Download as PDF, PPTX








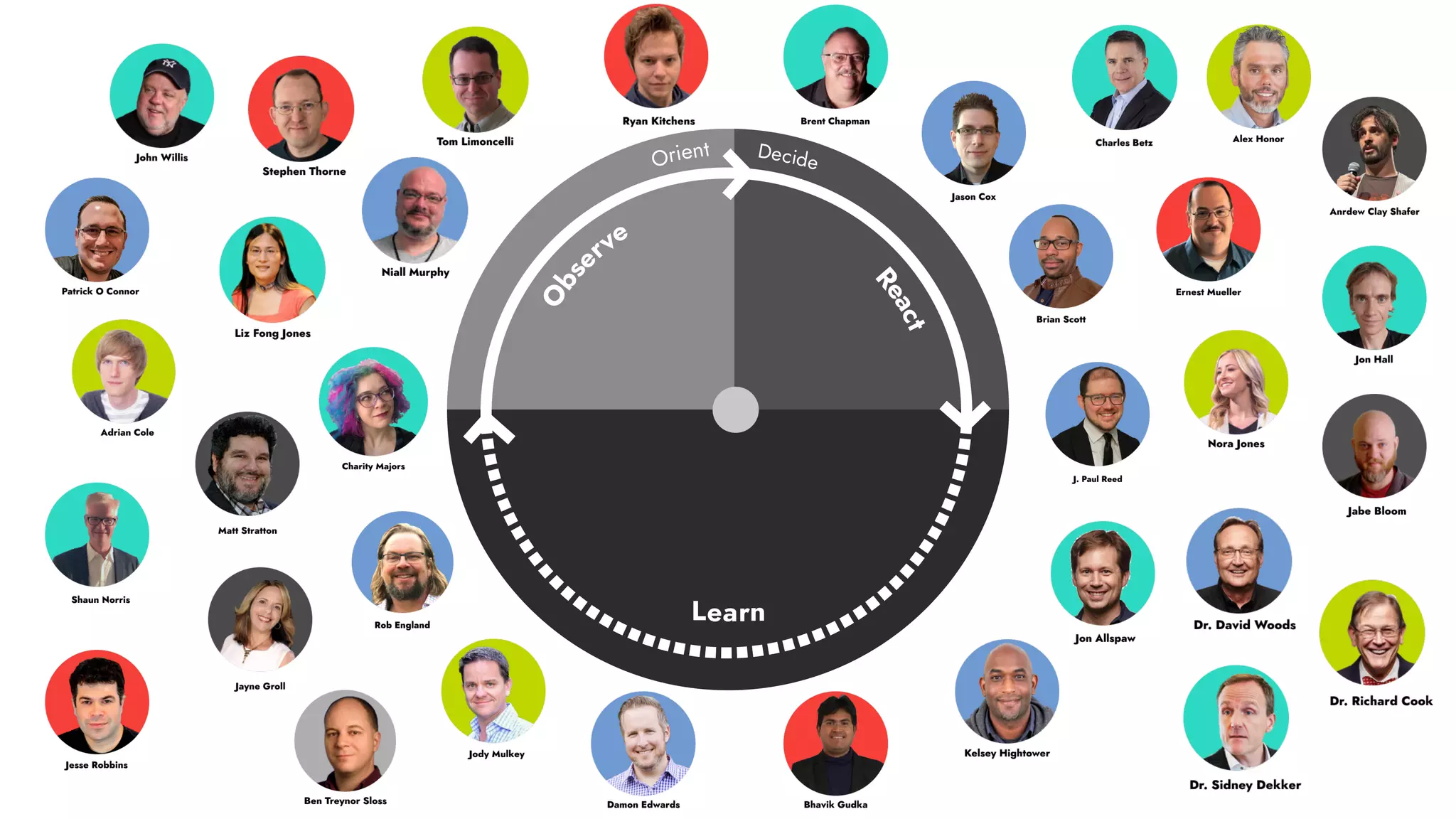
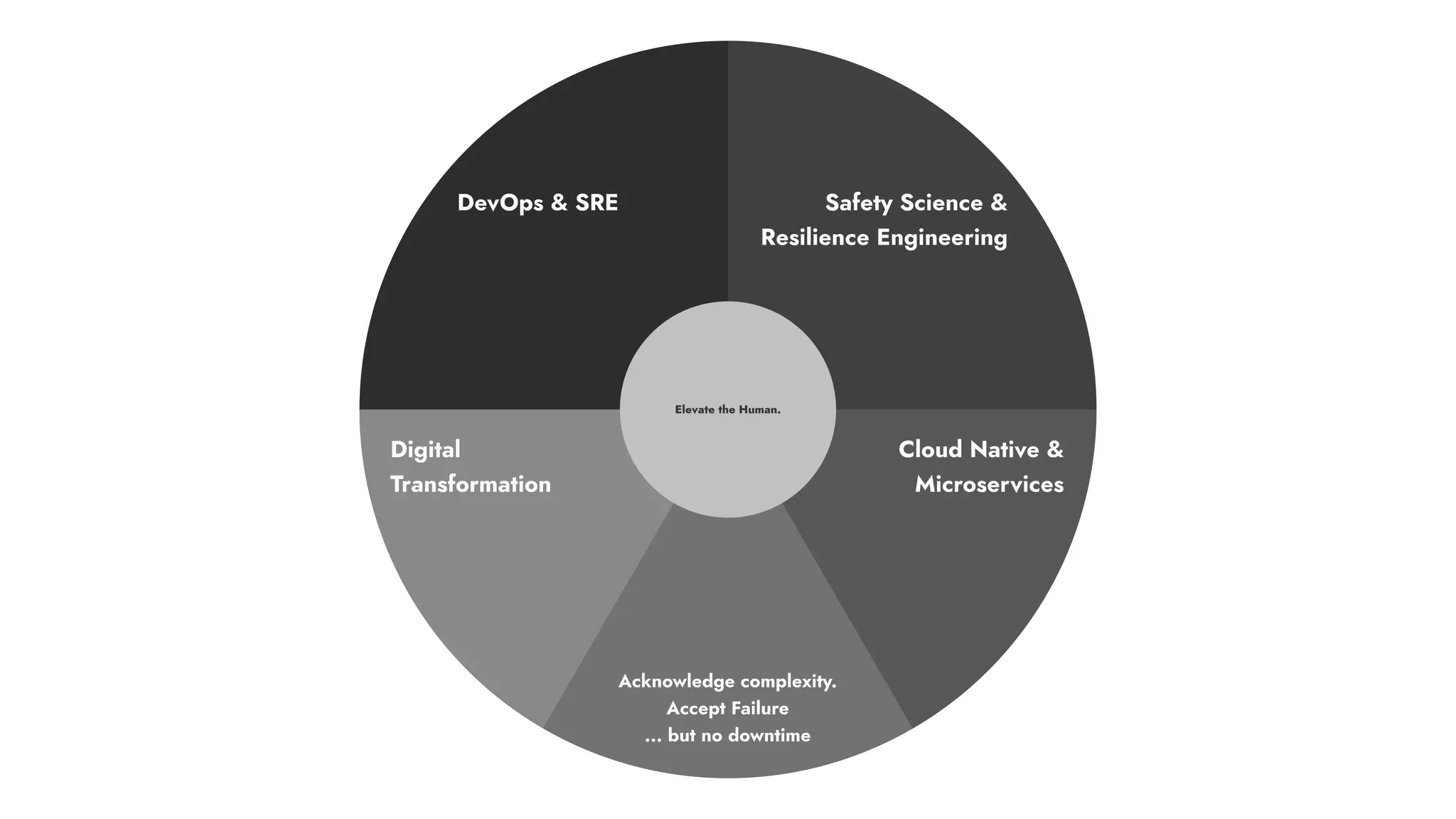









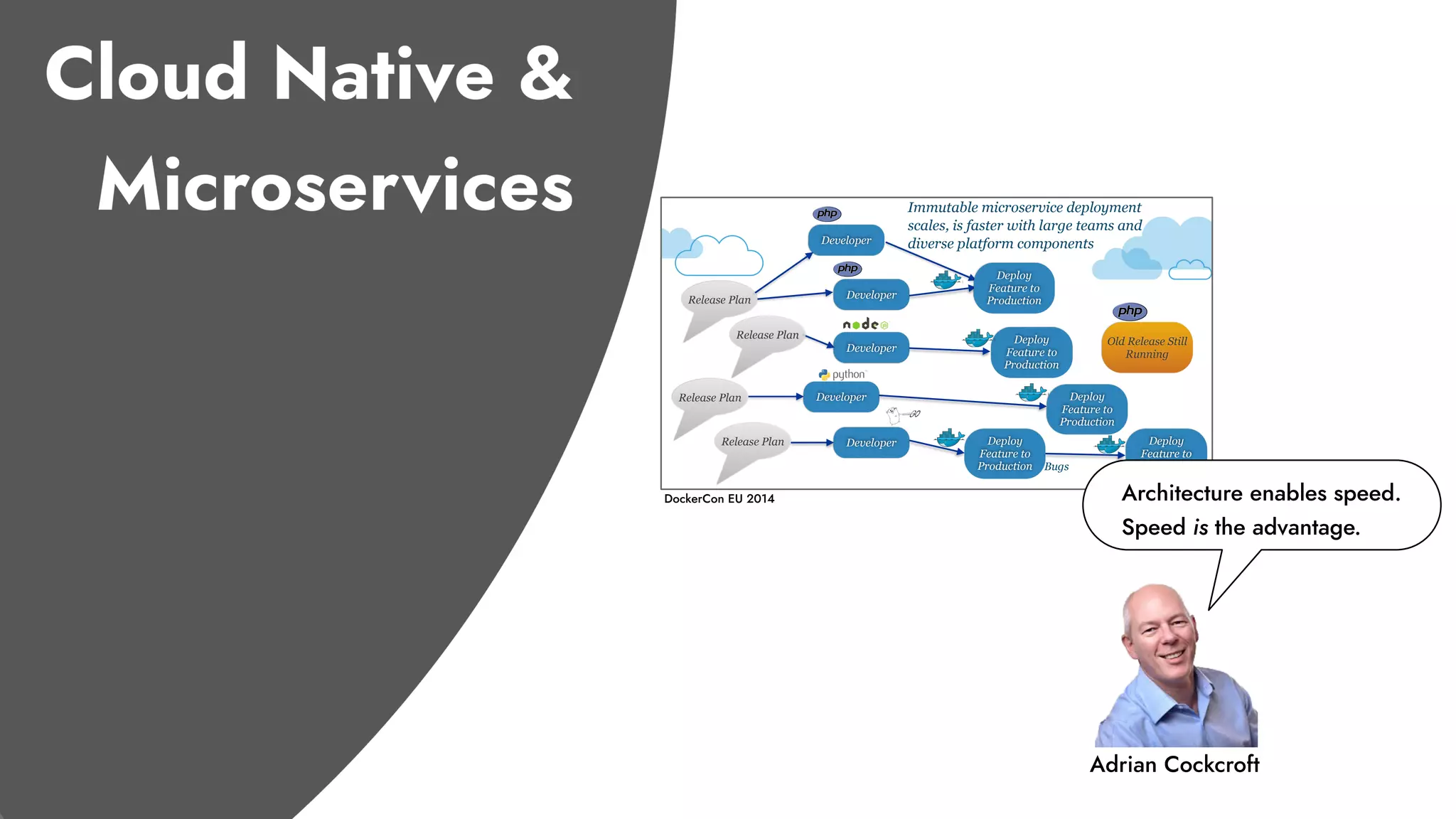













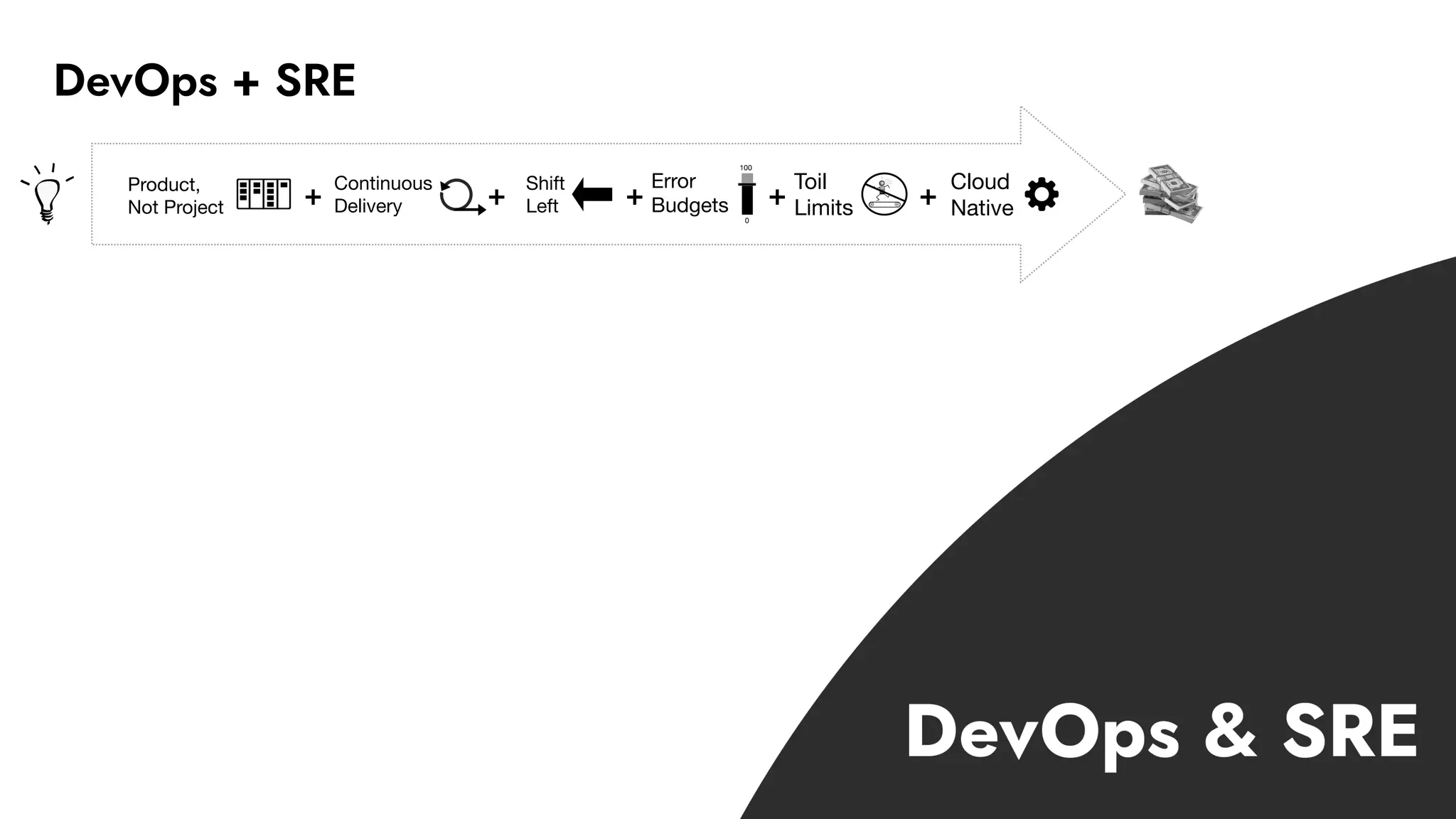
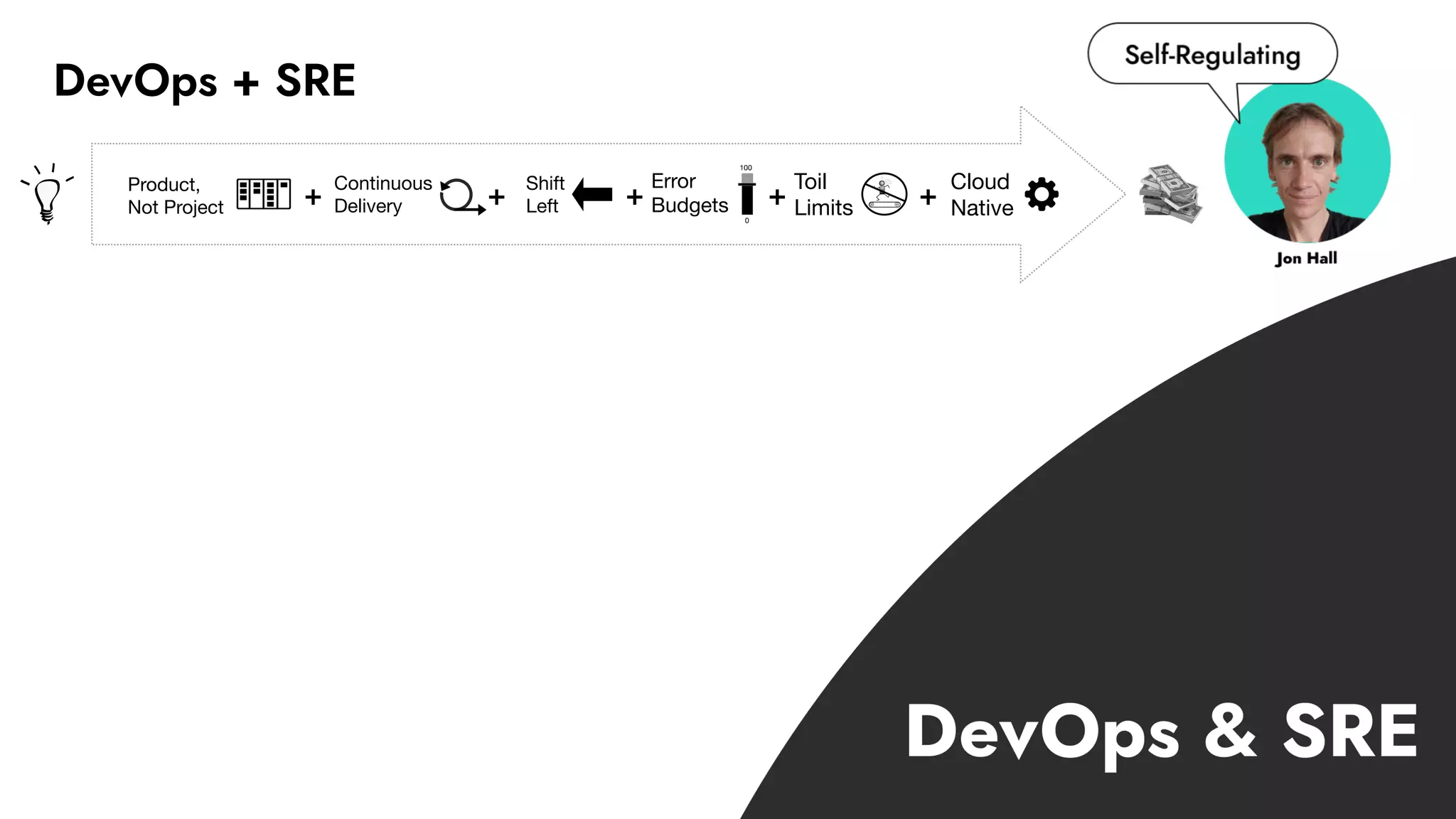
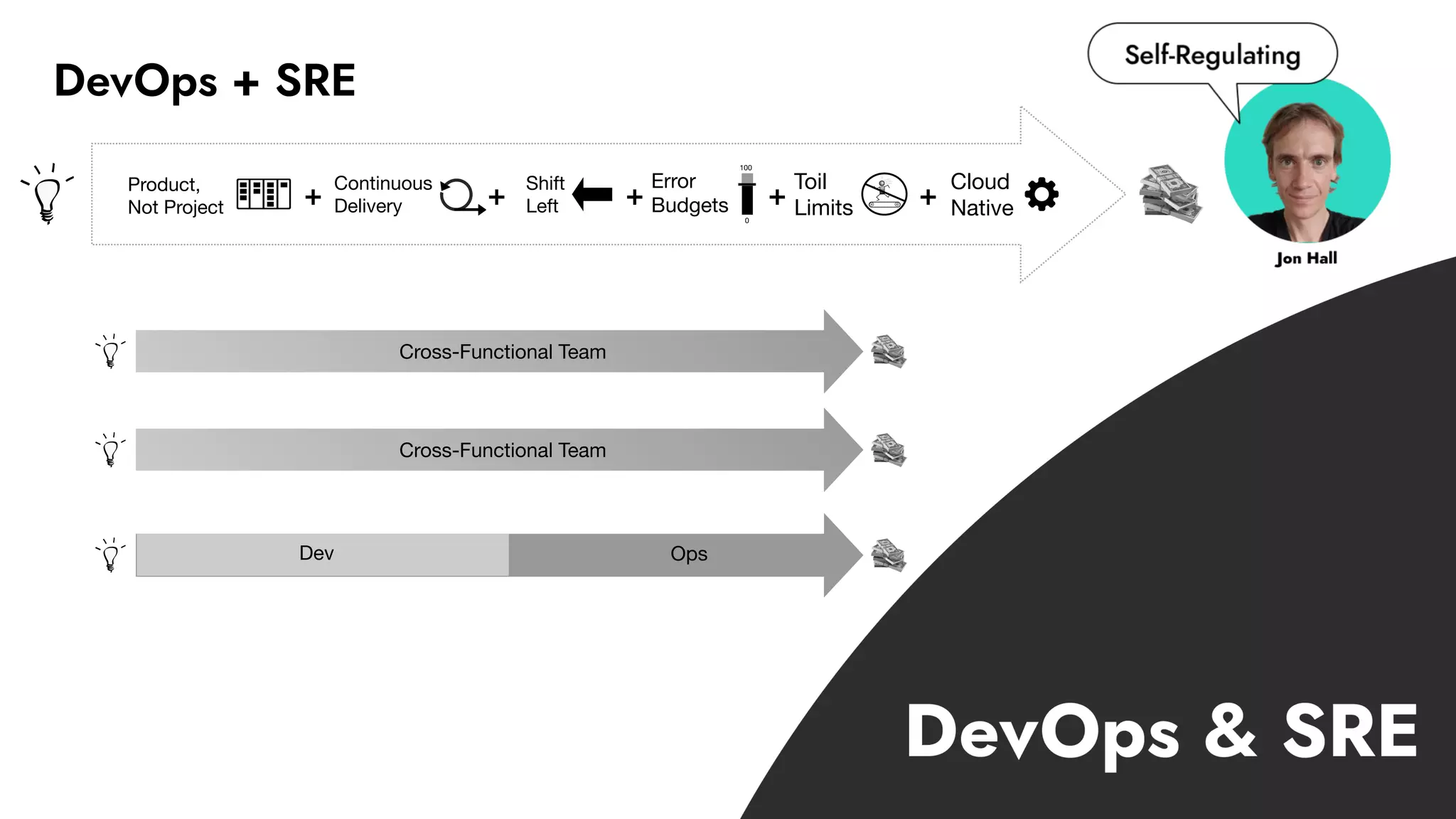
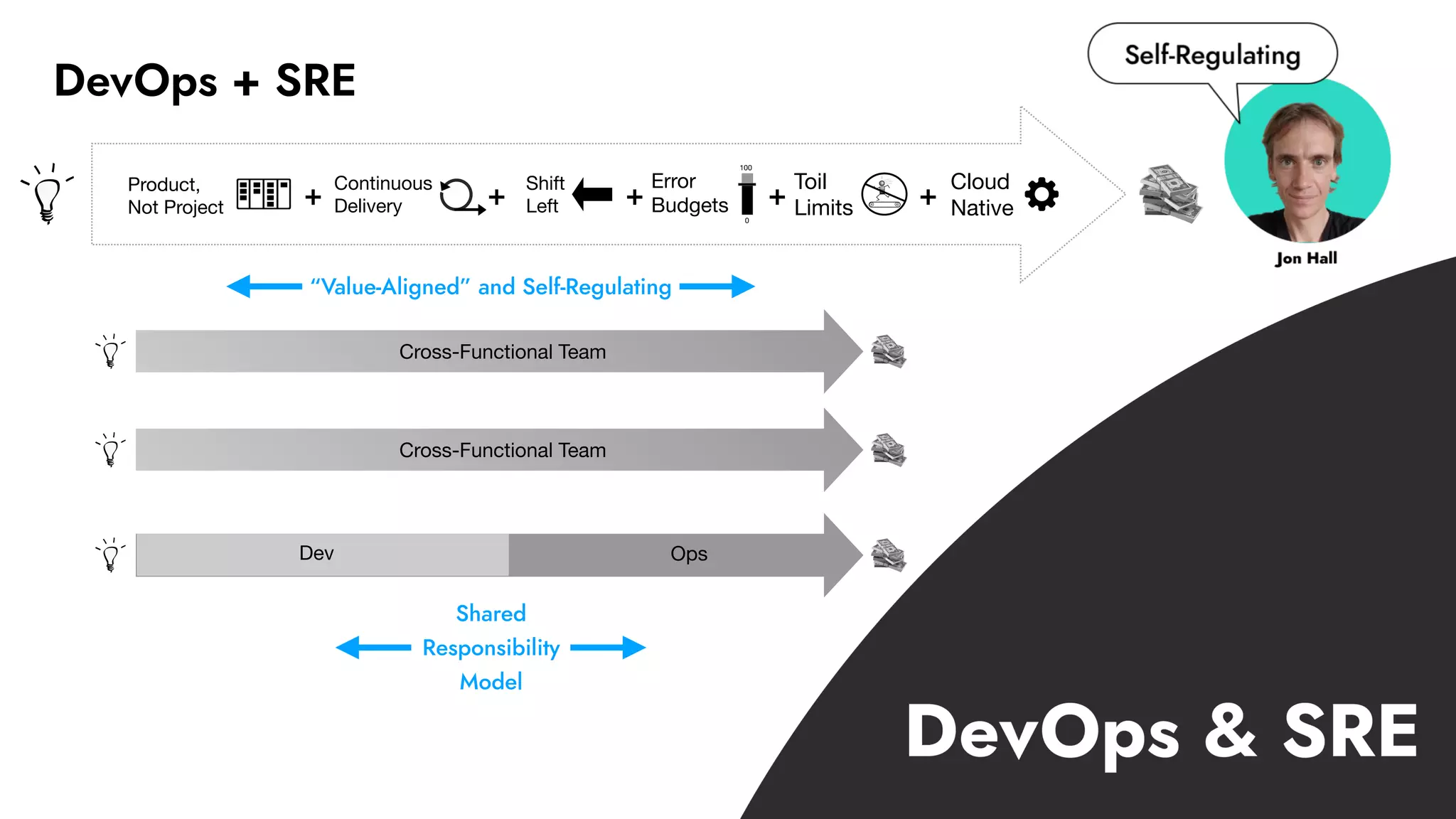

