Downloaded 19 times











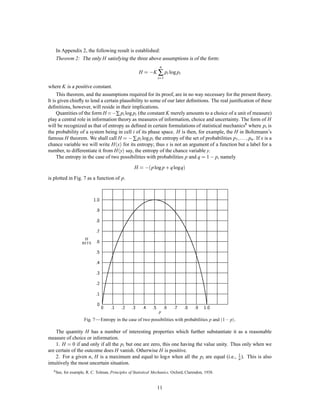













































The document presents a mathematical theory of communication developed by C. E. Shannon, focusing on the influence of noise, statistical structures of messages, and their effect on the design of communication systems. It outlines the fundamental components of a communication system and discusses the characteristics of discrete, continuous, and mixed systems, particularly emphasizing the measurement of channel capacity and the role of information sources. The theory integrates engineering principles with a mathematical framework to quantify and enhance communication efficiency.






































































































