Download as PDF, PPTX





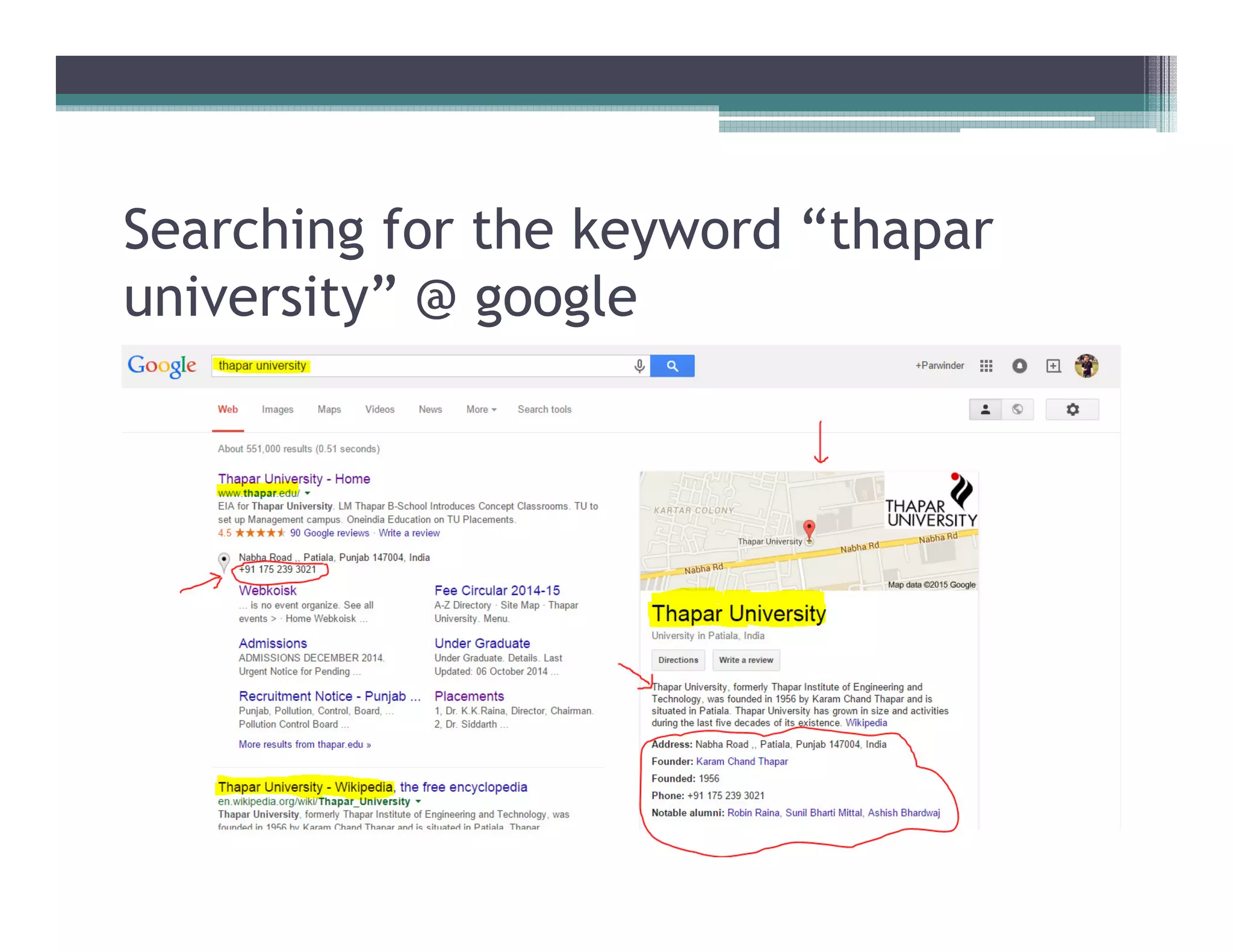

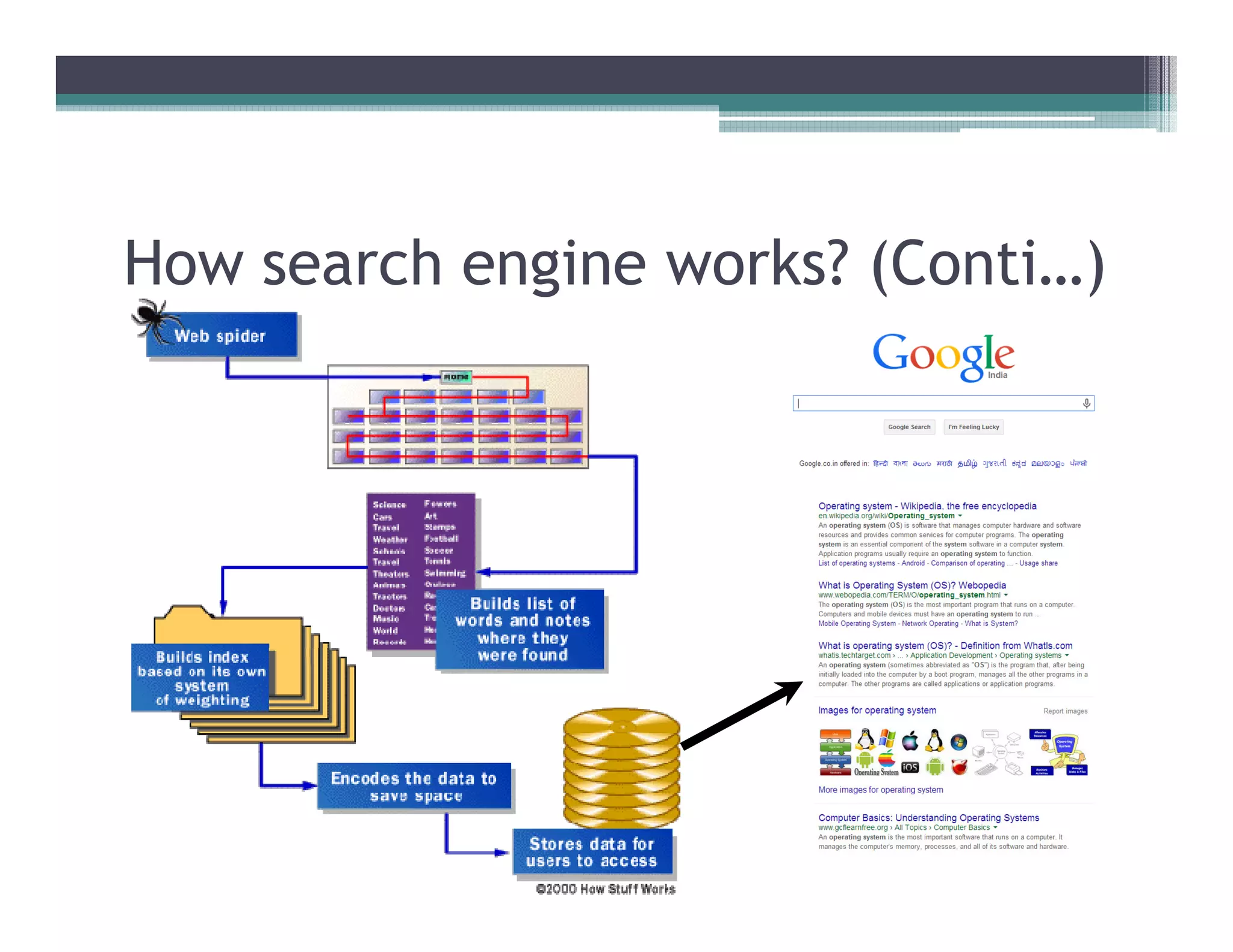


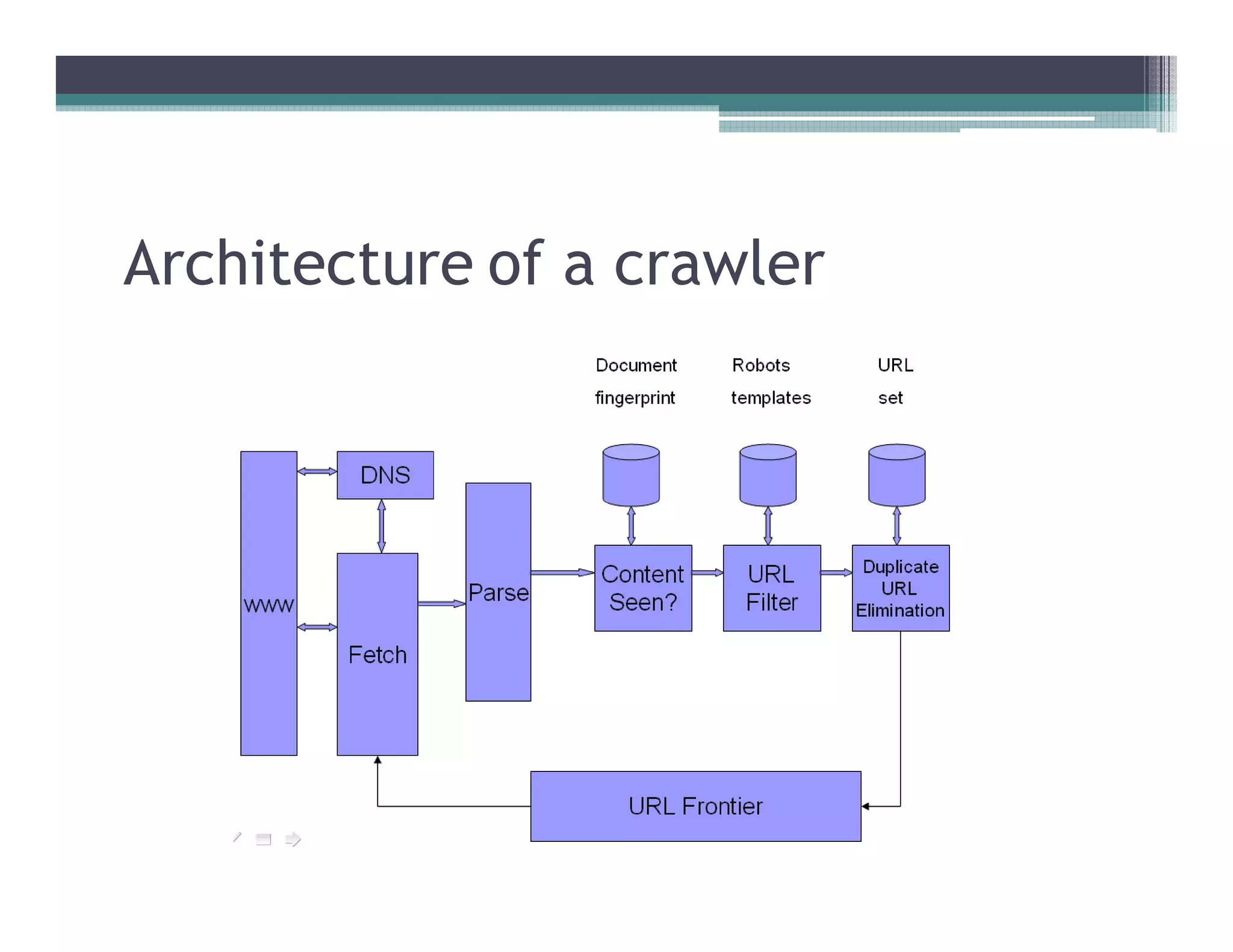