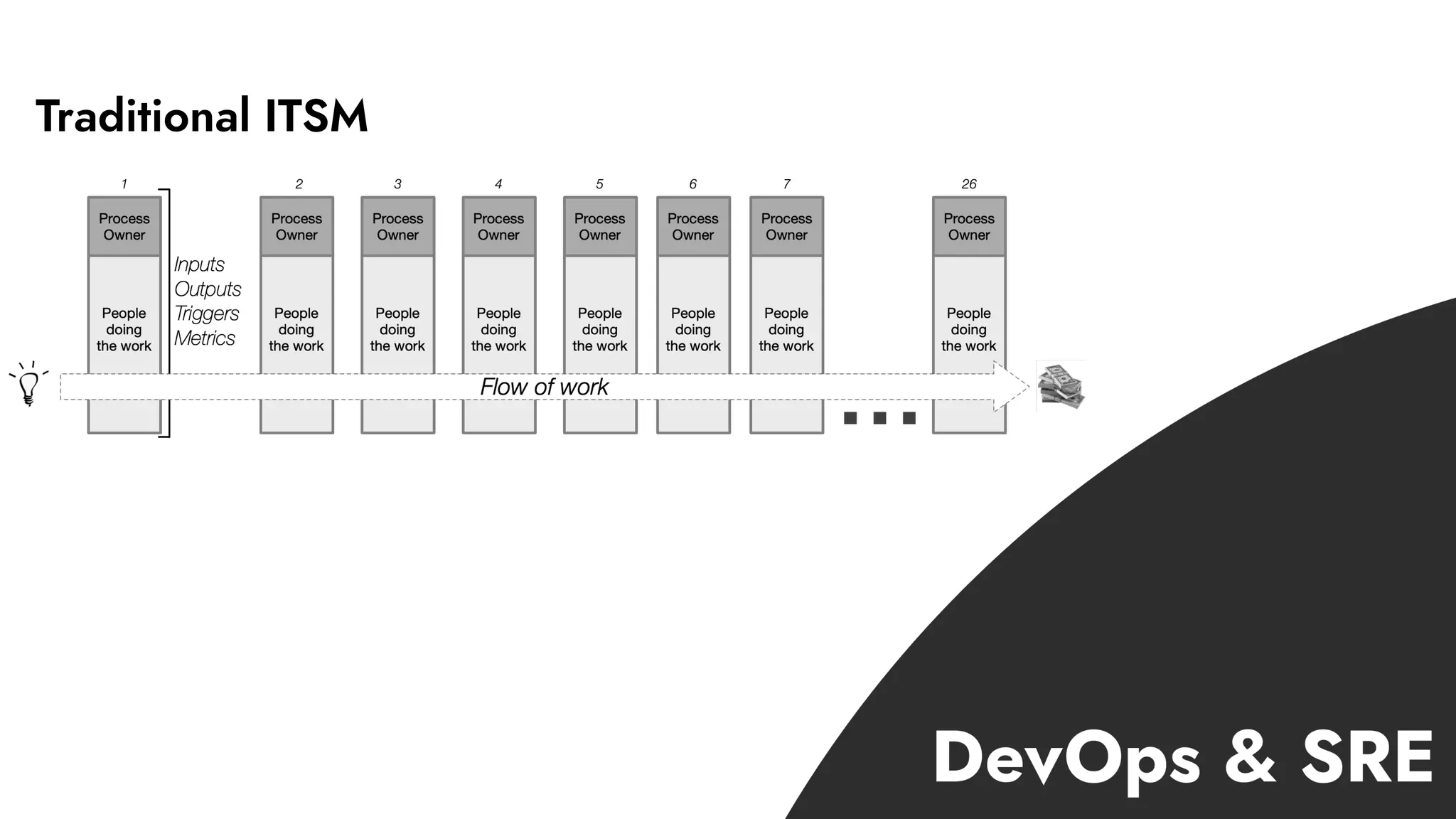
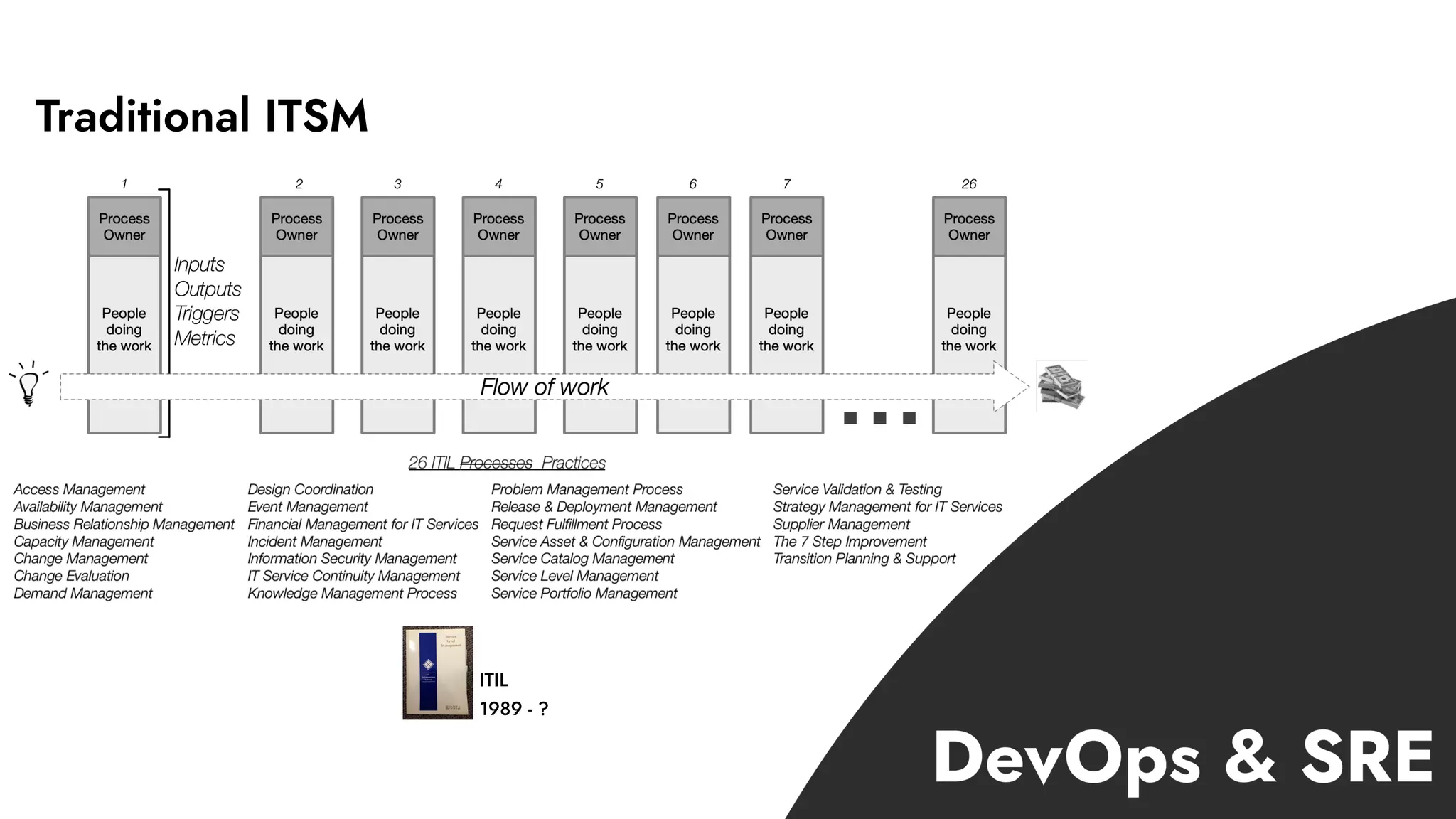
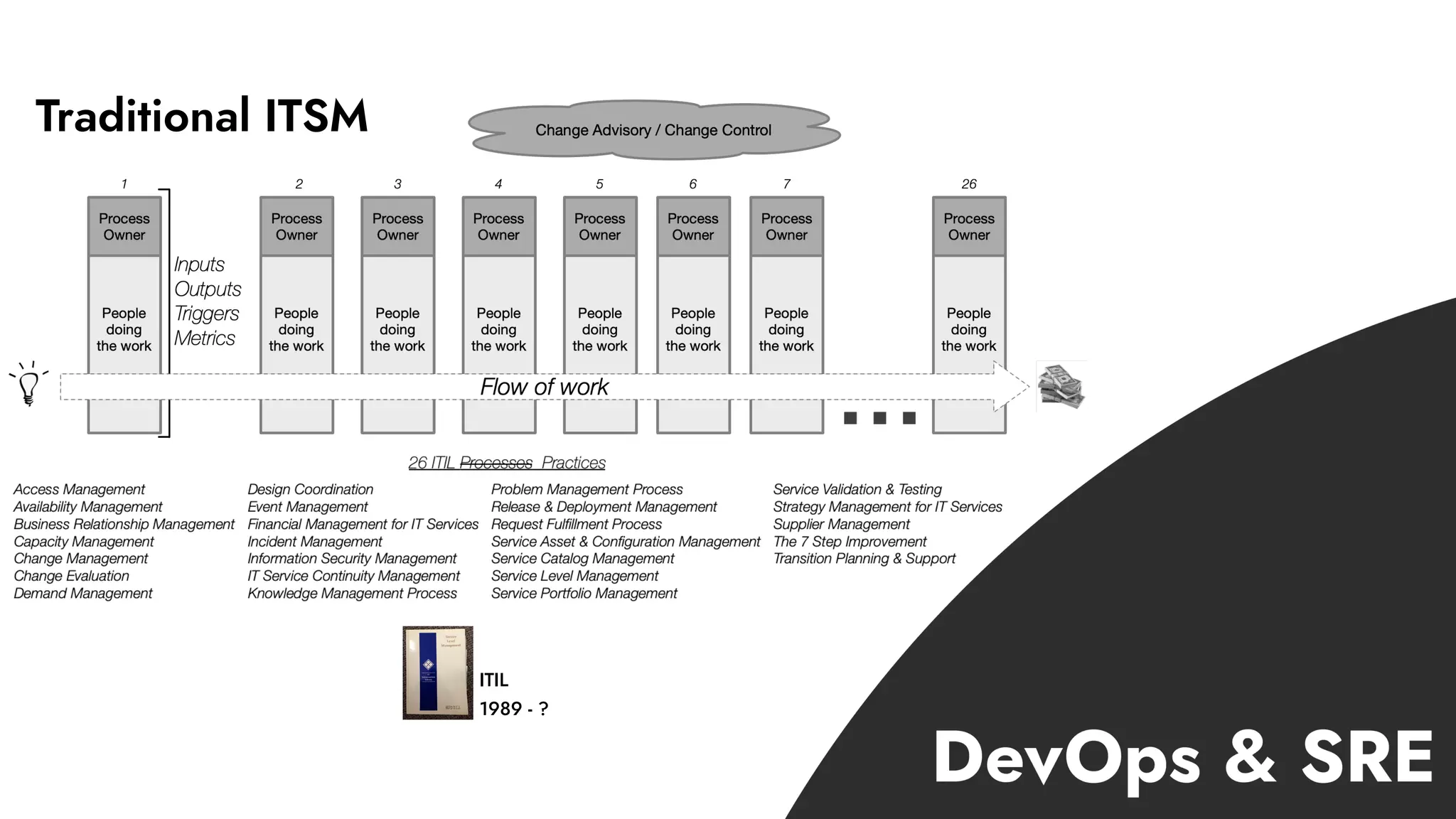
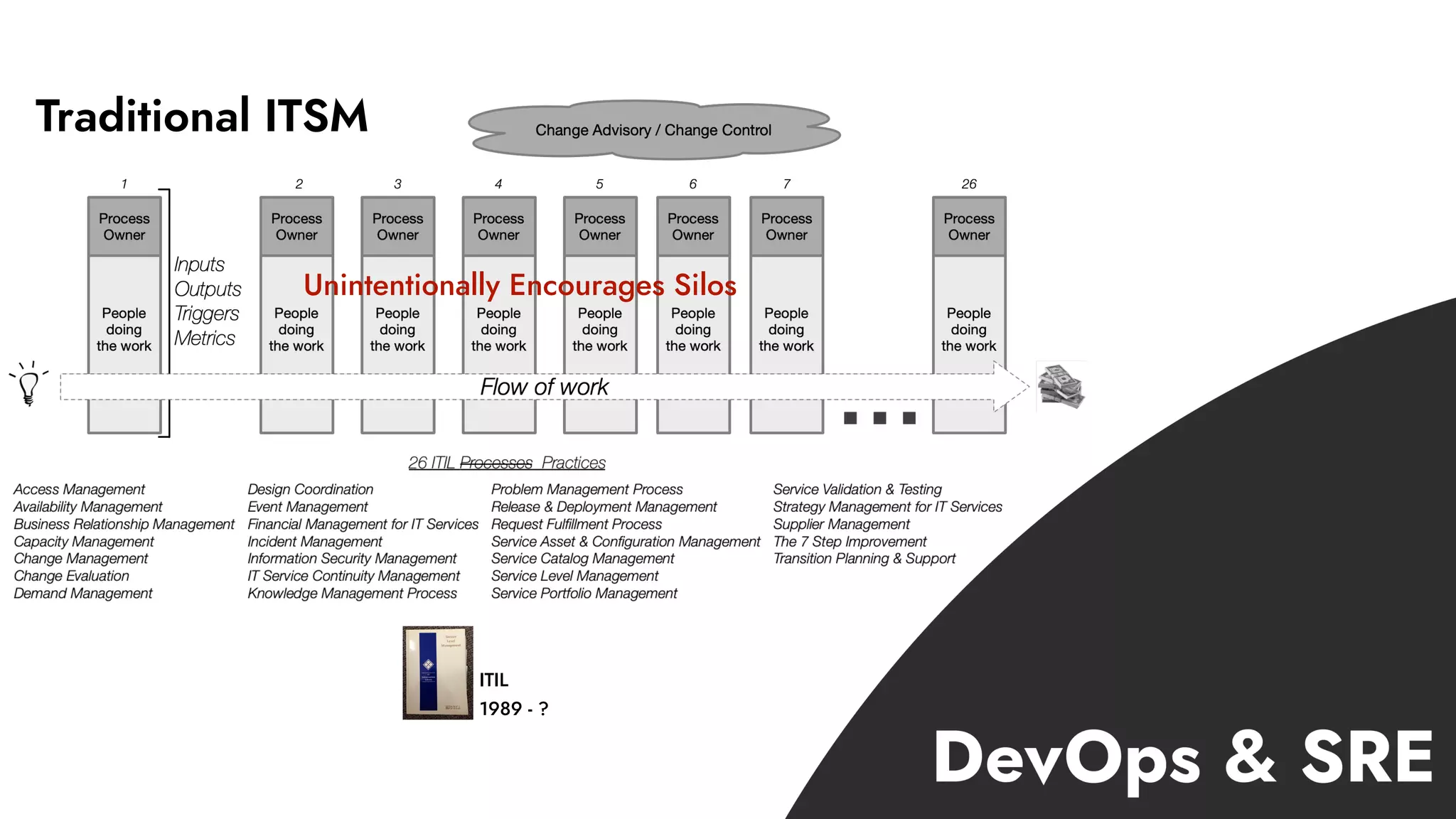
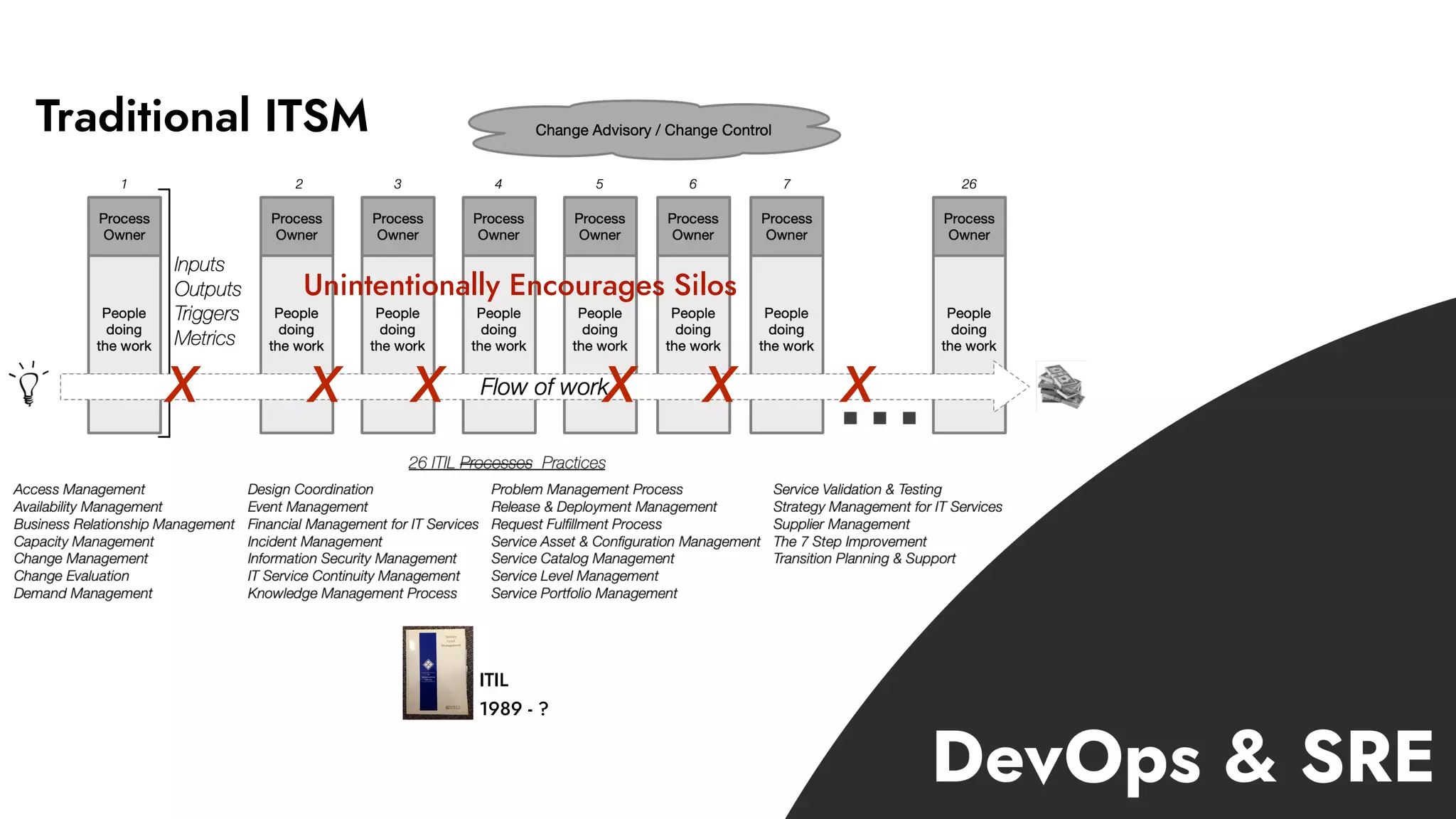
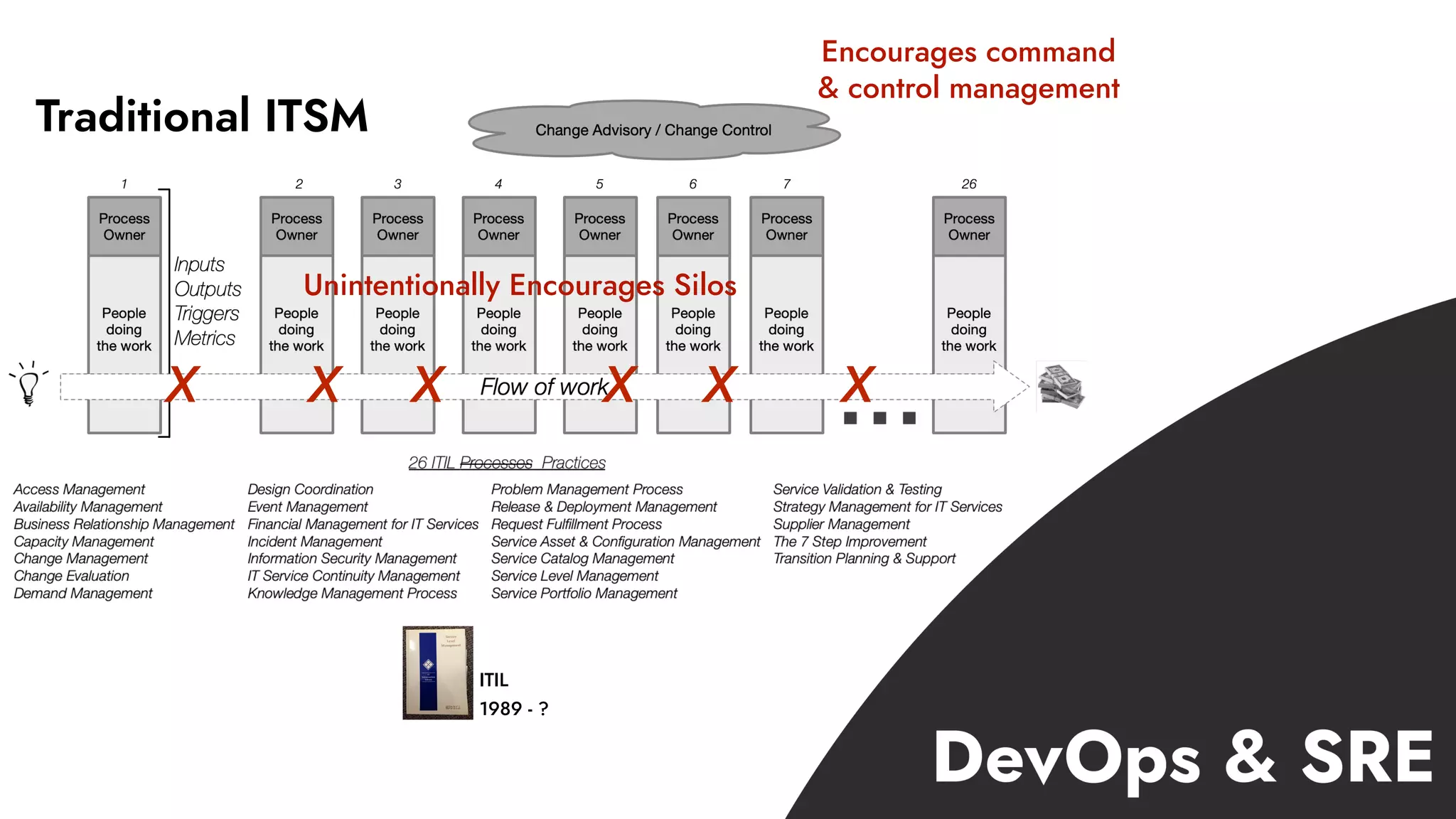
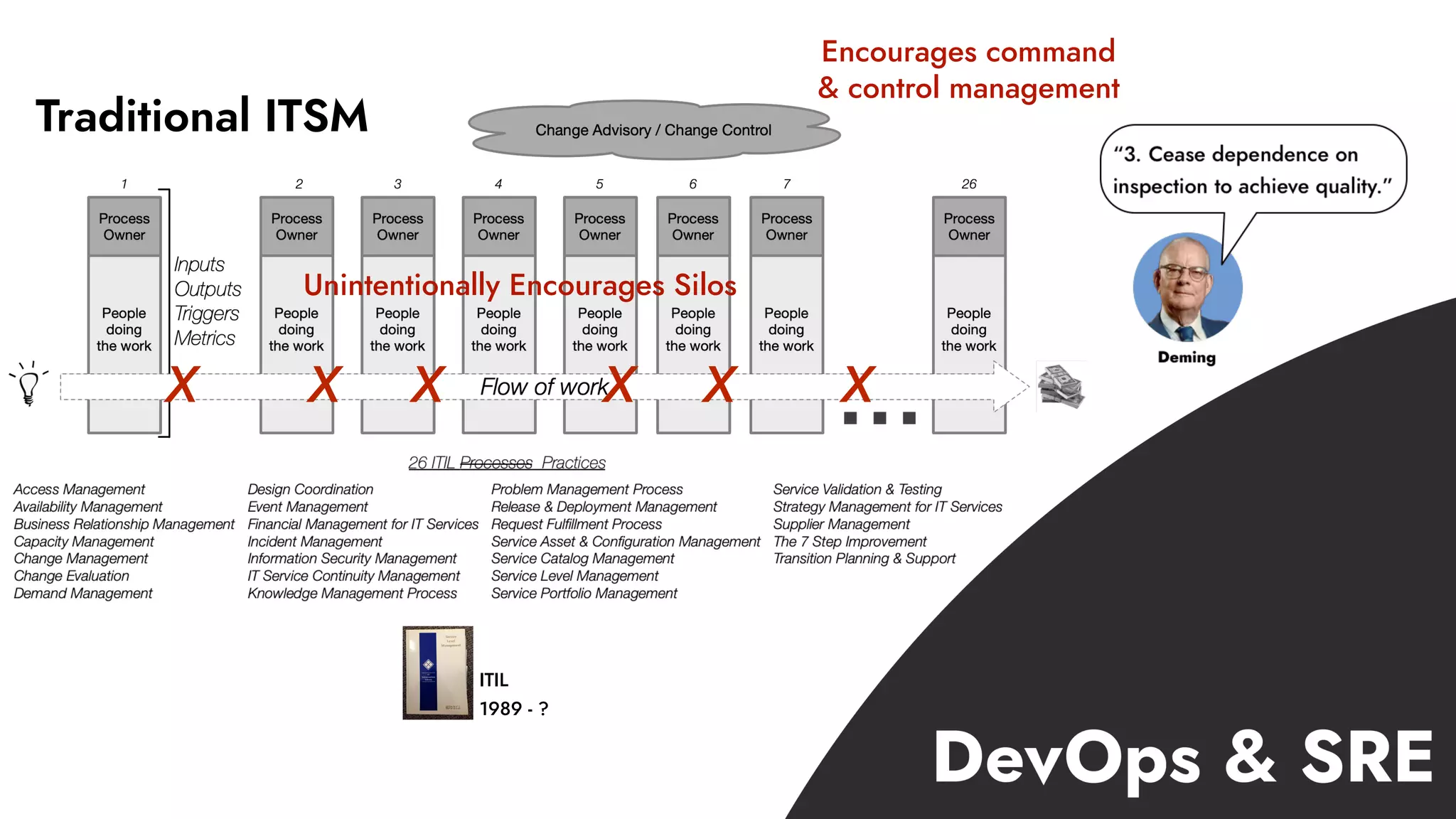
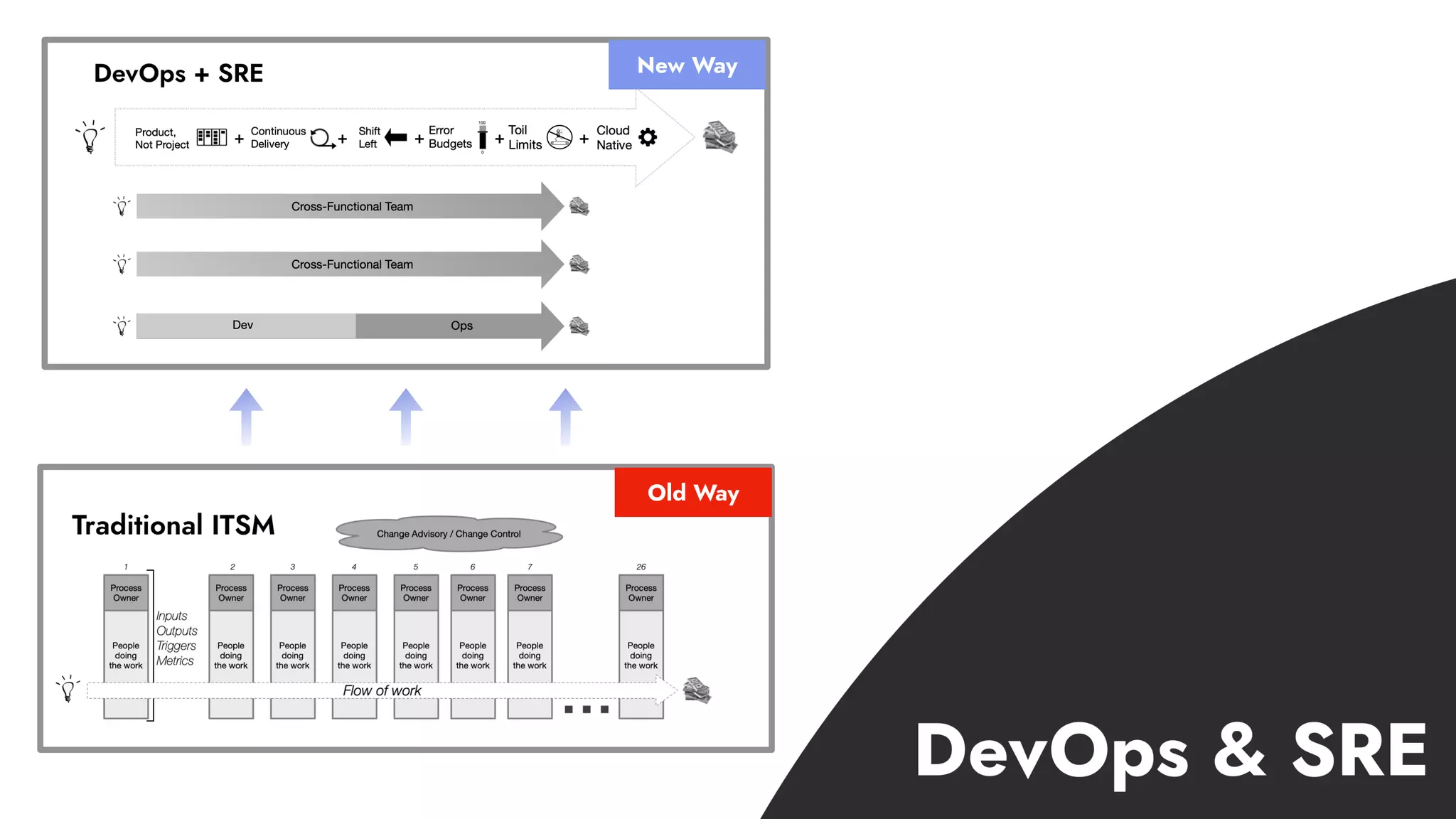
