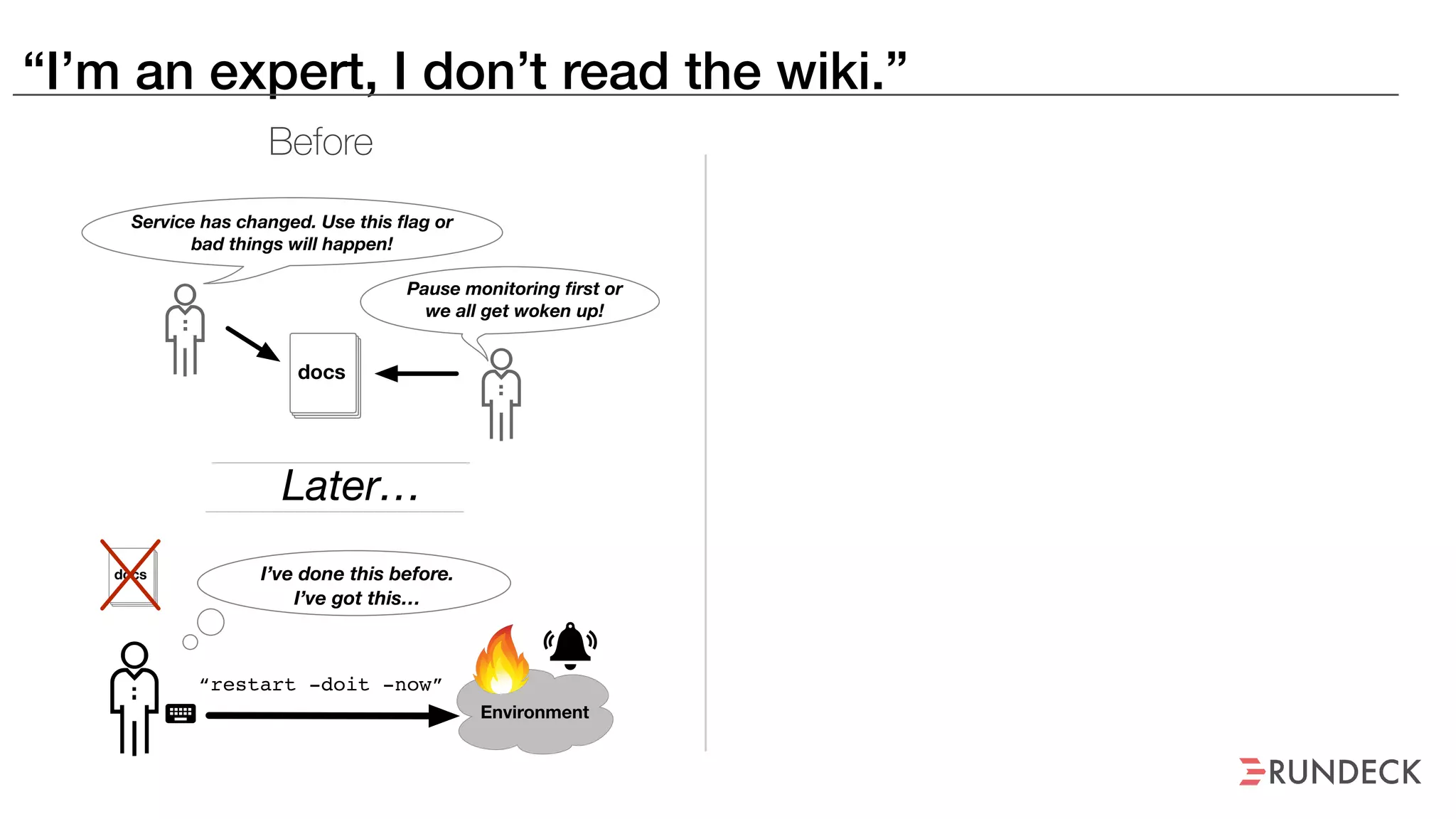
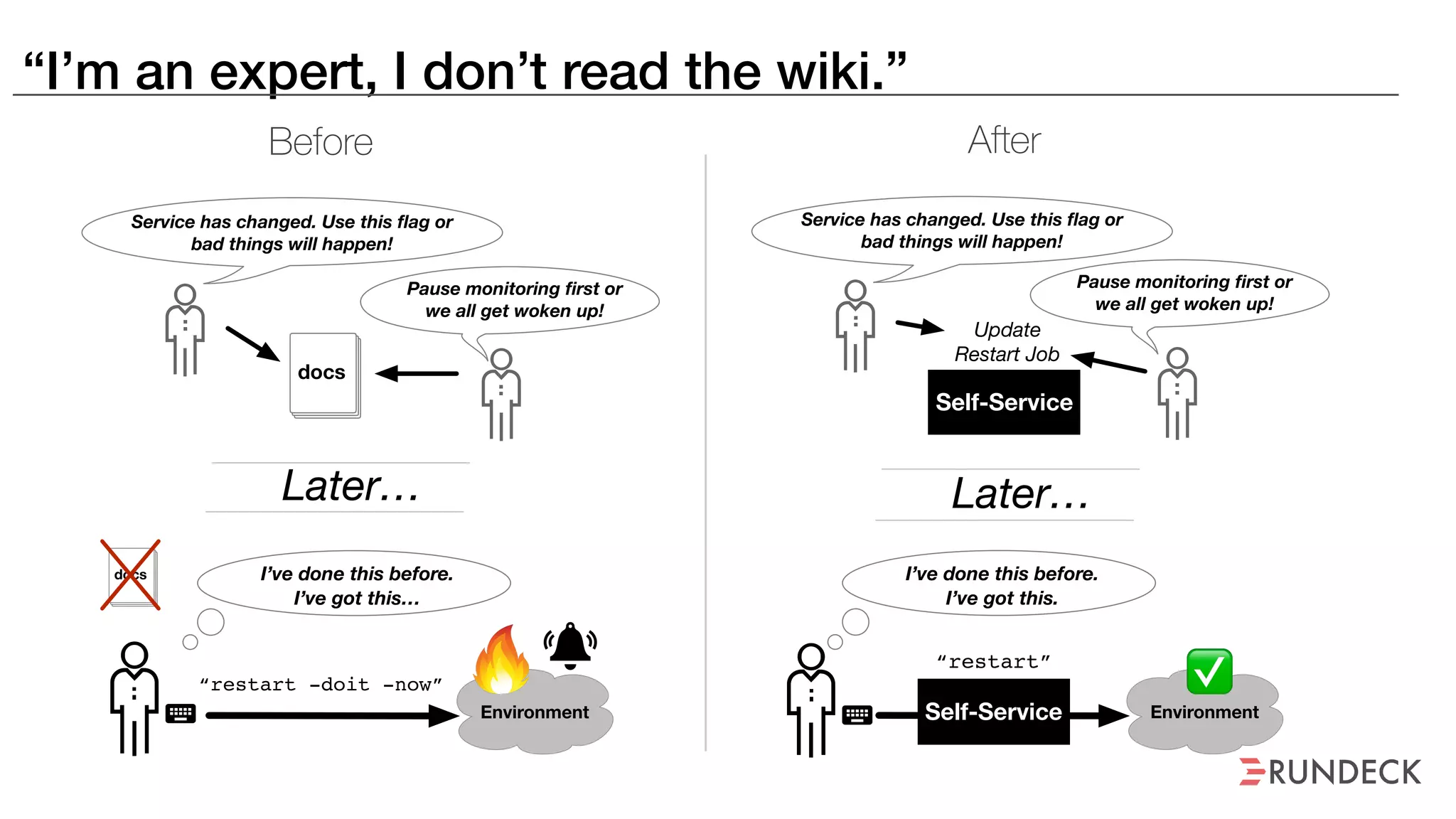
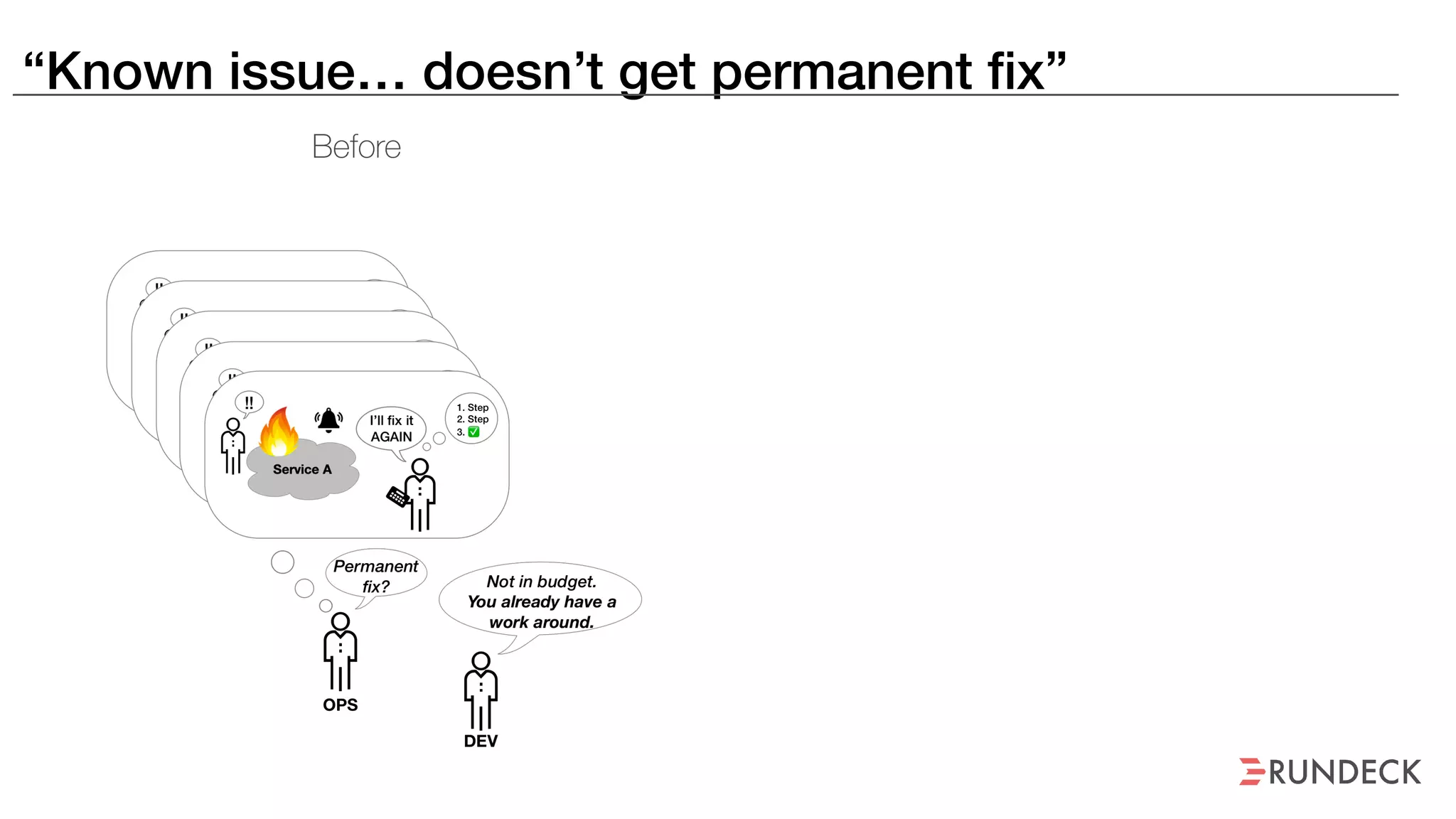
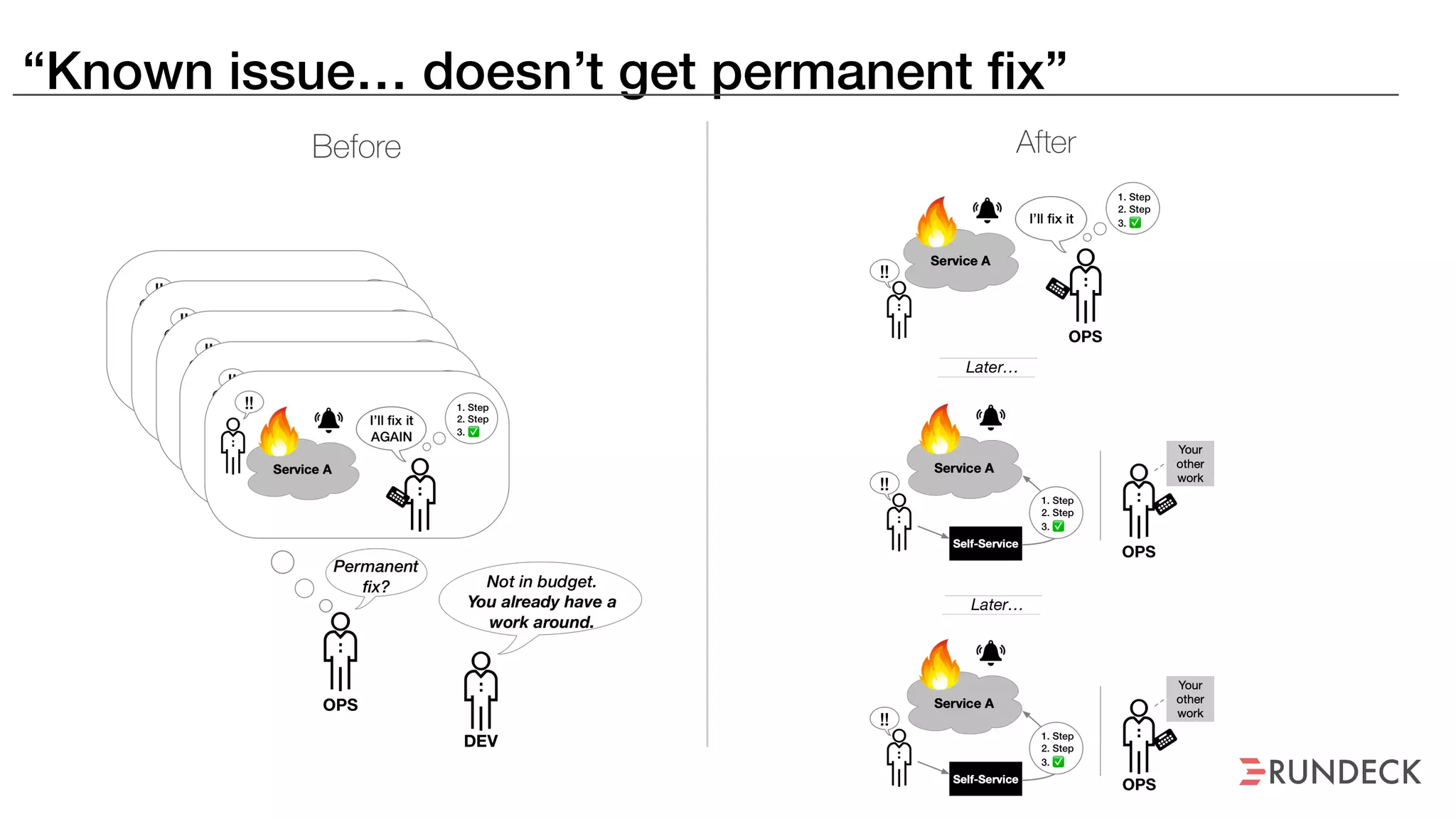
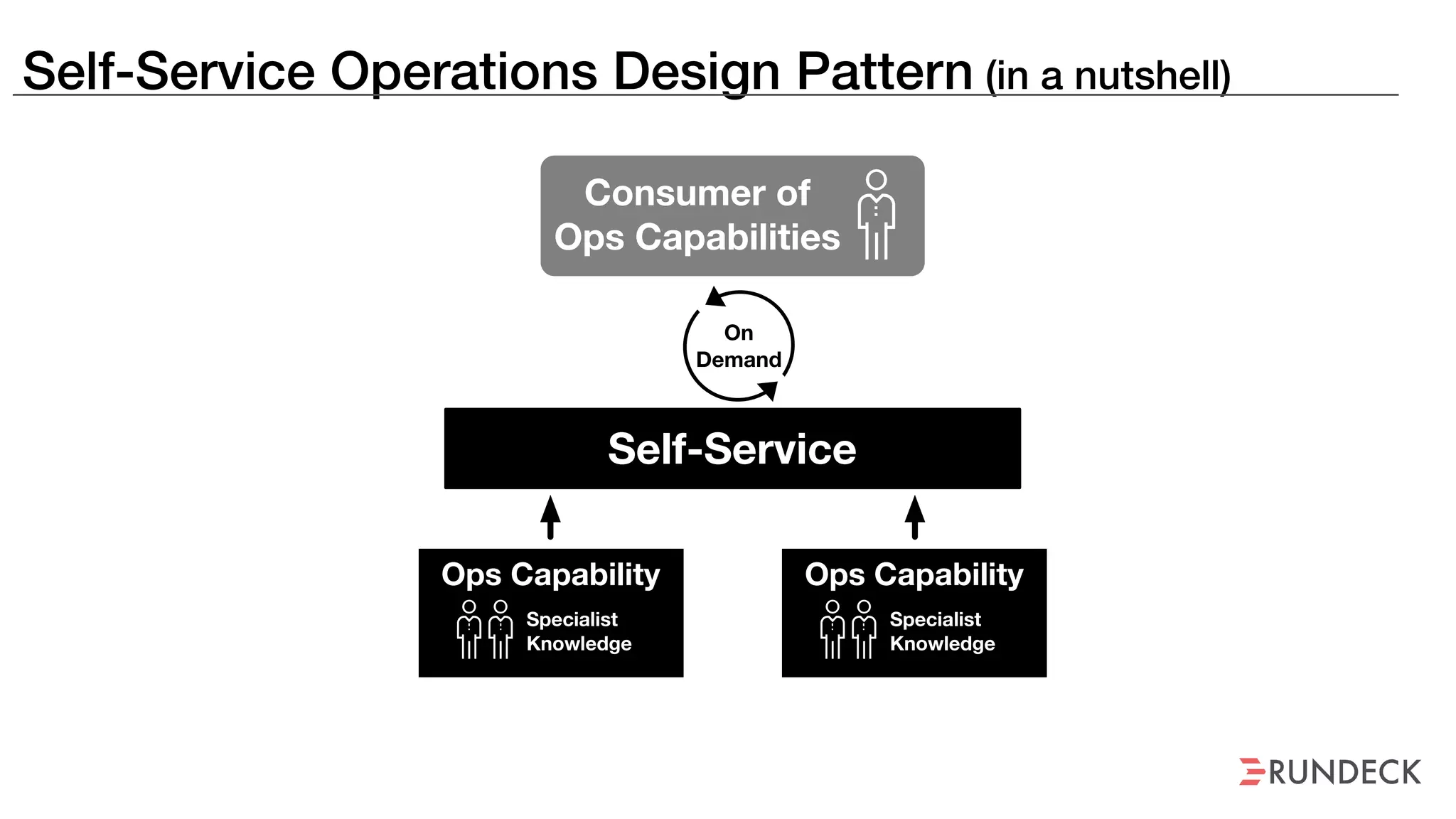
