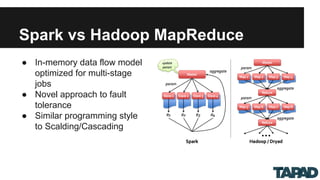
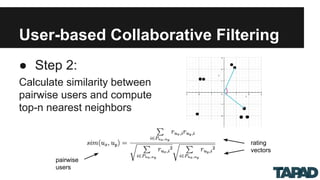
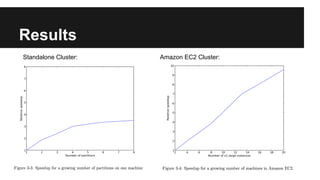
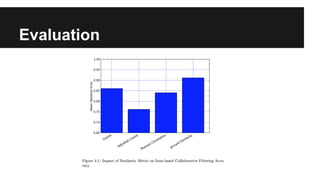
The document discusses scalable collaborative filtering recommendation algorithms using Apache Spark, highlighting its advantages over Hadoop MapReduce in processing large datasets. It explains the functioning of user-based and item-based collaborative filtering, detailing steps for calculating user similarity and effective recommendation scores. Key lessons include optimizing task distribution, using broadcast variables, and accounting for user rating behaviors in large-scale systems.






























































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)