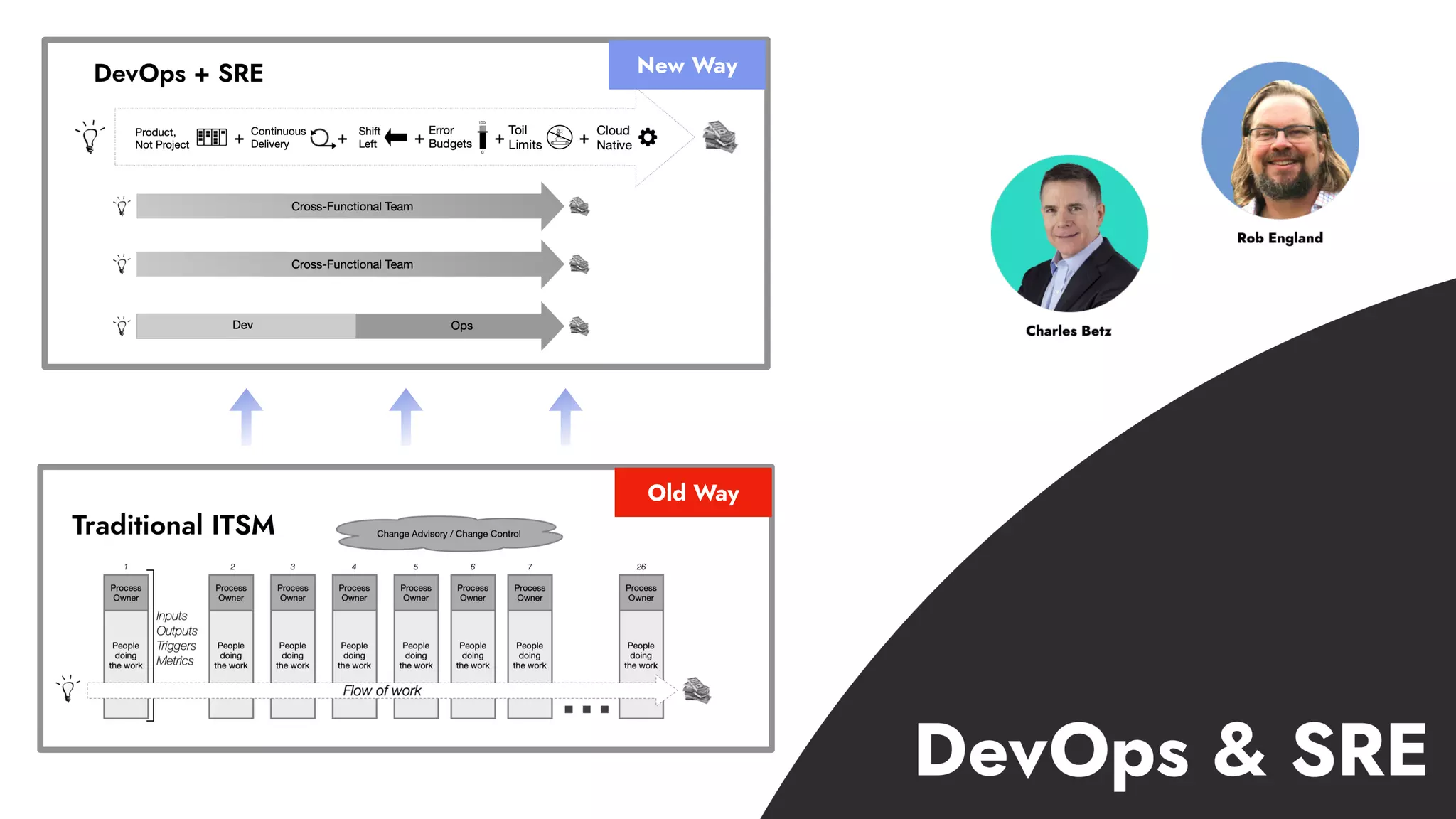












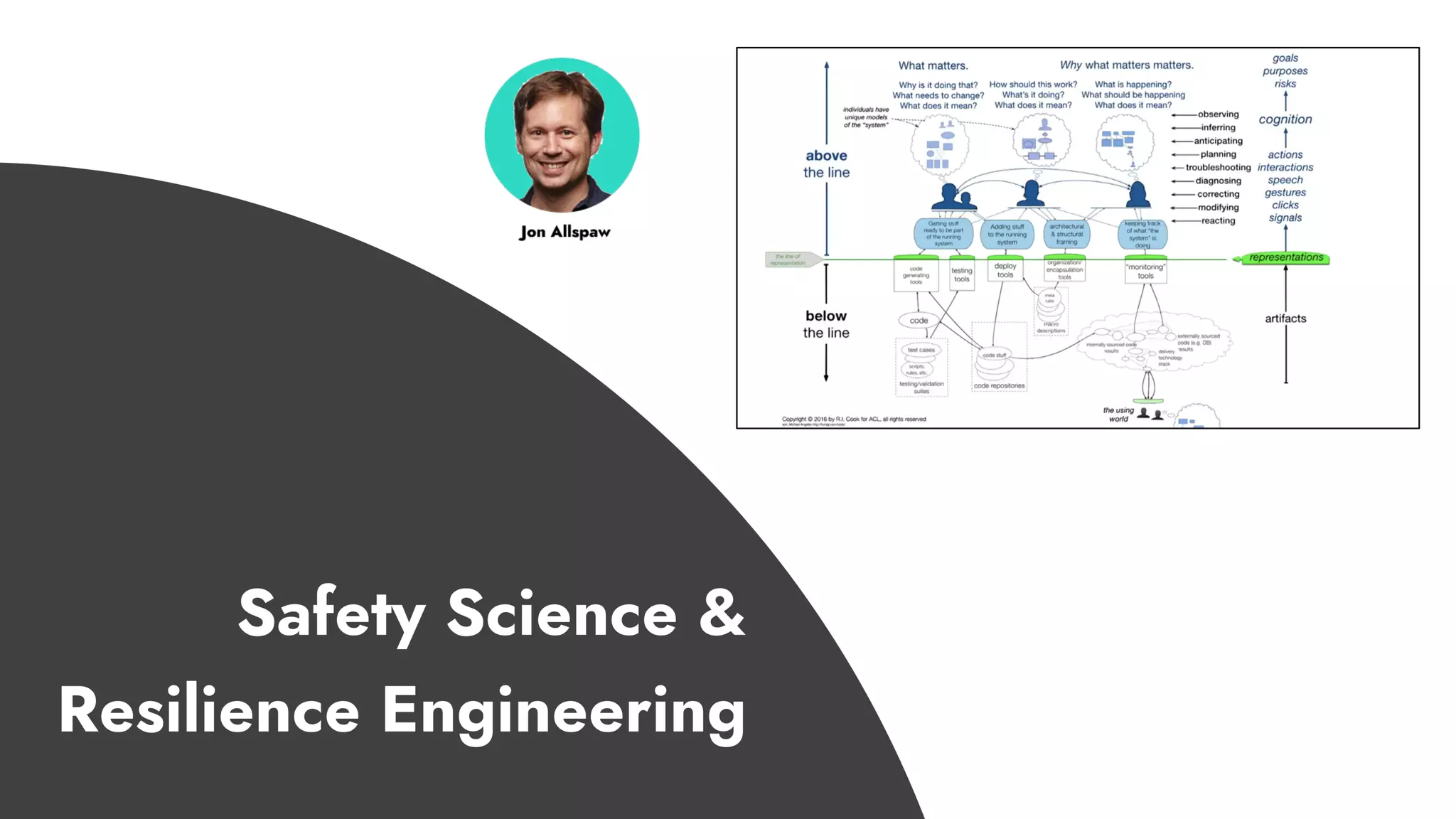















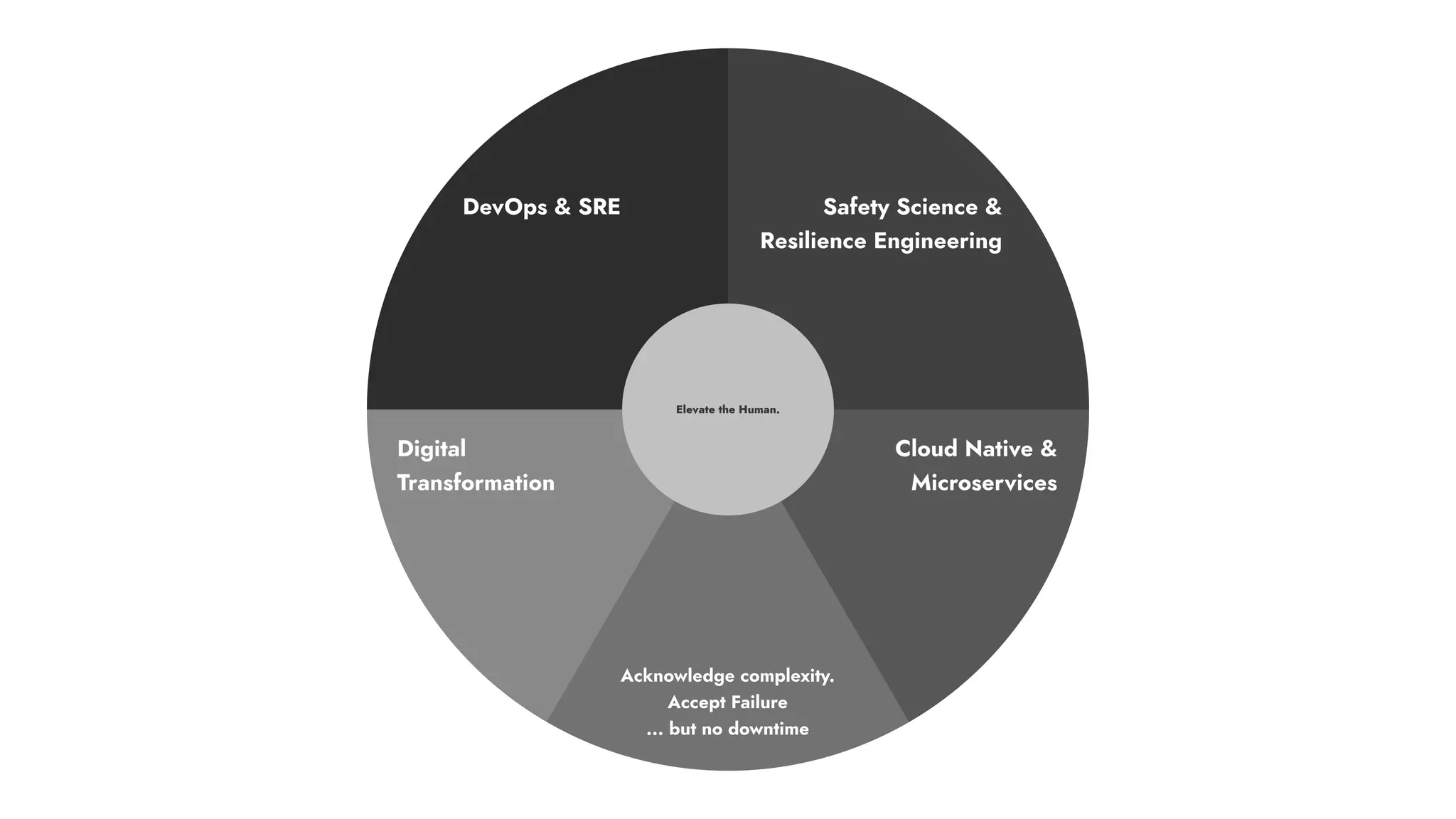
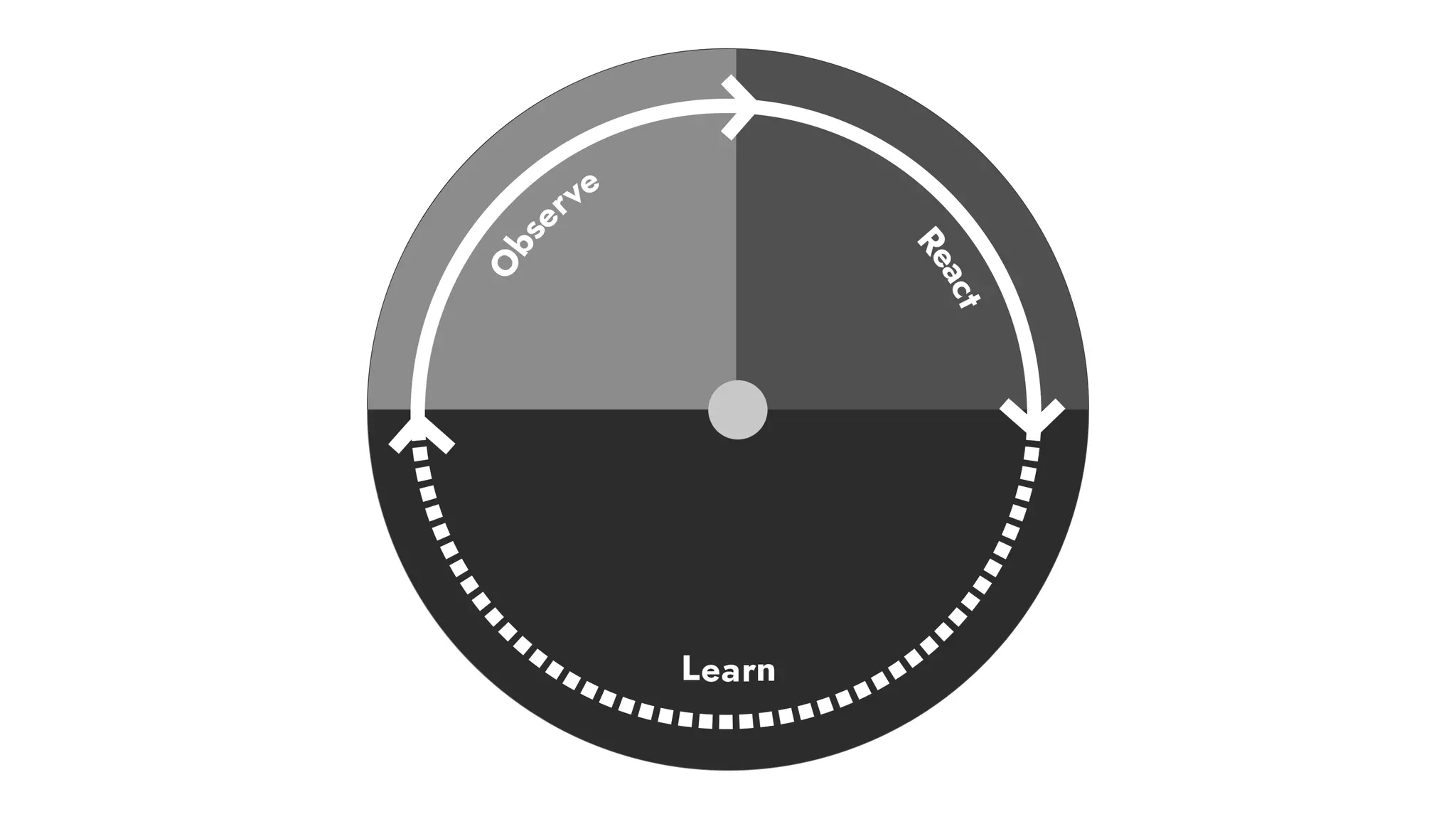
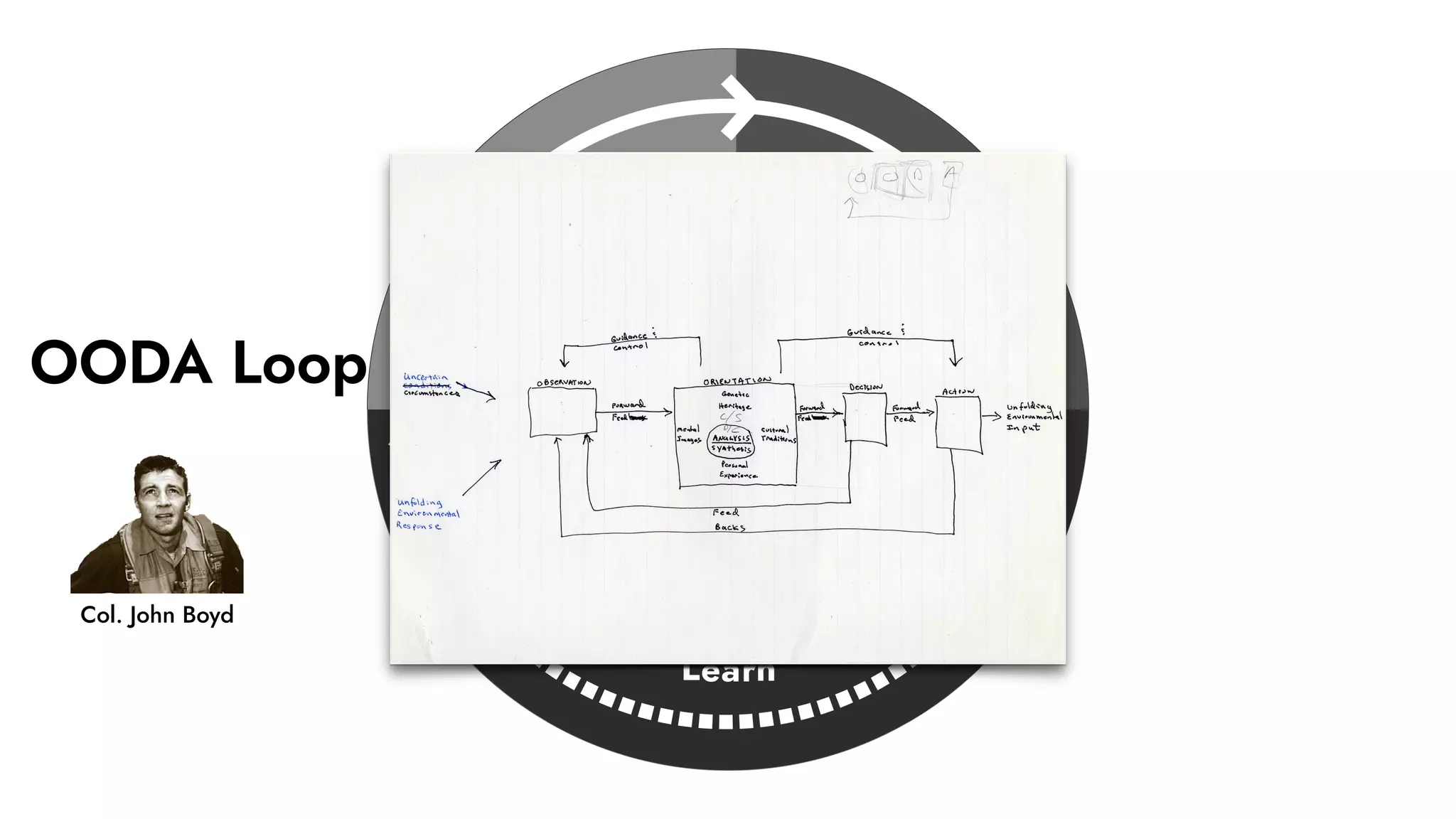
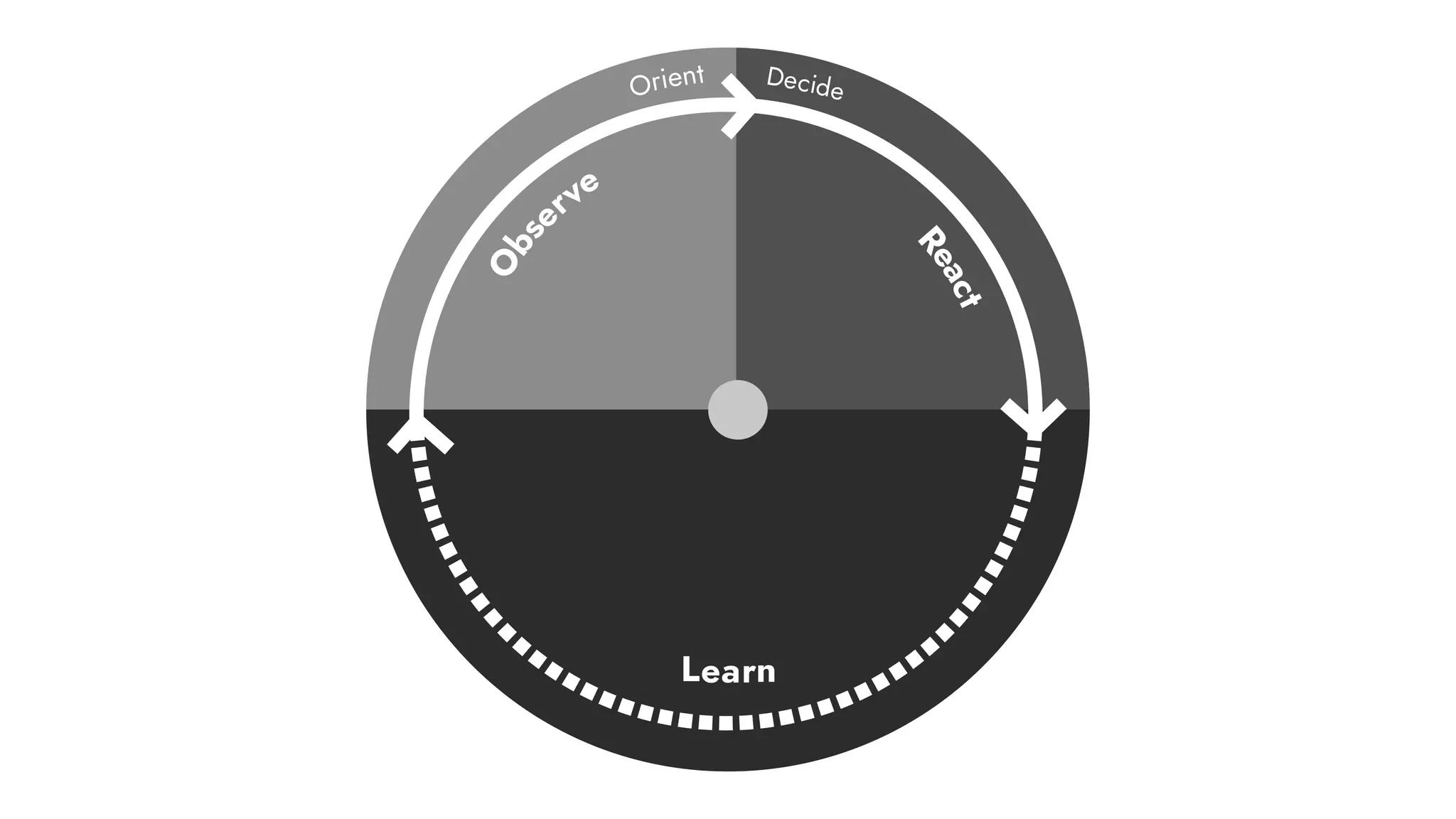

















