Download to read offline








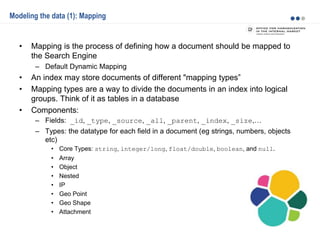

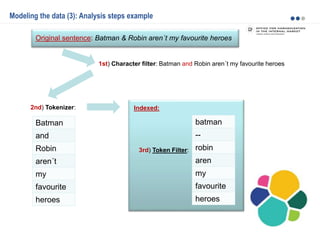



![PUT /my_index/blogpost/1
{
"title": "Nest eggs",
"body": "Making your money work...",
"tags": [ "cash", "shares" ],
"comments": [
{
"name": "John Smith",
"comment": "Great article",
"age": 28,
"stars": 4,
"date": "2014-09-01"
},
{
"name": "Alice White",
"comment": "More like this please",
"age": 31,
"stars": 5,
"date": "2014-10-22"
}
]
}
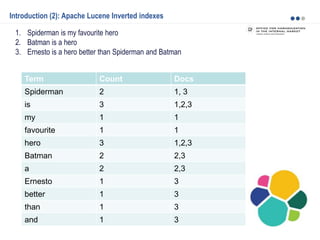
Modeling the data (7): Handling relationships – Nested objects
Given the fact that creating, deleting, and updating a single document in Elasticsearch is atomic, it
makes sense to store closely related entities within the same document:
Problem: As with denormalization, to update, add, or remove a nested object, we have to reindex the
whole document also the whole blogpost document.](https://image.slidesharecdn.com/2015-151015081423-lva1-app6891/85/Elasticsearch-basics-and-beyond-18-320.jpg)



Elasticsearch is a distributed, scalable, and highly available search and analytics engine. The key points discussed in the document include proper cluster configuration, data mappings, and monitoring. The document outlines Elasticsearch's architecture including shards, replicas, and cluster topology. It also discusses modeling data through mappings, analysis, and handling relationships. Monitoring is important and can be done through Elasticsearch plugins, JVM tools, and the stats API.



































