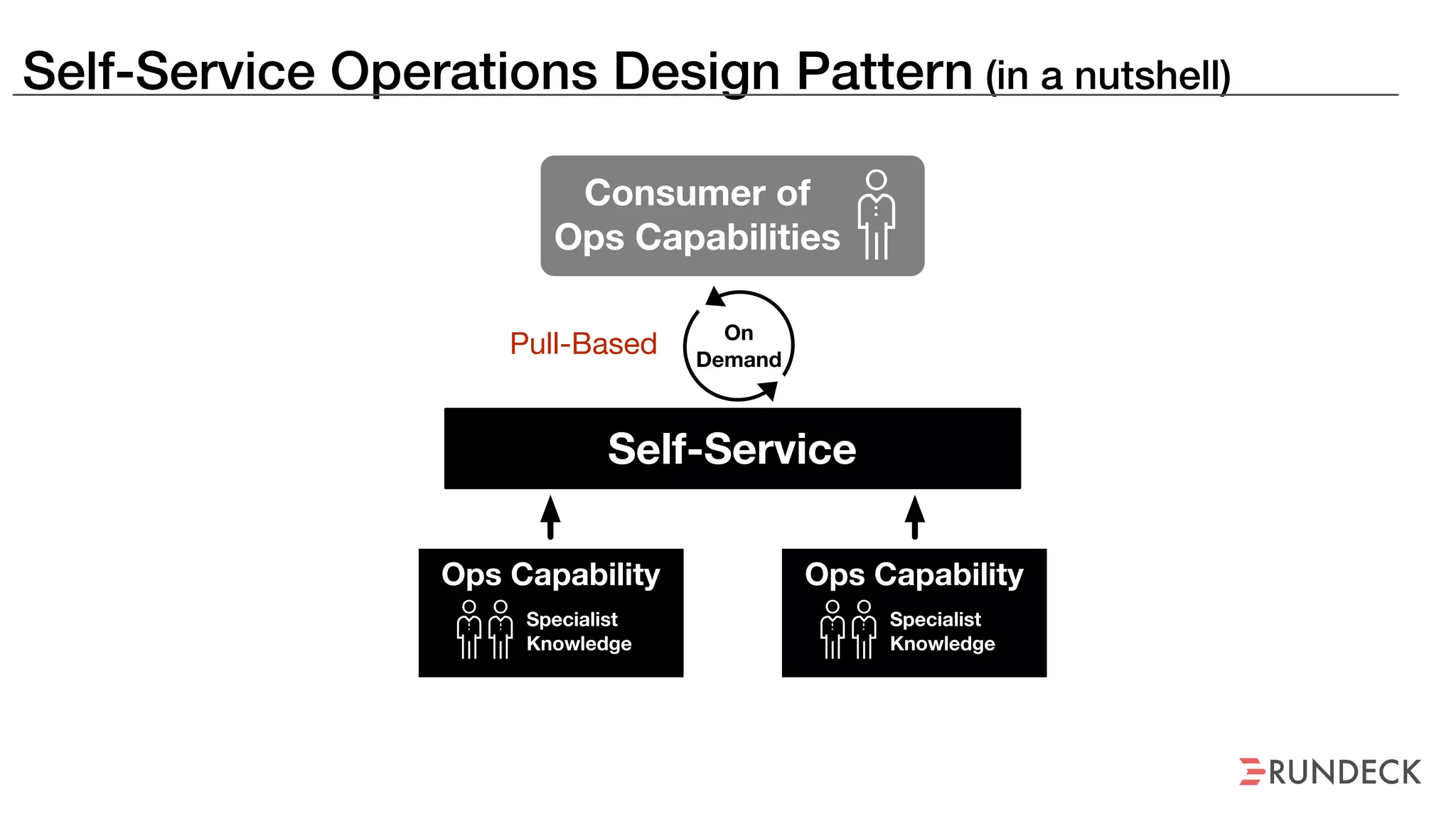
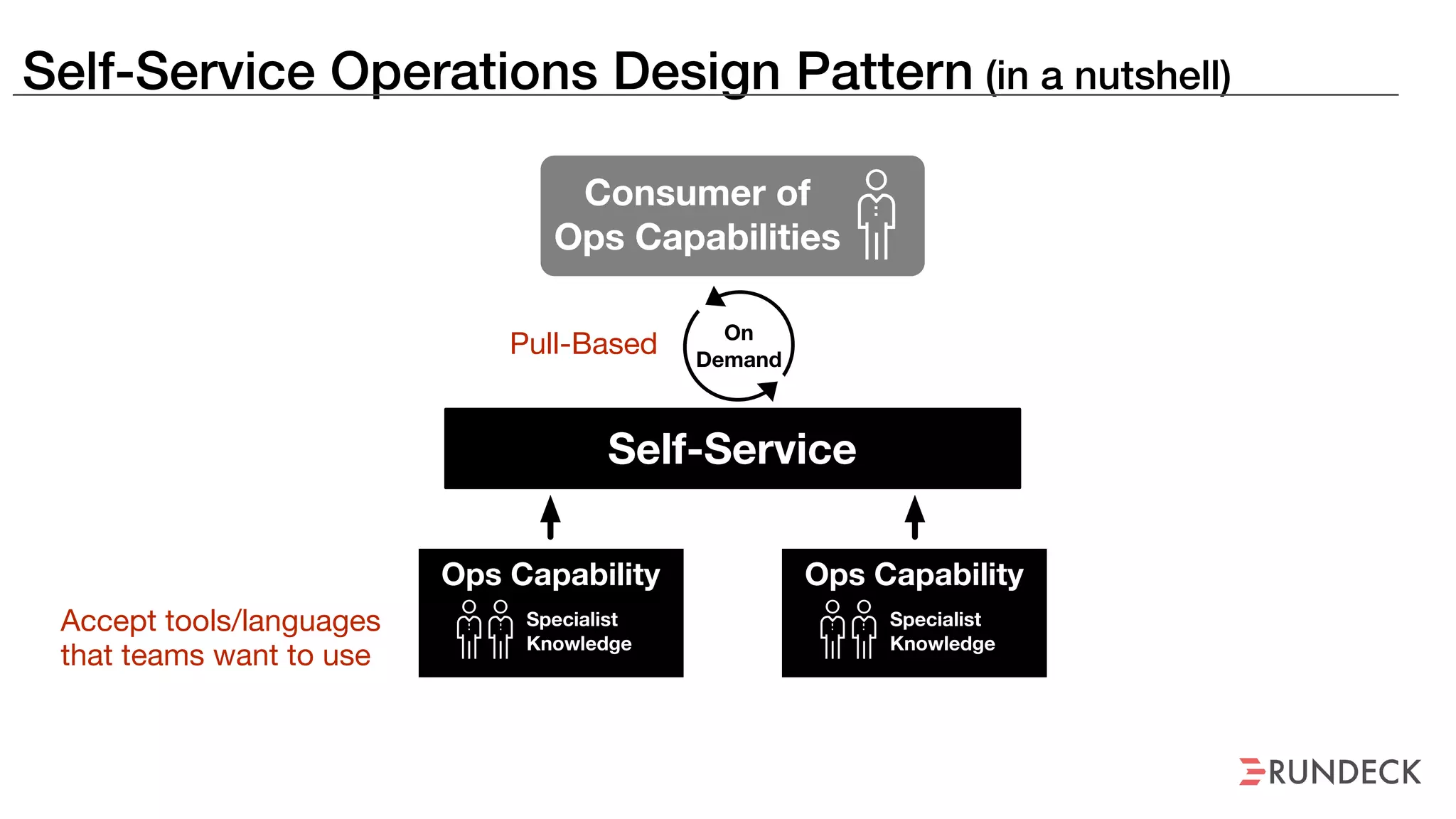
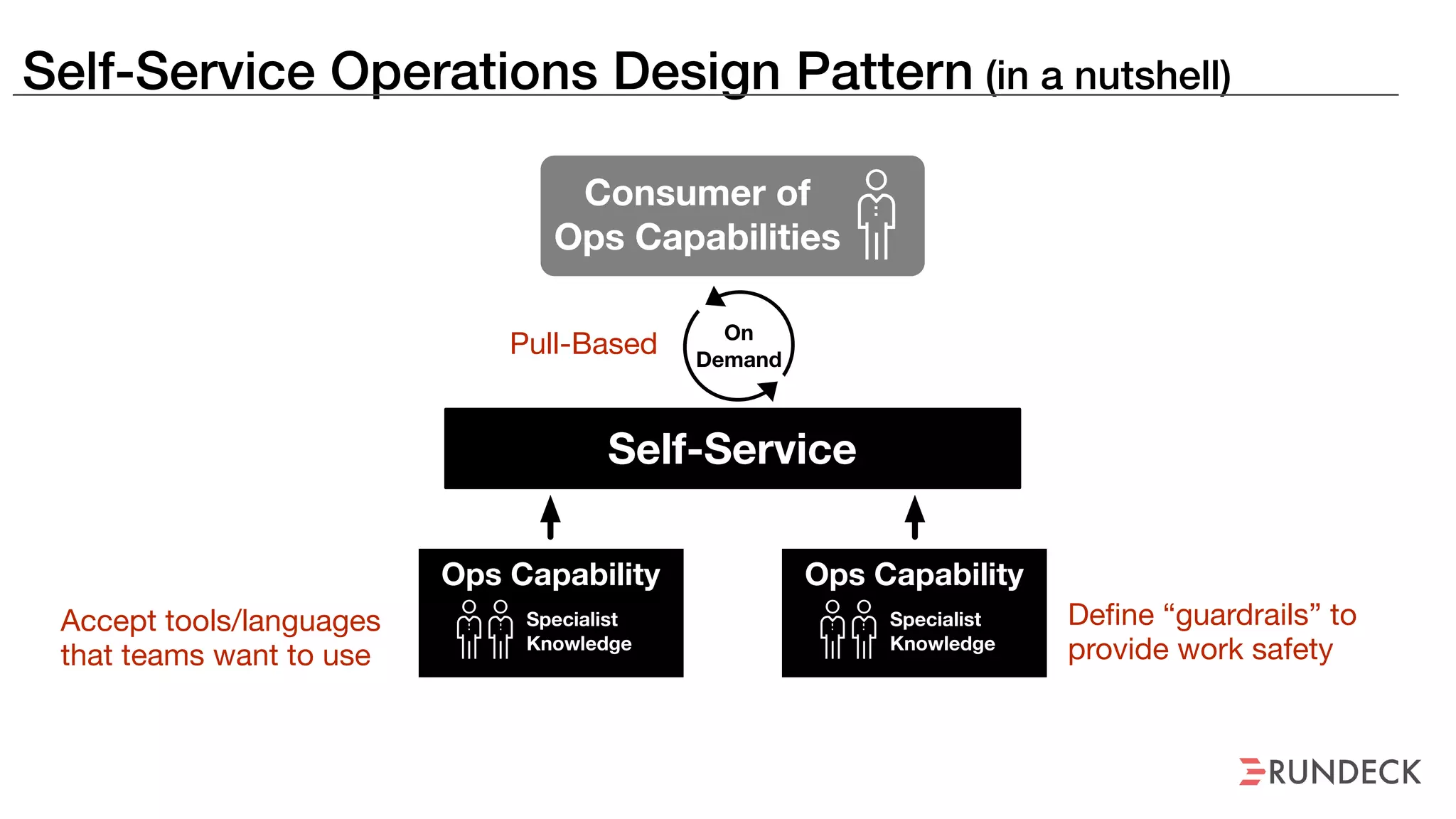
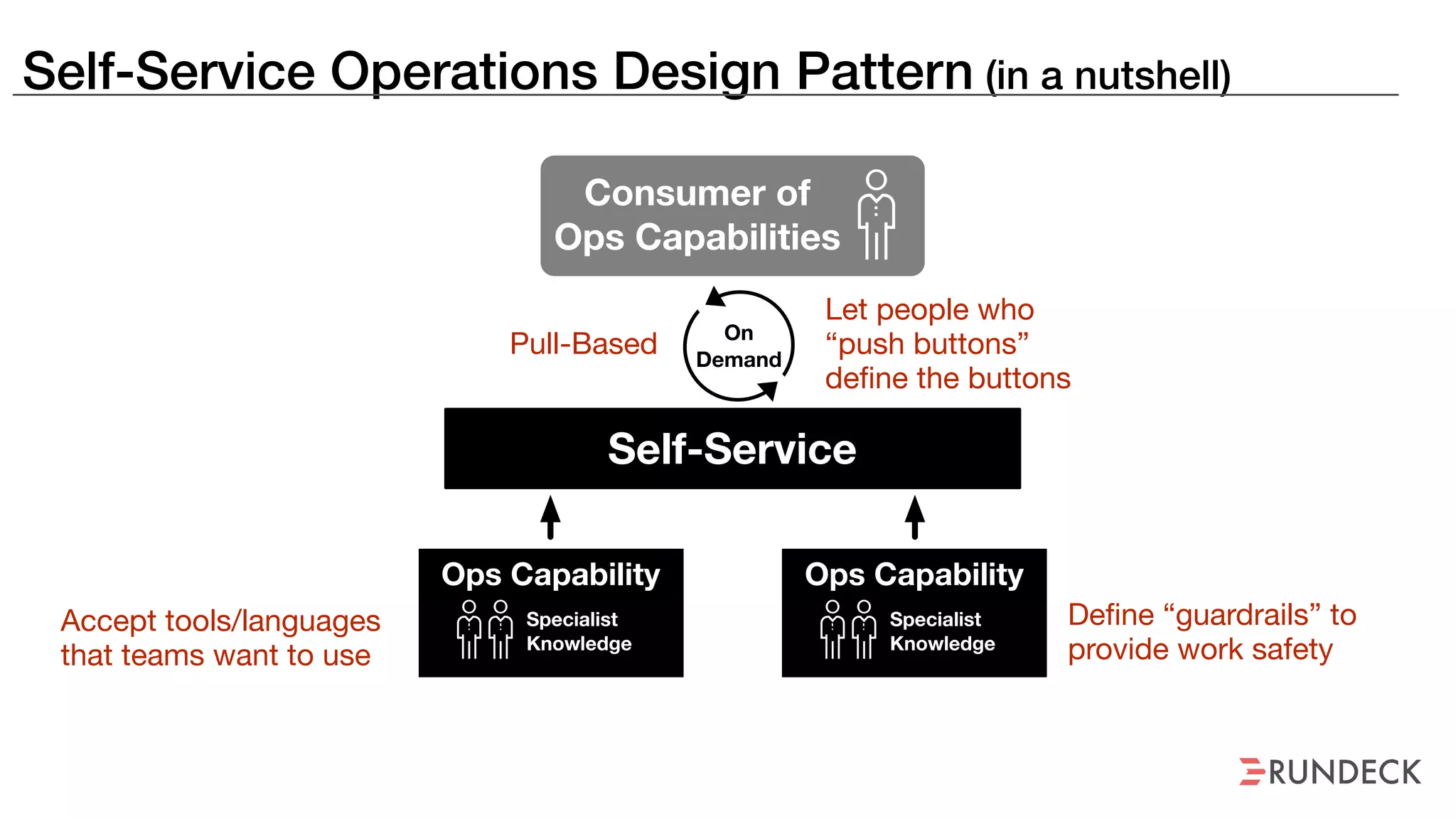
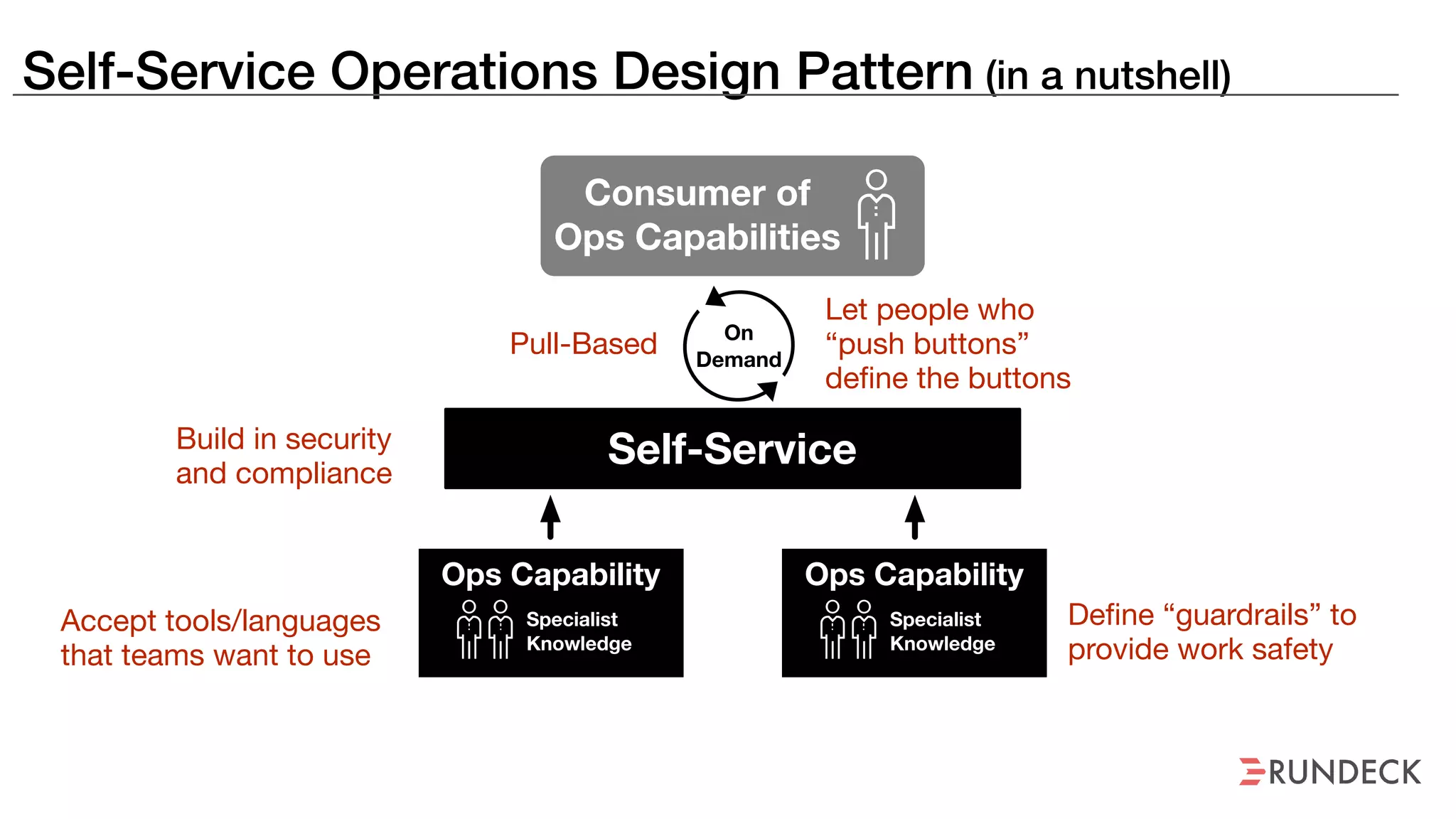