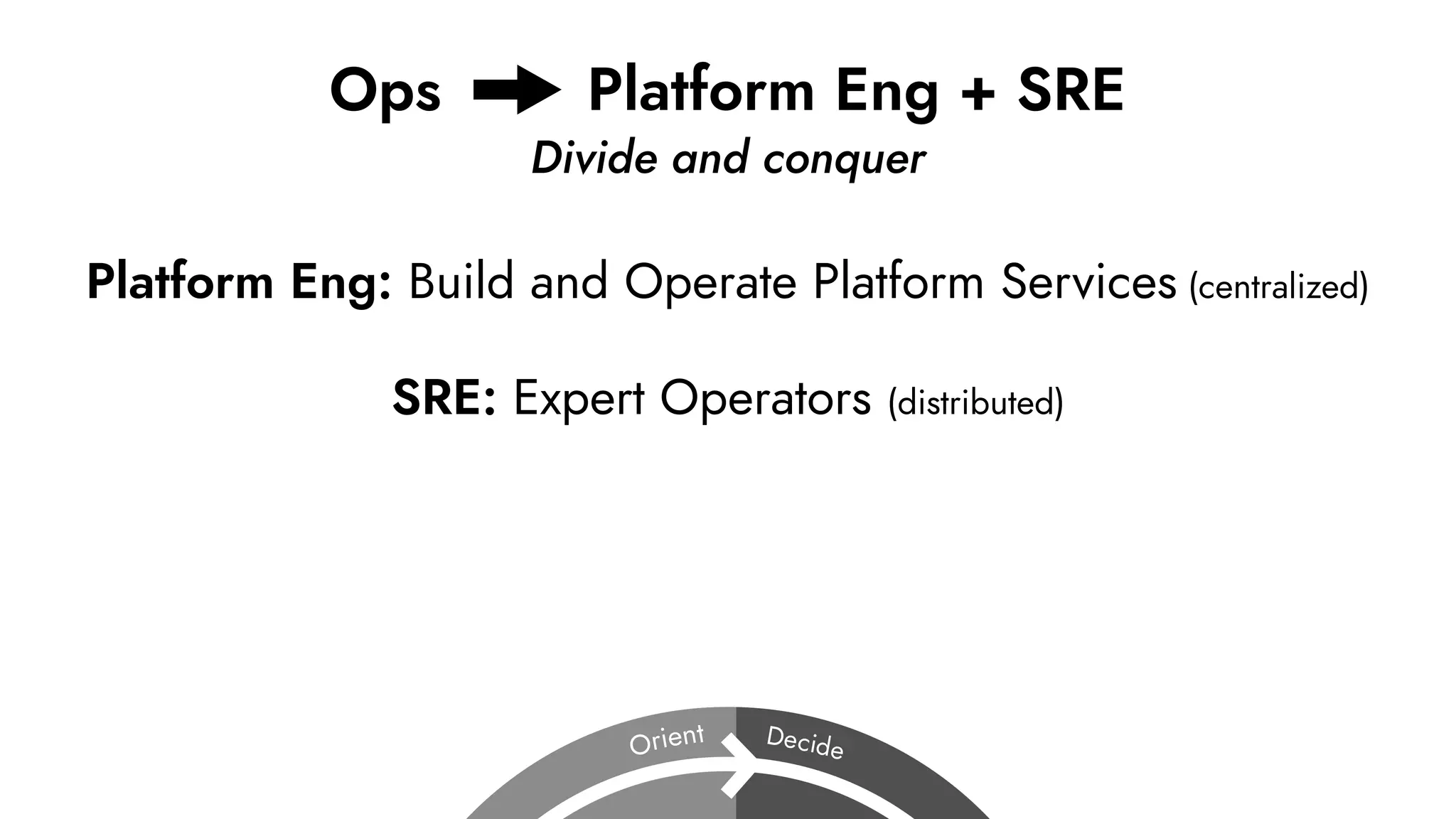














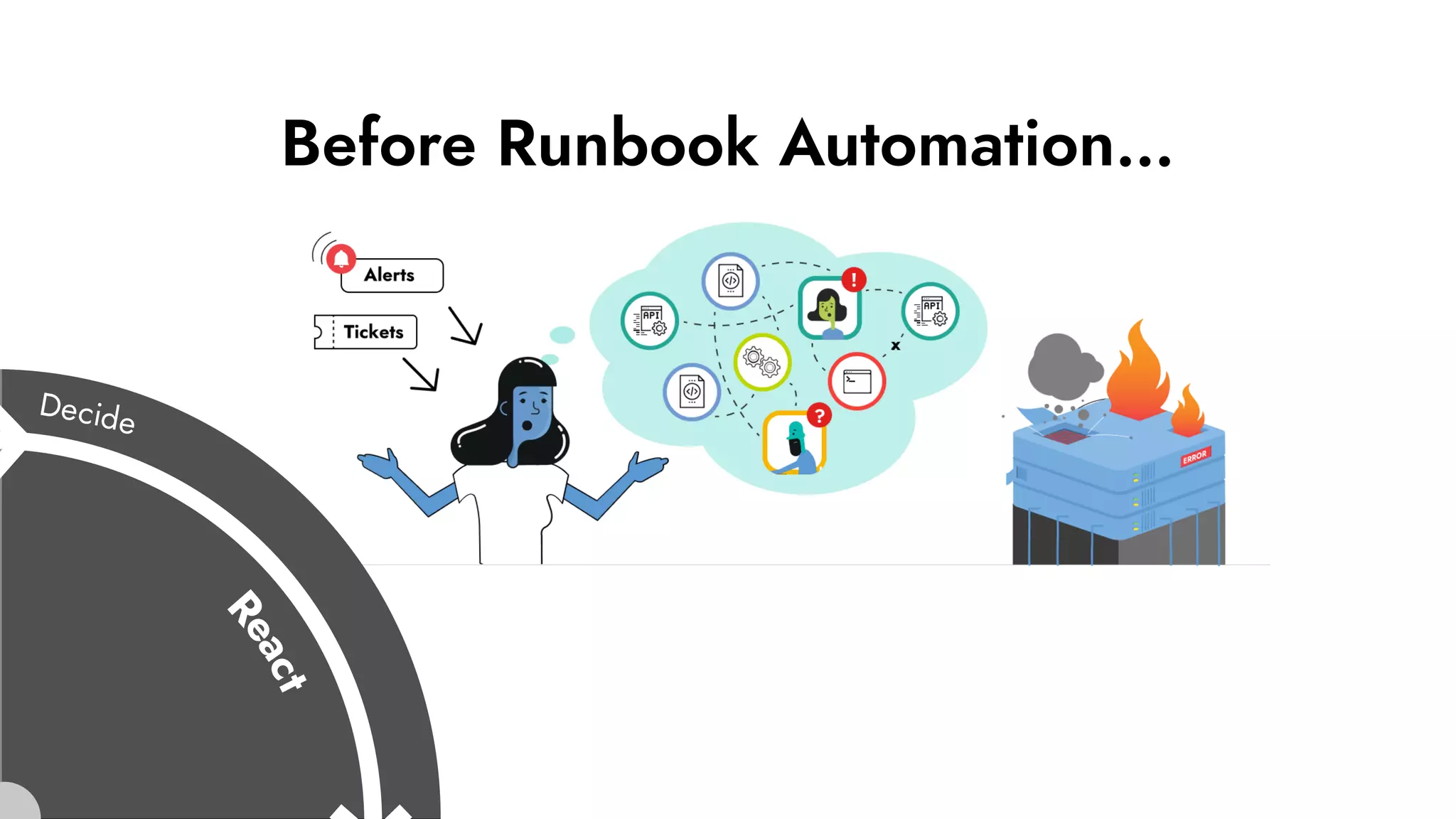
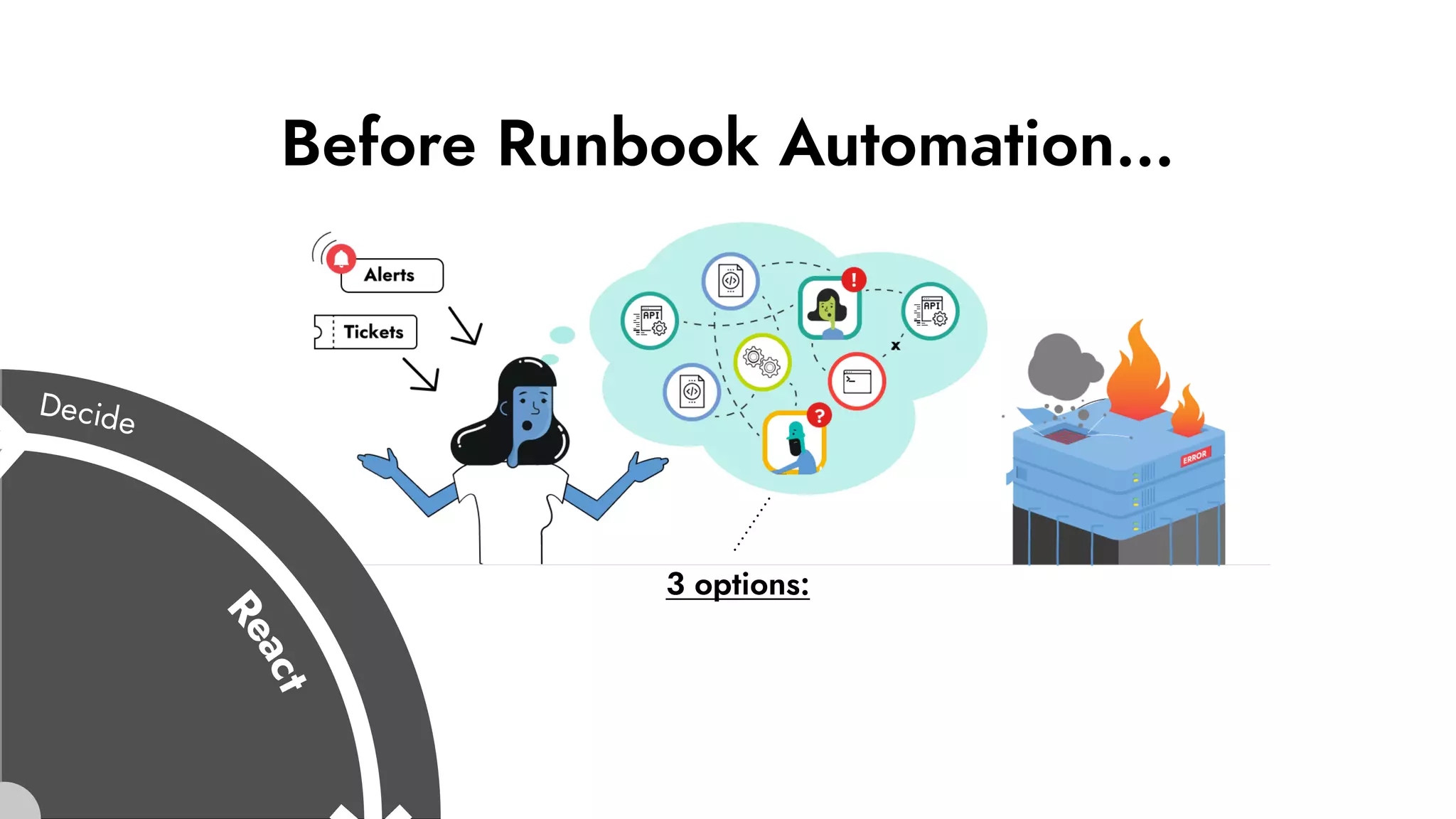
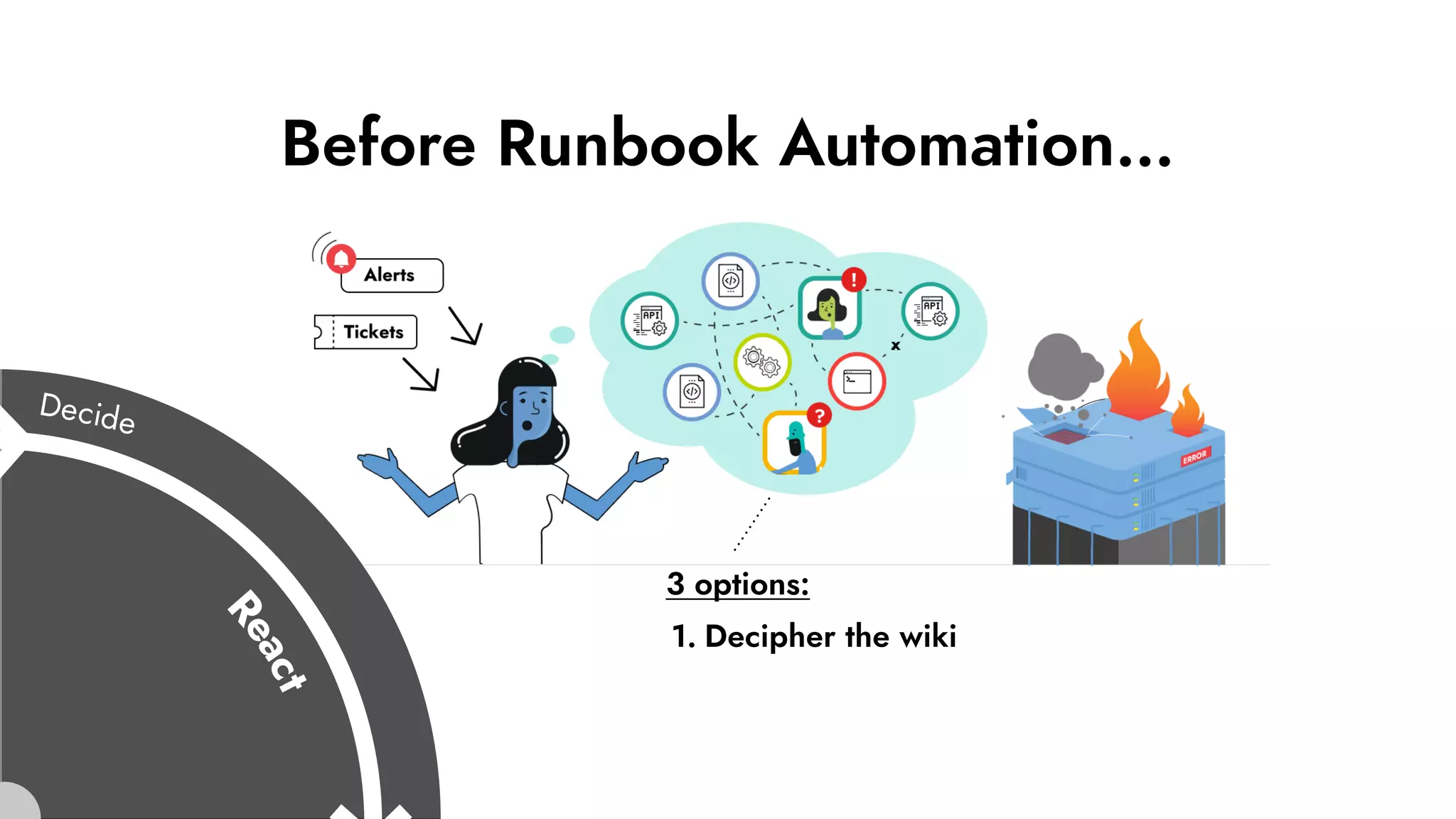
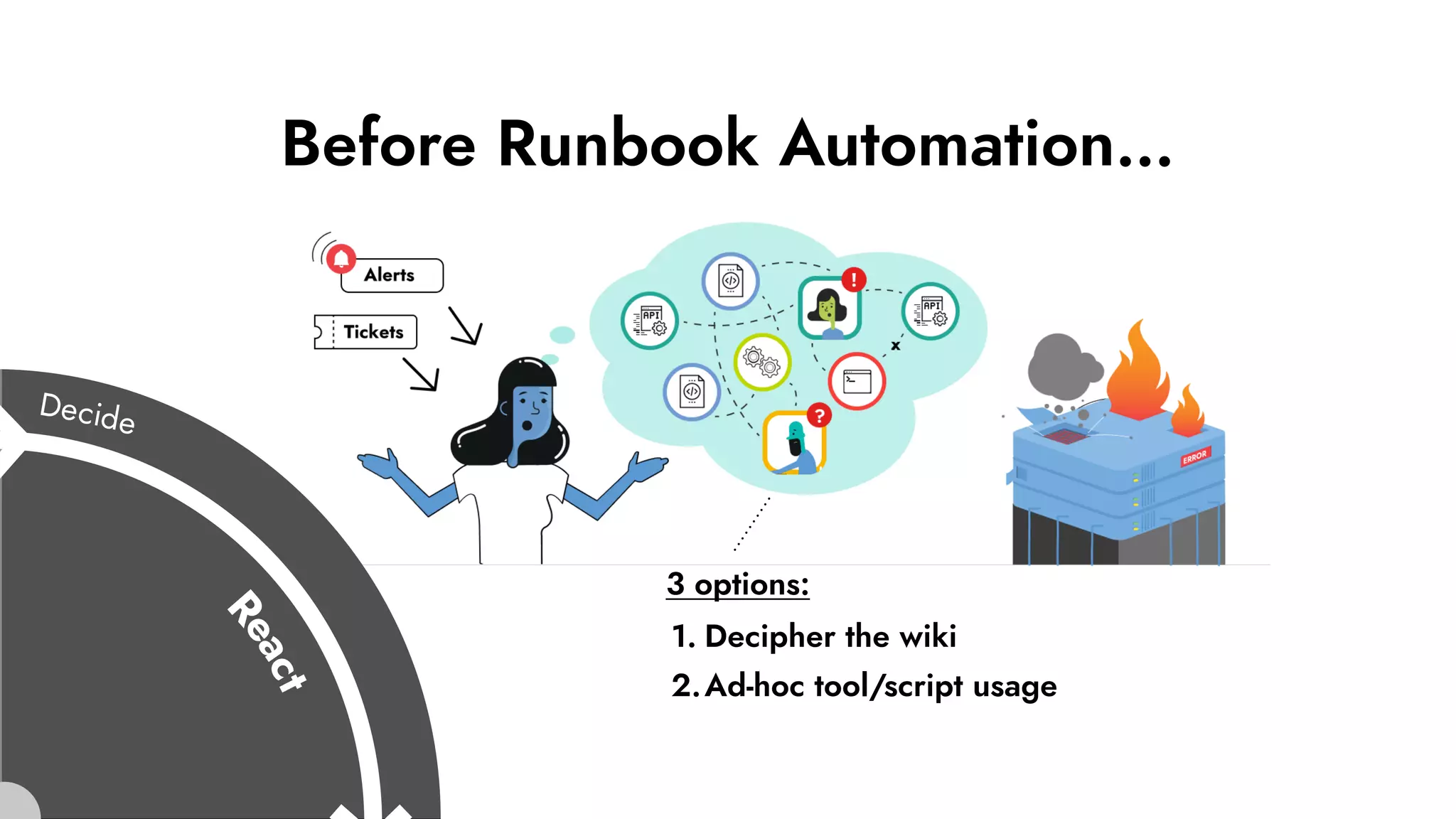
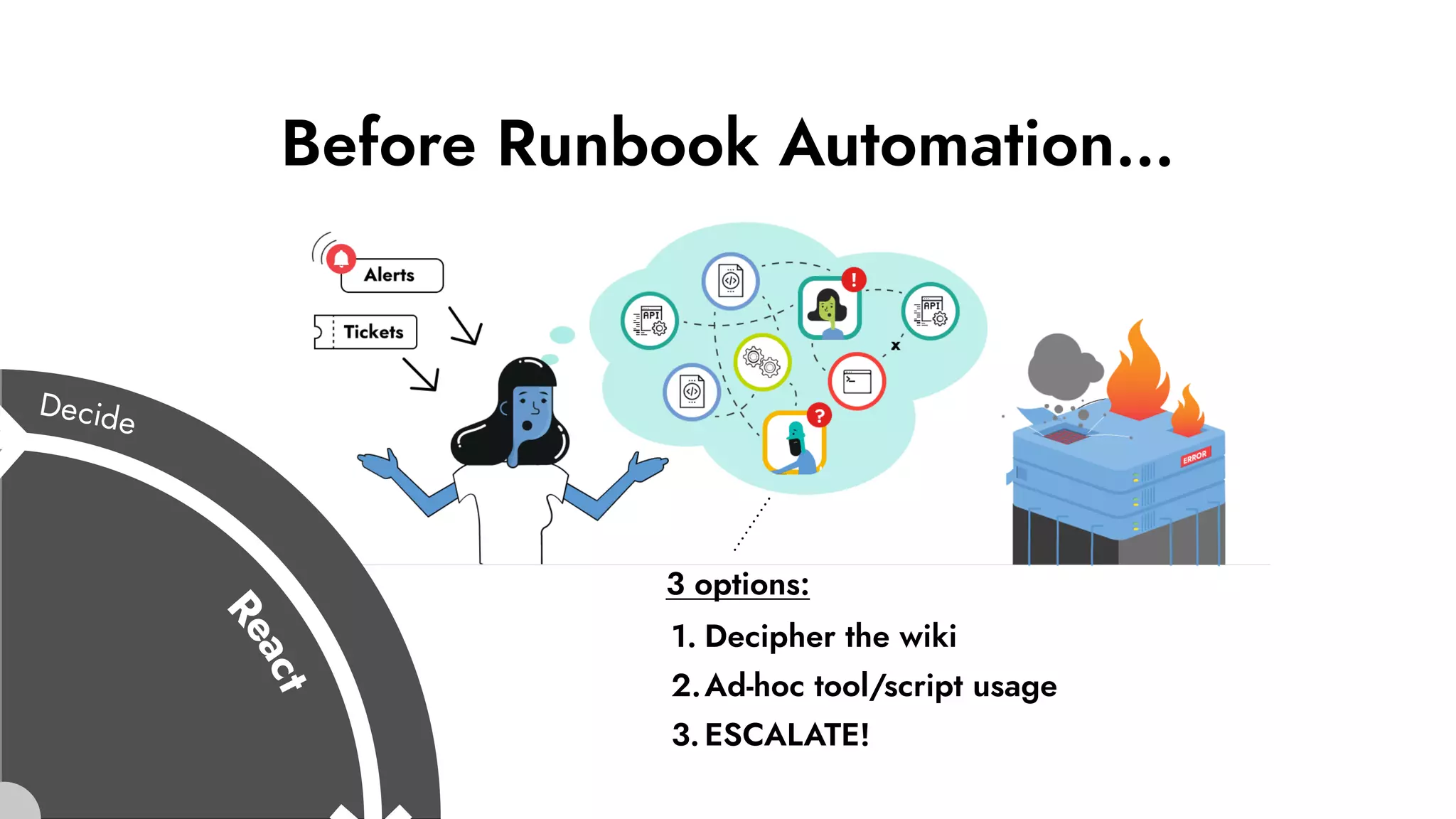
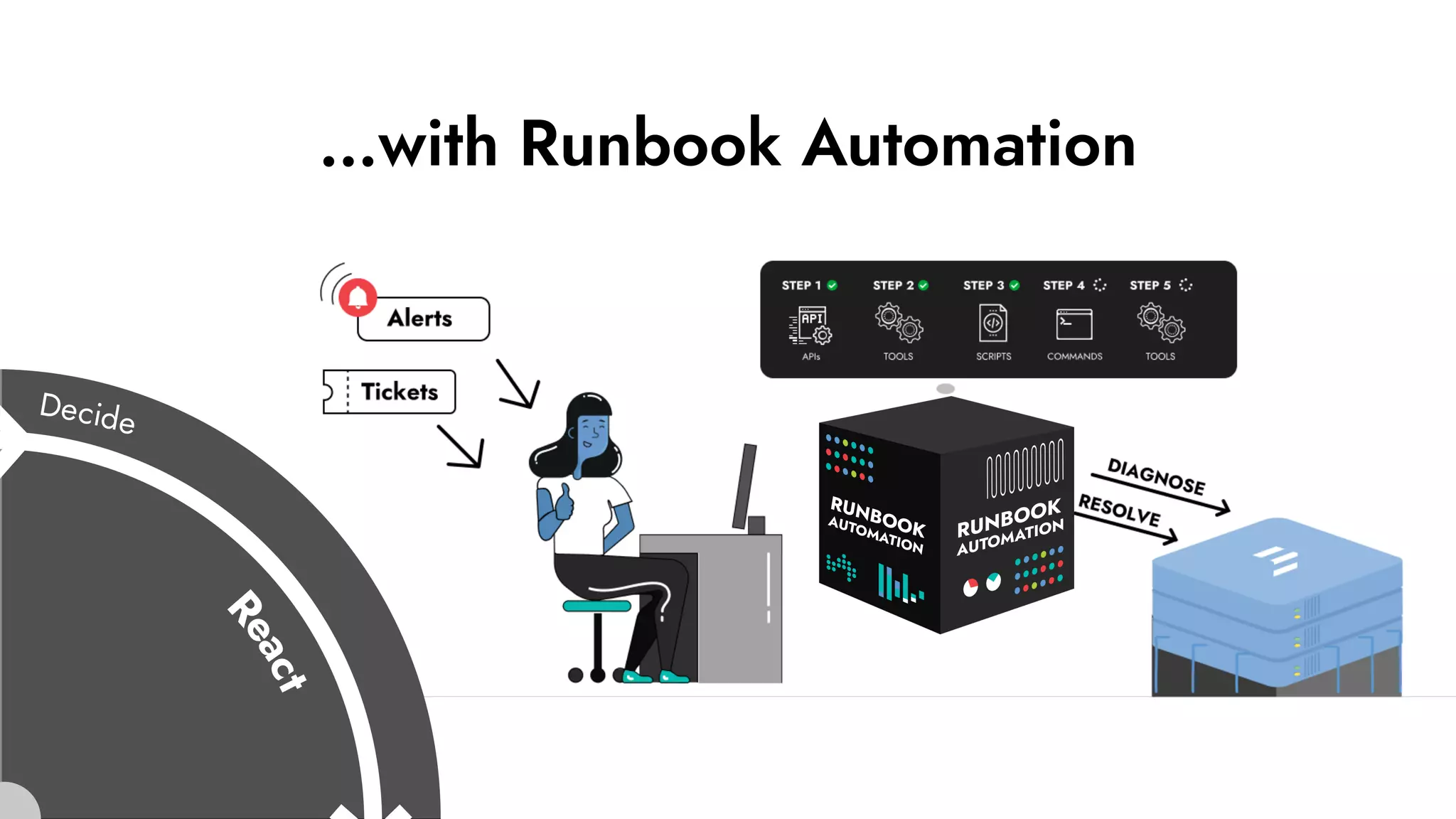

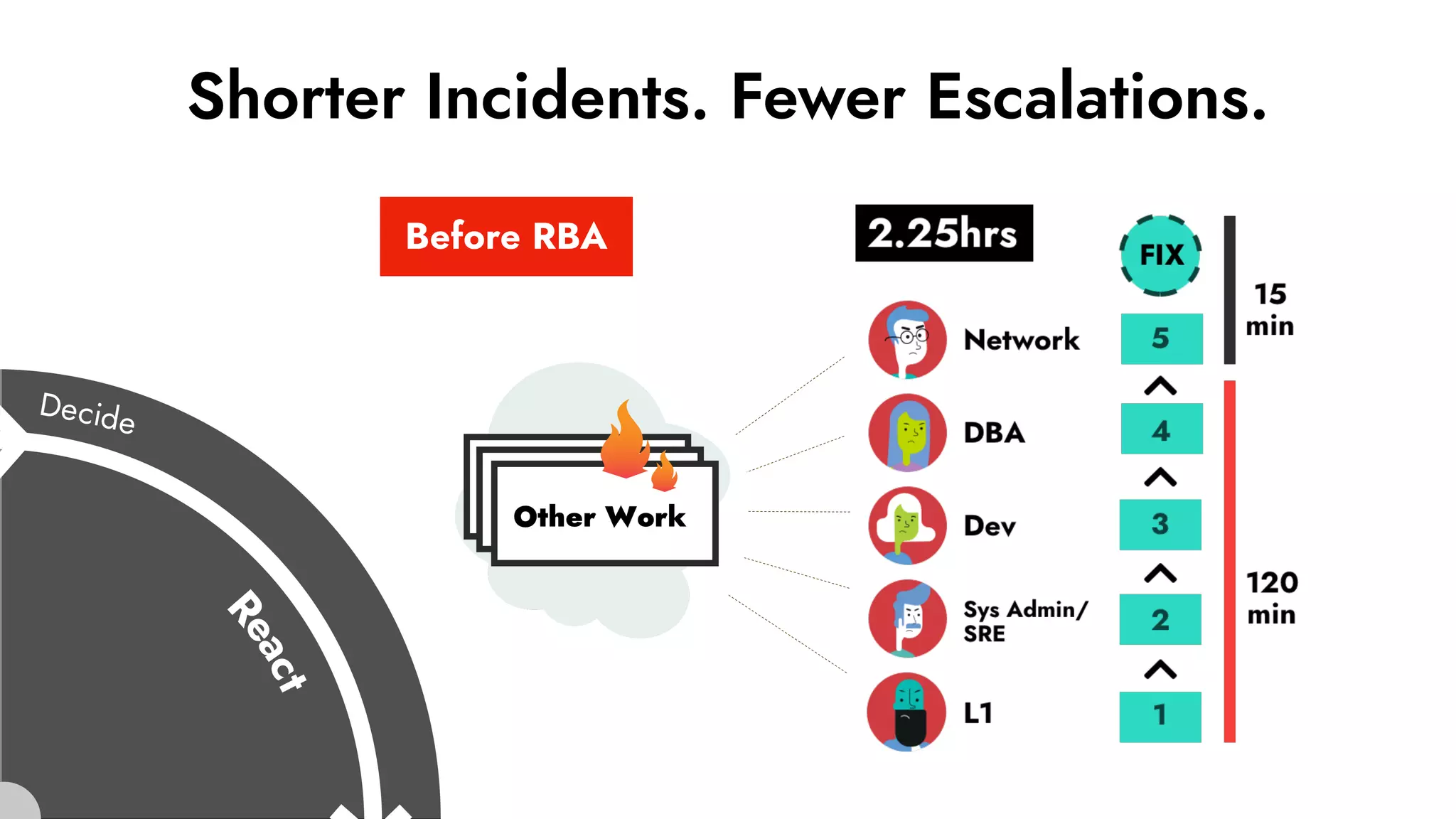