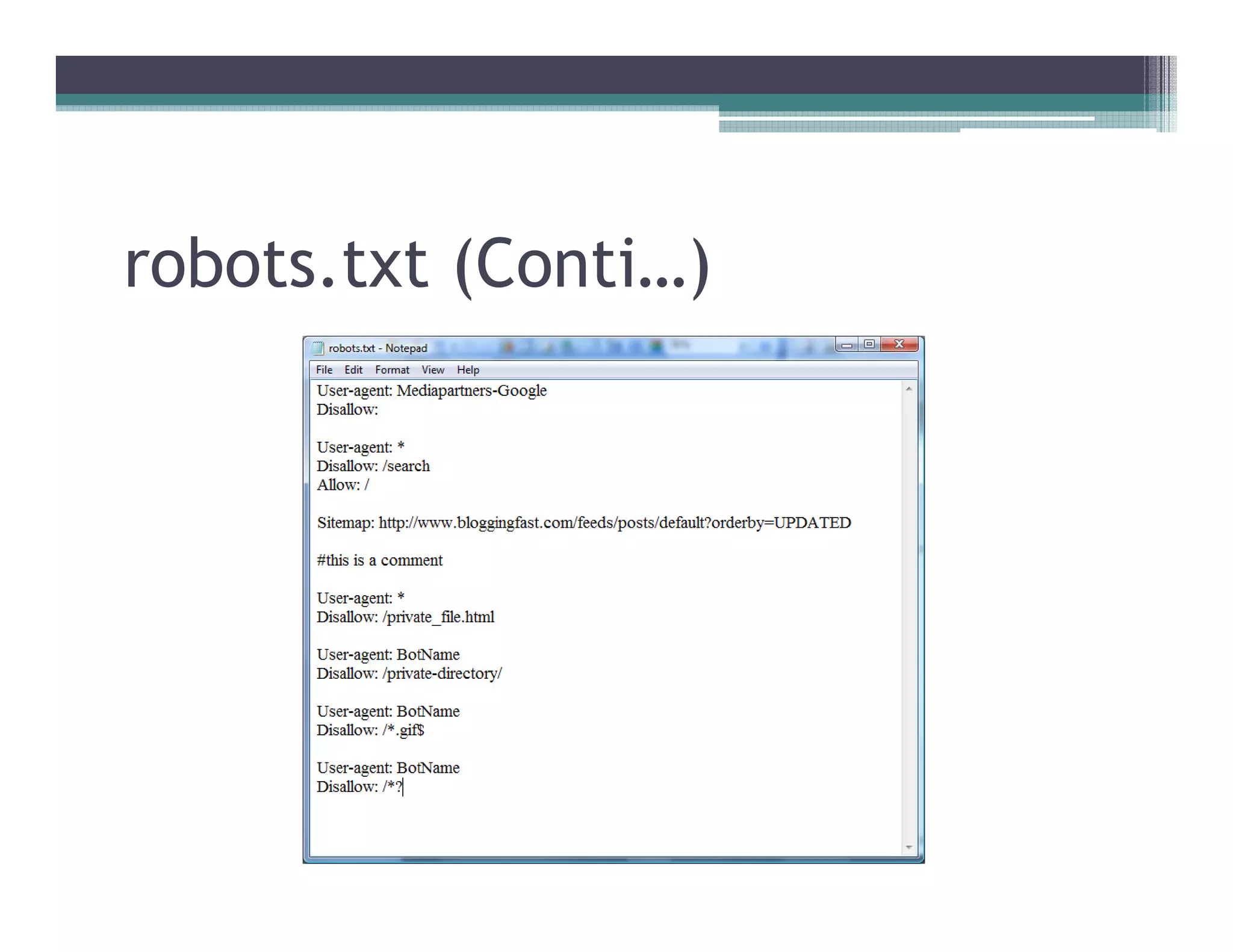


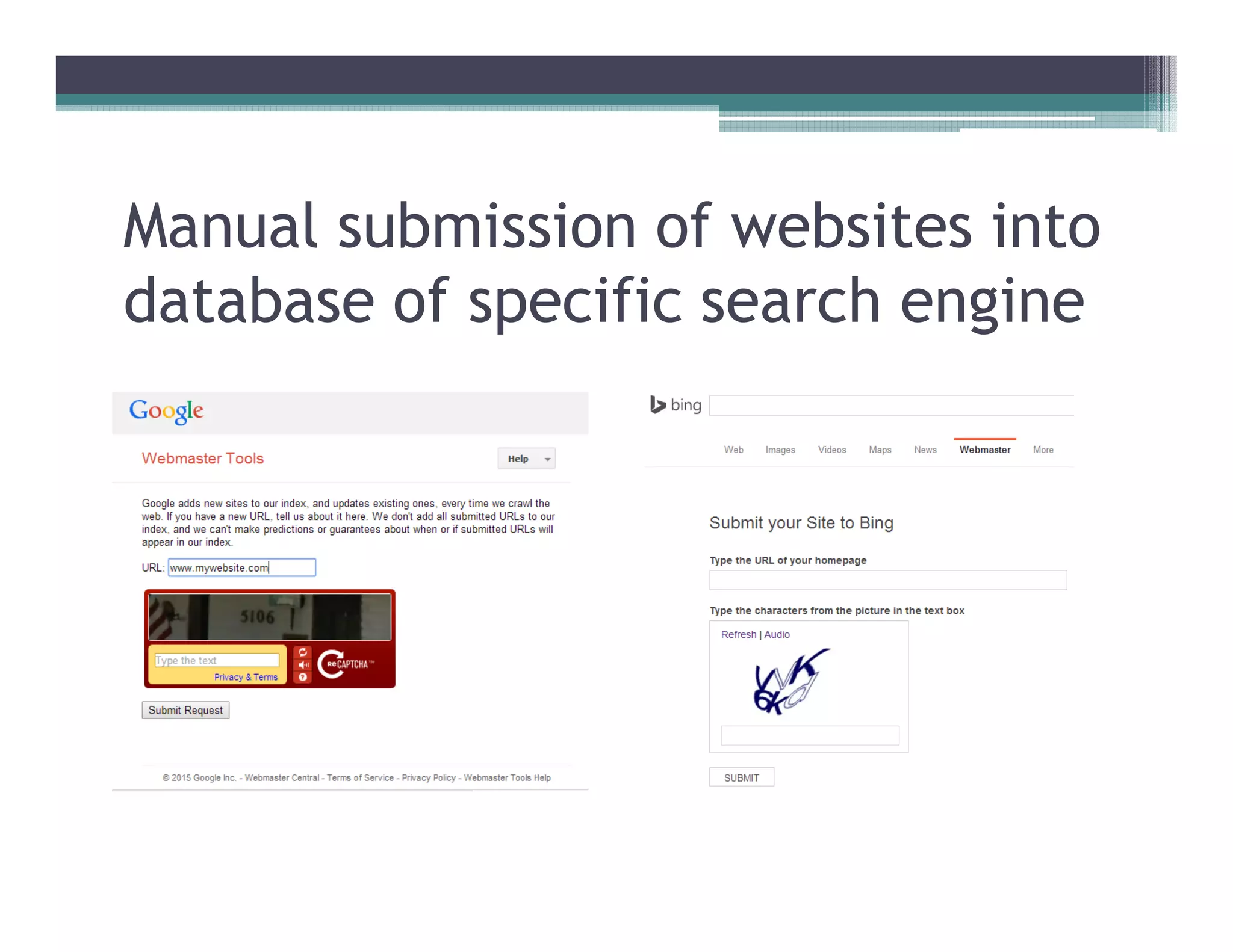





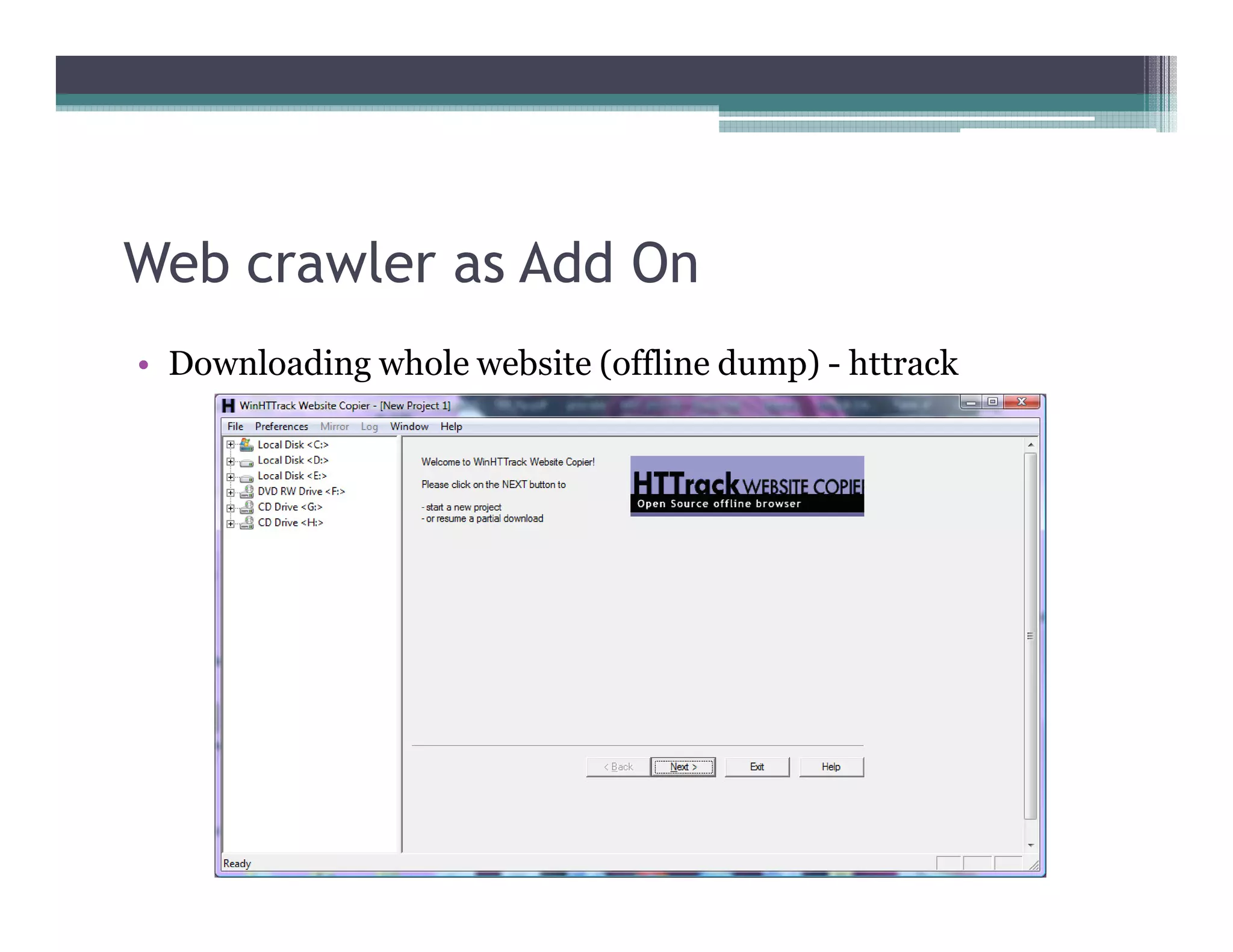
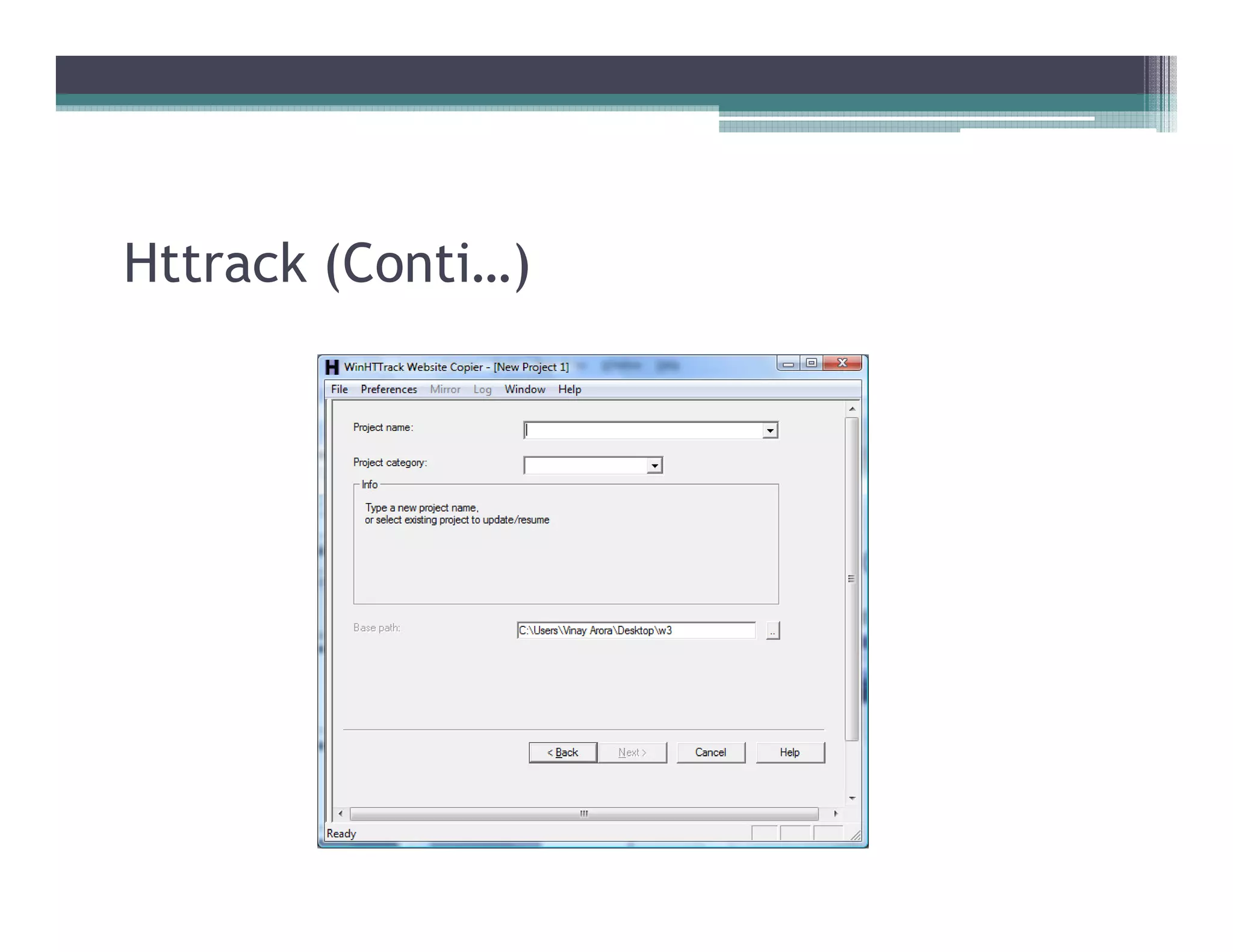
