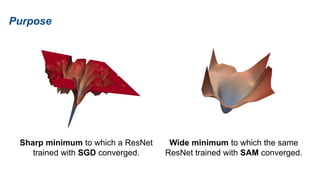
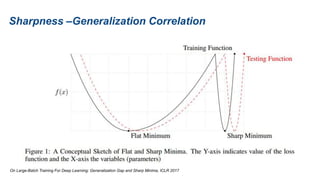
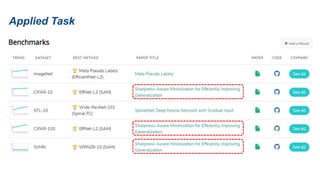
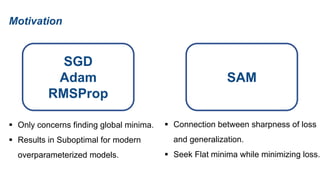
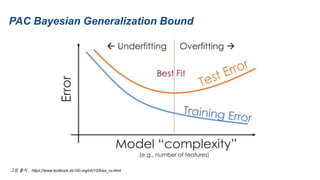
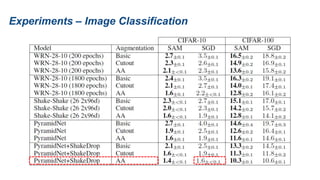
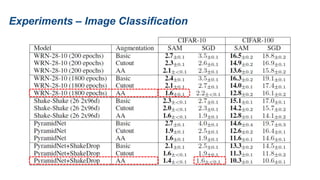
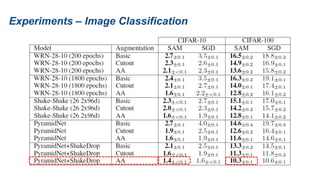
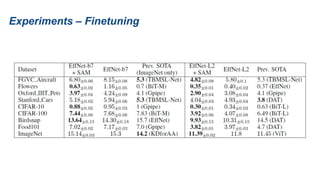
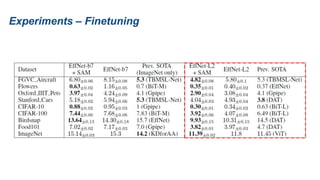
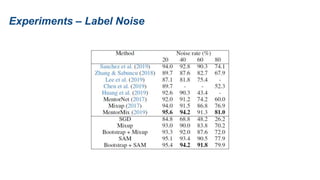
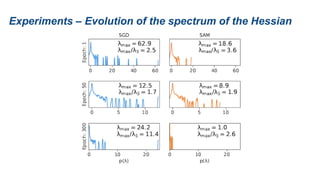
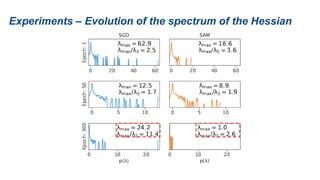
The document presents research on sharpness-aware minimization (SAM) as a method to improve generalization in deep learning, particularly for models trained with gradient descent methods like SGD. It discusses the correlation between loss sharpness and model generalization, explaining how SAM seeks to find flatter minima that enhance performance on various tasks including image classification and robustness to label noise. The approach involves minimizing upper bounds related to sharpness while also analyzing its effectiveness through experiments.






























































![[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0114-220114032933-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Deep Direct Reinforcement Learning for Financial Signal Representation...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks171113miyazaki-171114063842-thumbnail.jpg?width=640&height=640&fit=bounds)
















































![Polymer [ बहुलक ] Chemistry Notes PDF - Irfanullah Mehar - JJ Sir Chemistry.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/polymerchemistrynotespdf-irfanullahmehar-jjsirchemistry-260210172118-3f9b37f7-thumbnail.jpg?width=640&height=640&fit=bounds)











