Download as PDF, PPTX





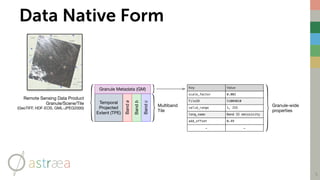
![Canonical ML Functional Form
6
c
1
a
1
b
1TPEA
1GMA [ 0 ] [ 0 ] [ 0 ] . . .[r1, c1]
Spark Dataframe Row
(i.e. ML Observation)
Band Values at
Single Cell
. . .. . .. . .. . .. . .. . .
Projected Extent of
Tile + Cell Row/
Column
Bandc
Bandb
Banda
Temporal
Projected
Extent (TPE)
Granule Metadata (GM)](https://image.slidesharecdn.com/rastersincatalyst-170525201903/85/Harnessing-Spark-Catalyst-for-Custom-Data-Payloads-6-320.jpg)




![14
IMPLEMENTATION
From GeoTiff to RDD[Tile] to Dataset[Tile] to DataFrame](https://image.slidesharecdn.com/rastersincatalyst-170525201903/85/Harnessing-Spark-Catalyst-for-Custom-Data-Payloads-14-320.jpg)

![GeoTrellis
• GeoTrellis is an open source
Scala framework for efficiently
manipulating raster GIS data
• Provides facilities to ingest and
process tiles at scale
• Has powerful abstractions for
working with RDD[Tile]s.
– Mosaicing, stitching, pyramiding,
resampling, reprojecting, etc.
– Implements C. Dana Tomlin’s
“Map Algebra”
16](https://image.slidesharecdn.com/rastersincatalyst-170525201903/85/Harnessing-Spark-Catalyst-for-Custom-Data-Payloads-16-320.jpg)

![Encoding Data with Spark Catalyst
• Catalyst is the engine behind Spark DataFrames & SQL
• Moving data from RDDs to DataFrames requires using one of two
Catalyst APIs:
– ExpressionEncoder[Tile] or
– UserDefinedType[Tile]
• Both are (currently) package private
• Both have steep learning curves
• Both are extremely powerful once harnessed
– ExpressionEncoder is ideal for simple structures
– UserDefinedType is more efficient for larger data payloads
• For our needs, UserDefinedType (UDT) is the best fit
18](https://image.slidesharecdn.com/rastersincatalyst-170525201903/85/Harnessing-Spark-Catalyst-for-Custom-Data-Payloads-18-320.jpg)
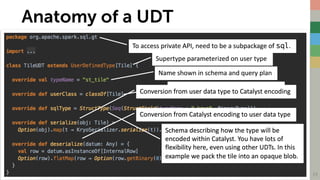





- The document discusses harnessing Spark Catalyst to efficiently build machine learning models with earth observation data like satellite imagery. - It describes registering a Tile user-defined type (UDT) to encode raster tile data payloads in Spark DataFrames and SQL, allowing the use of powerful Spark APIs. - The approach prototyped leverages the GeoTrellis library to ingest raster data into RDDs of tiles, then encodes tiles as a UDT to represent them as columns in DataFrames for further analysis and machine learning.



































