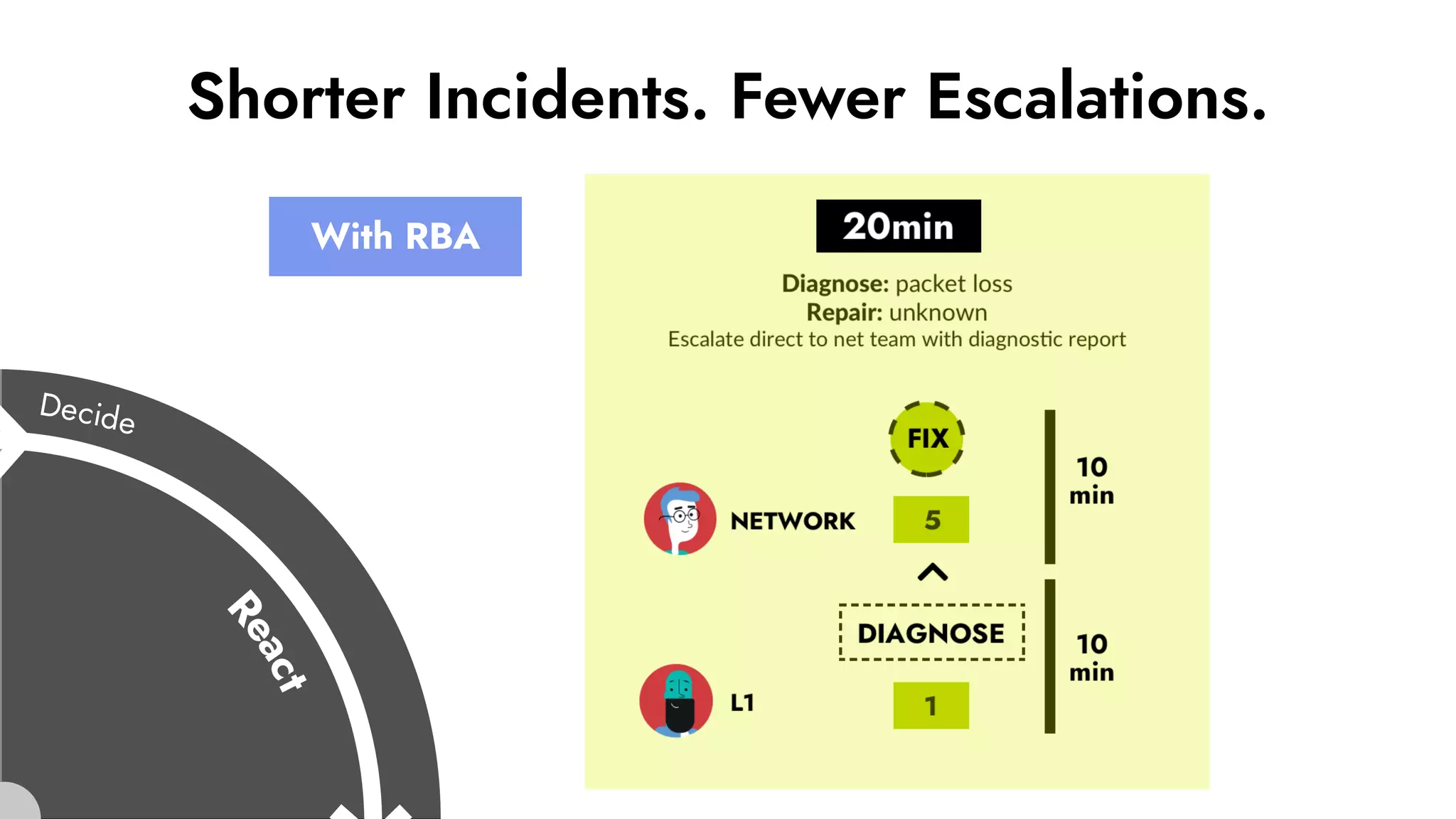
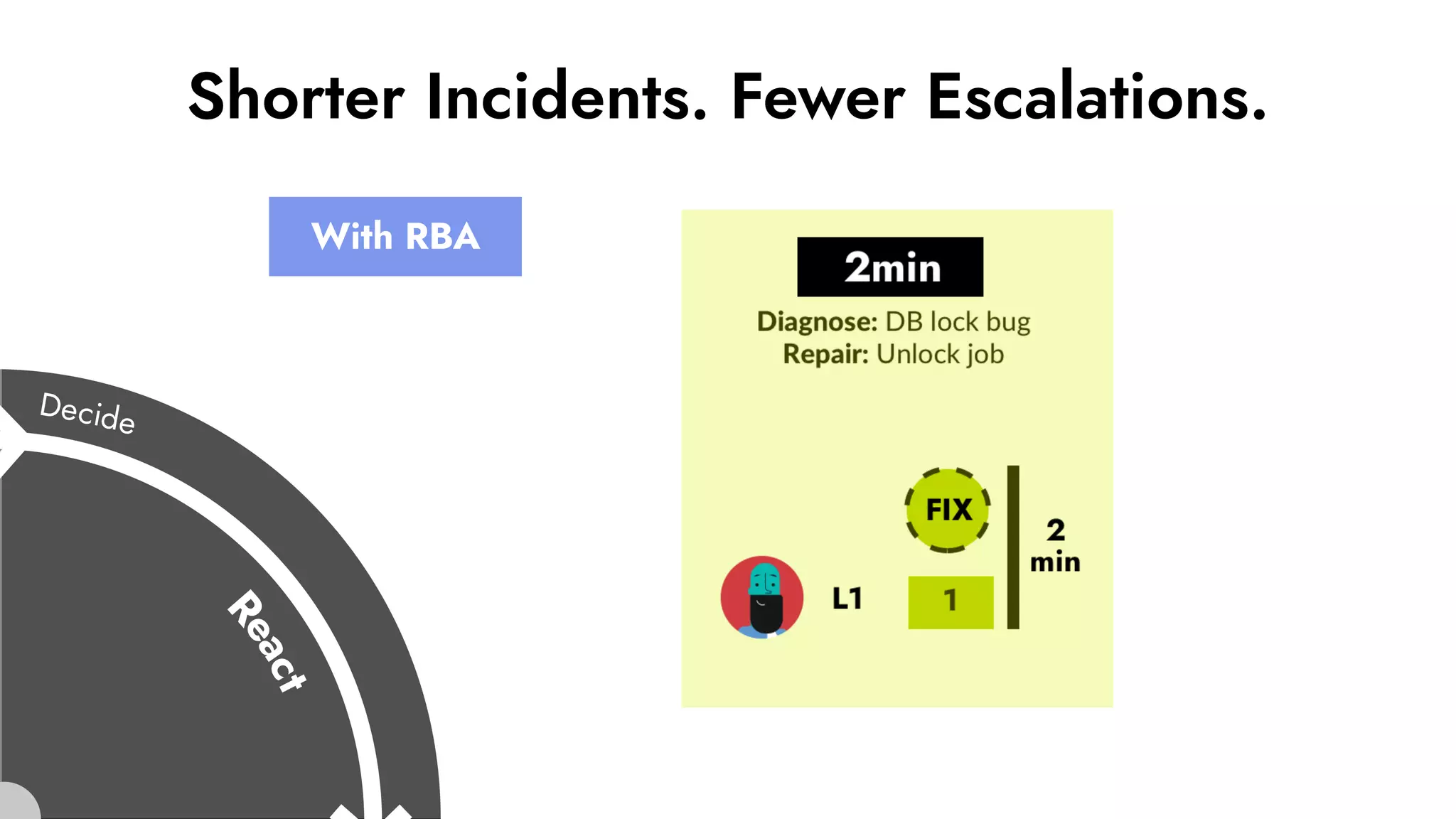
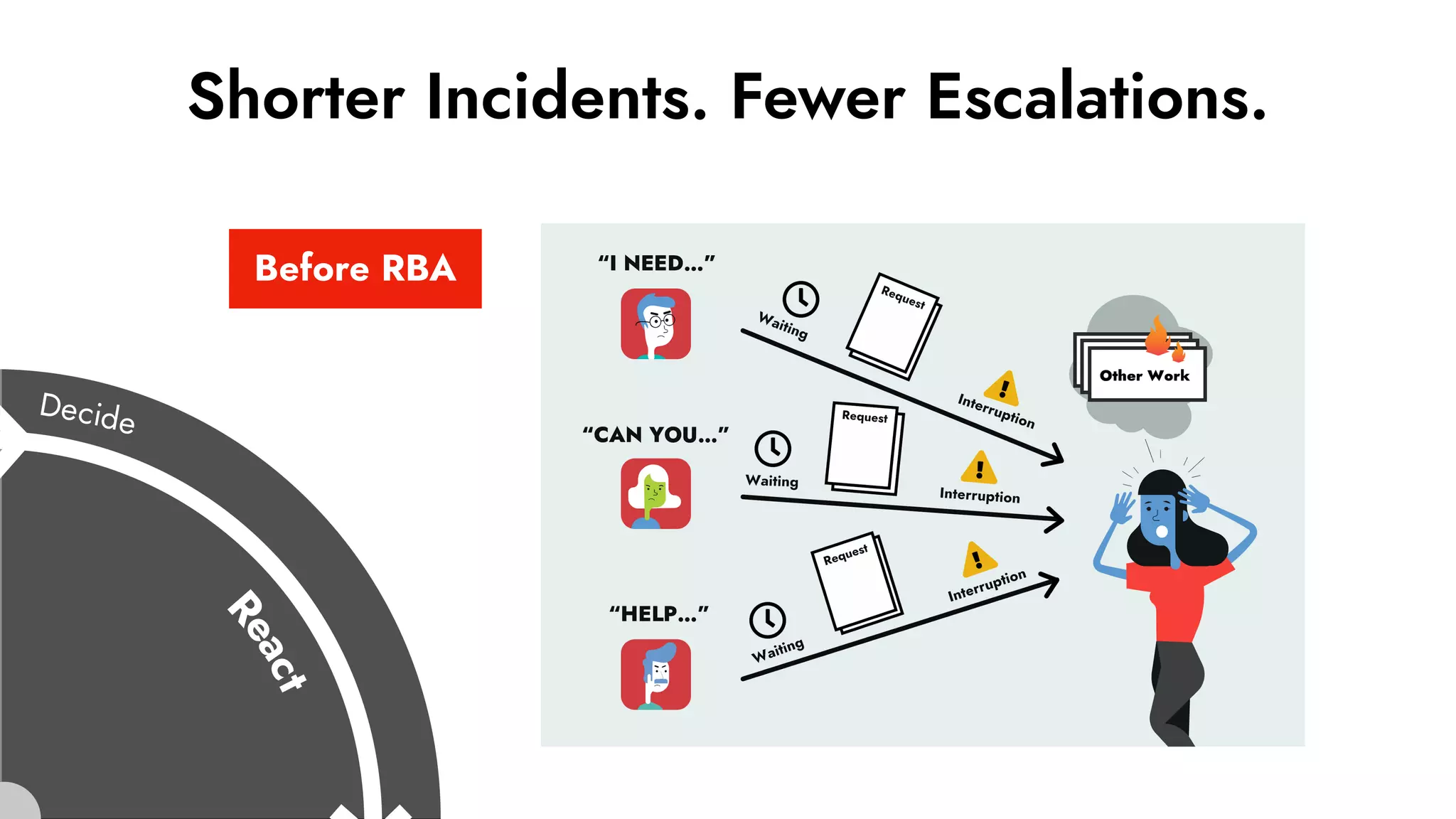
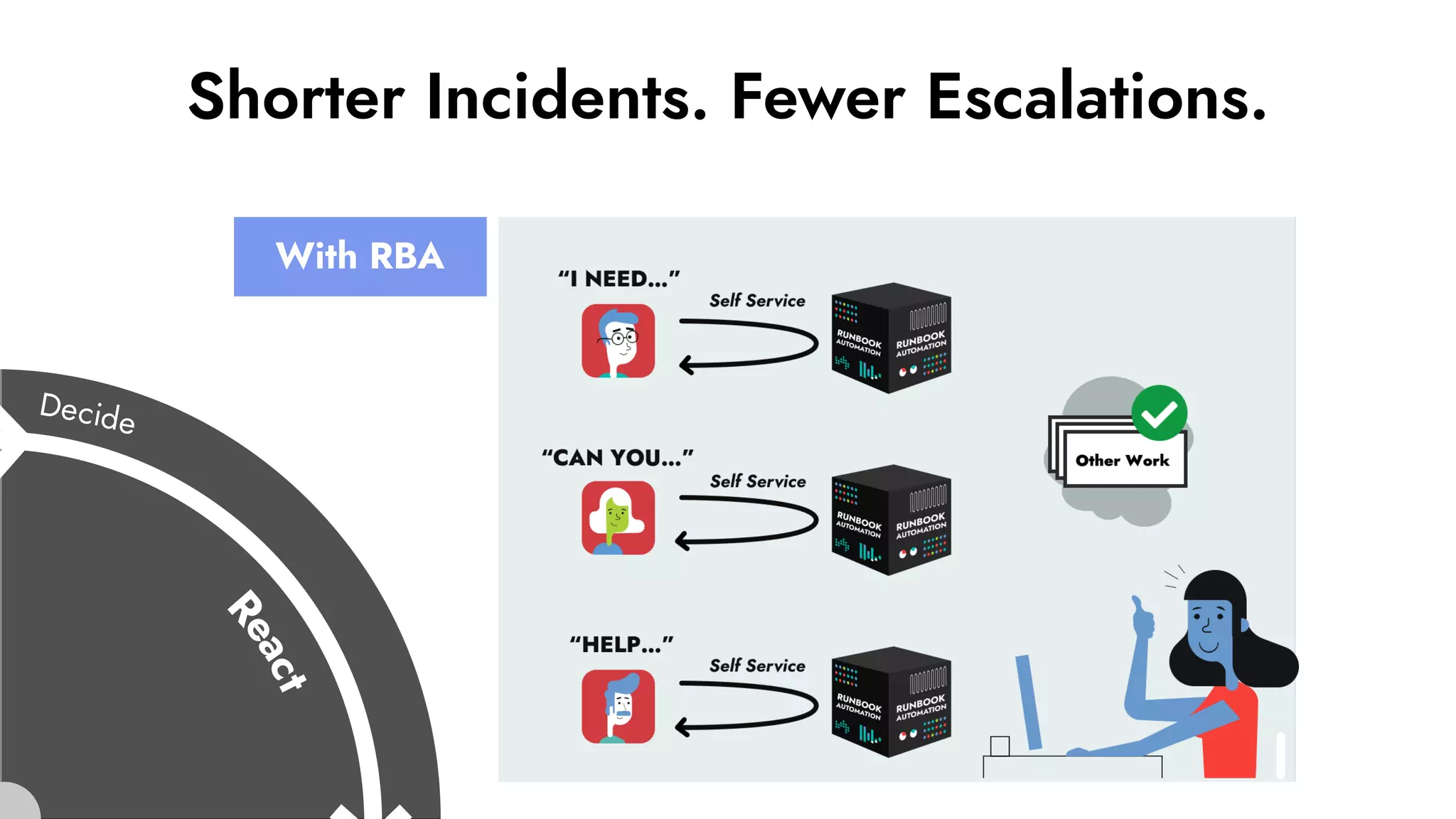


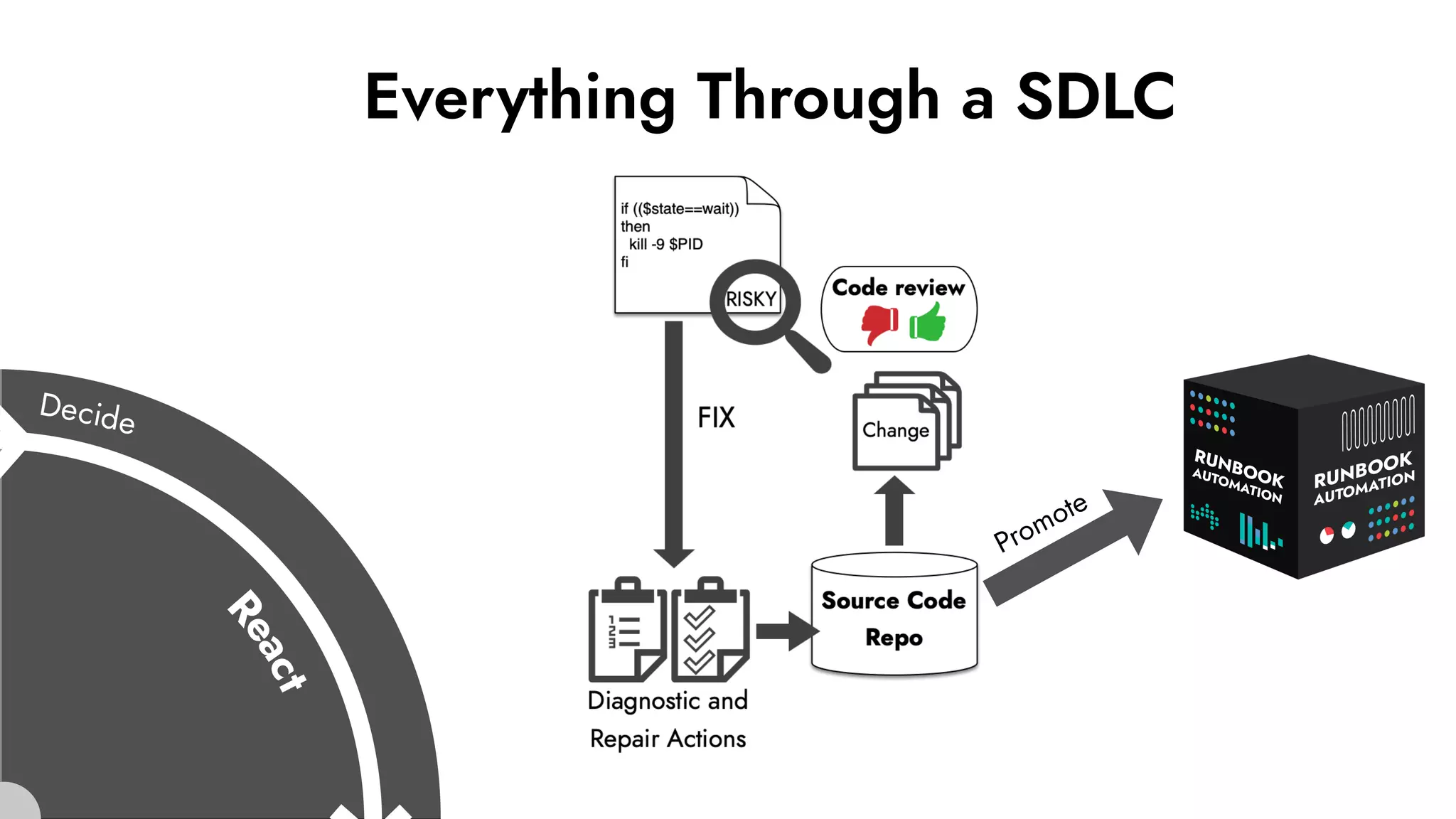
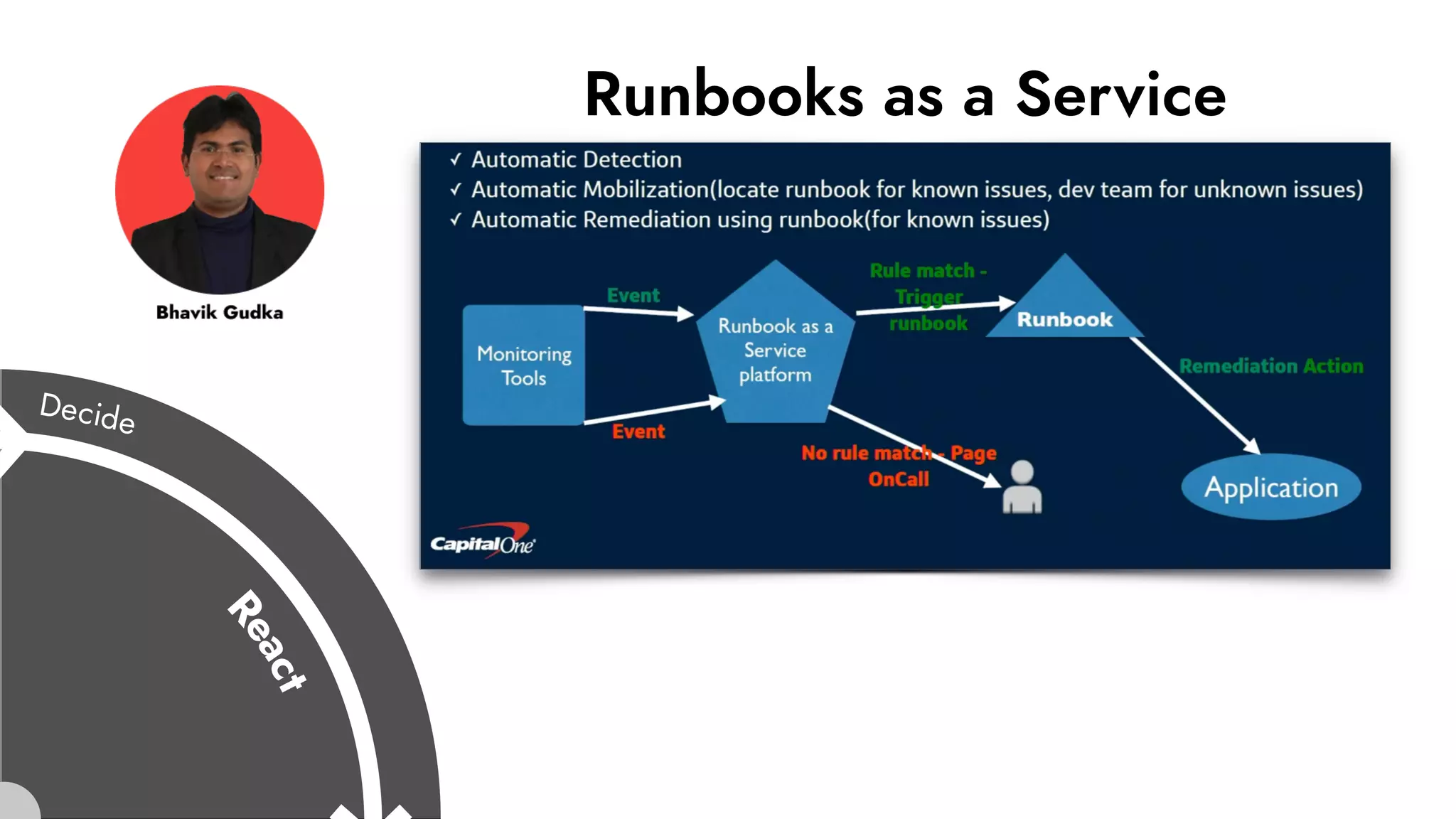


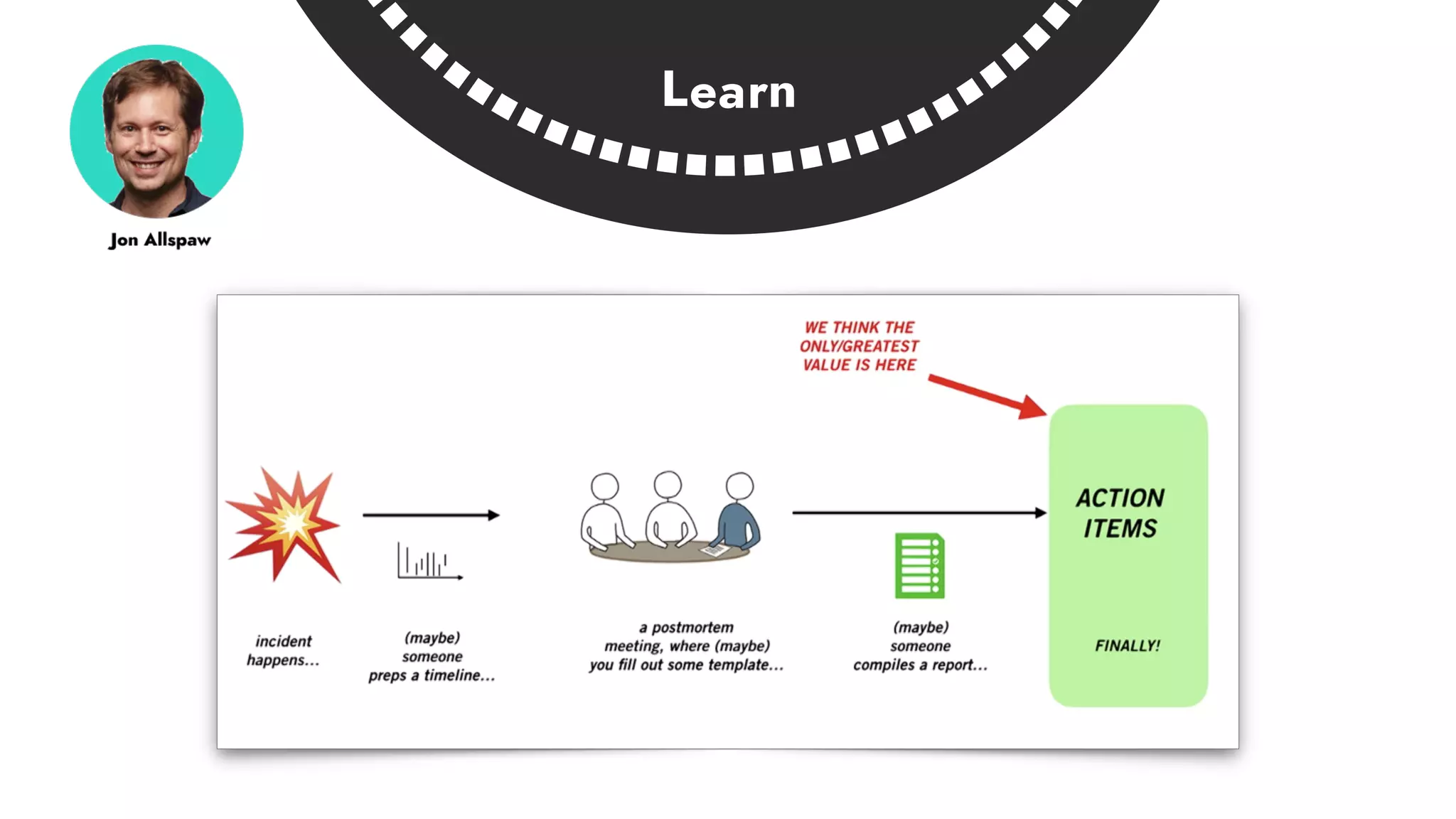
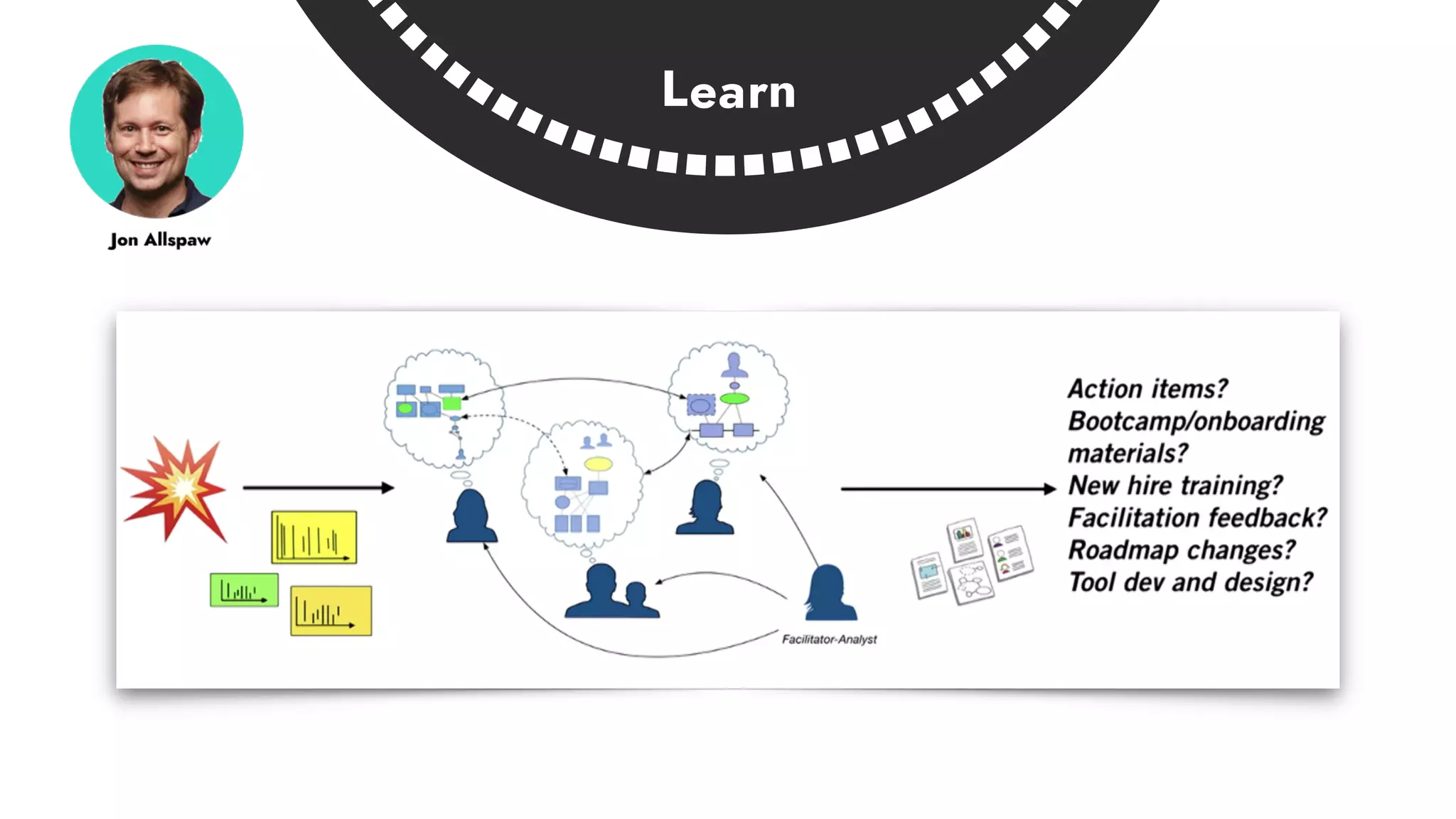
