Download as PDF, PPTX



















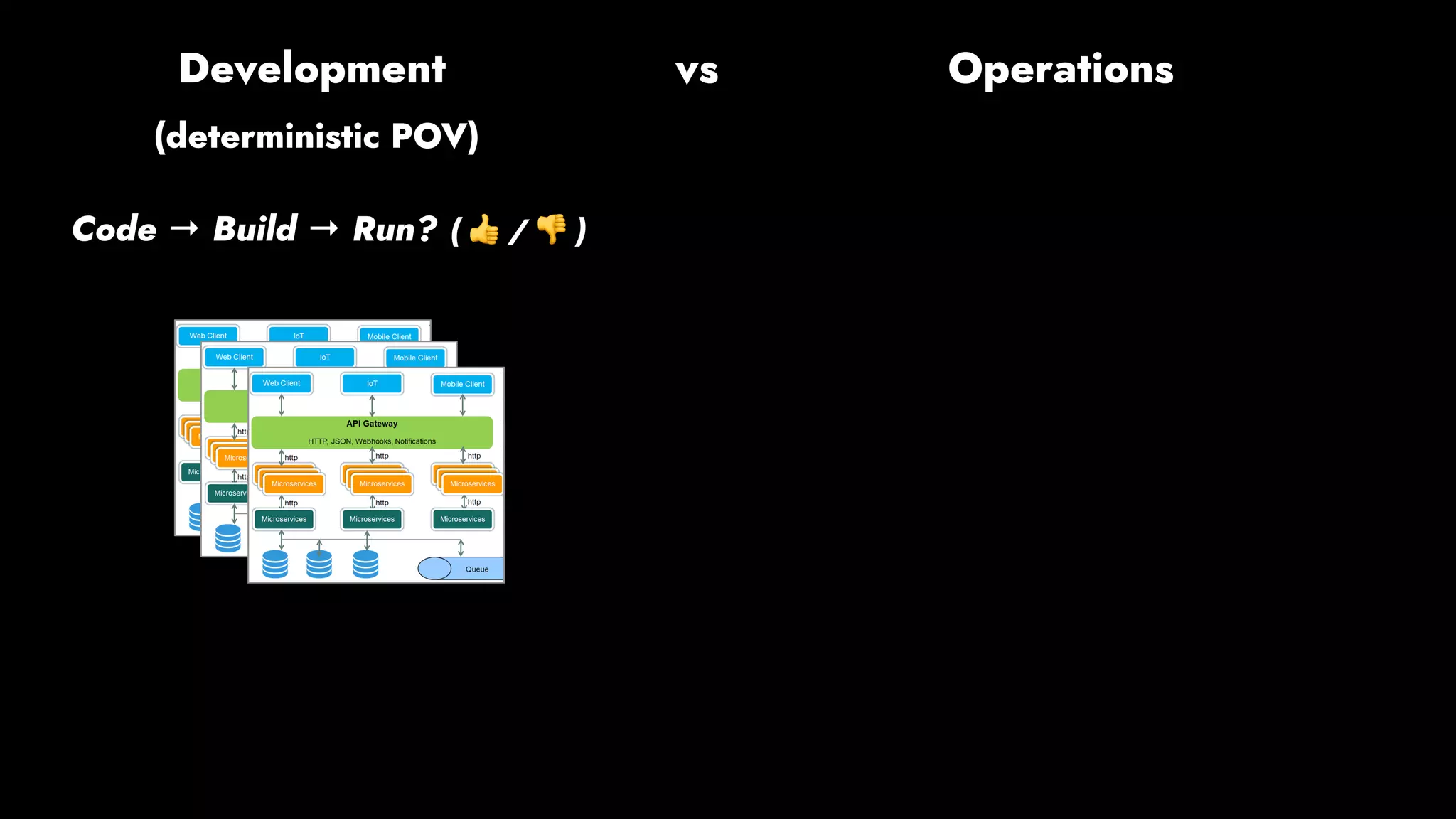
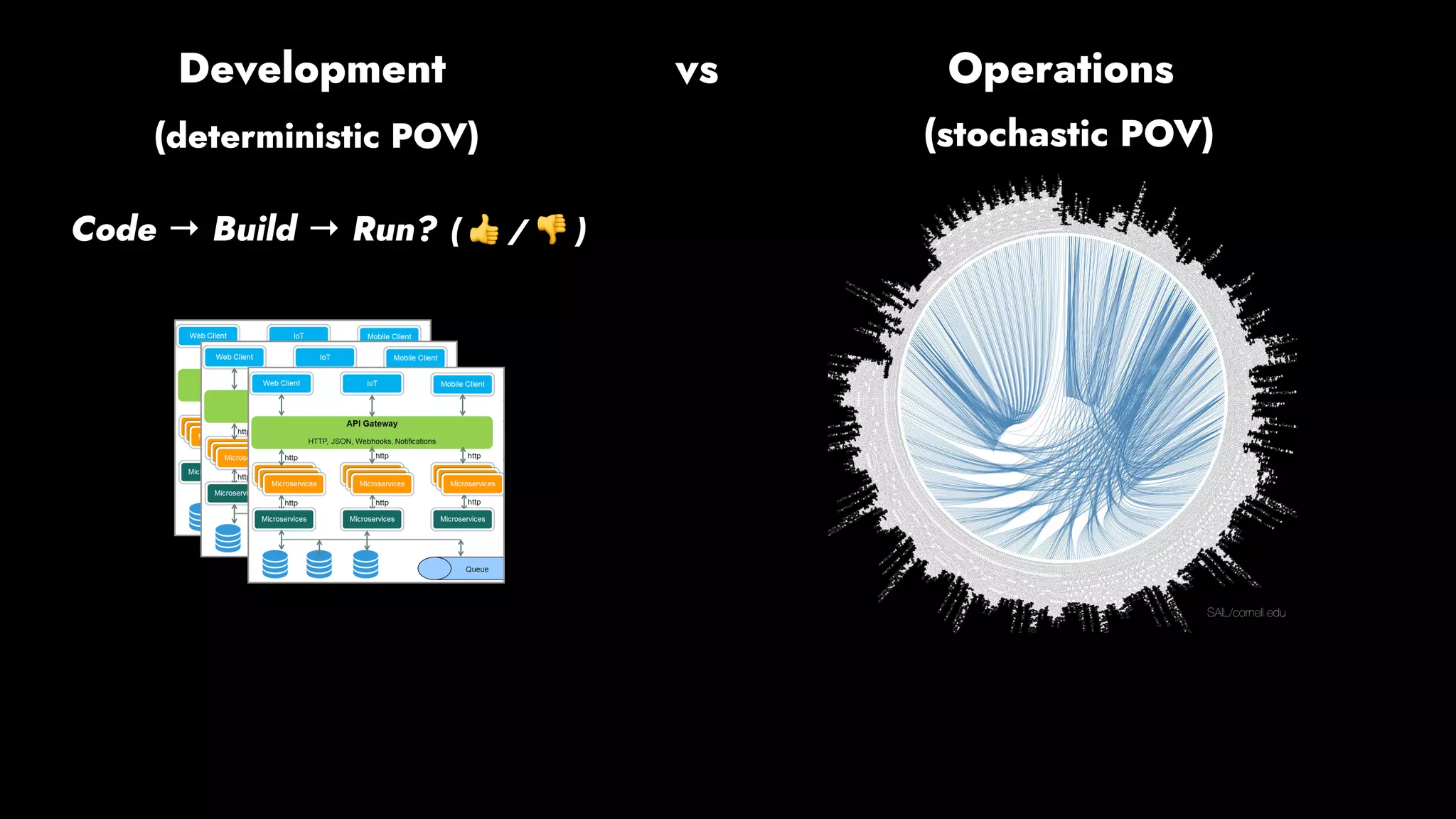

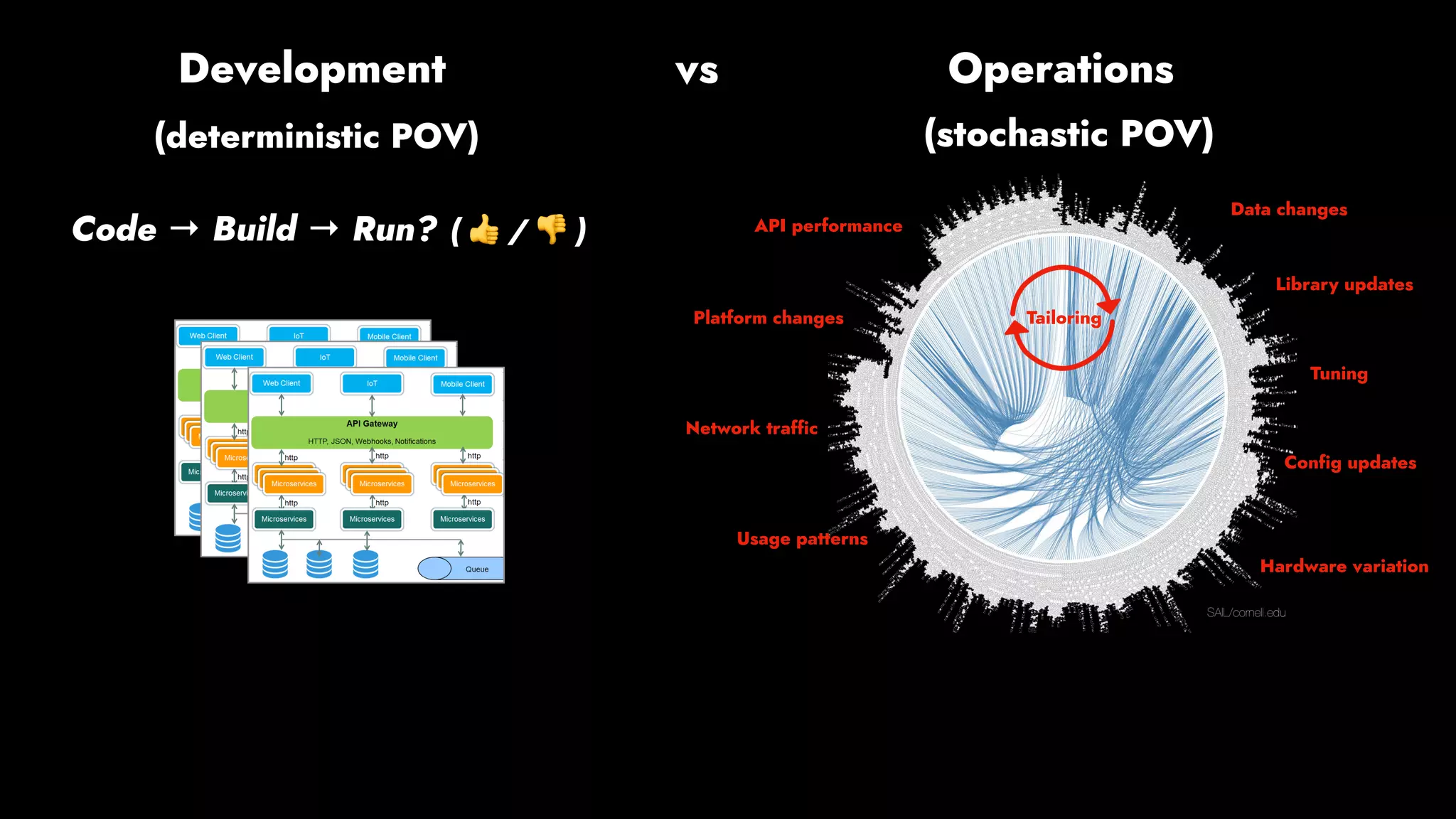
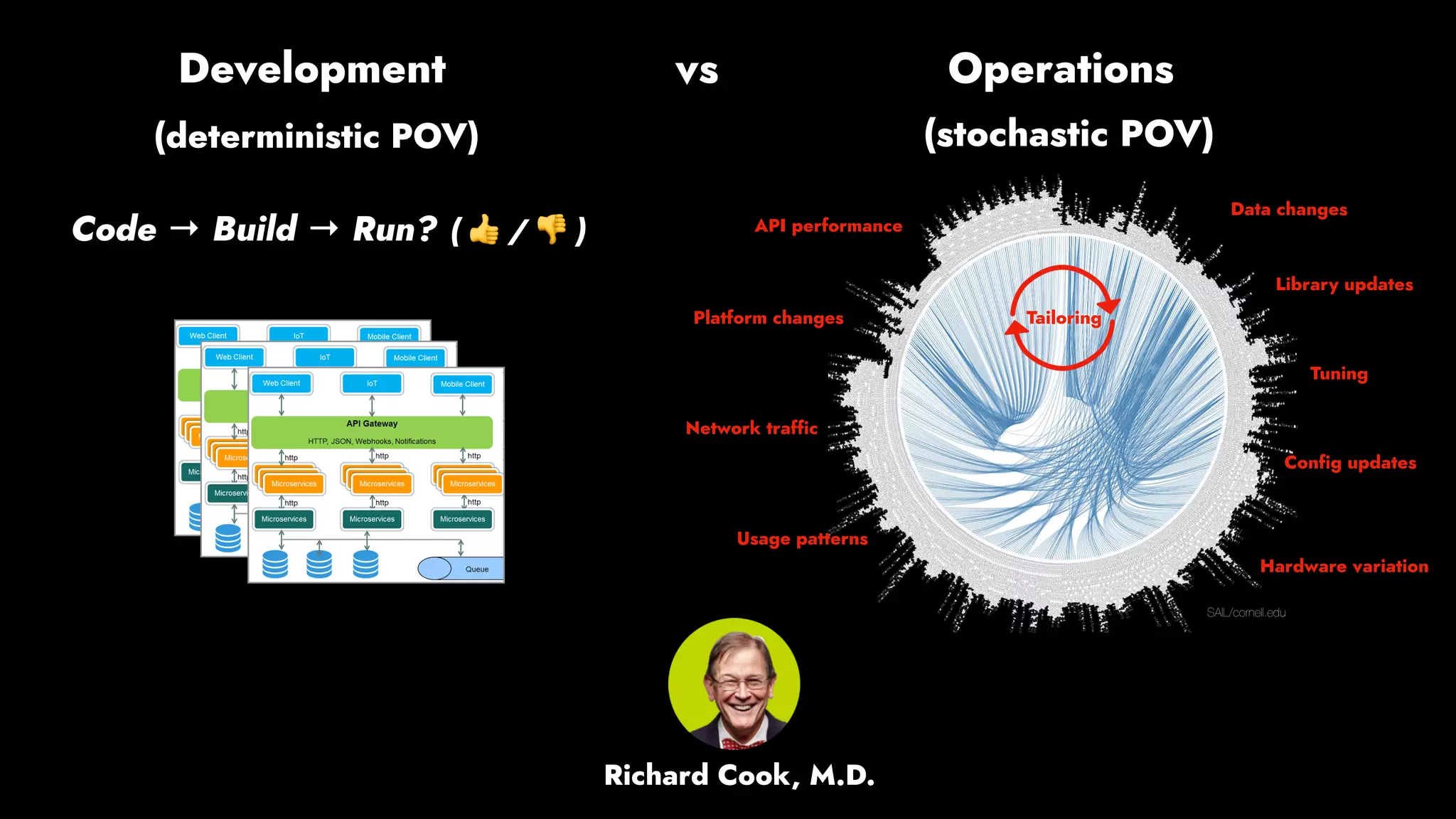
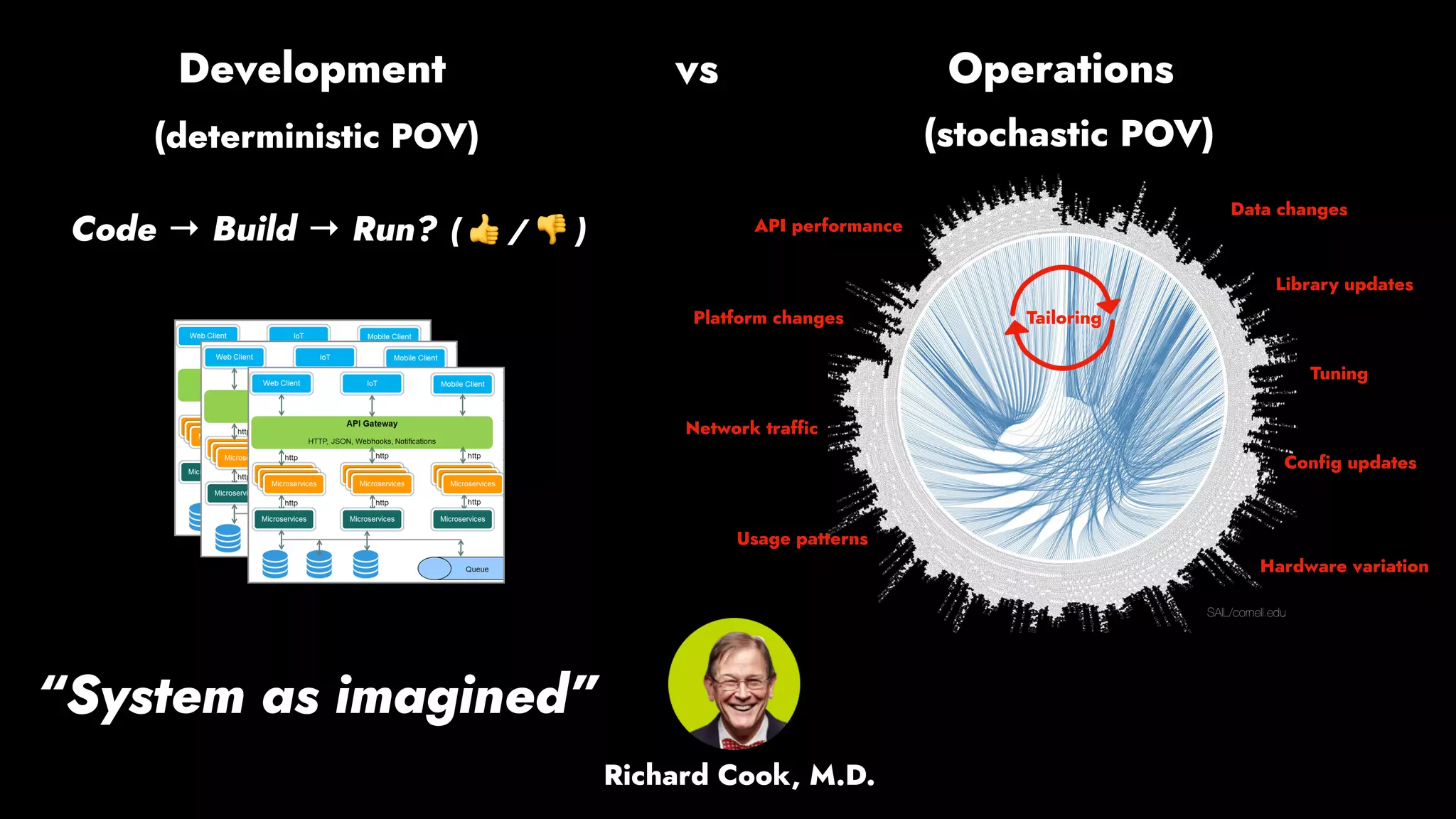
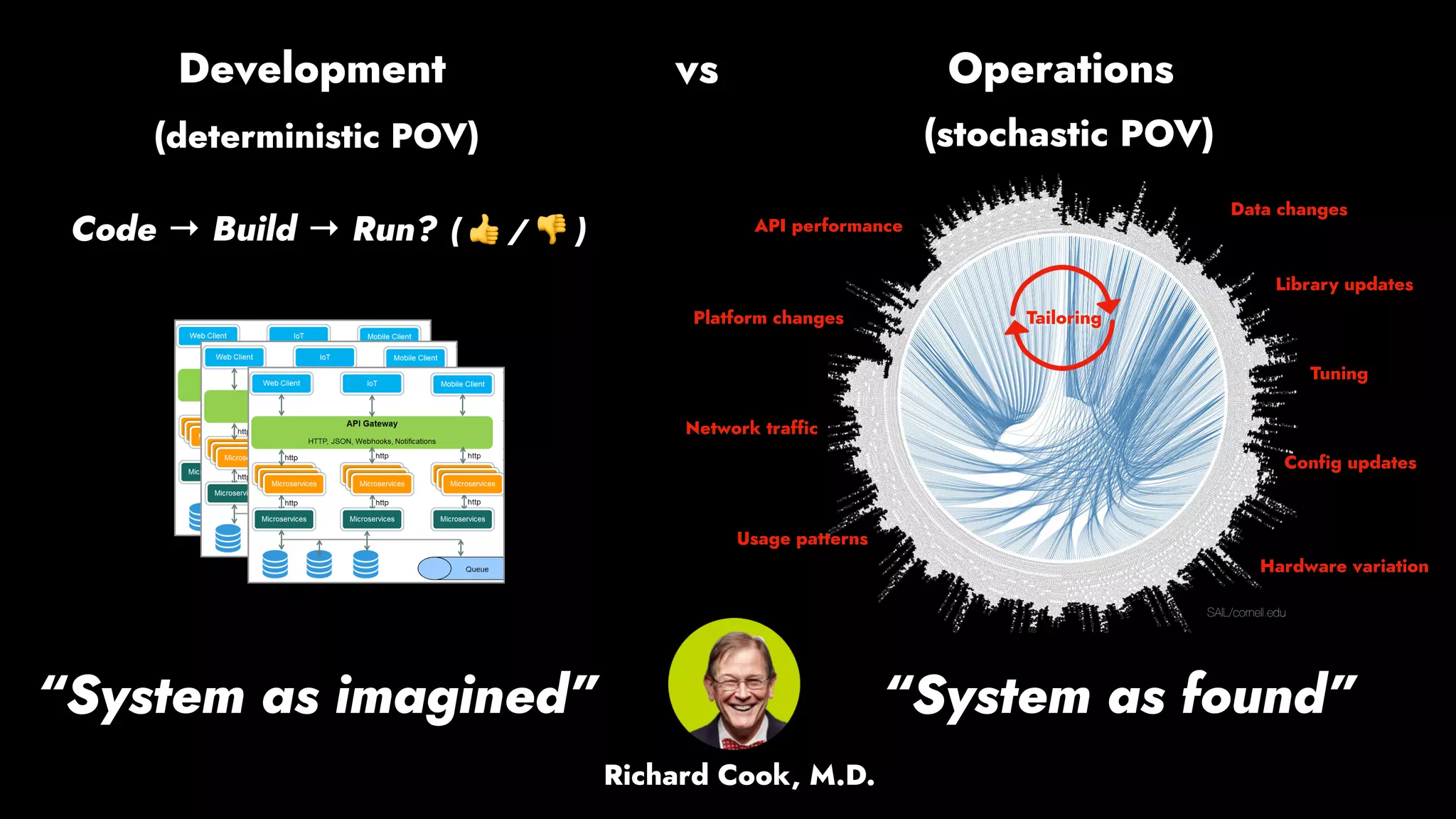











