

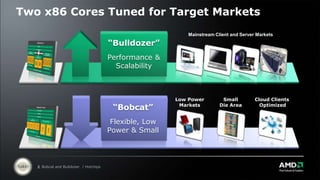


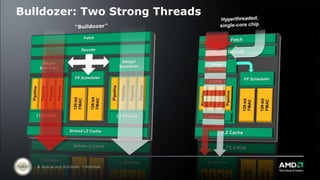



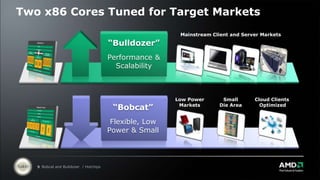


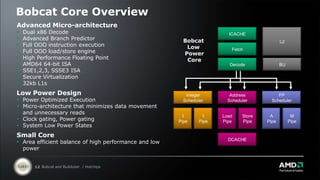



AMD is introducing two new x86 CPU cores called "Bulldozer" and "Bobcat". Bulldozer is aimed at mainstream client and server markets, featuring improved performance and scalability. It uses a shared/dedicated resource approach to increase performance per watt. Bobcat is optimized for low power markets like cloud clients. It features a smaller, more efficient design to deliver high performance while minimizing power consumption and die size.







































































































