








![Introduction
Background
◦ Recovery
rare exception -> regular operation
GFS[1]:
Hundreds or even thousands of machines
Inexpensive commodity parts
High concurrency/IO
◦ High failure tolerance, both for
High availability and to prevent data loss
[1] S. Ghemawat, H. Gobioff, and S.-T. Leung, “The Google file system,” in
SOSP ’03: Proc. of the 19th ACM Symposium on Operating Systems
Principles, 2003.](https://image.slidesharecdn.com/simpleregeneratingcodes-120410203719-phpapp02/85/Simple-regenerating-codes-Network-Coding-for-Cloud-Storage-9-320.jpg)

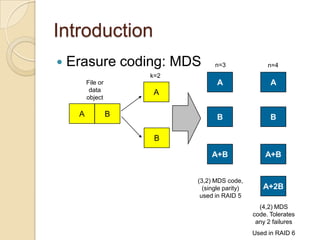
![Introduction
Erasure coding vs. Replica[3]erasure code
(4,2) MDS
Replication (any 2 suffice to recover)
File or A A
data A
object
A B
vs
B
B A+B
B A+2B
[3]A. G. Dimakis, P. G. Godfrey, Y. Wu, M. J. Wainwright, and K. Ramchandran,“Network
coding for distributed storage systems,” in IEEE Trans. on Inform. Theory, vol. 56, pp.](https://image.slidesharecdn.com/simpleregeneratingcodes-120410203719-phpapp02/85/Simple-regenerating-codes-Network-Coding-for-Cloud-Storage-12-320.jpg)
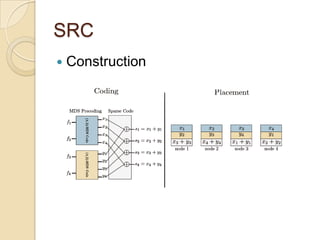
![Introduction
Erasure coding vs. Replica[3]erasure code
(4,2) MDS
Replication (any 2 suffice to recover)
File or A A
data A
object
A B
Erasure coding is introducing redundancy in an optimal way.
vs
B Very useful in practice
i.e. Reed-Solomon codes, Fountain Codes, (LT and Raptor)…
B A+B
B A+2B
[3]A. G. Dimakis, P. G. Godfrey, Y. Wu, M. J. Wainwright, and K. Ramchandran,“Network
coding for distributed storage systems,” in IEEE Trans. on Inform. Theory, vol. 56, pp.](https://image.slidesharecdn.com/simpleregeneratingcodes-120410203719-phpapp02/85/Simple-regenerating-codes-Network-Coding-for-Cloud-Storage-13-320.jpg)



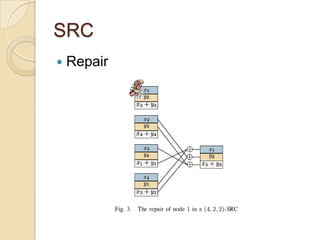
![SRC
Object
Requirement I: (n, k) property
MDS[2]
[2] Alexandros G. Dimakis, Kannan Ramchandran, Yunnan
Wu, Changho Suh:
A Survey on Network Codes for Distributed Storage. in Proceedings of the](https://image.slidesharecdn.com/simpleregeneratingcodes-120410203719-phpapp02/85/Simple-regenerating-codes-Network-Coding-for-Cloud-Storage-17-320.jpg)

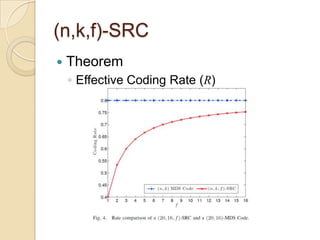
![SRC
Requirement II: efficient exact repair
◦ Efficient: Low complexity
◦ Exact repair (vs. functional repair)[3] :
1. [demands]Data have to stay in systematic
form
2. [complexity]Updating repairing-decoding
rules-> additional overhead
3. [security] dynamic repairing-and-decoding
rules observed by eavesdroppers ->
information leakage
[2] Changho Suh, Kannan Ramchandran: Exact Regeneration Codes
for Distributed Storage Repair Using Interference Alignment. in IEEE
TRANSACTIONS ON INFORMATION THEORY, VOL. 57, NO. 3, MARCH](https://image.slidesharecdn.com/simpleregeneratingcodes-120410203719-phpapp02/85/Simple-regenerating-codes-Network-Coding-for-Cloud-Storage-19-320.jpg)











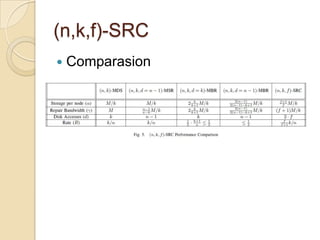



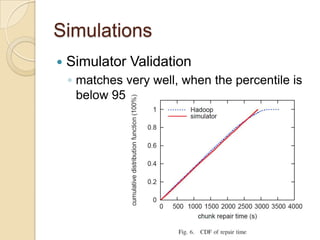
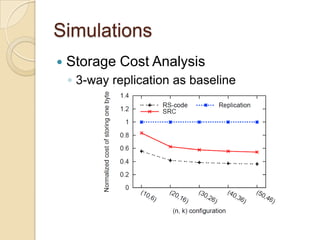
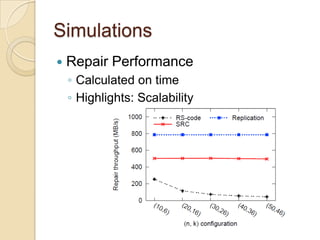
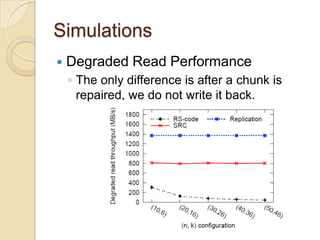

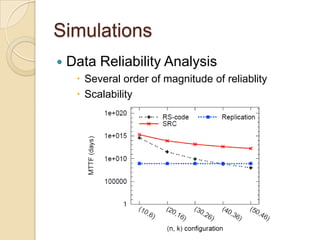




The document presents Simple Regenerating Codes (SRC) for efficient data repair in cloud storage systems. SRC combines MDS codes for reliability with XOR operations to allow repair using minimal bandwidth and disk I/O. Simulations show SRC reduces storage costs compared to replication and maintains high reliability while improving repair scalability through reduced repair bandwidth and disk accesses.





















![129966862758614726[1]](https://cdn.slidesharecdn.com/ss_thumbnails/1299668627586147261-130806105216-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)















































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)
