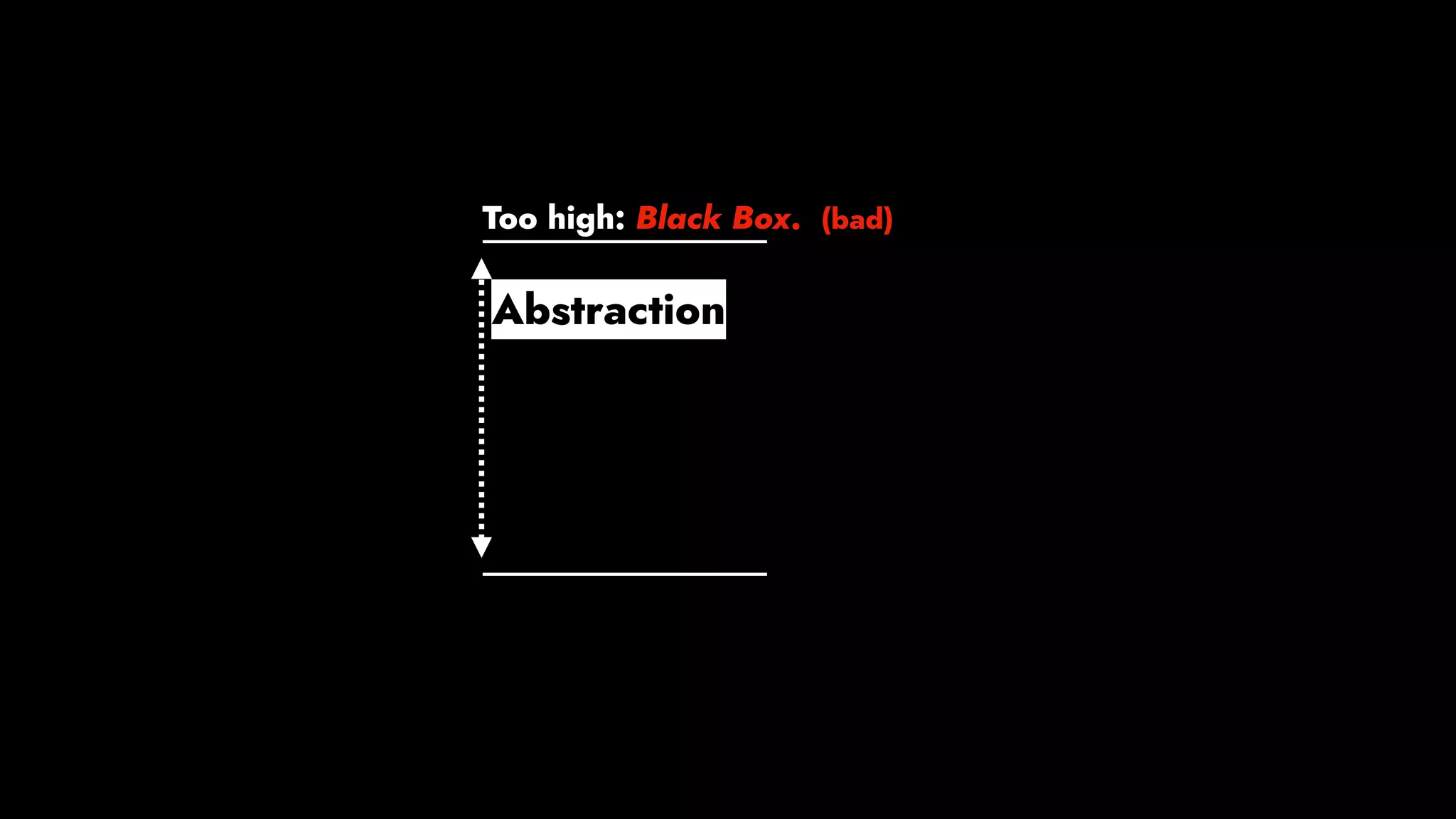
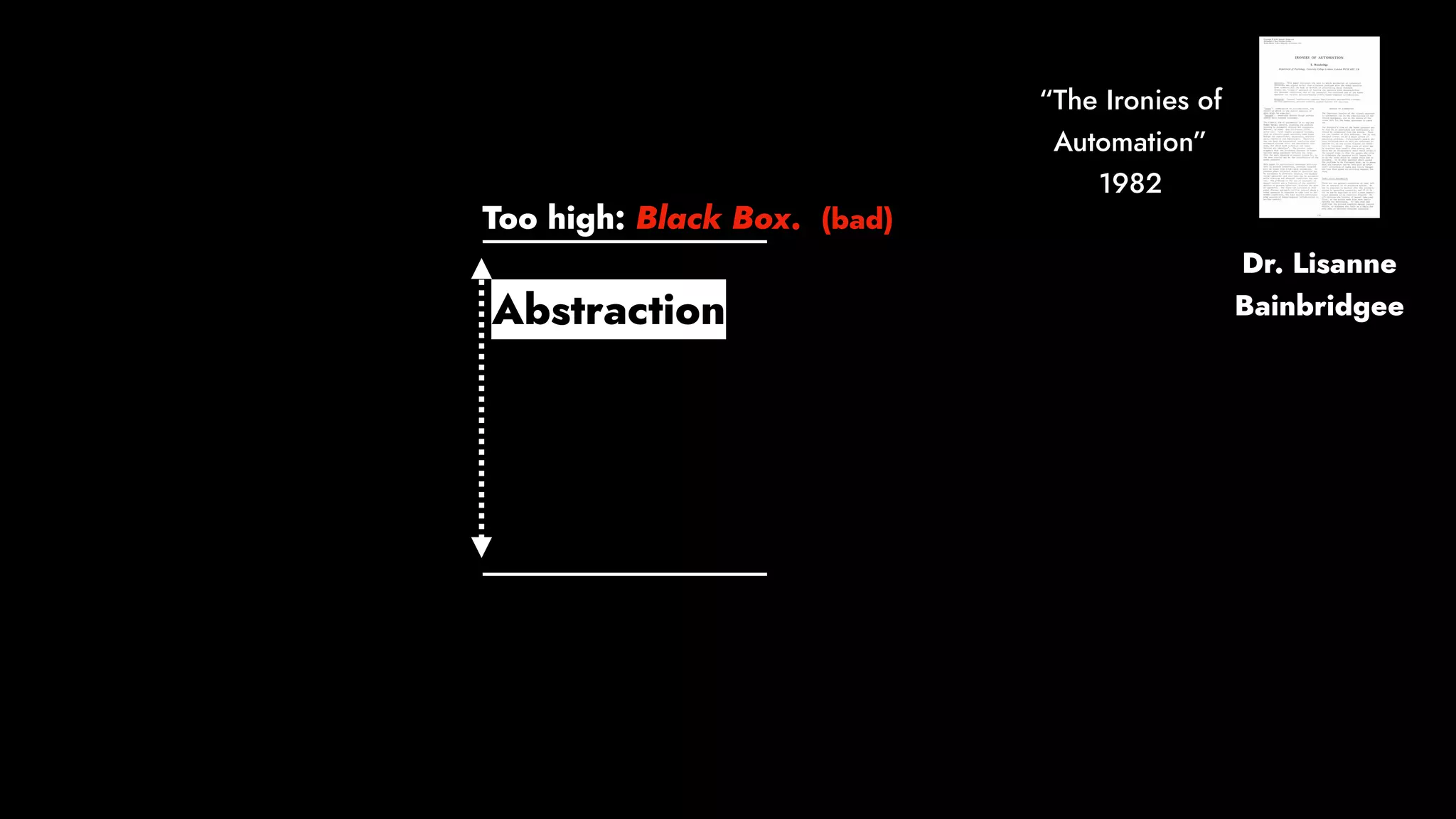
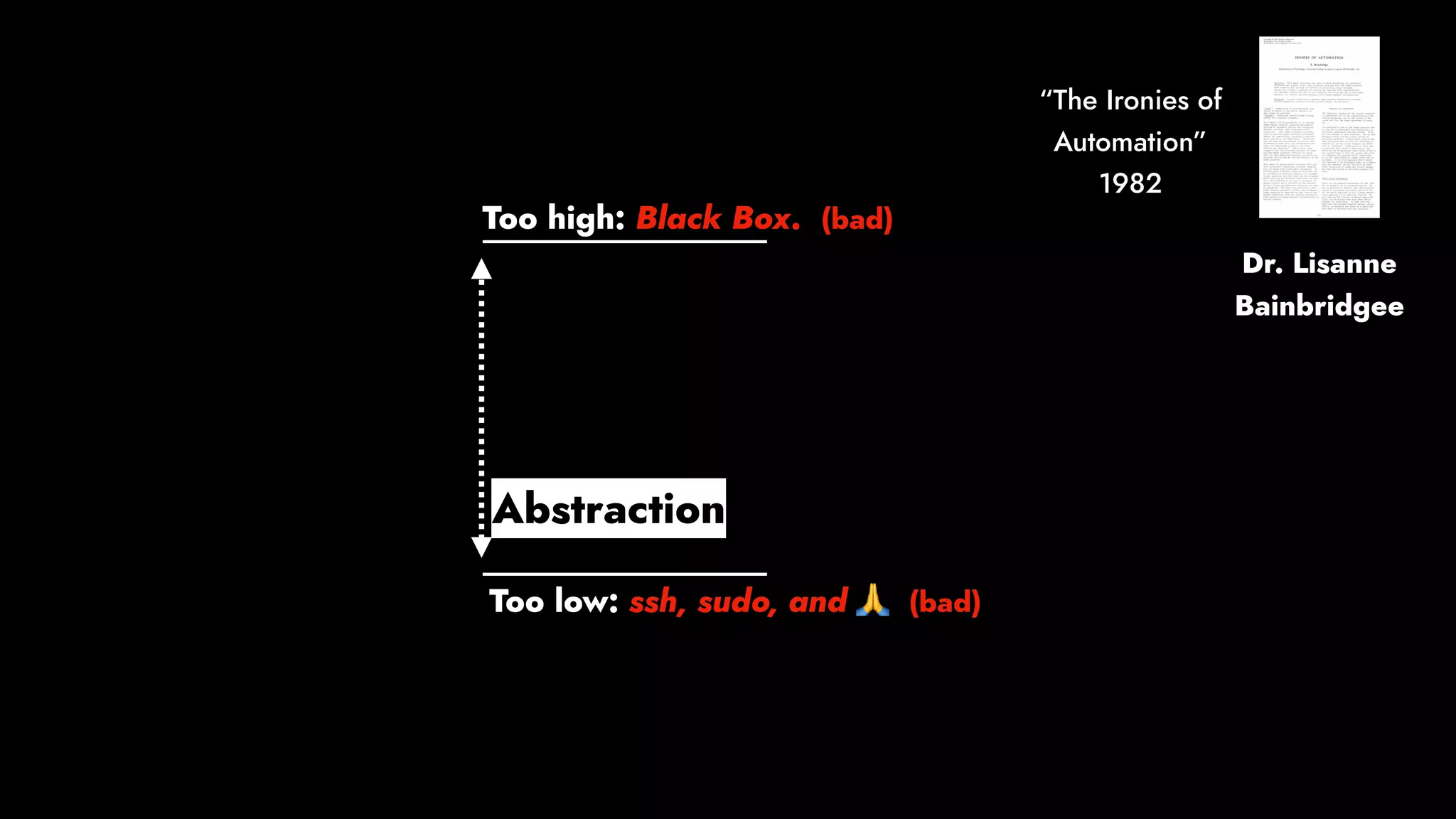
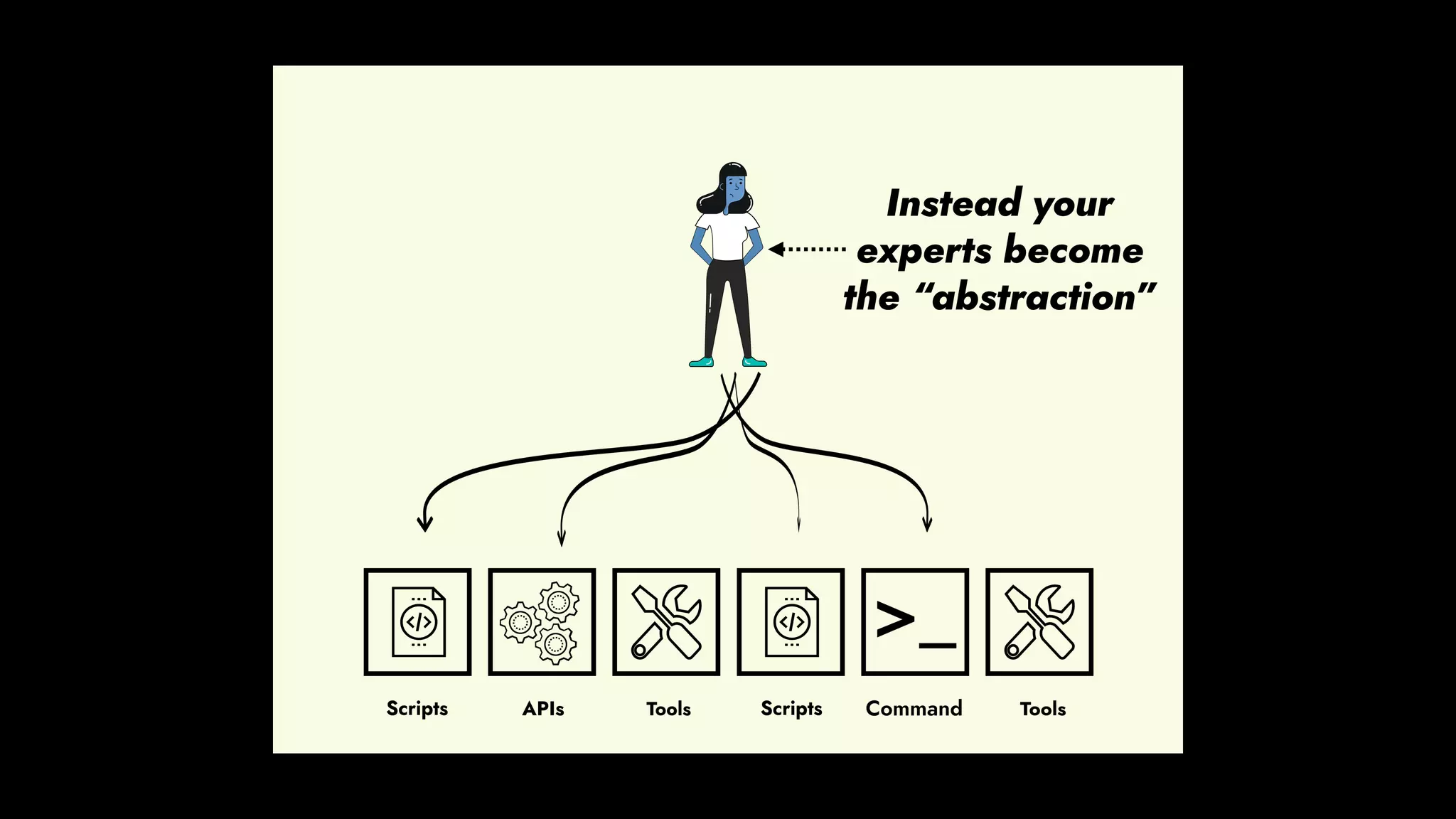
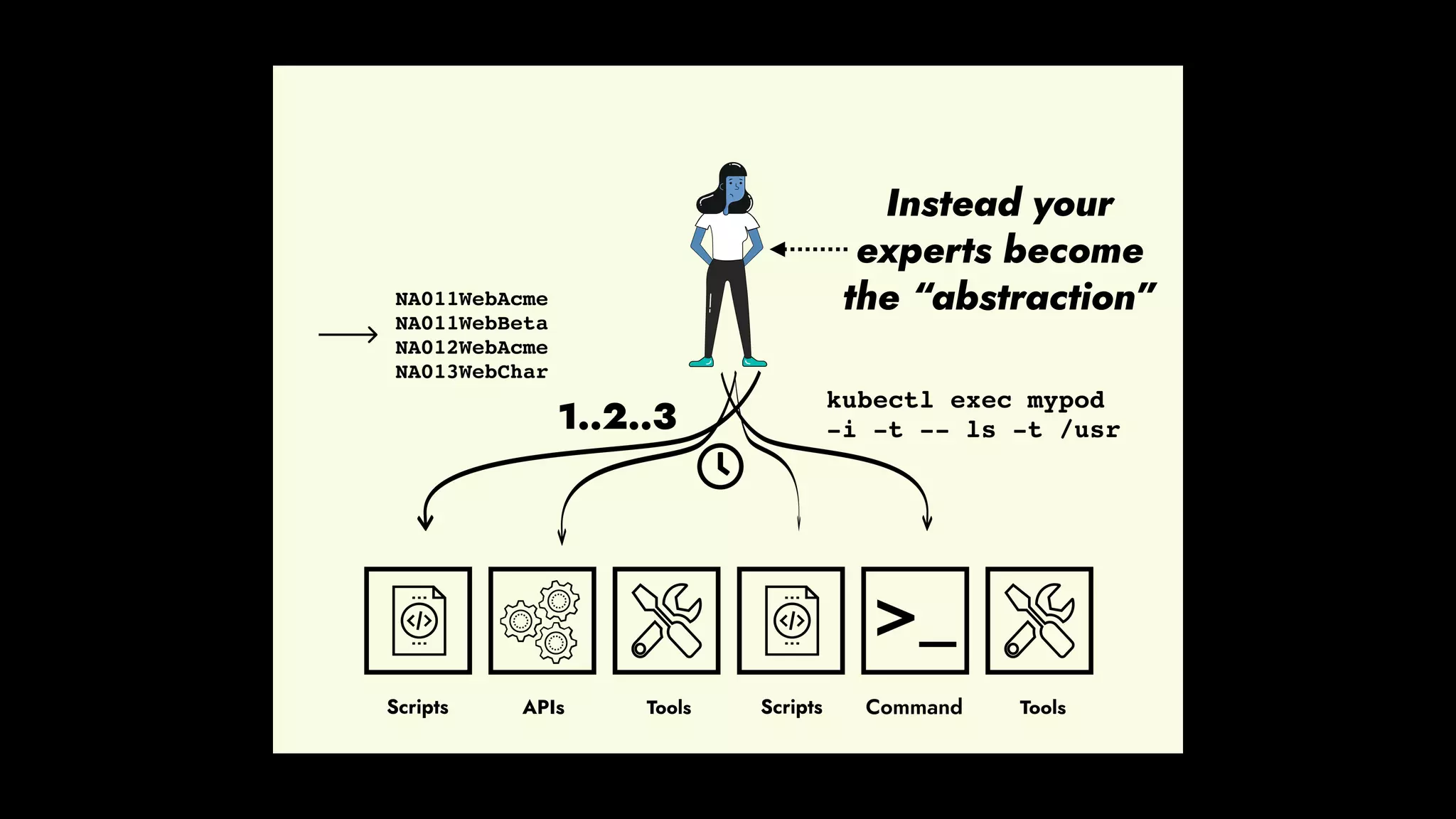
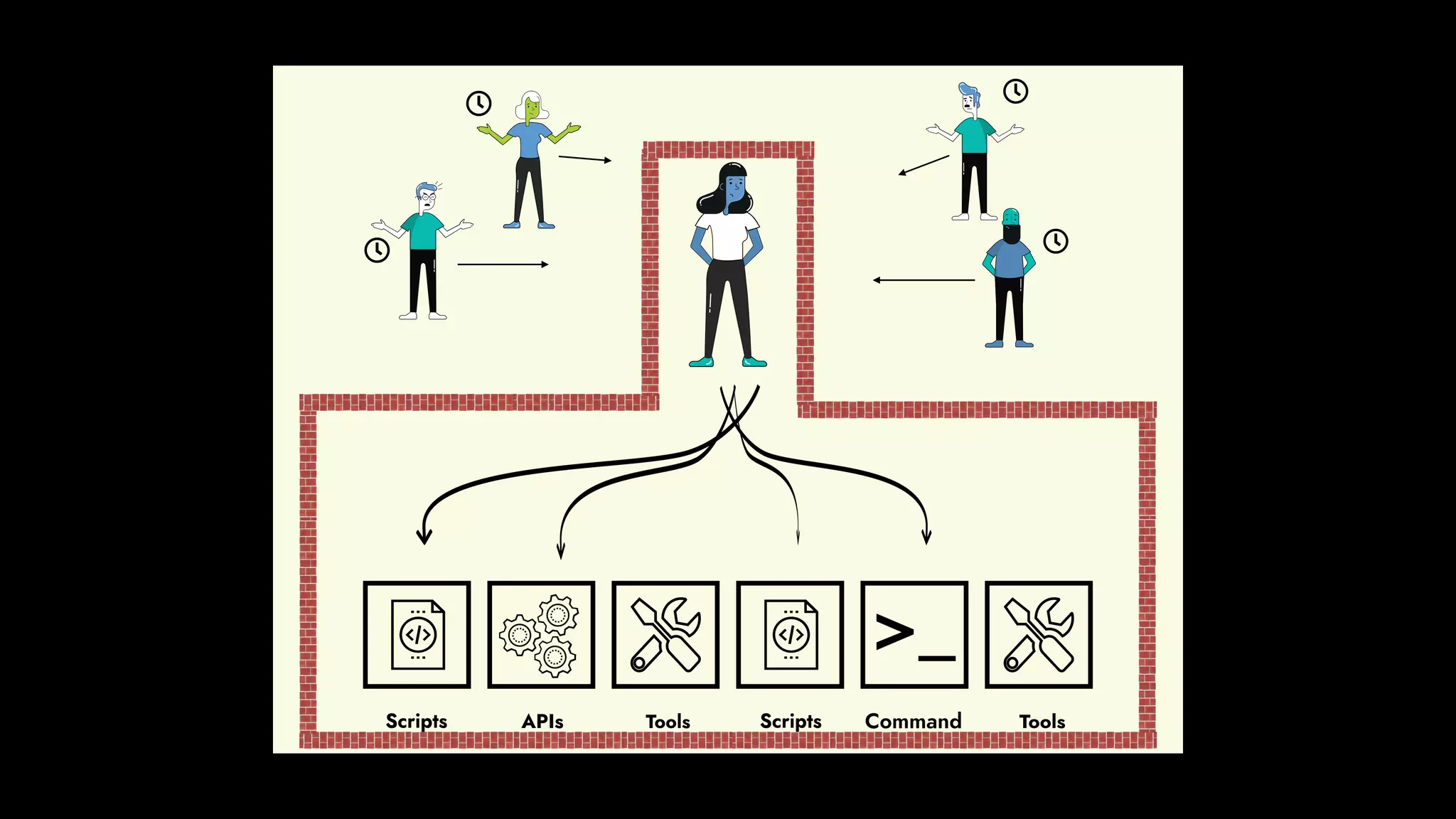
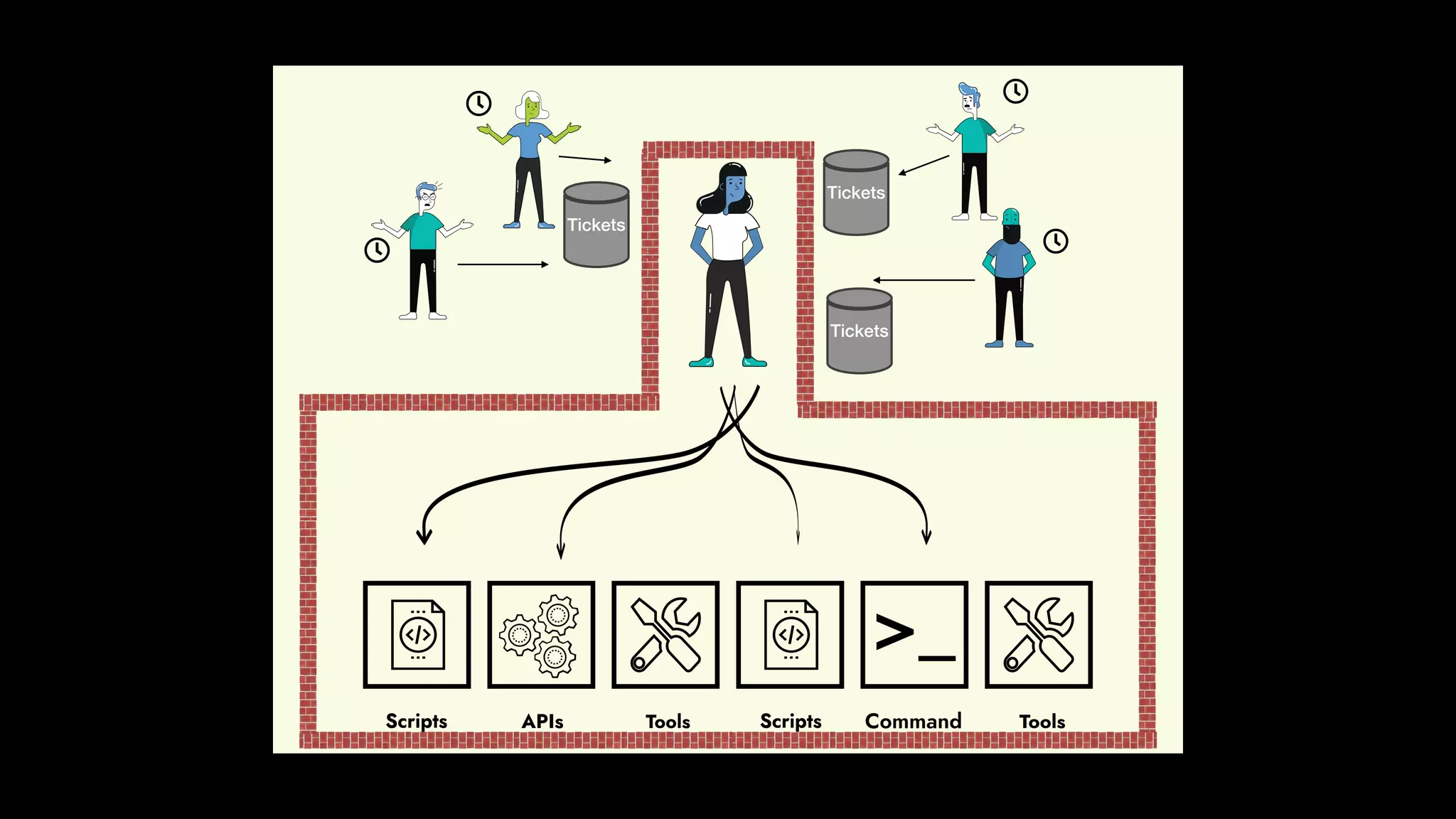
