Downloaded 58 times














![Implementation
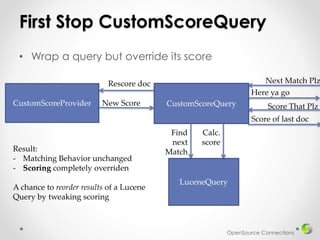
• CustomScoreProvider rescores each doc with
IndexReader & docId
OpenSource Connections
// Give all docs a score of 1.0
public float customScore(int doc, float subQueryScore, float
valSrcScores[]) throws IOException {
return (float)(1.0f); // New Score
}](https://image.slidesharecdn.com/customlucenequeries-140415110757-phpapp02/85/Hacking-Lucene-for-Custom-Search-Results-18-320.jpg)
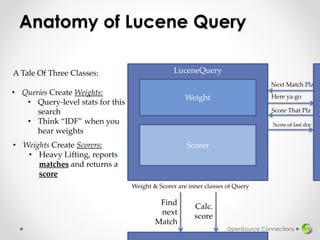
![Implementation
• Example: Sort by number of terms in a field
OpenSource Connections
// Rescores by counting the number of terms in the field
public float customScore(int doc, float subQueryScore, float
valSrcScores[]) throws IOException {
IndexReader r = context.reader();
Terms tv = r.getTermVector(doc, _field);
TermsEnum termsEnum = null;
termsEnum = tv.iterator(termsEnum);
int numTerms = 0;
while((termsEnum.next()) != null) {
numTerms++;
}
return (float)(numTerms); // New Score
}](https://image.slidesharecdn.com/customlucenequeries-140415110757-phpapp02/85/Hacking-Lucene-for-Custom-Search-Results-19-320.jpg)

























Doug Turnbull discusses customizing search results using Lucene, highlighting challenges in satisfying user expectations and the limitations of standard search methods. He introduces the concept of custom scoring and querying to enhance relevance in search results, providing practical examples and code snippets. The presentation encourages leveraging these advanced techniques to overcome complex search problems while noting the potential complexities involved.























































































