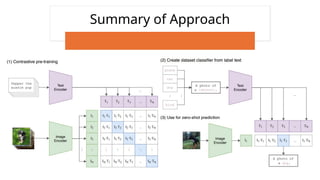
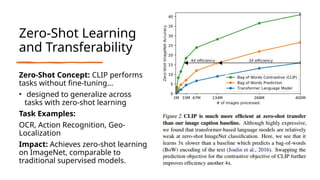
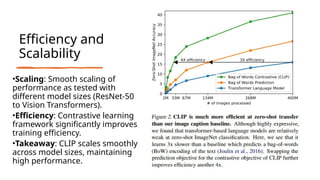
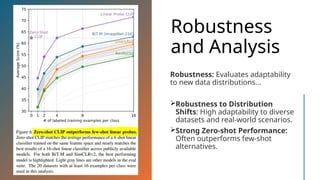
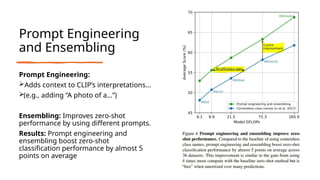
The document discusses CLIP (Contrastive Language-Image Pre-training), a framework designed to overcome the limitations of traditional computer vision models by enabling learning from natural language paired with images. It utilizes a dataset of 400 million image-text pairs and employs a contrastive learning strategy to achieve high performance, including zero-shot capabilities across various tasks. While CLIP shows strong generalization and scalability, it faces challenges such as data bias and underperformance in specialized domains.




















![[PR12] You Only Look Once (YOLO): Unified Real-Time Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/yolo-170616085751-thumbnail.jpg?width=640&height=640&fit=bounds)












![[5분 논문요약] Structured Knowledge Distillation for Semantic Segmentation](https://cdn.slidesharecdn.com/ss_thumbnails/20190410sjleestructuredknowledgedistillationforsemanticsegmentation-190414152930-thumbnail.jpg?width=640&height=640&fit=bounds)








![251103_Thuy_Labseminar[Grounded Language-Image Pre-training].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/251103thuylabseminar-251103113311-941d56eb-thumbnail.jpg?width=640&height=640&fit=bounds)





![251027_Thuy_Labseminar[Scaling Language-Image Pre-training via Masking].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/251027thuylabseminar-251027105015-a1b9f3e8-thumbnail.jpg?width=640&height=640&fit=bounds)




![[NS][Lab_Seminar_250224]GraphAdapter.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar250224graphadapter-250224130027-8504e9dc-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 24] Nemanja Milosevic - Beyond Supervised Learning with Zero-Shot...](https://cdn.slidesharecdn.com/ss_thumbnails/nemanjamilosevic-241219150756-b1cc16e6-thumbnail.jpg?width=640&height=640&fit=bounds)



















![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)