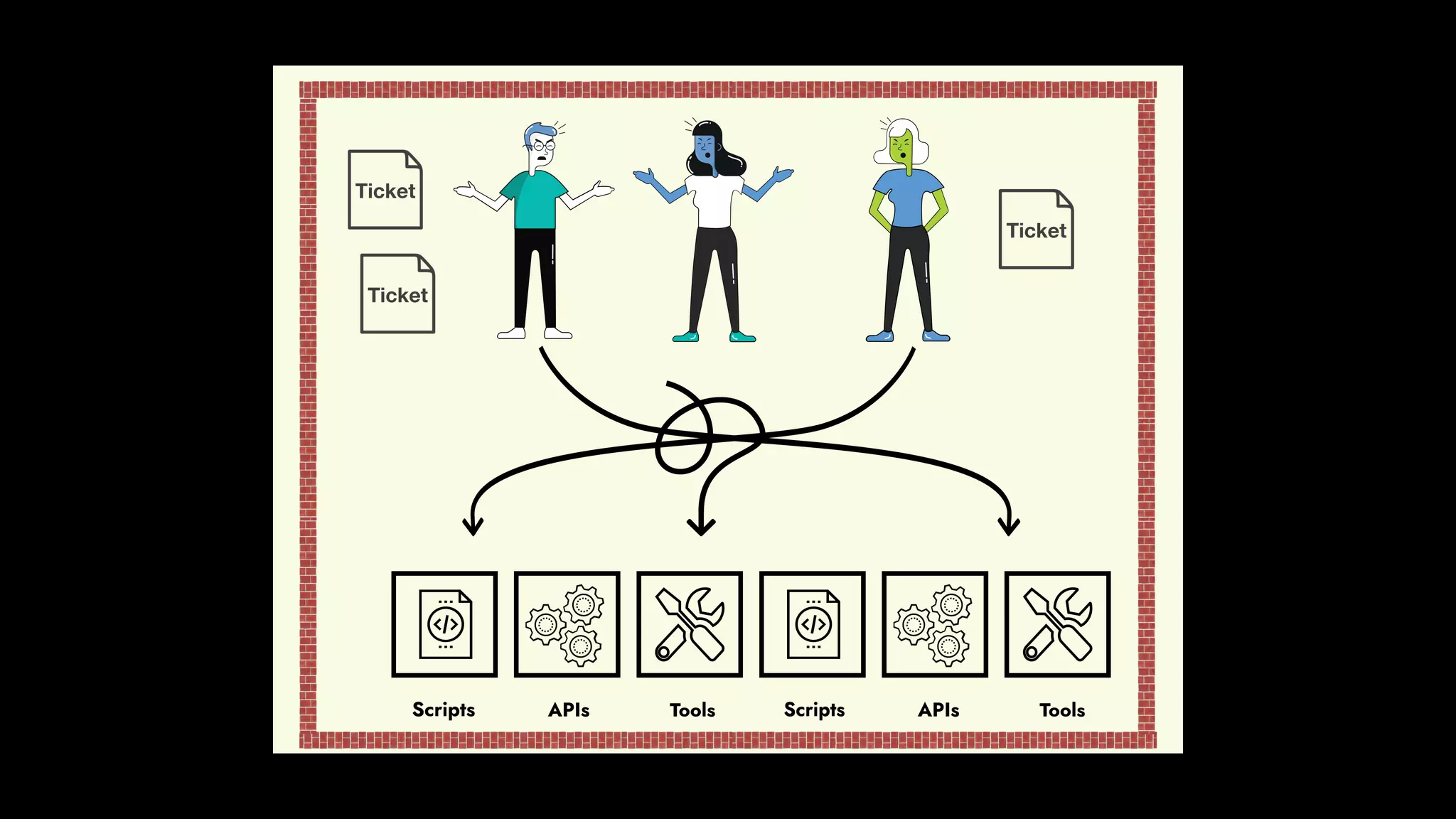
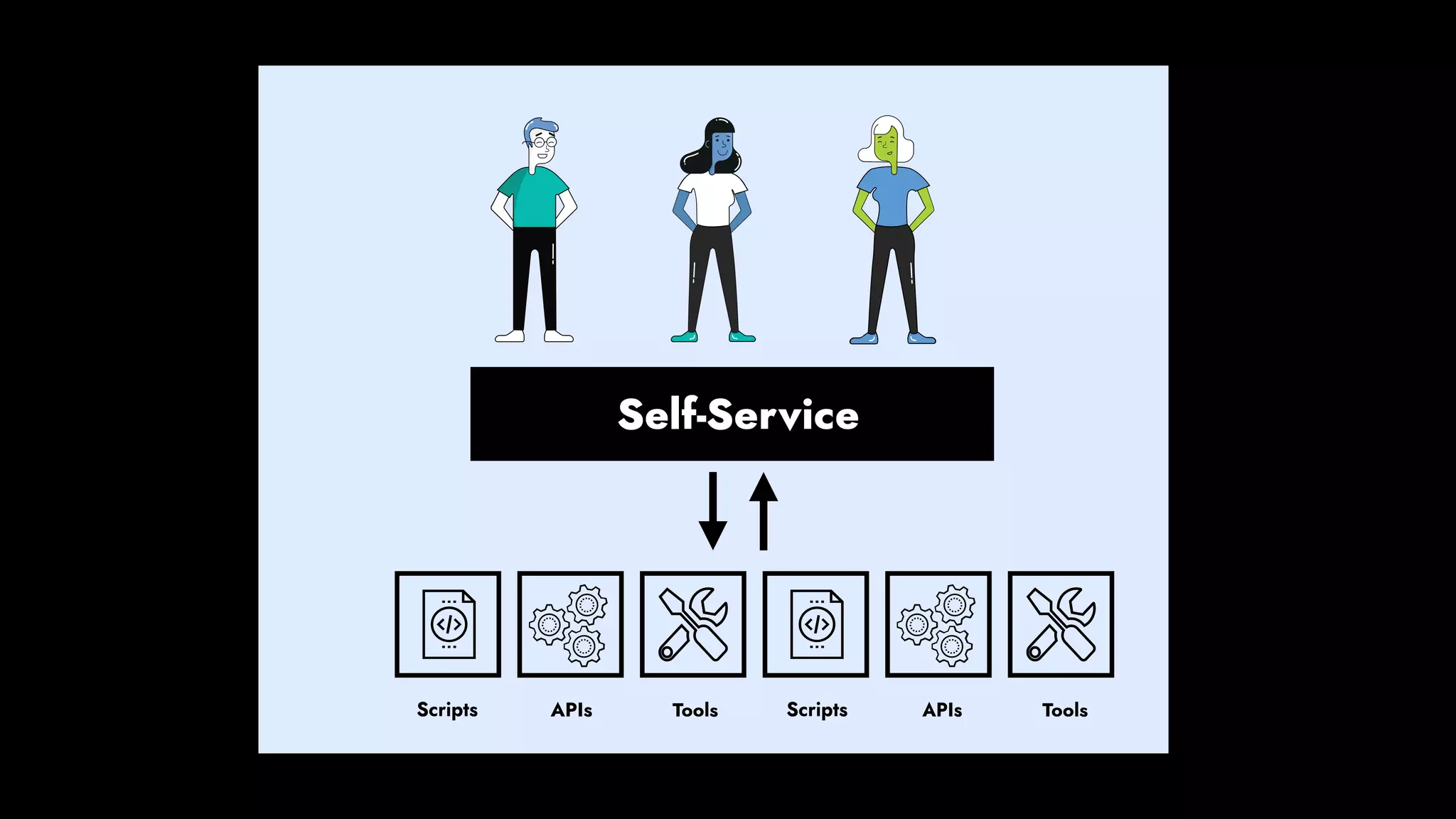
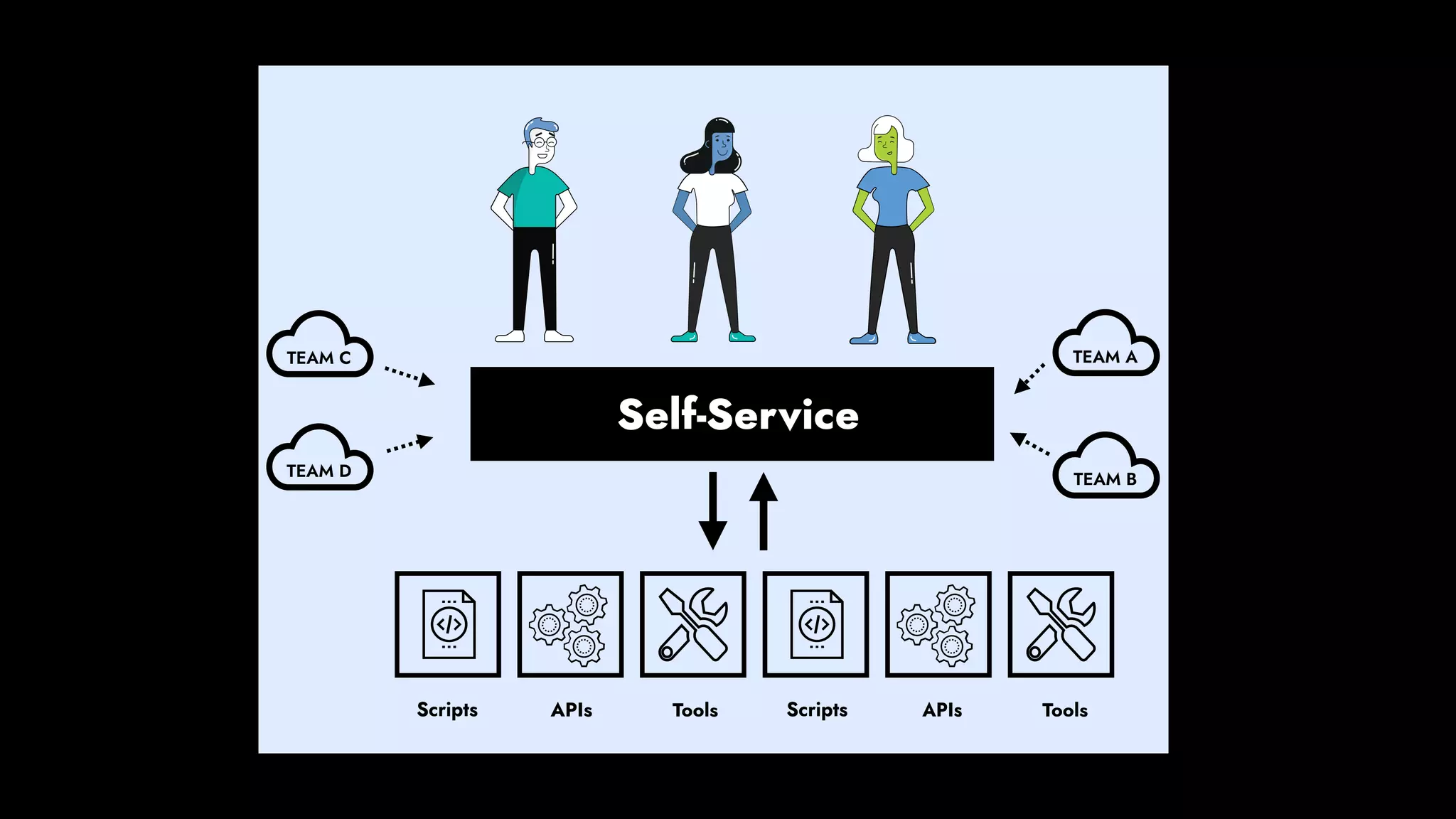

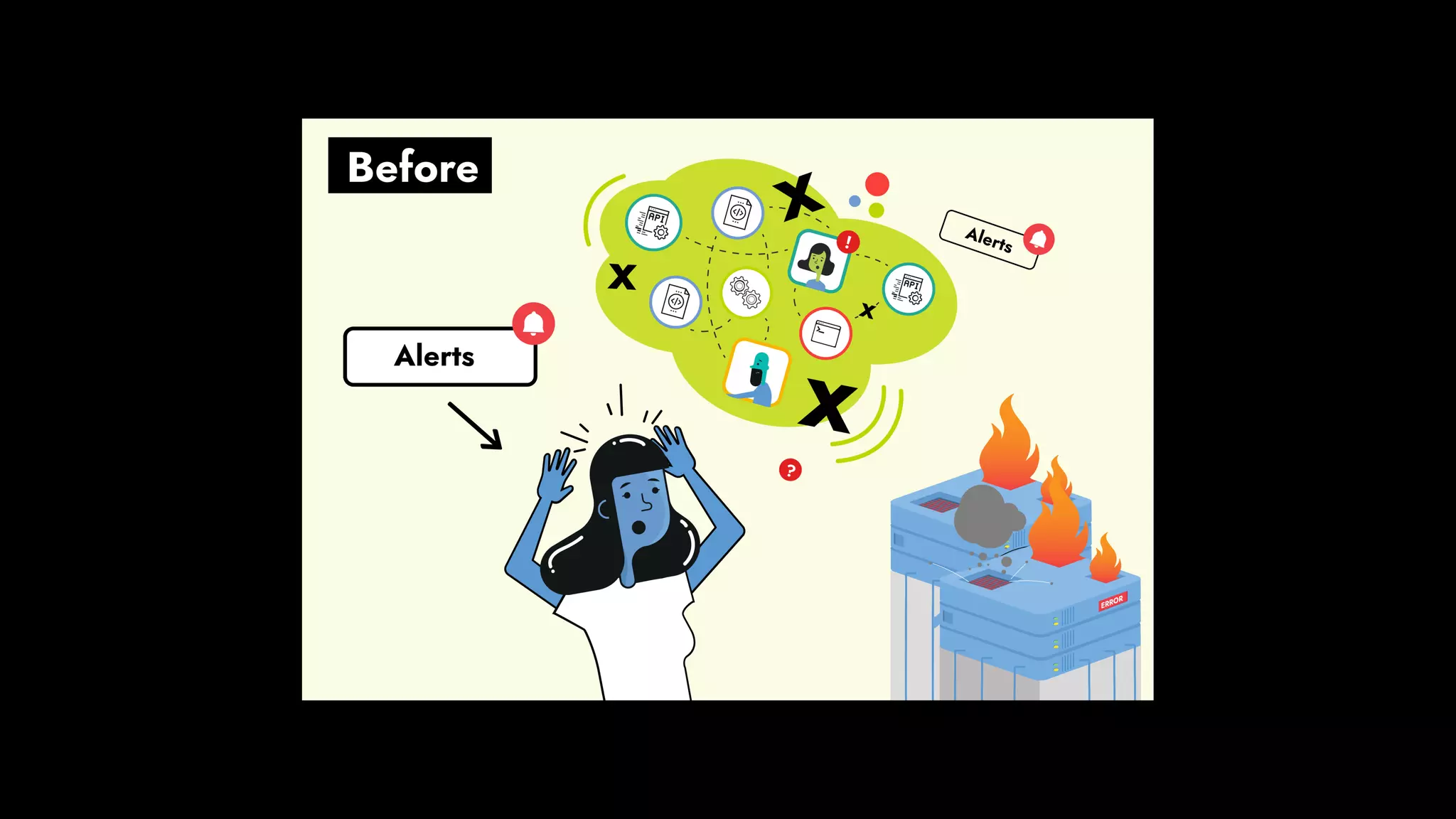
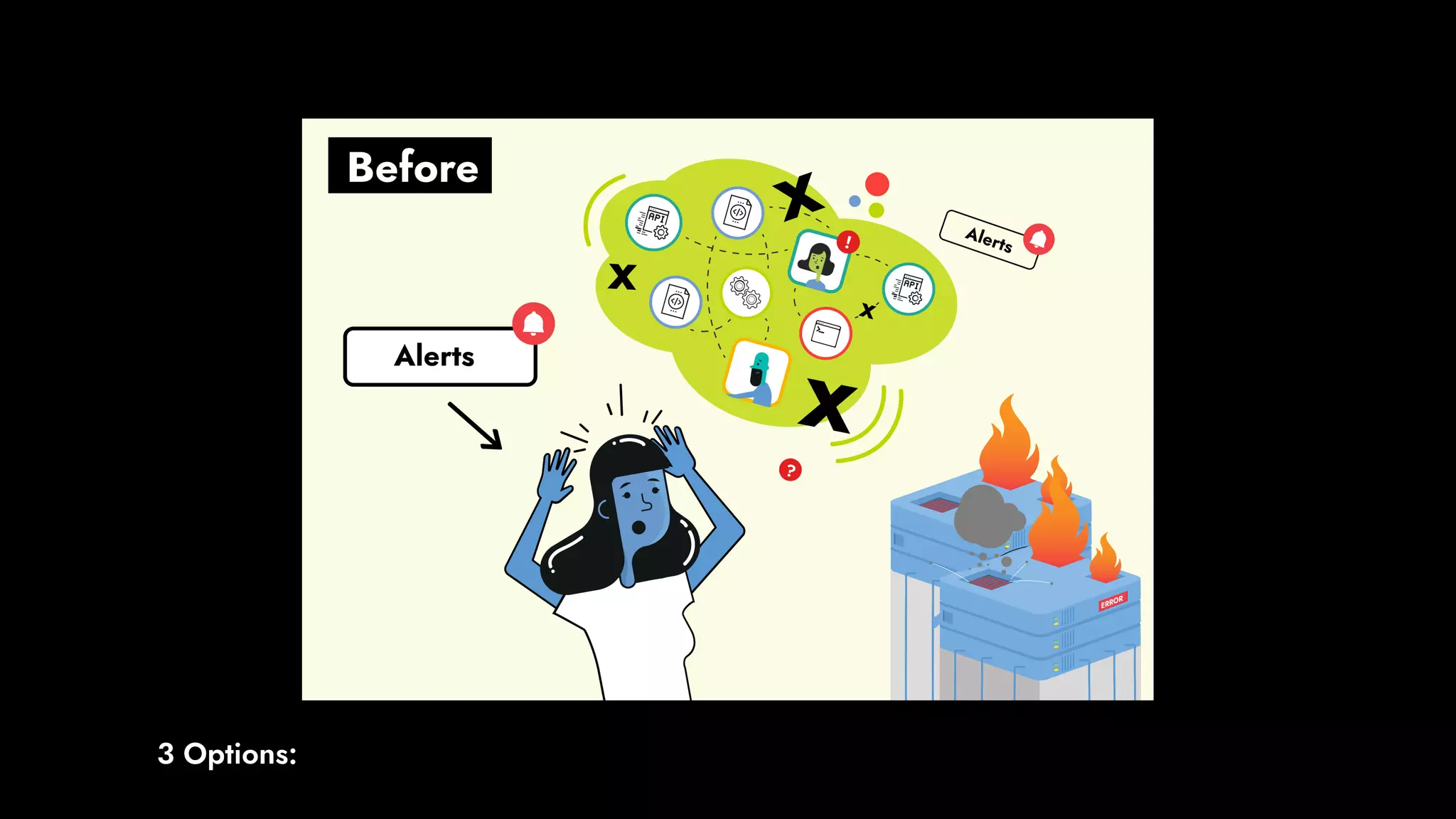
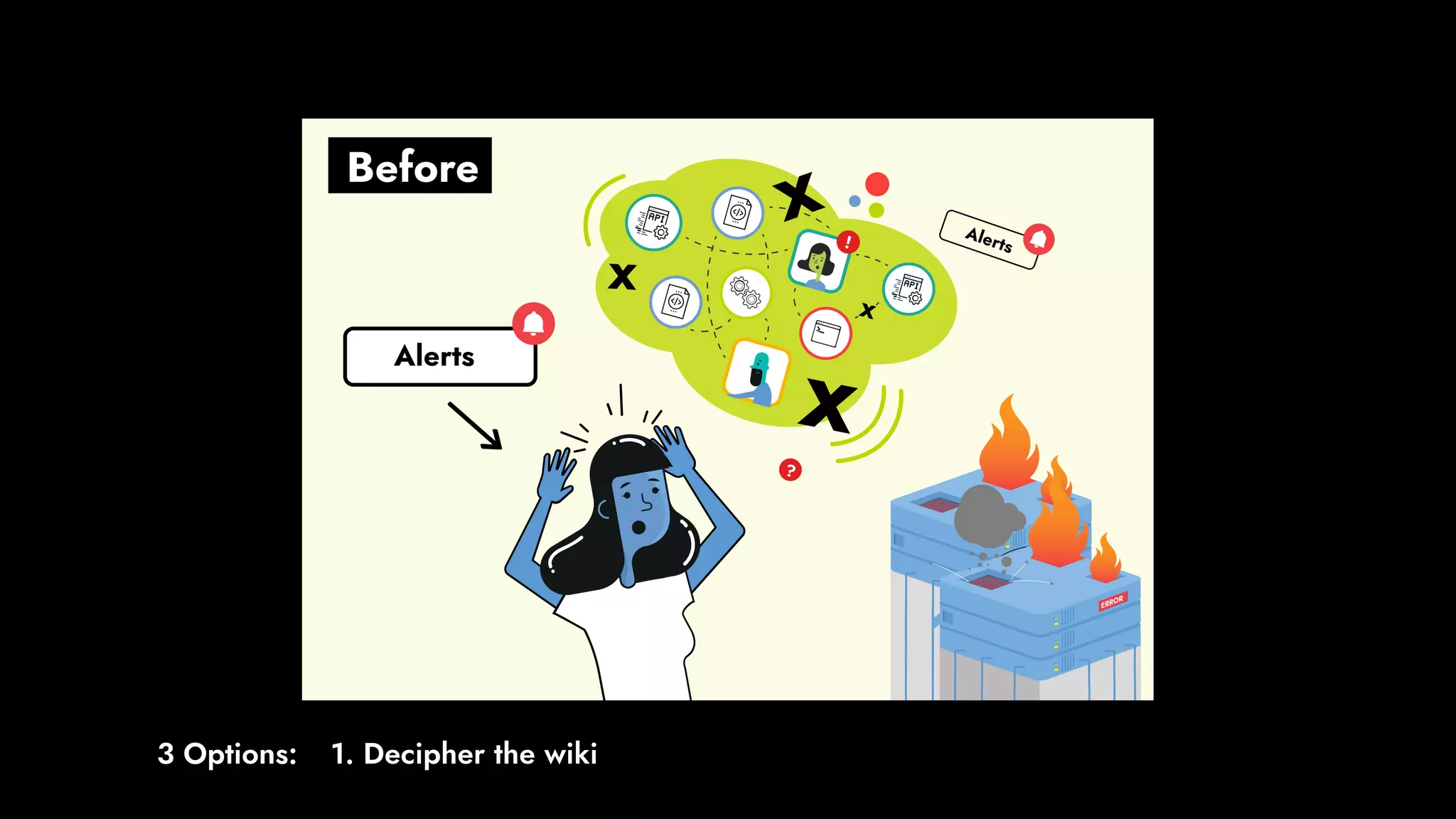
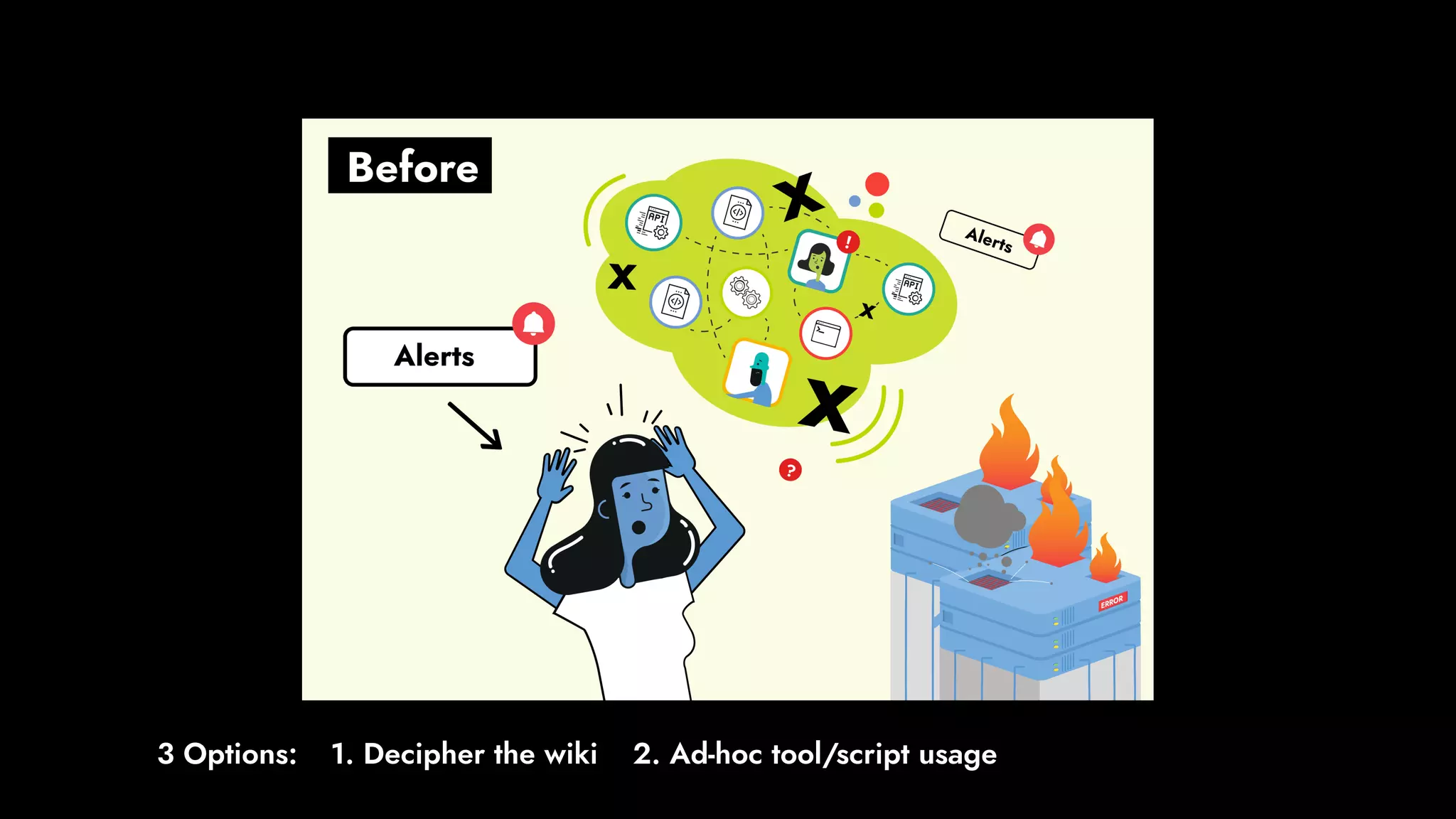