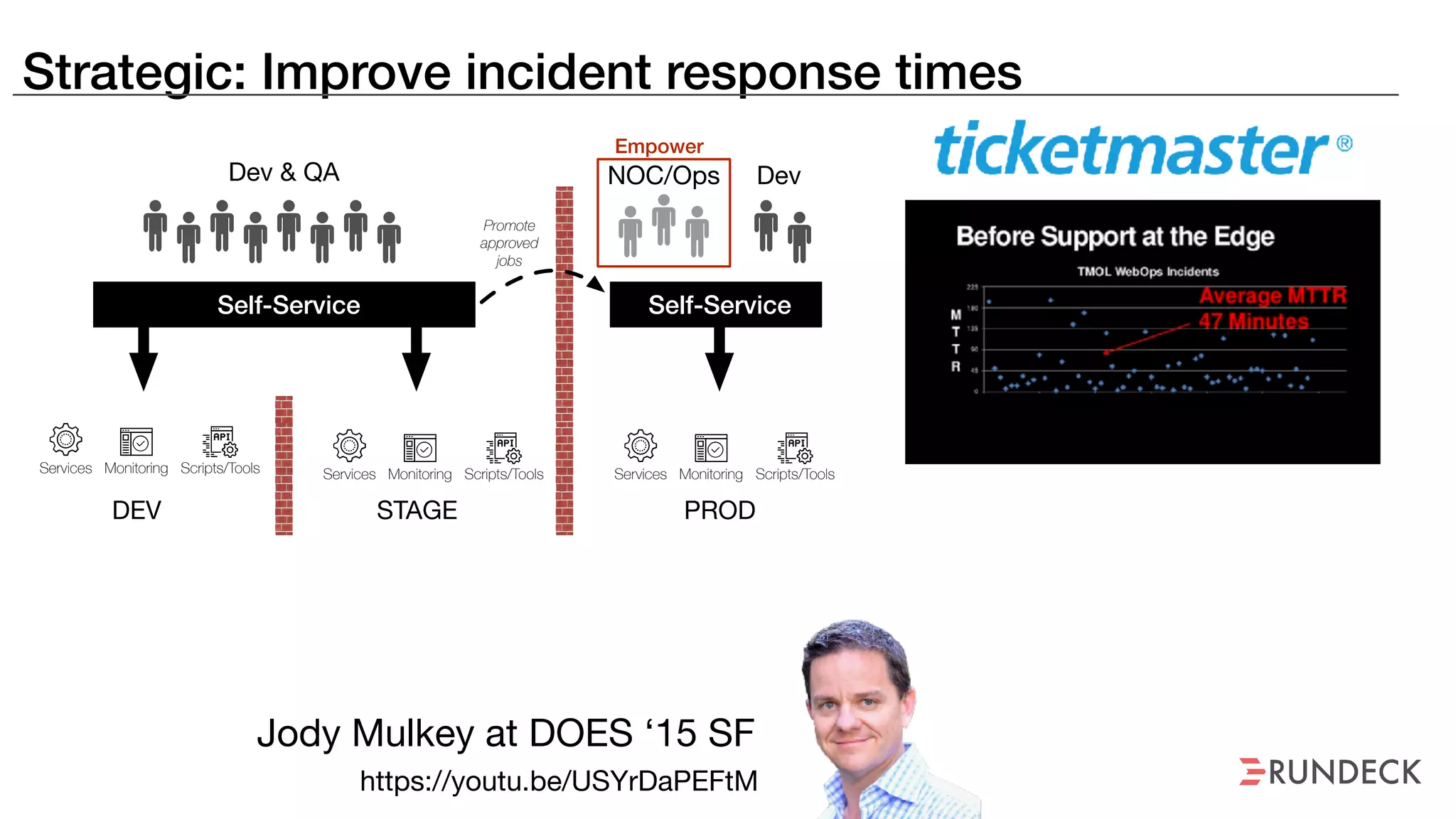
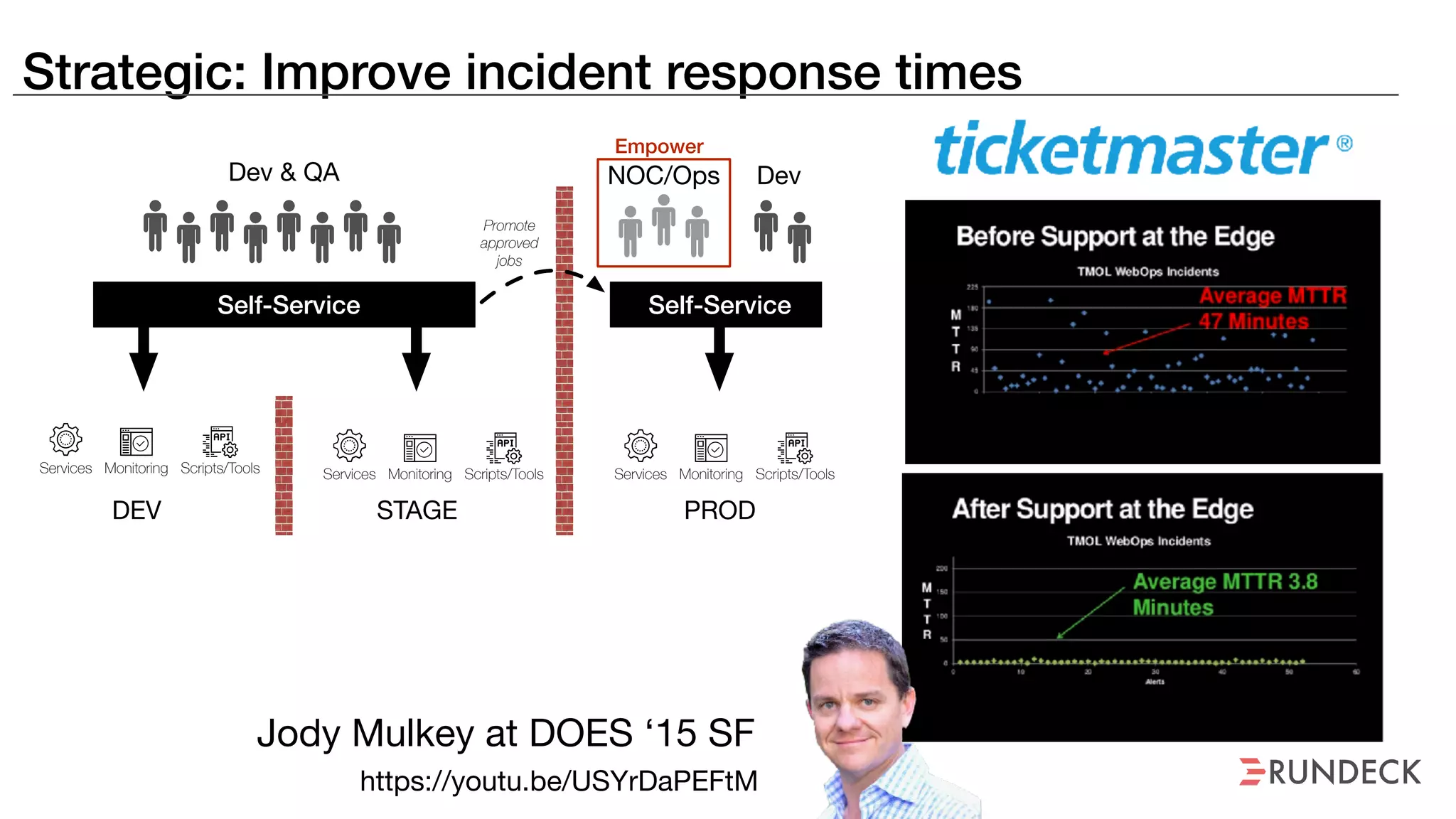
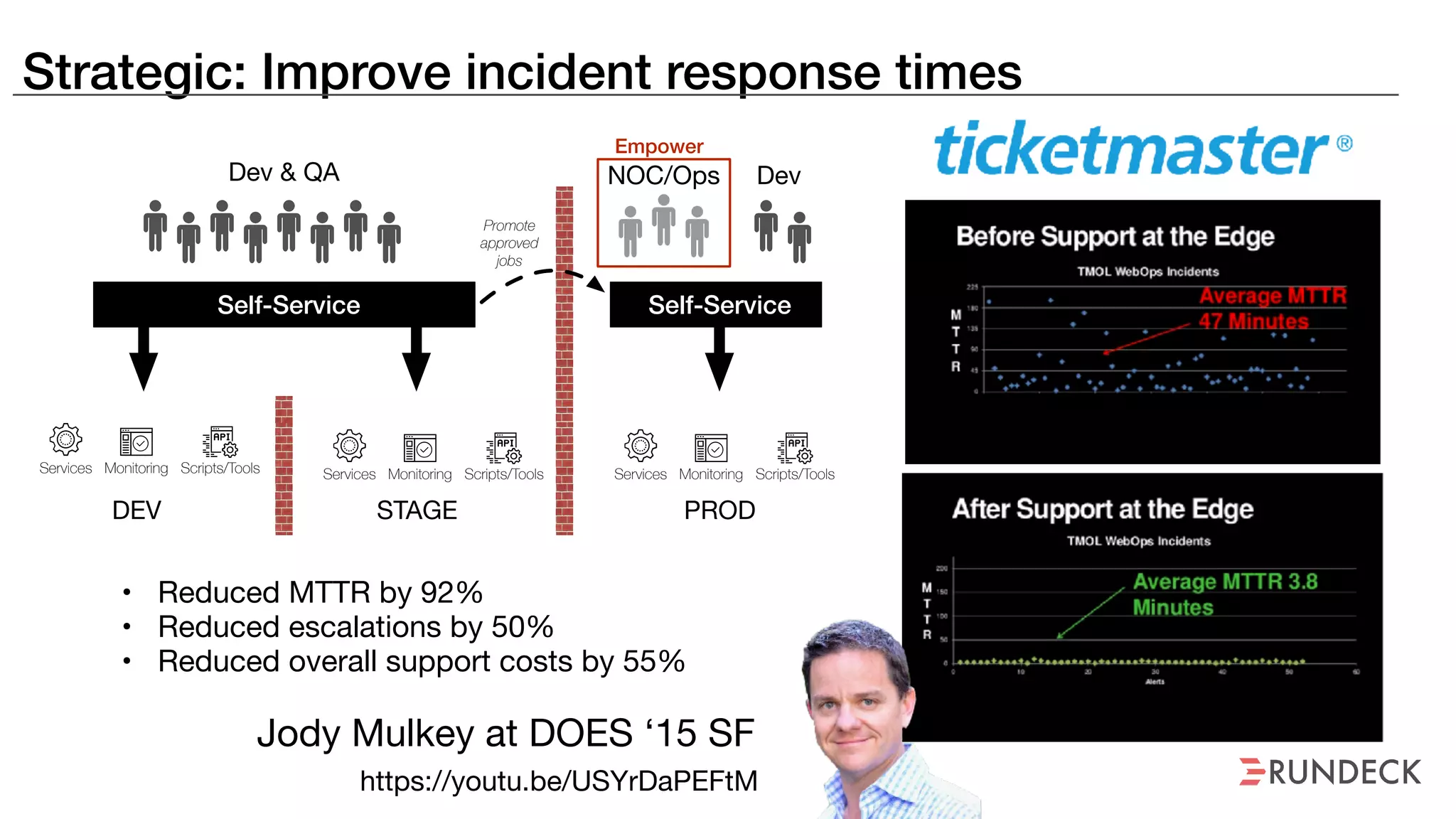


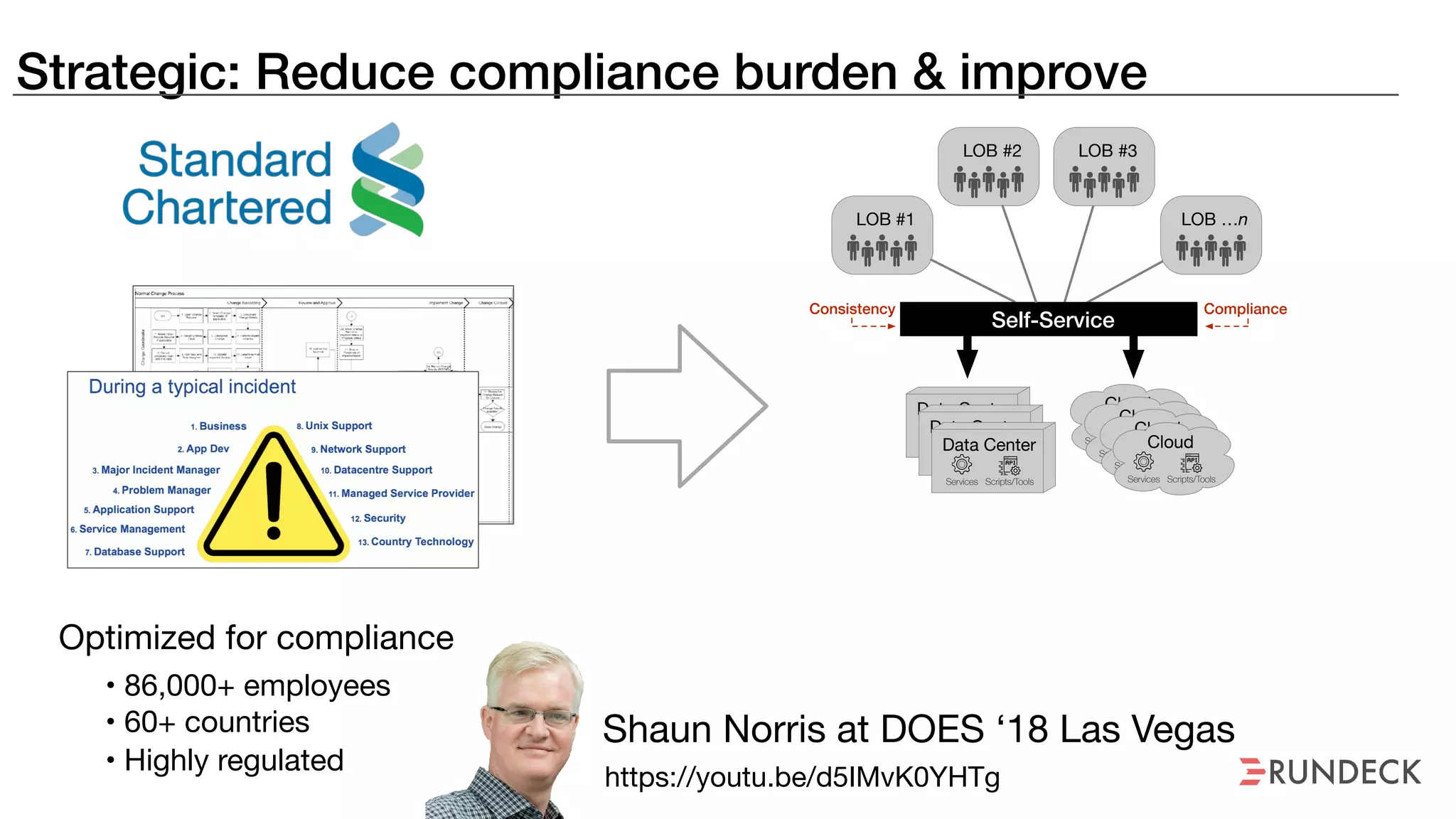
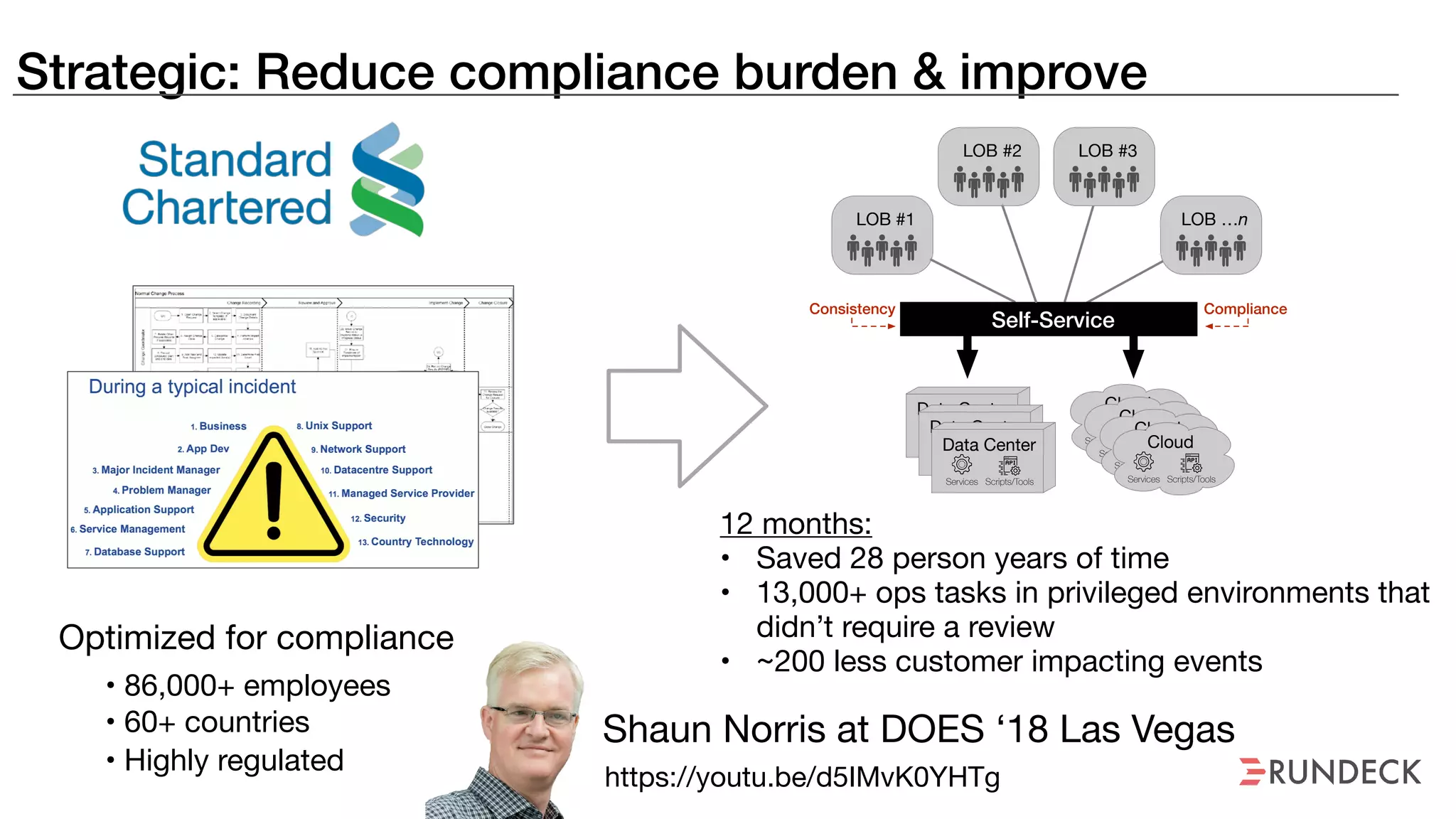
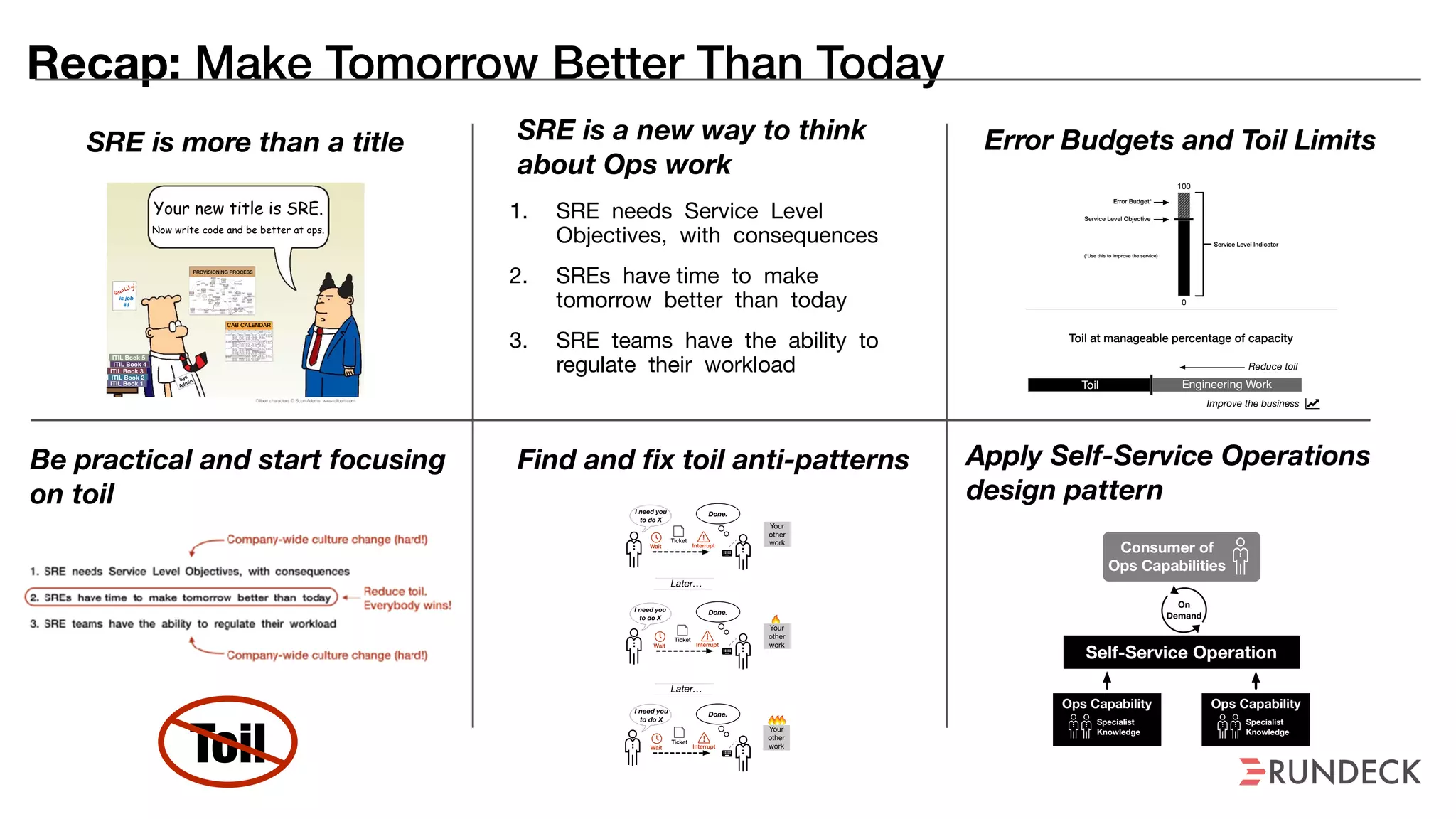


The document discusses the concept of Site Reliability Engineering (SRE) and its principles, emphasizing that it reorganizes how operations are performed for more efficient service delivery. It highlights the importance of reducing 'toil'—manual, repetitive work—and creating service level objectives to improve operational effectiveness and team workloads. Additionally, it suggests empowering teams to implement self-service capabilities and encourages a culture shift towards shared responsibility in operations.





























![Site-Reliability-Engineering-v2[6241].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/site-reliability-engineering-v26241-221023035909-82e9559b-thumbnail.jpg?width=640&height=640&fit=bounds)




































![Runbook Automation: Old News or a Key to Unlock Performance? [DOES2020]](https://cdn.slidesharecdn.com/ss_thumbnails/does-damonedwards-v2-201015073337-thumbnail.jpg?width=640&height=640&fit=bounds)


![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)

















