Downloaded 51 times


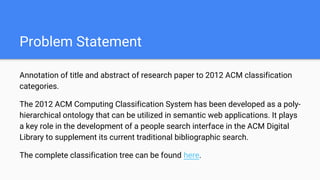








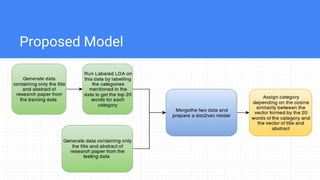

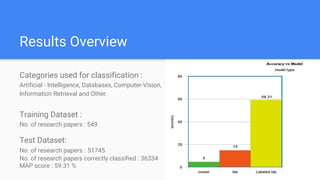


The document describes a project to semantically annotate research papers with ACM classification categories. It discusses using cosine similarity, latent Dirichlet allocation, and a proposed model combining labeled LDA and doc2vec. The proposed model trains a supervised topic model to learn document representations that capture semantic relationships between papers and categories. The model achieved 59.31% mean average precision and 45.03% NDCG on a test dataset, demonstrating an improvement over baselines.



































![[SmartNews] Globally Scalable Web Document Classification Using Word2Vec](https://cdn.slidesharecdn.com/ss_thumbnails/smartnewsdocumentclassification-150428133649-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)














![Document Clustering using LDA | Haridas Narayanaswamy [Pramati]](https://cdn.slidesharecdn.com/ss_thumbnails/documentclusteringusinglda-190430091535-thumbnail.jpg?width=640&height=640&fit=bounds)




