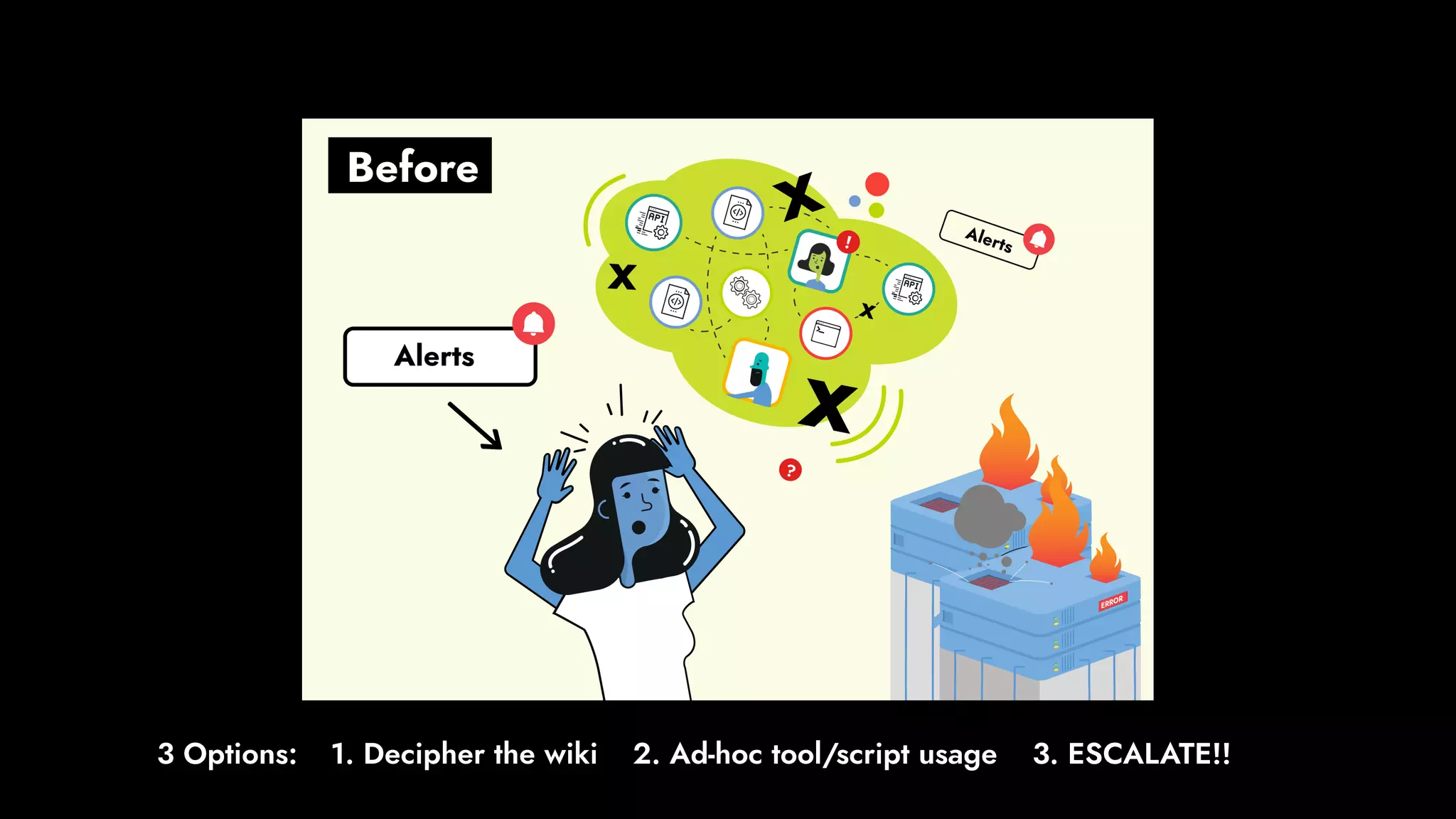
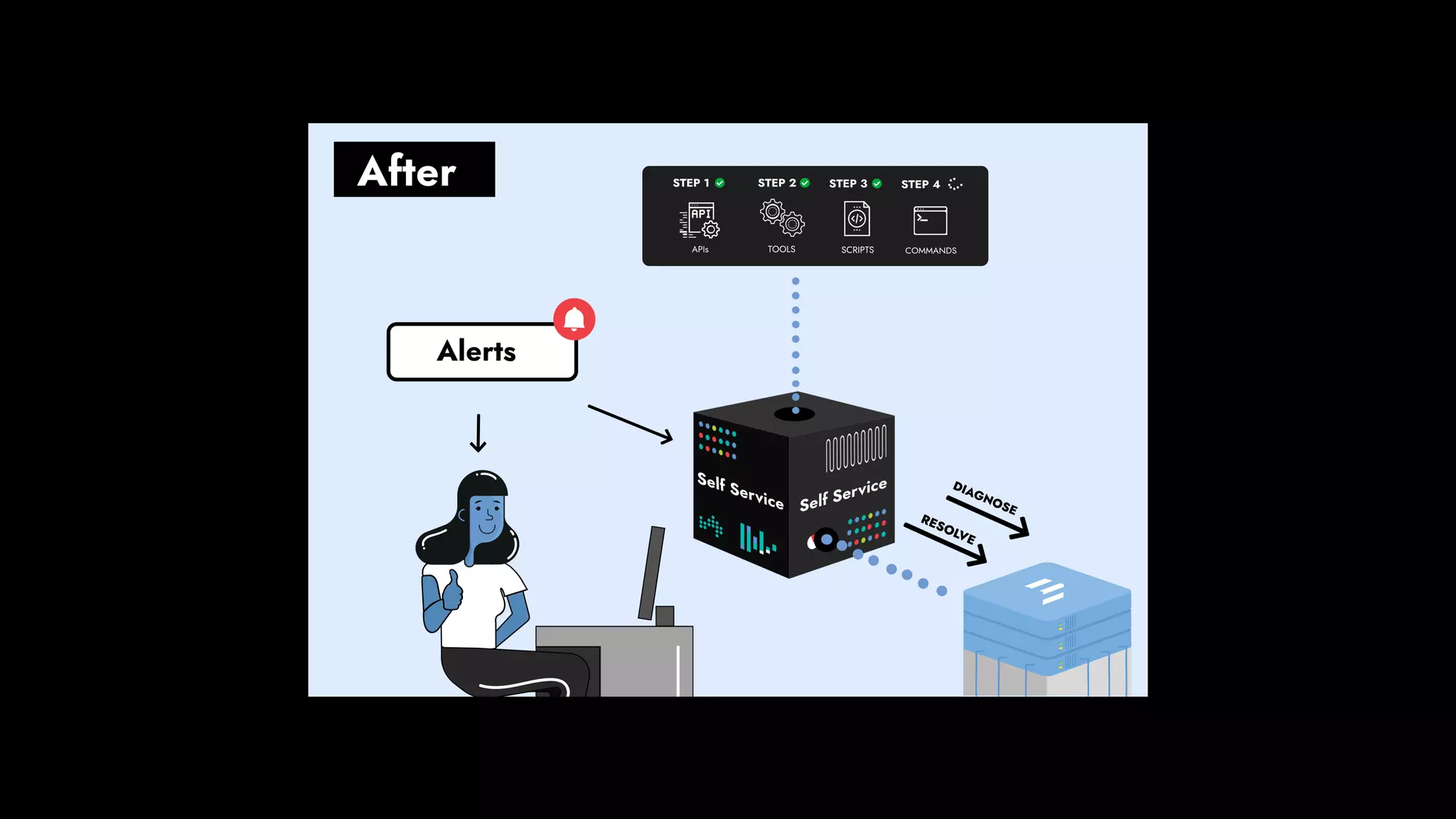
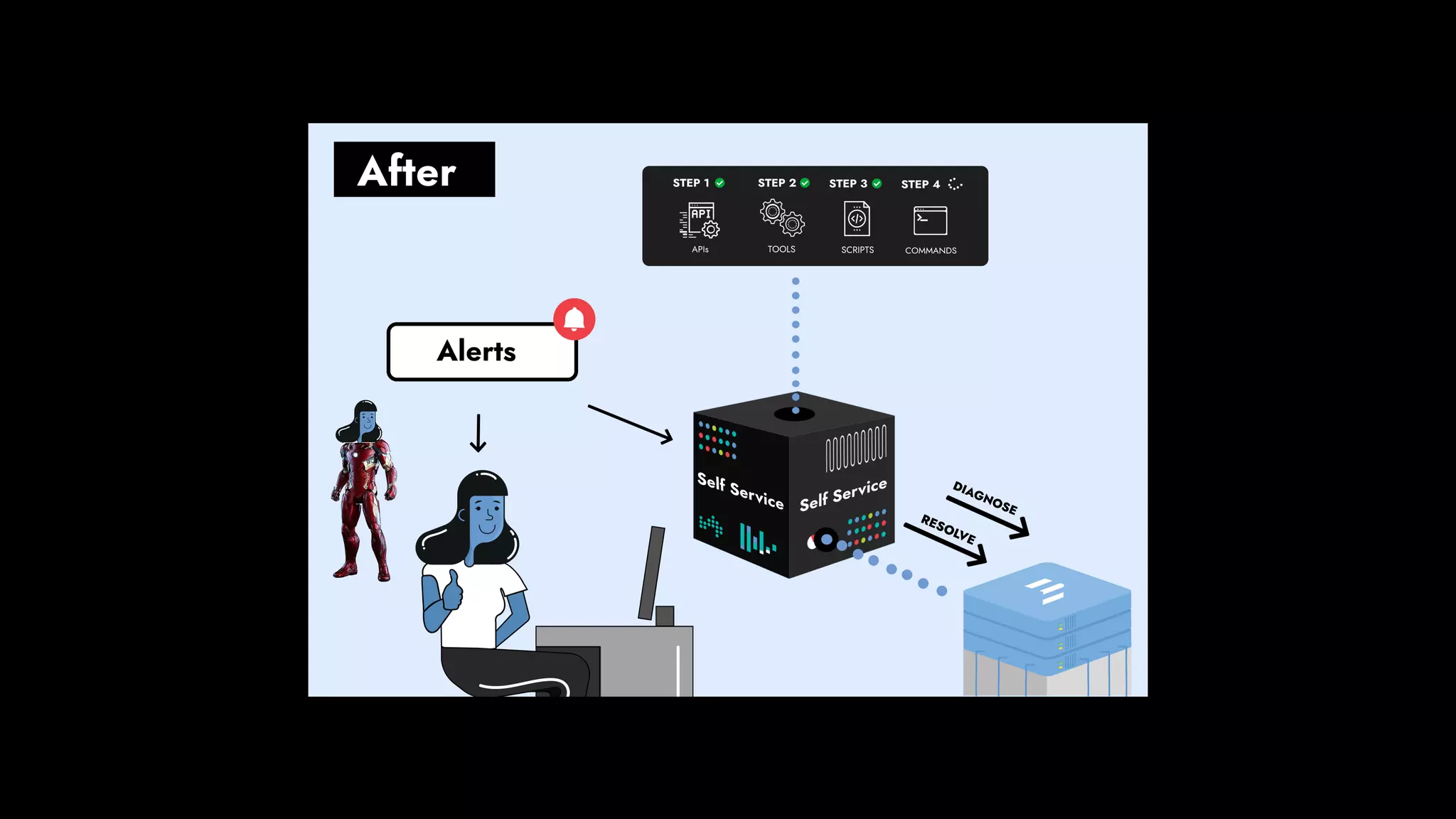
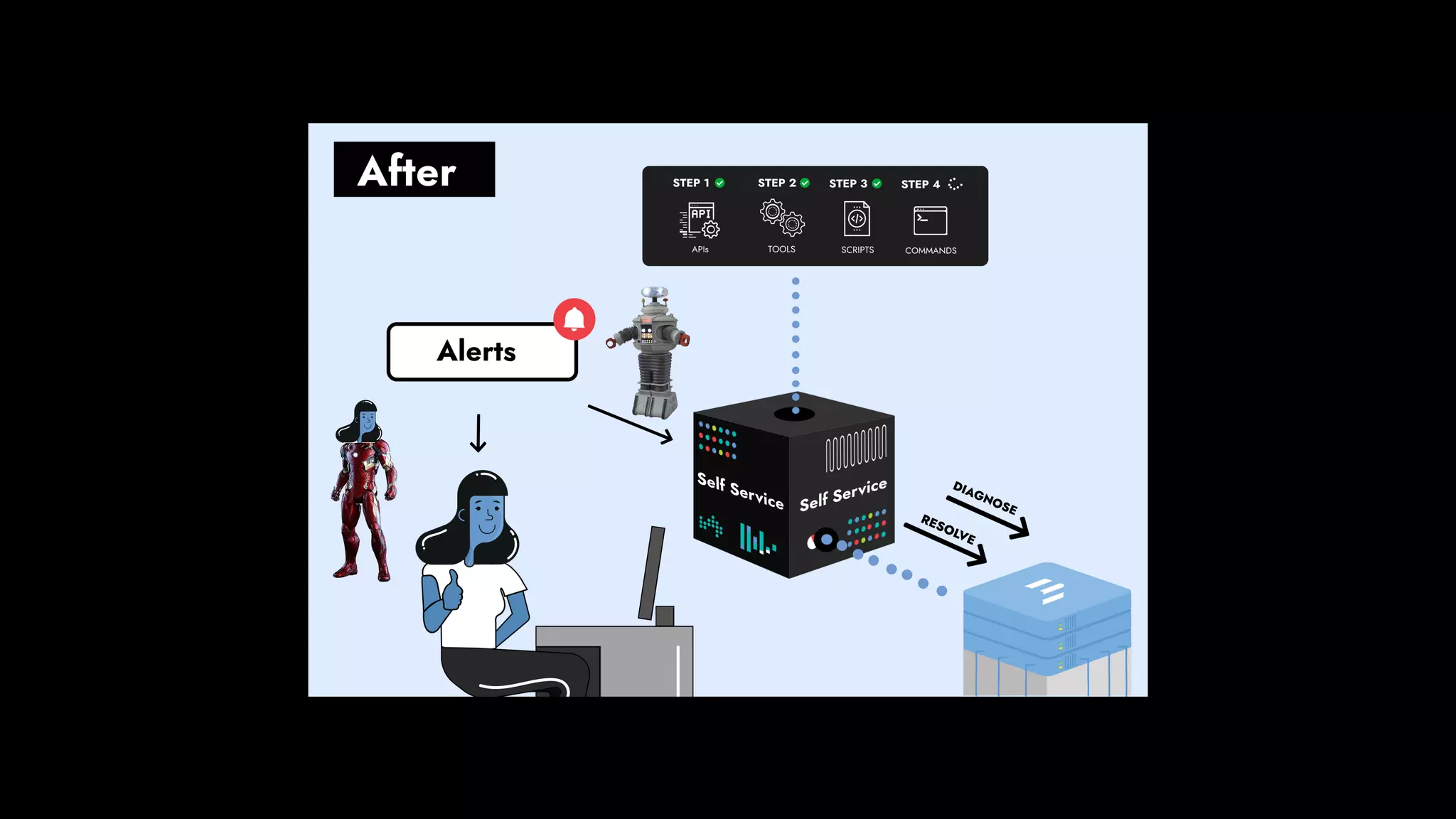




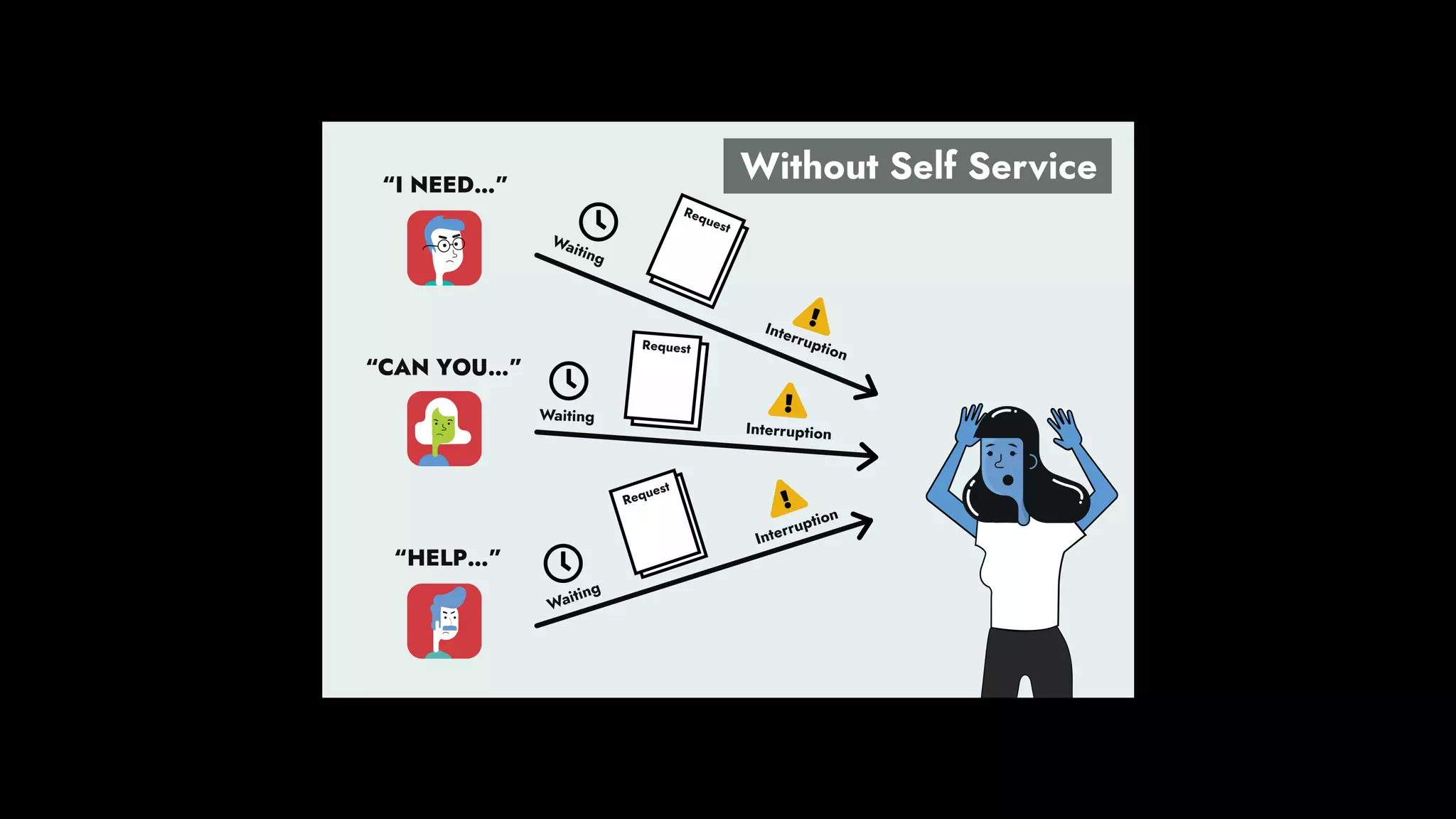
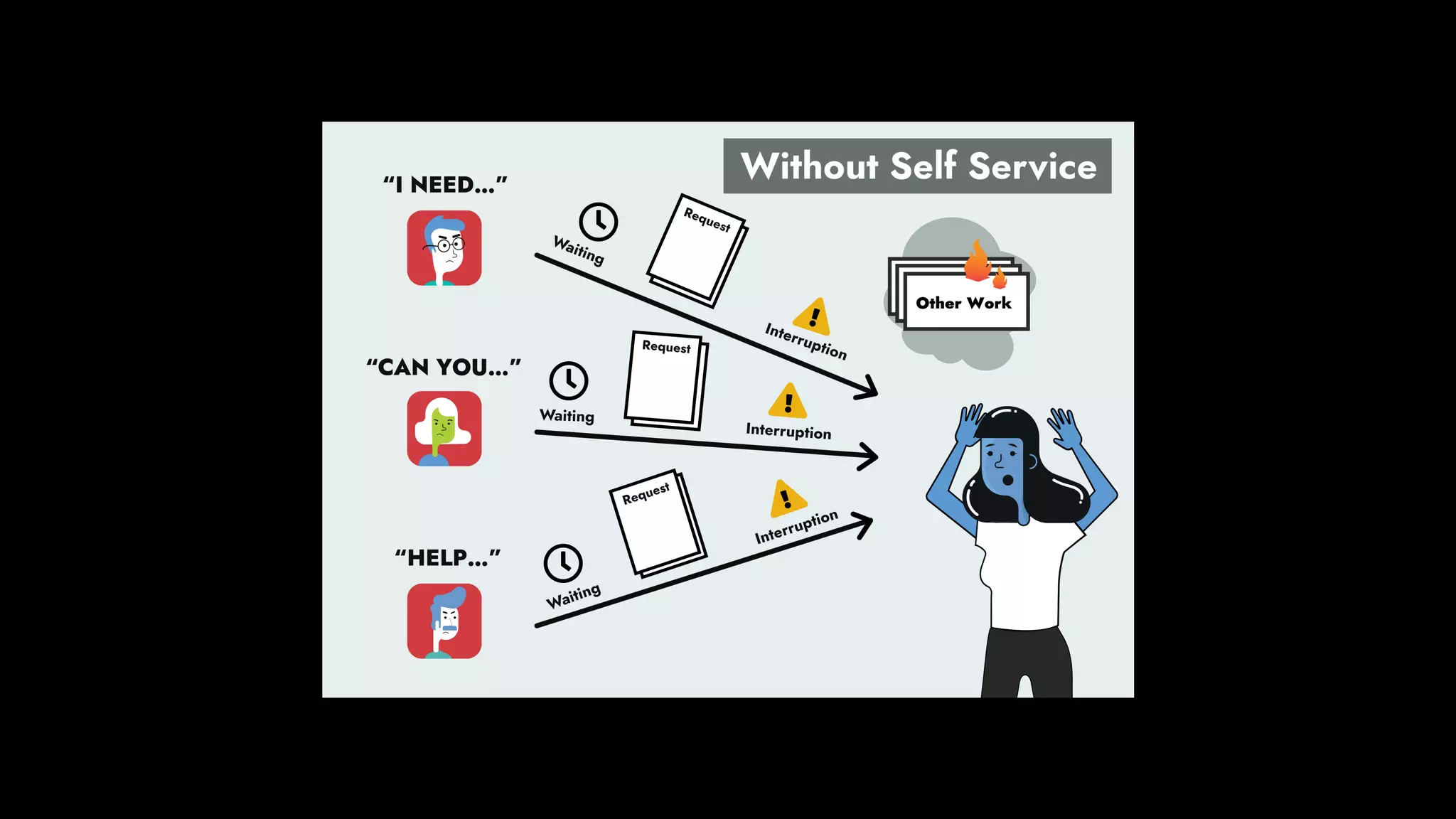
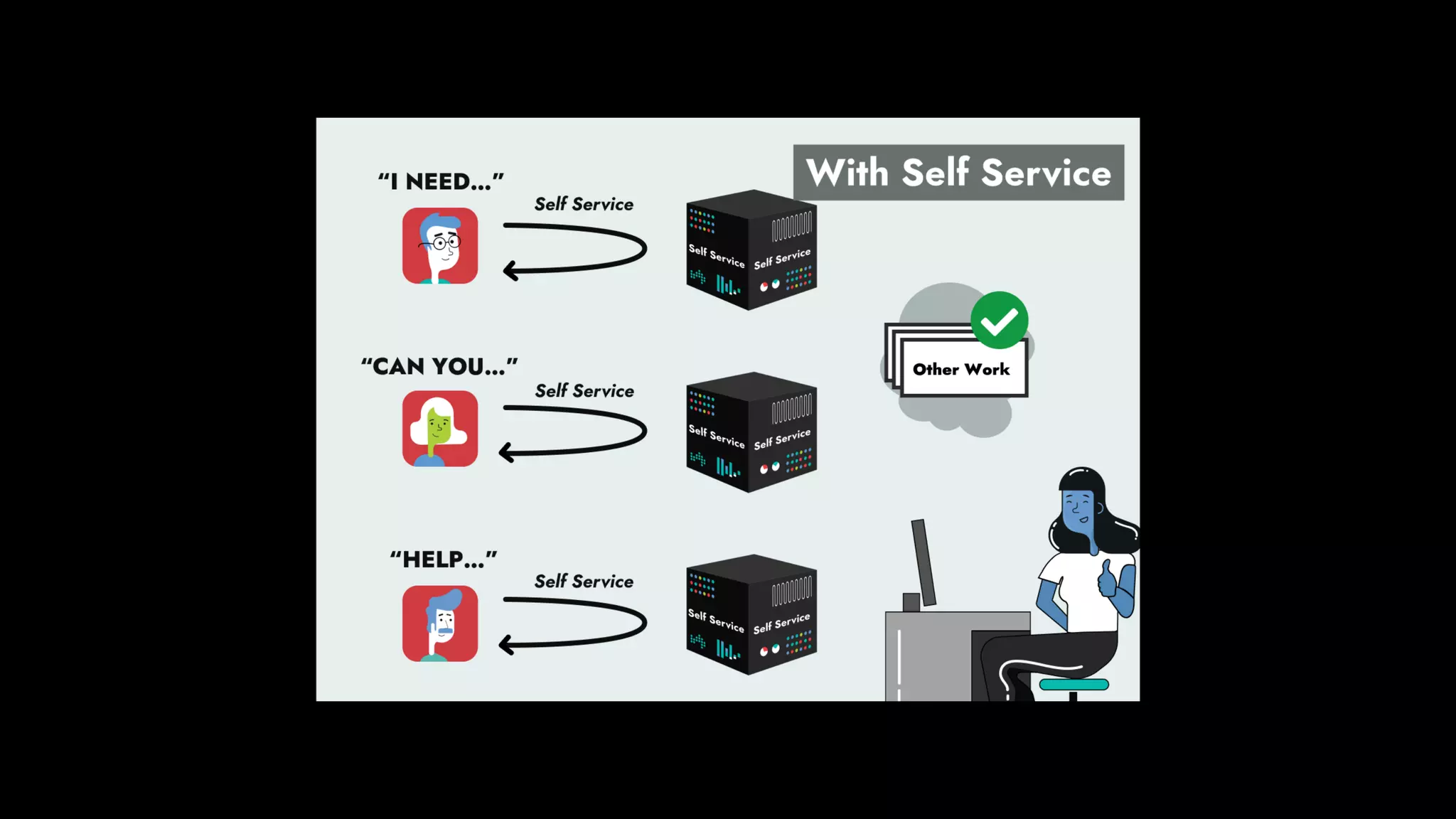