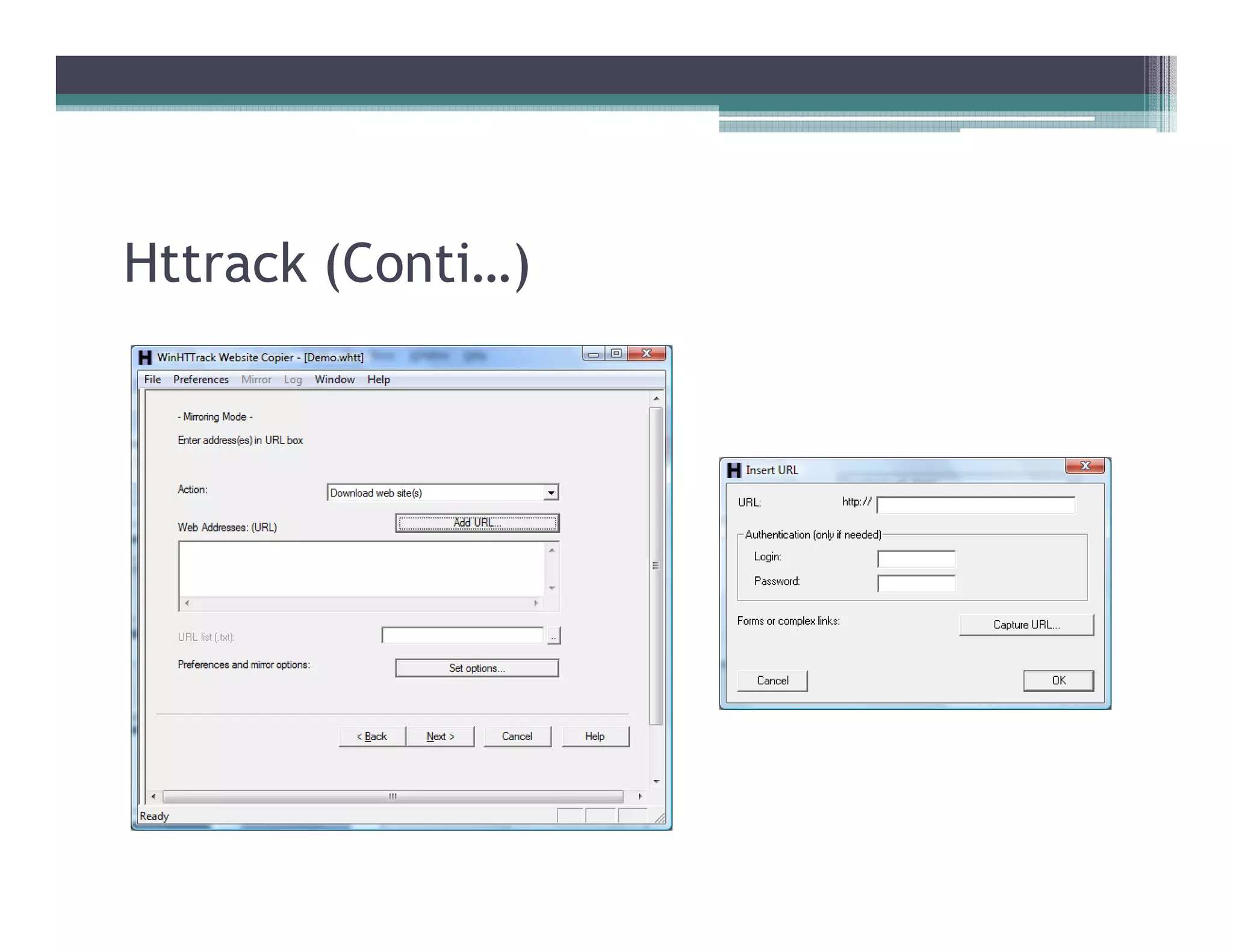
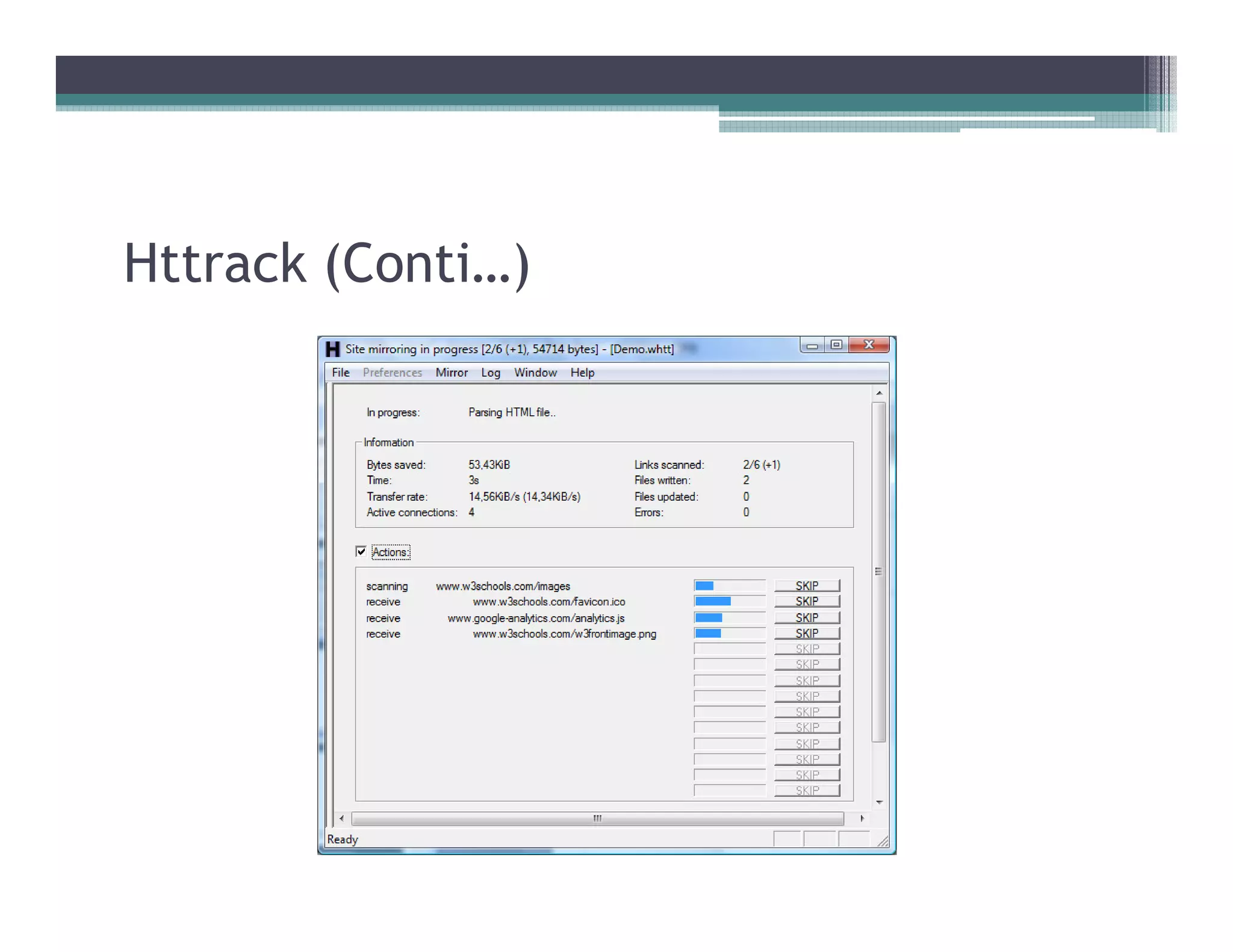

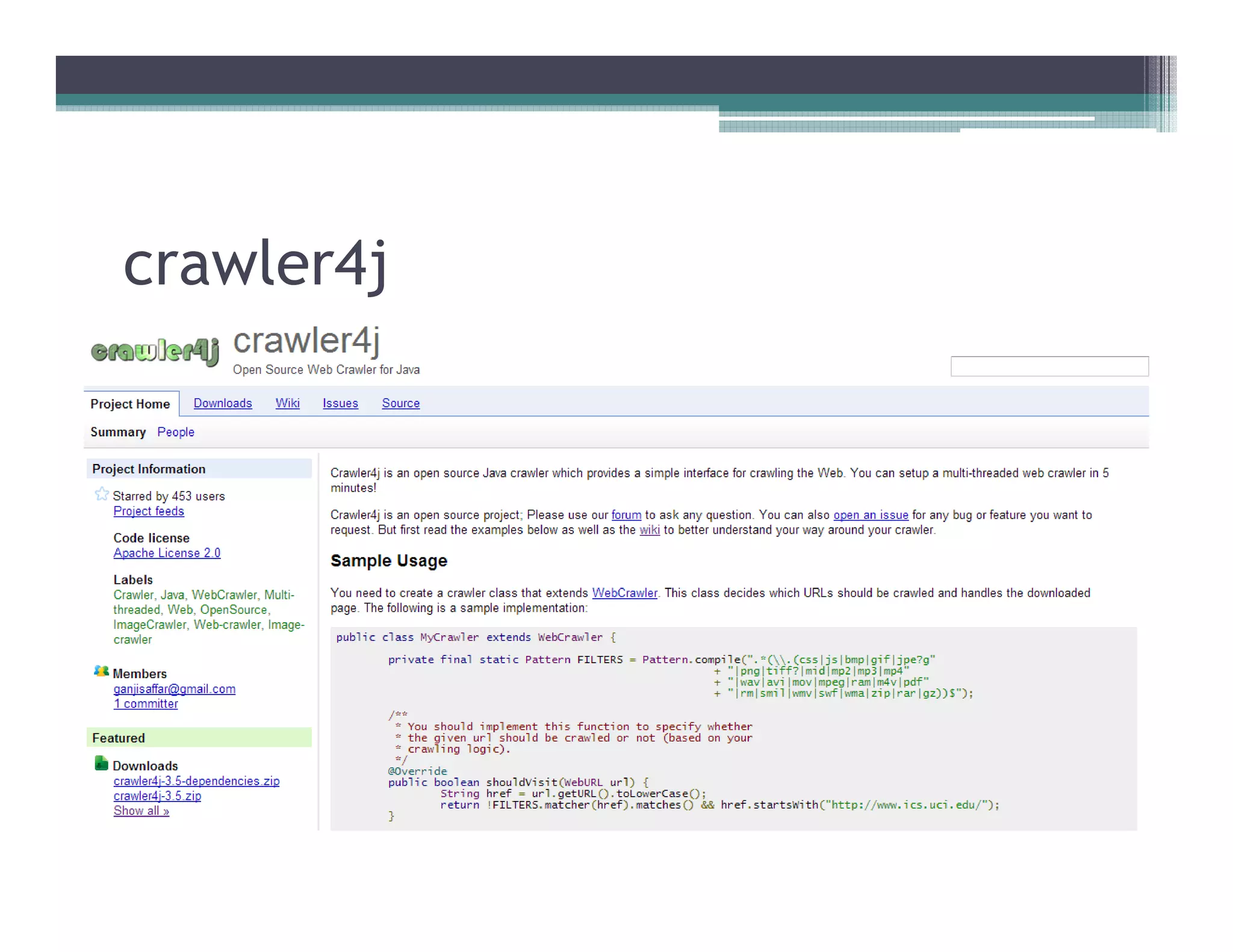




This document discusses search engines and web crawling. It begins by defining a search engine as a searchable database that collects information from web pages on the internet by indexing them and storing the results. It then discusses the need for search engines and provides examples. The document outlines how search engines work using spiders to crawl websites, index pages, and power search functionality. It defines web crawlers and their role in crawling websites. Key factors that affect web crawling like robots.txt, sitemaps, and manual submission are covered. Related areas like indexing, searching algorithms, and data mining are summarized. The document demonstrates how crawlers can download full websites and provides examples of open source crawlers.







































































































