Downloaded 49 times










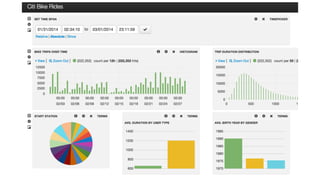


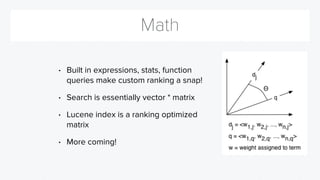








The document discusses Solr, an open-source search platform with over 8 million downloads, highlighting its key features such as full-text search, data analysis tools, and massive scalability. It emphasizes the importance of quickly identifying significant data for exploration and includes information on integrations with tools like Logstash and Kibana. Lucidworks, the company behind Solr, is noted for its substantial contributions to Solr's development, providing various resources and integration options for data science applications.
























































