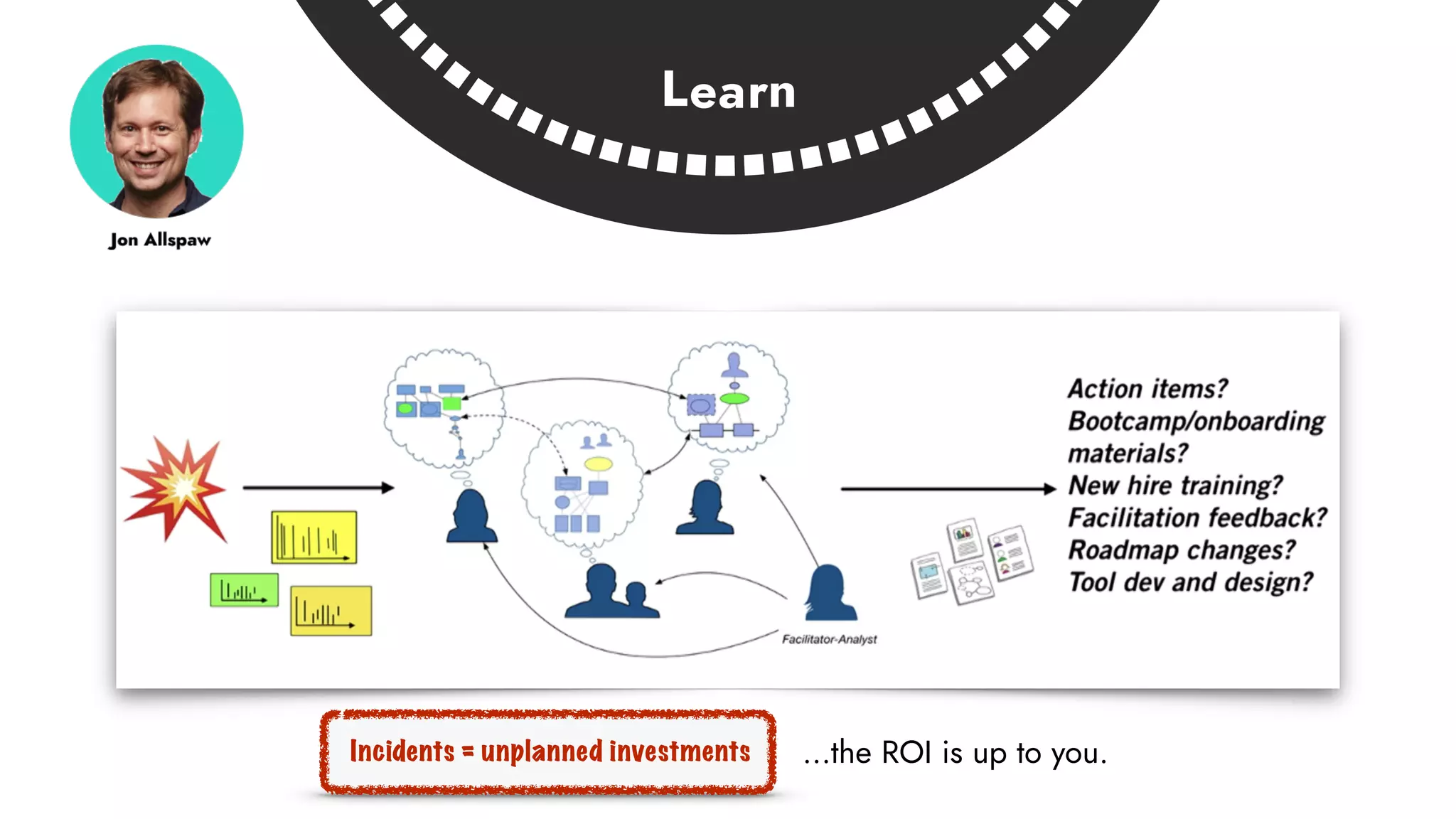
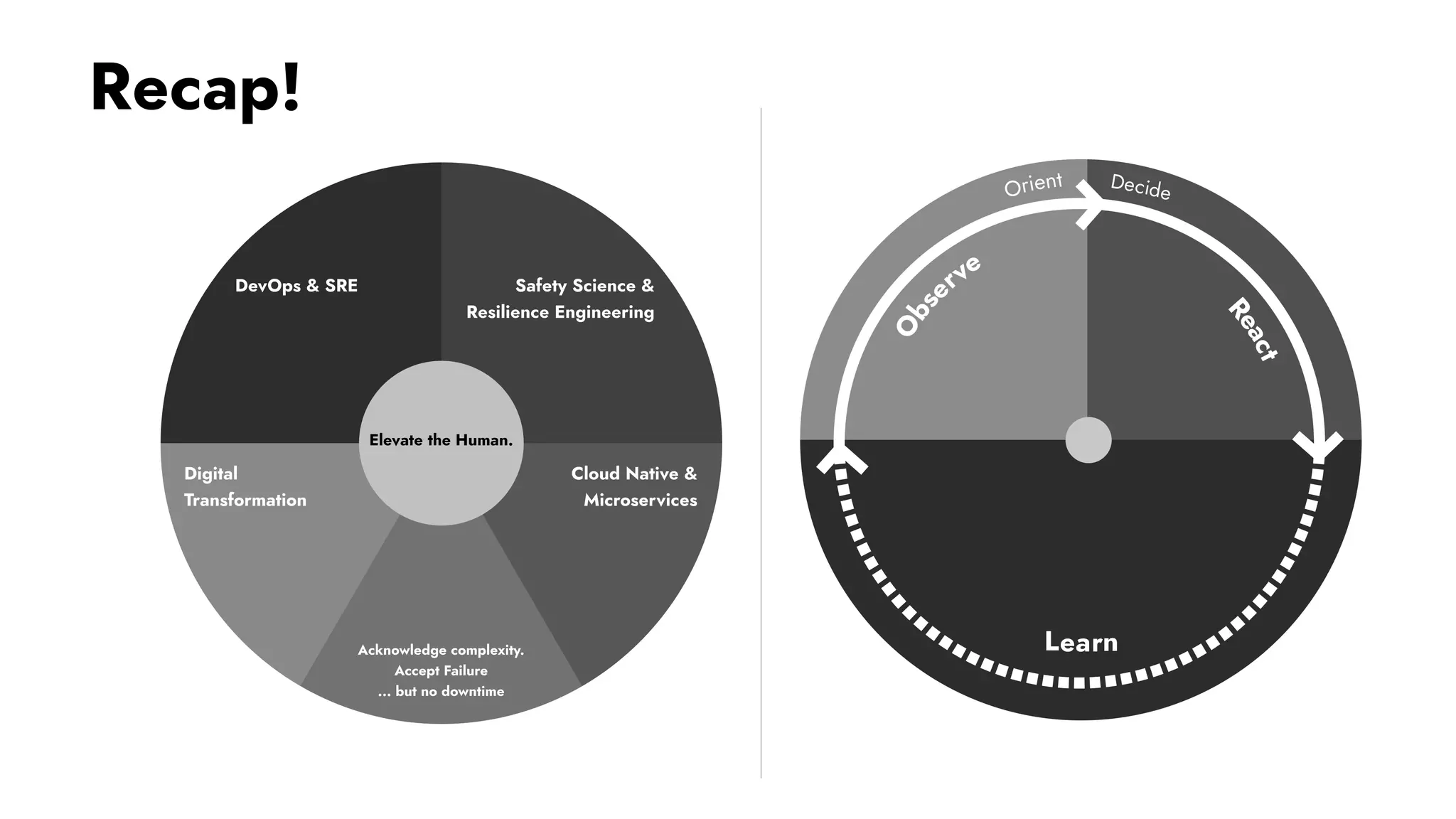


The document discusses the importance of incident management in organizations leveraging DevOps and Site Reliability Engineering (SRE), emphasizing that the ability to respond to unplanned disruptions is critical for operational success. It outlines the principles of SRE, the need for effective communication and collaboration, and the role of automation in improving response times and reducing escalations. Additionally, it highlights the transition from traditional IT service management to a more integrated, cross-functional approach that encourages shared responsibilities and continuous improvement.































































![Runbook Automation: Old News or a Key to Unlock Performance? [DOES2020]](https://cdn.slidesharecdn.com/ss_thumbnails/does-damonedwards-v2-201015073337-thumbnail.jpg?width=640&height=640&fit=bounds)























