







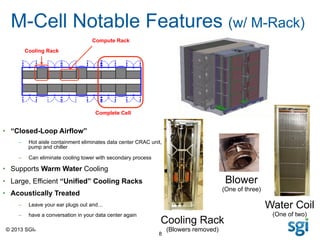
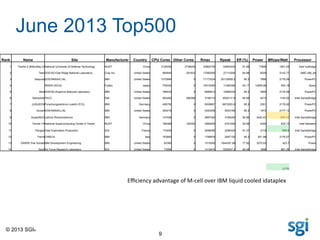
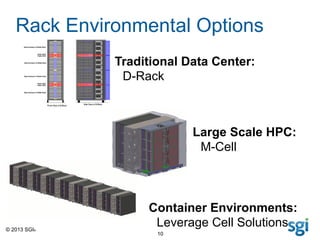

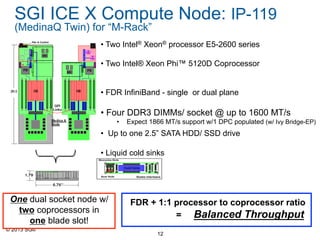






The document outlines SGI's advancements in high-performance computing (HPC), showcasing the SGI UV and ICE X servers designed for data-intensive applications, featuring the latest Intel Xeon processors. It highlights the performance rankings of multiple supercomputers and presents the efficiency advantages of their M-cell technology over traditional data center solutions. SGI emphasizes a focus on solving customer problems with innovative computing and cooling solutions.































































































