




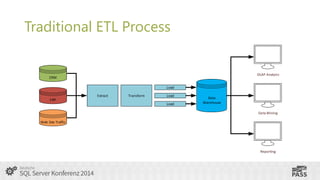
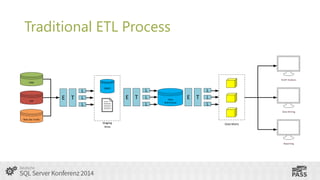
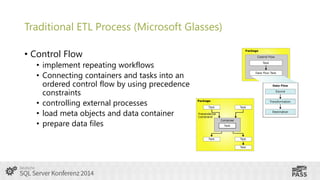
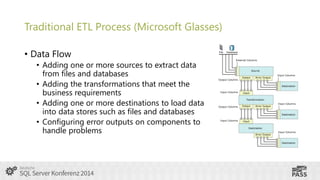
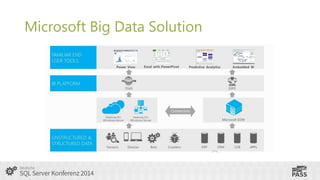








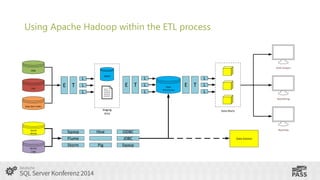


























This document summarizes a presentation on using SQL Server Integration Services (SSIS) with HDInsight. It introduces Tillmann Eitelberg and Oliver Engels, who are experts on SSIS and HDInsight. The agenda covers traditional ETL processes, challenges of big data, useful Apache Hadoop components for ETL, clarifying statements about Hadoop and ETL, using Hadoop in the ETL process, how SSIS is more than just an ETL tool, tools for working with HDInsight, getting started with Azure HDInsight, and using SSIS to load and transform data on HDInsight clusters.











































