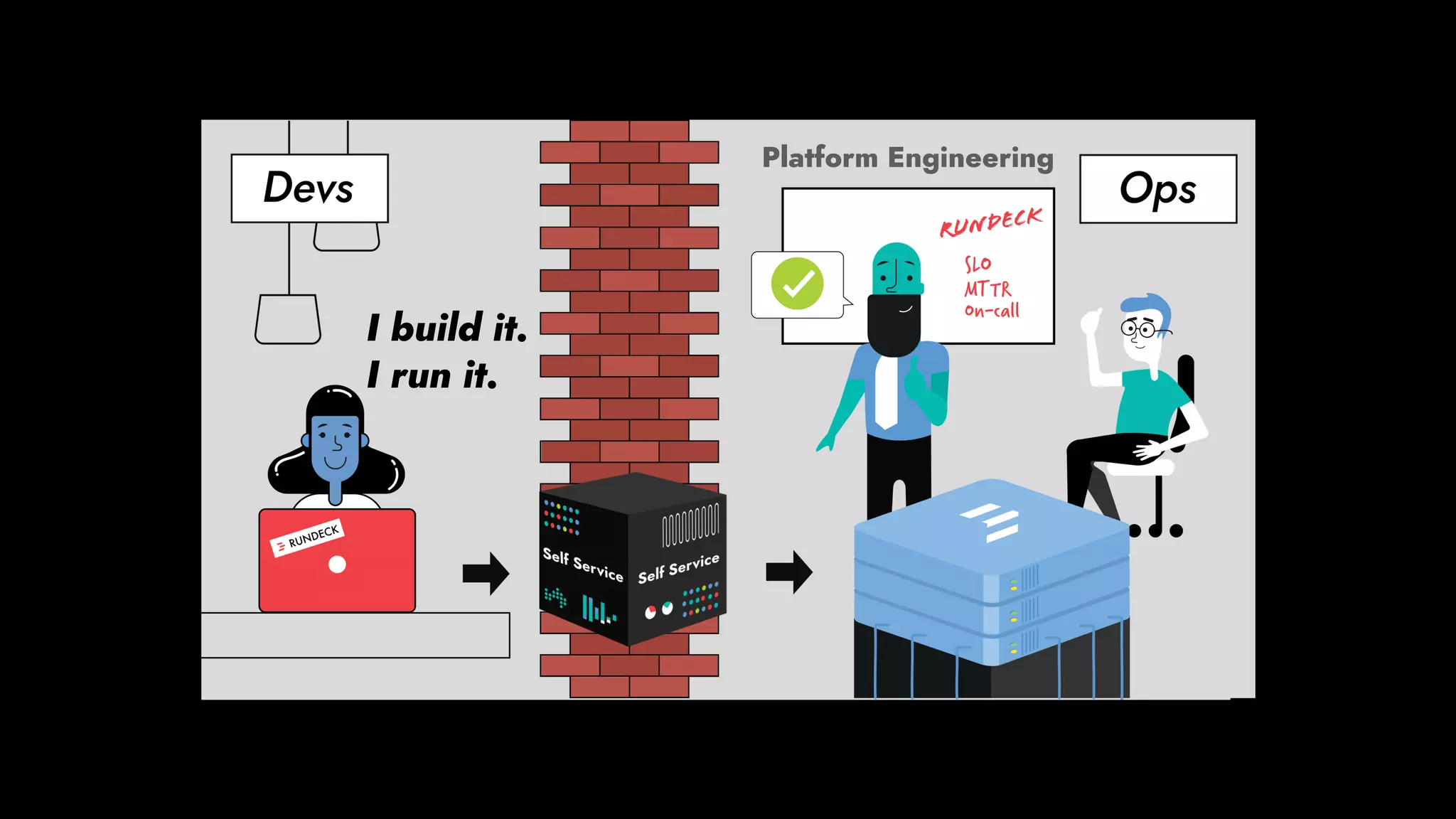


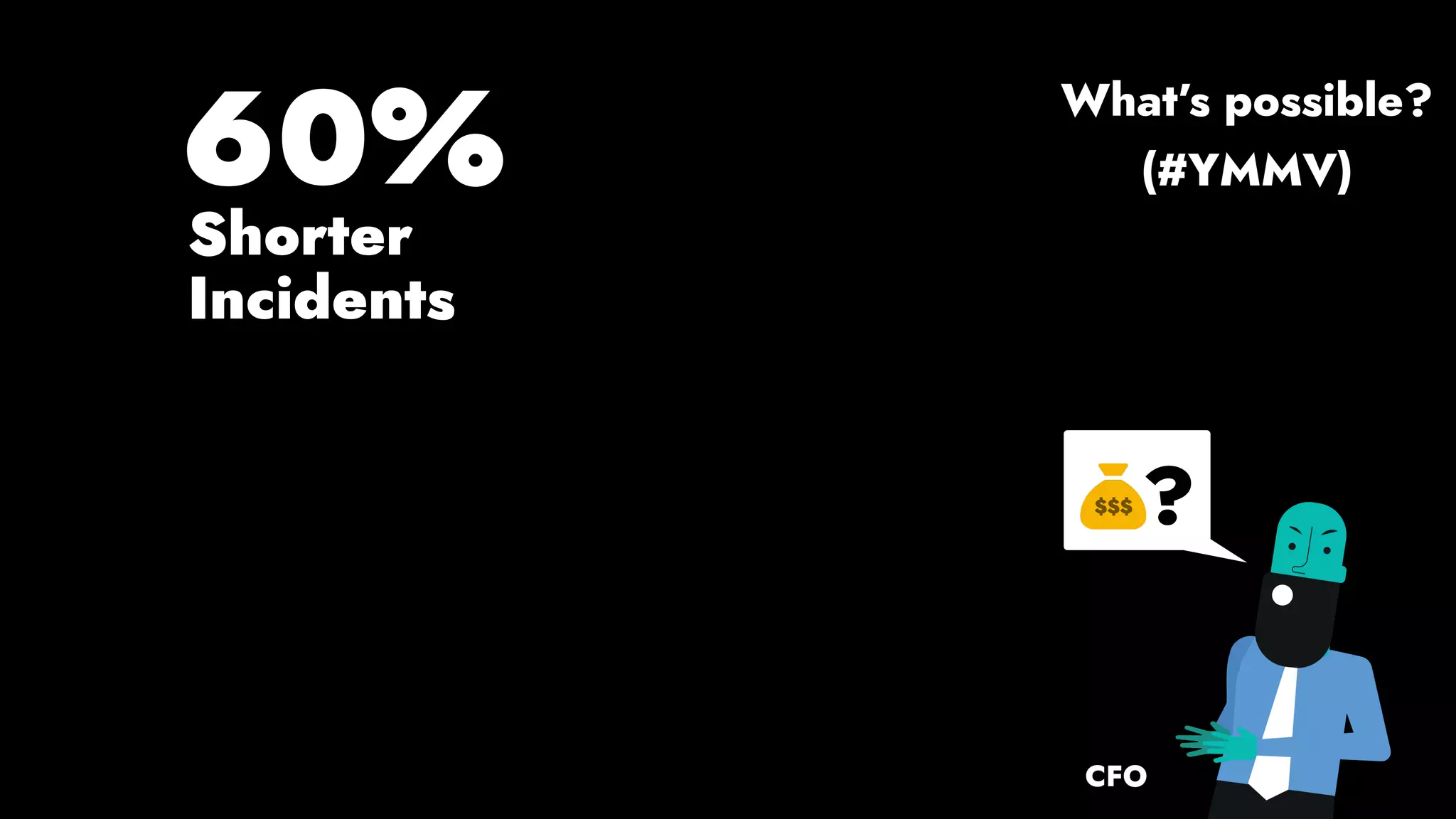
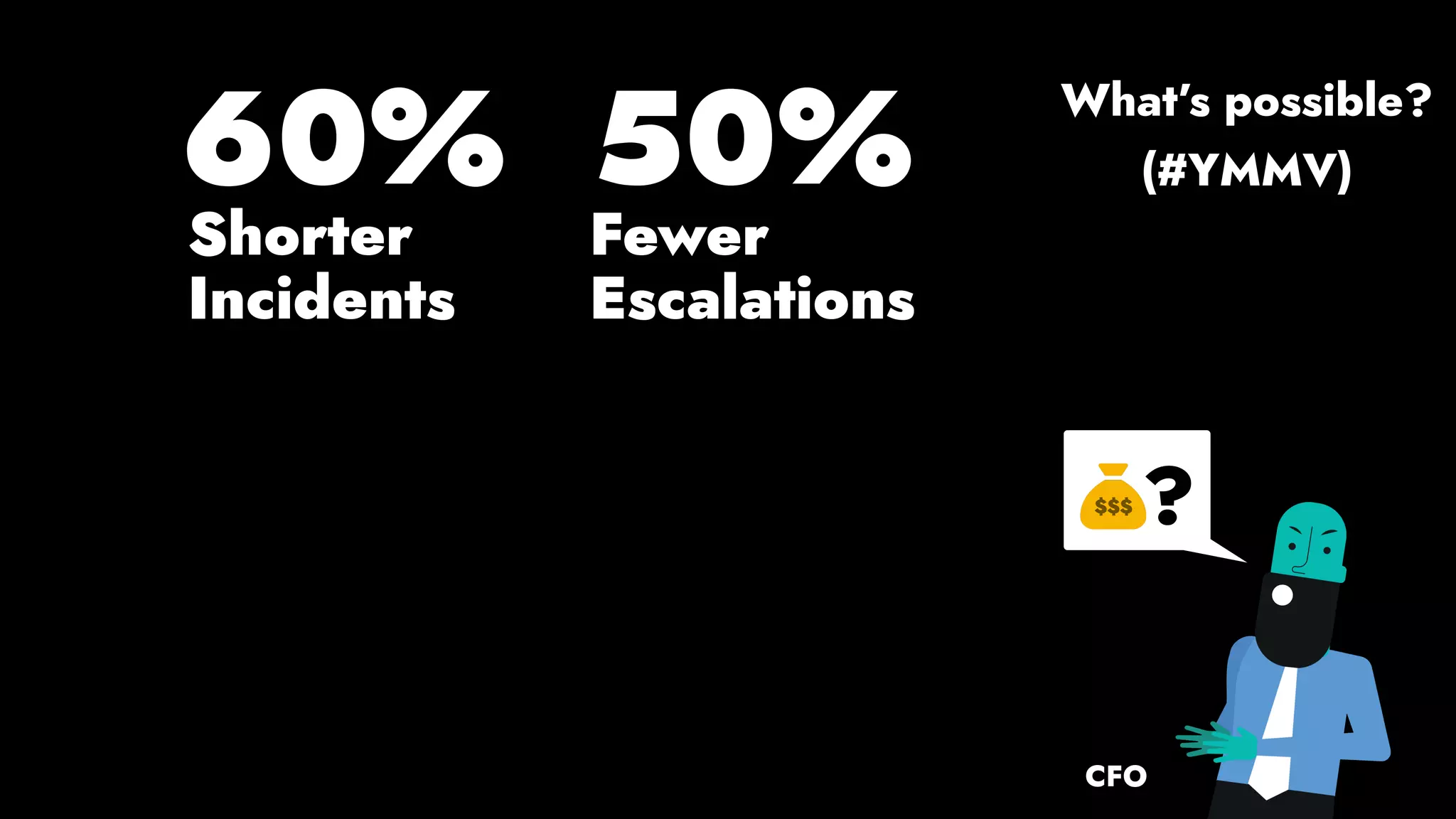
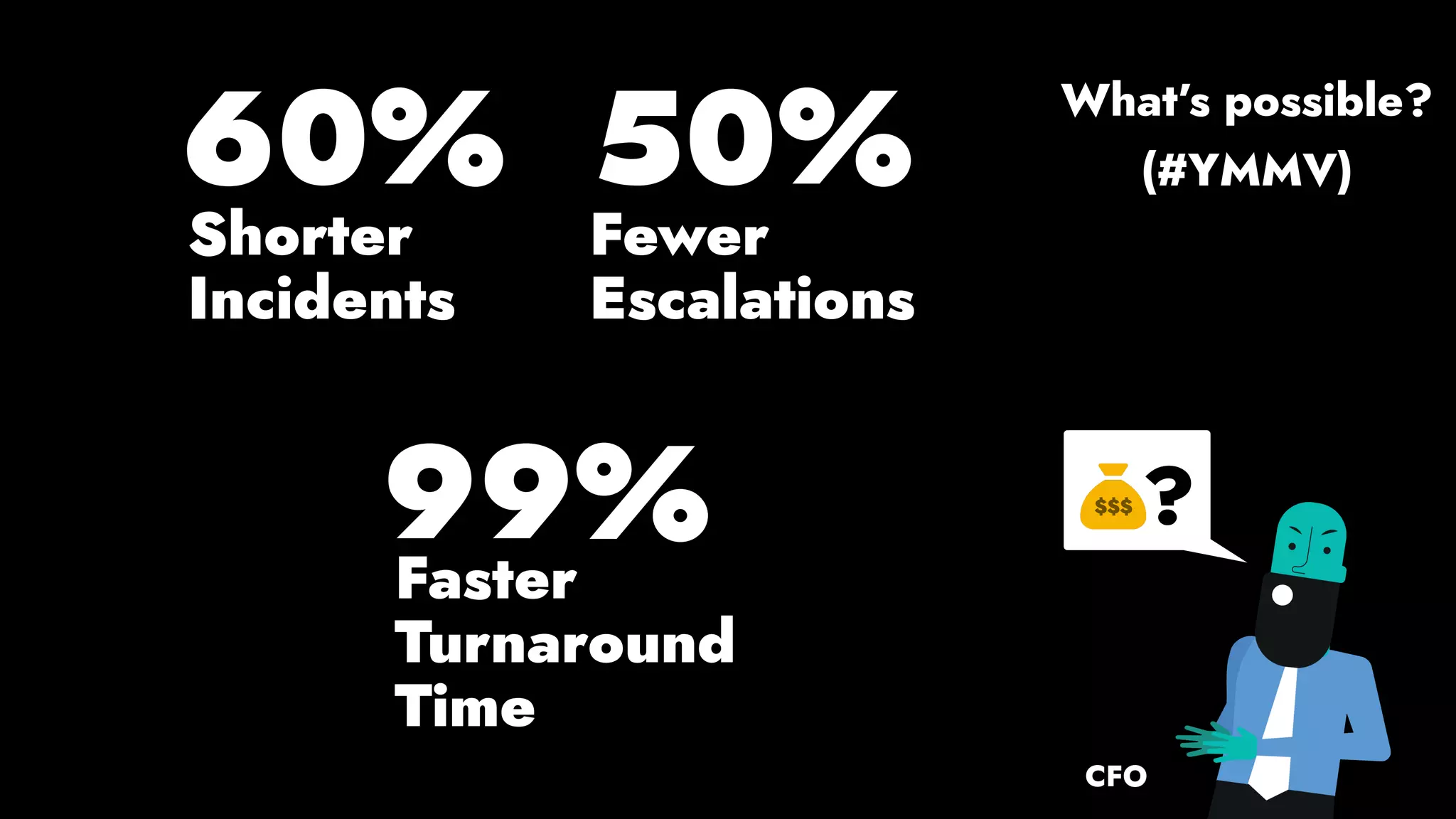
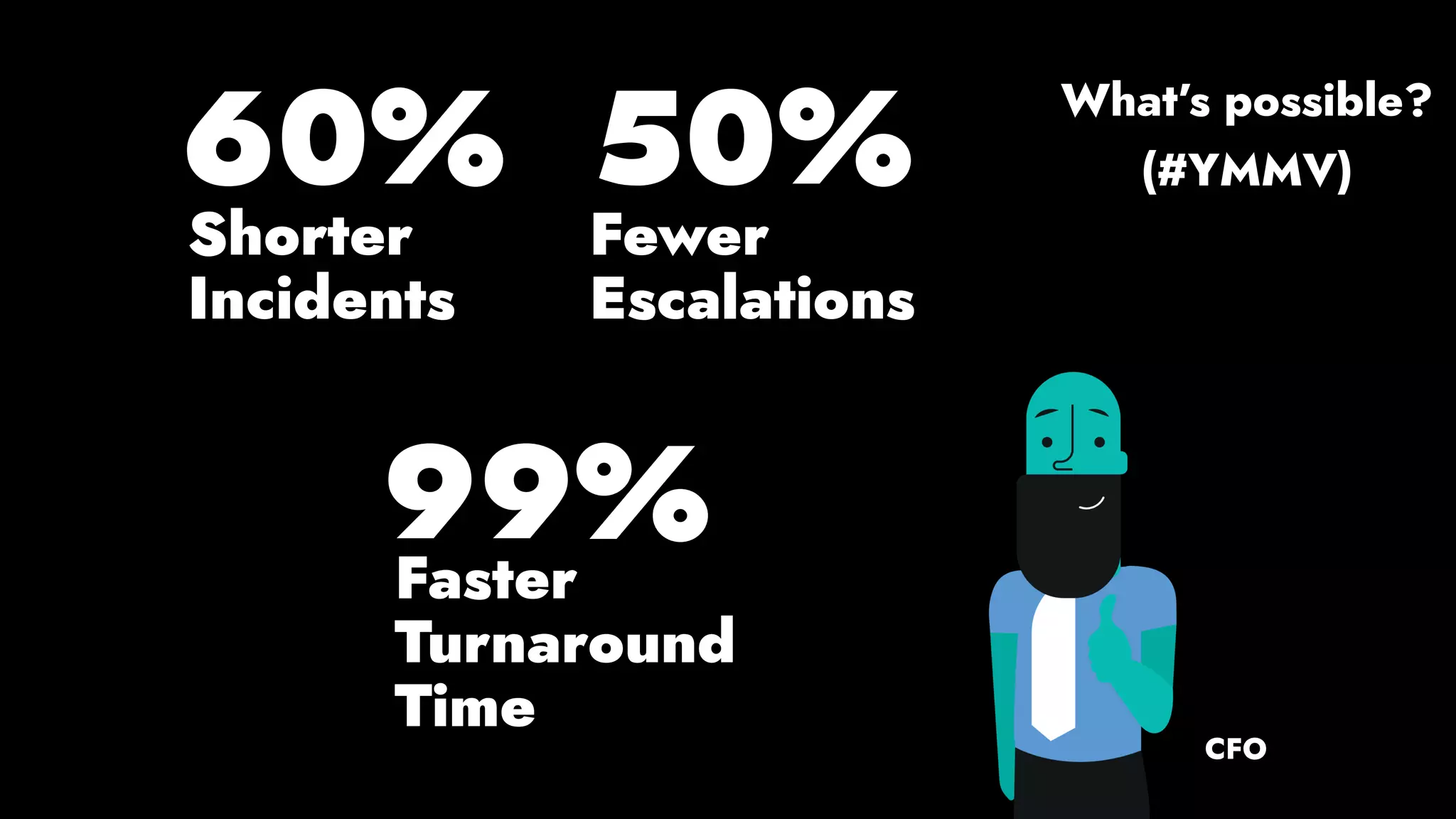
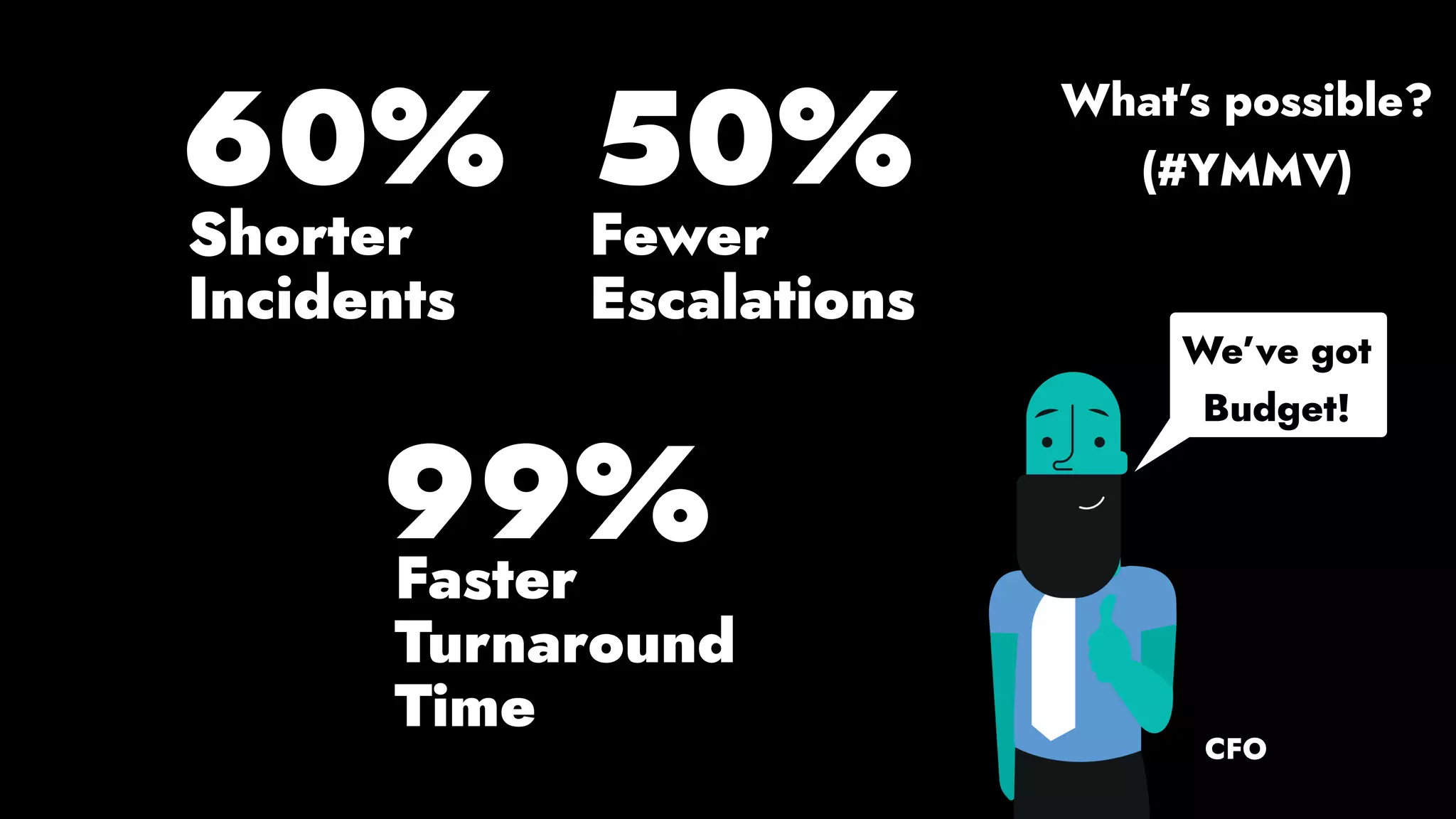
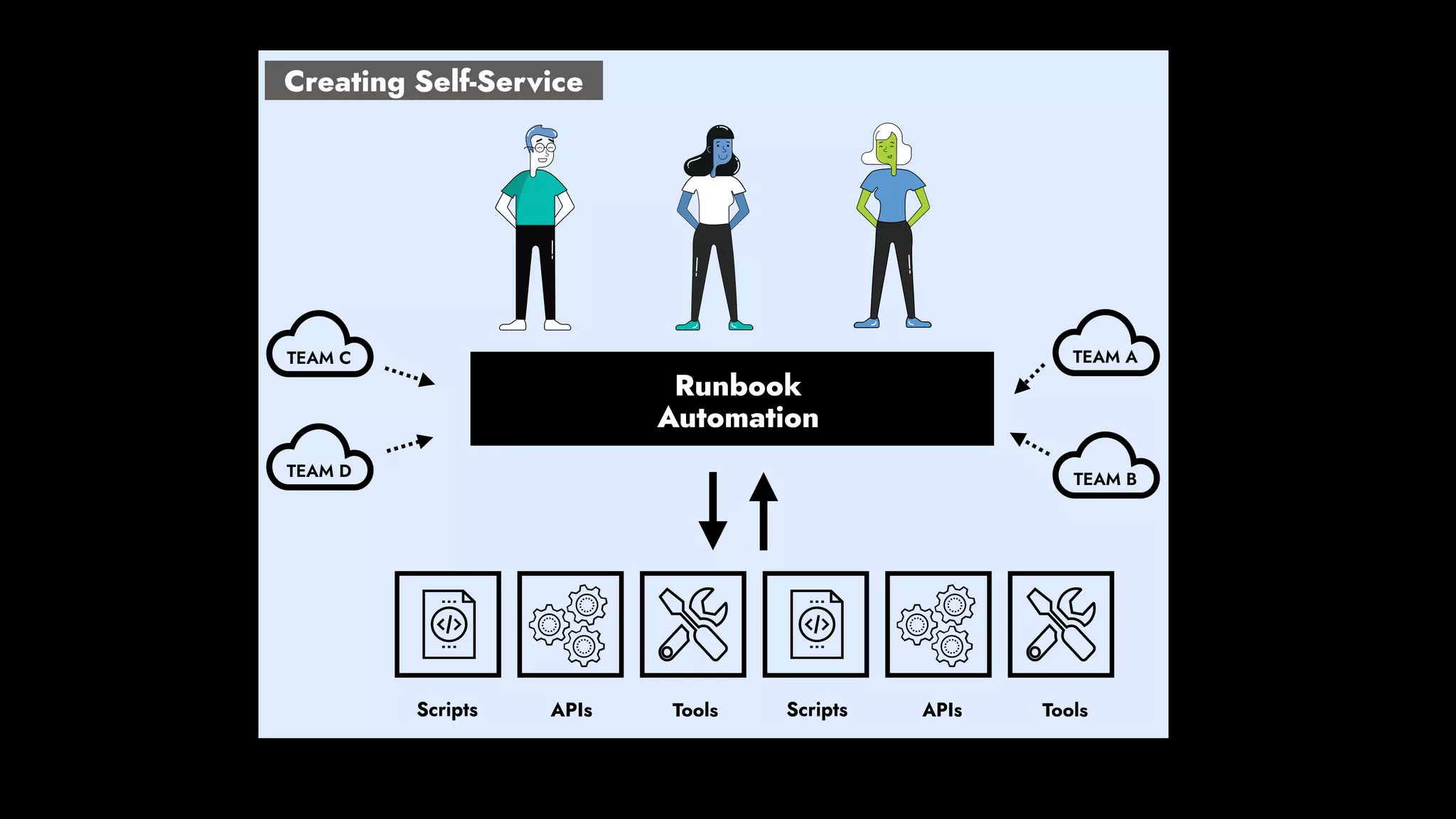
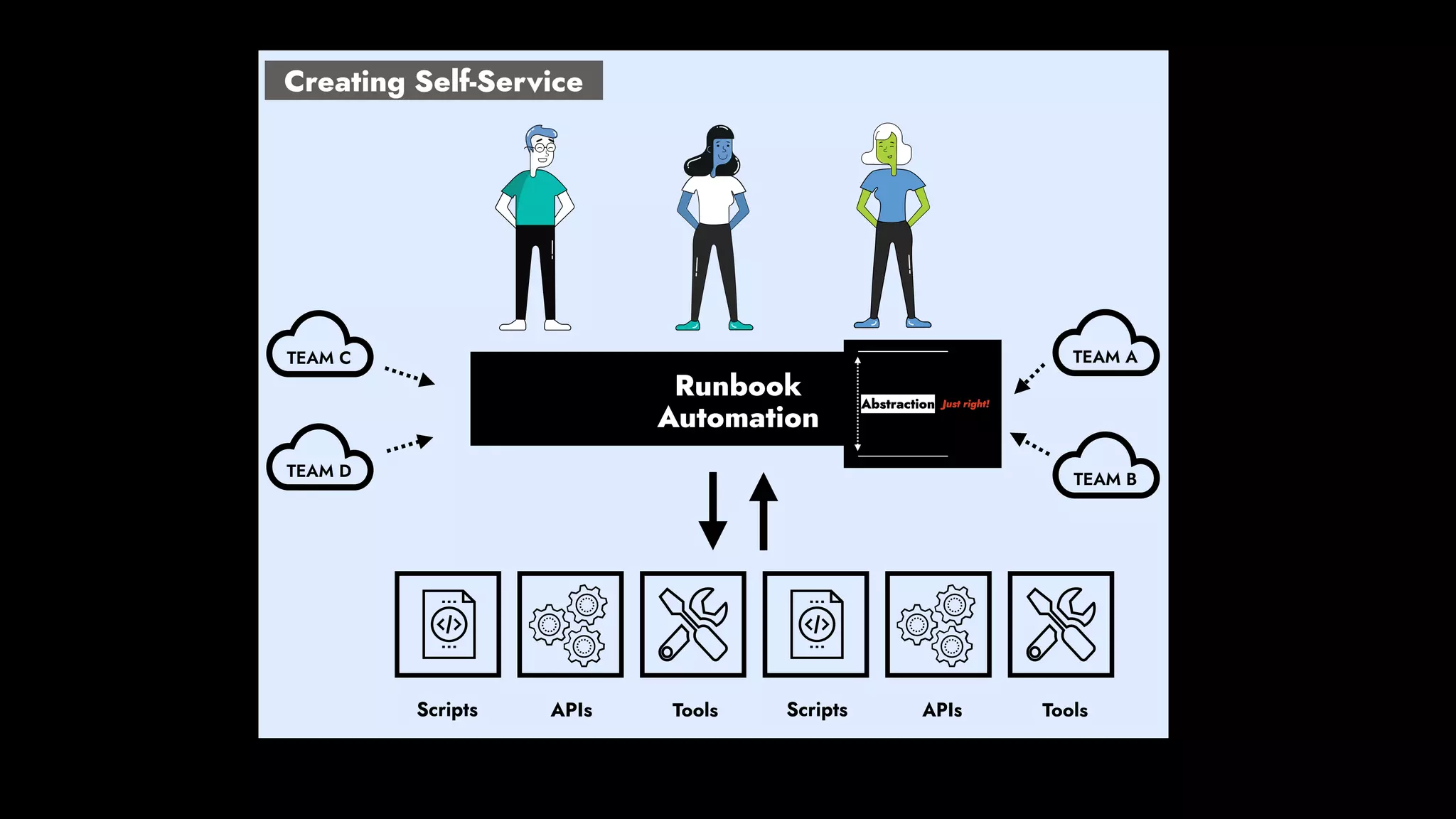
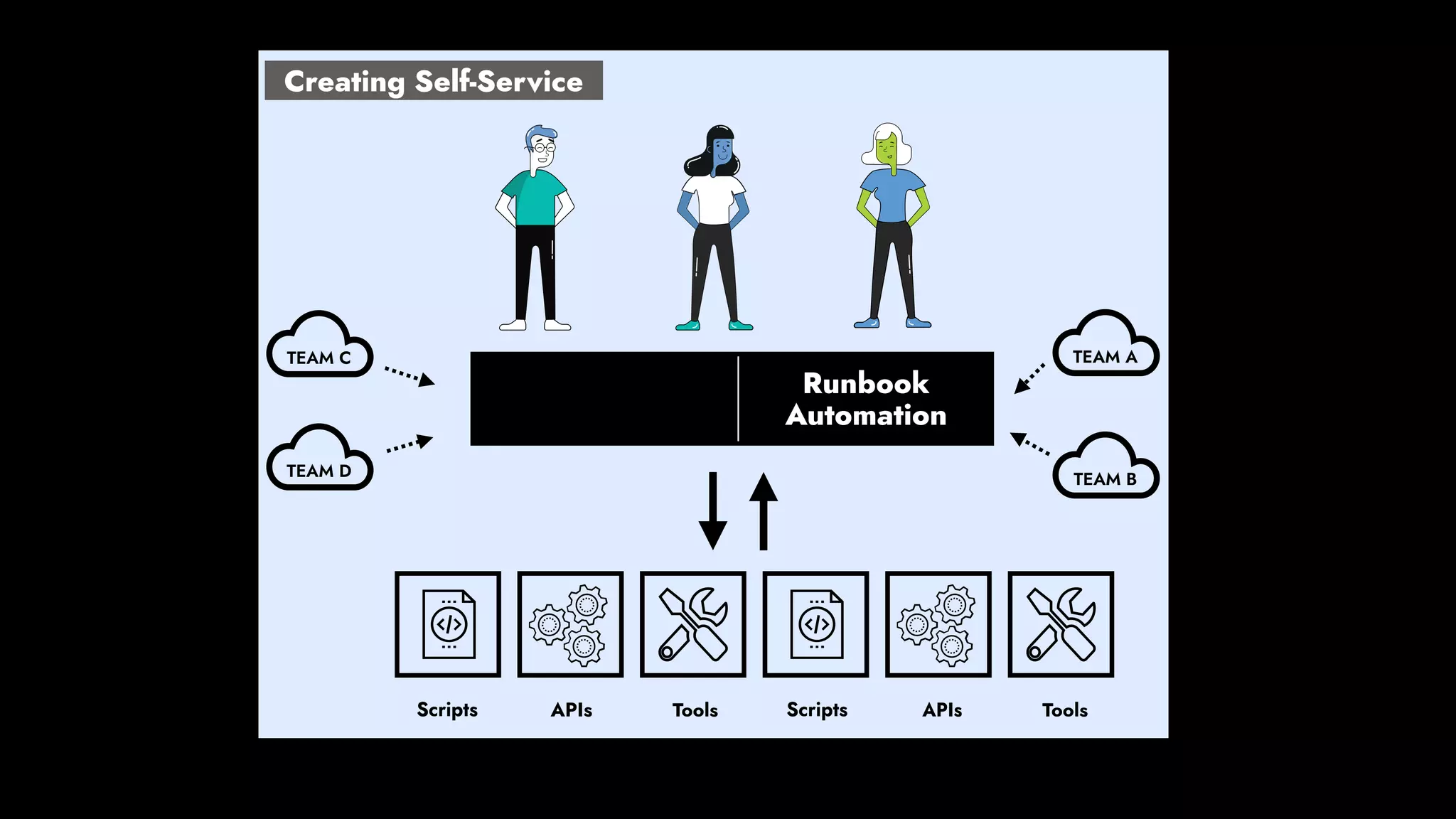
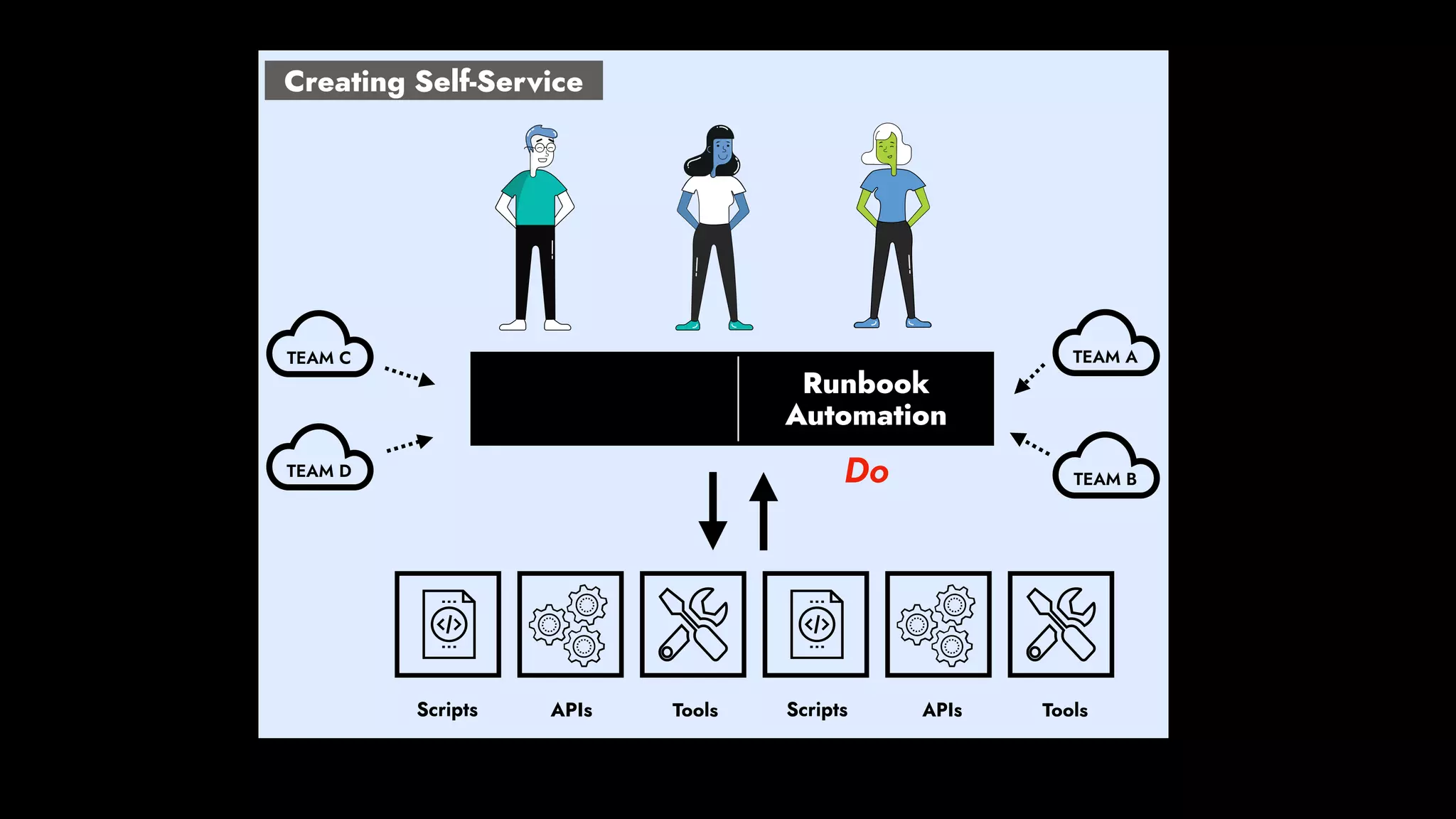
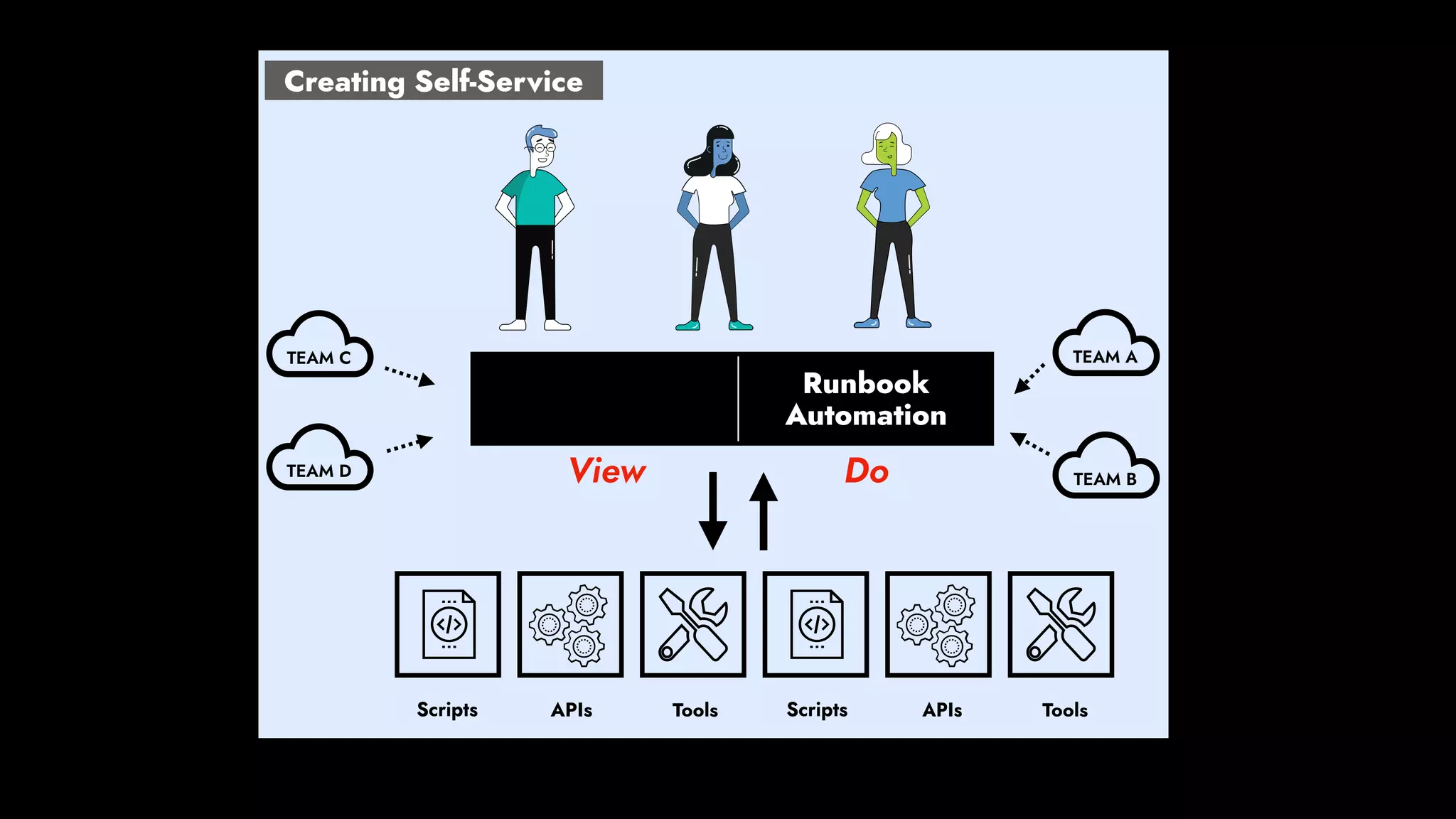
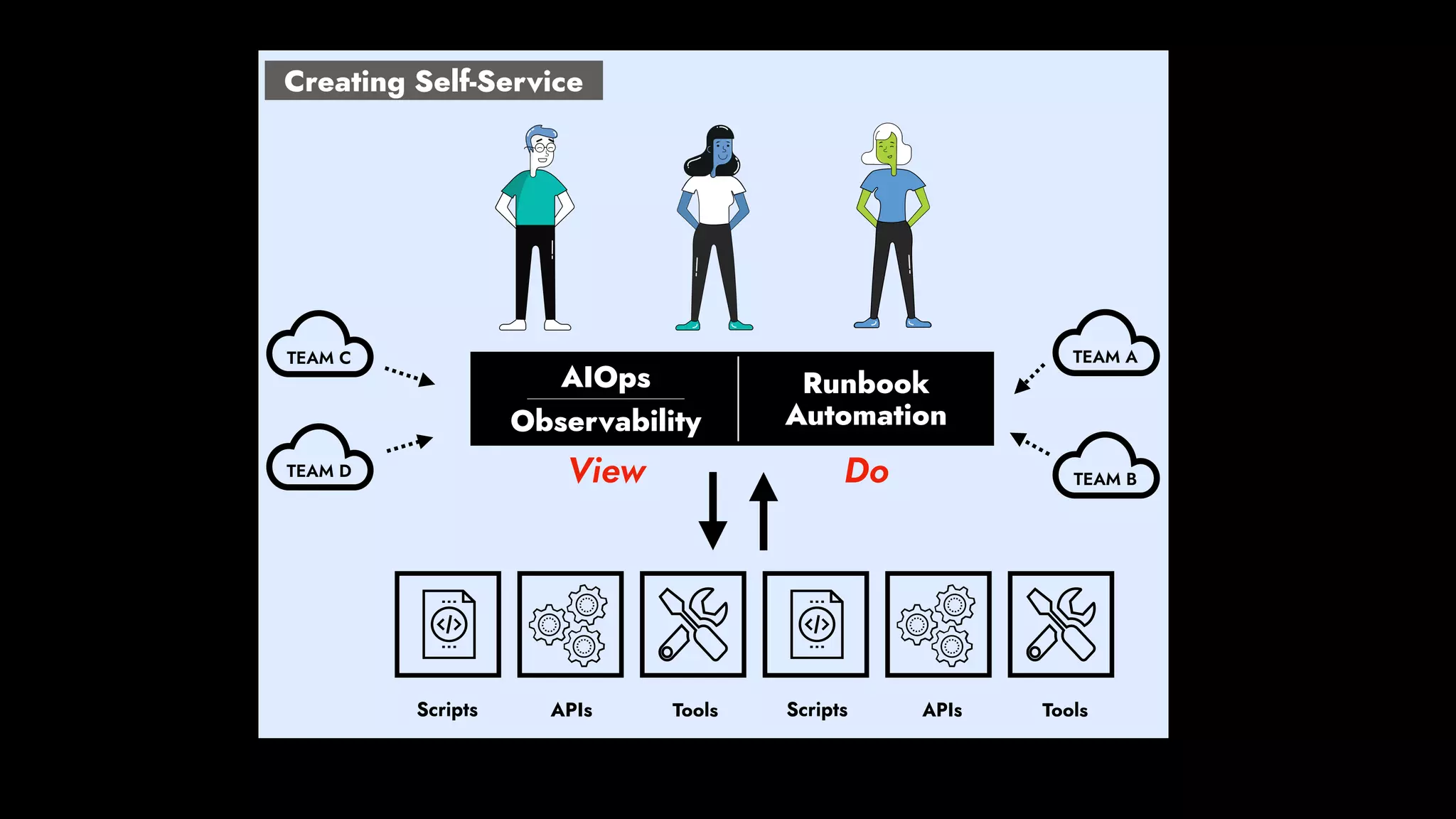





The document discusses the importance of runbook automation in enhancing operational performance and incident management, proposing that the next major advancements will come from improving operational techniques. It emphasizes the complexity of systems and the need for human operators to effectively monitor, respond, adapt, and learn from incidents rather than relying solely on automation. Key strategies include creating self-service options and improving collaboration between development and operations teams.











































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)






![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)


