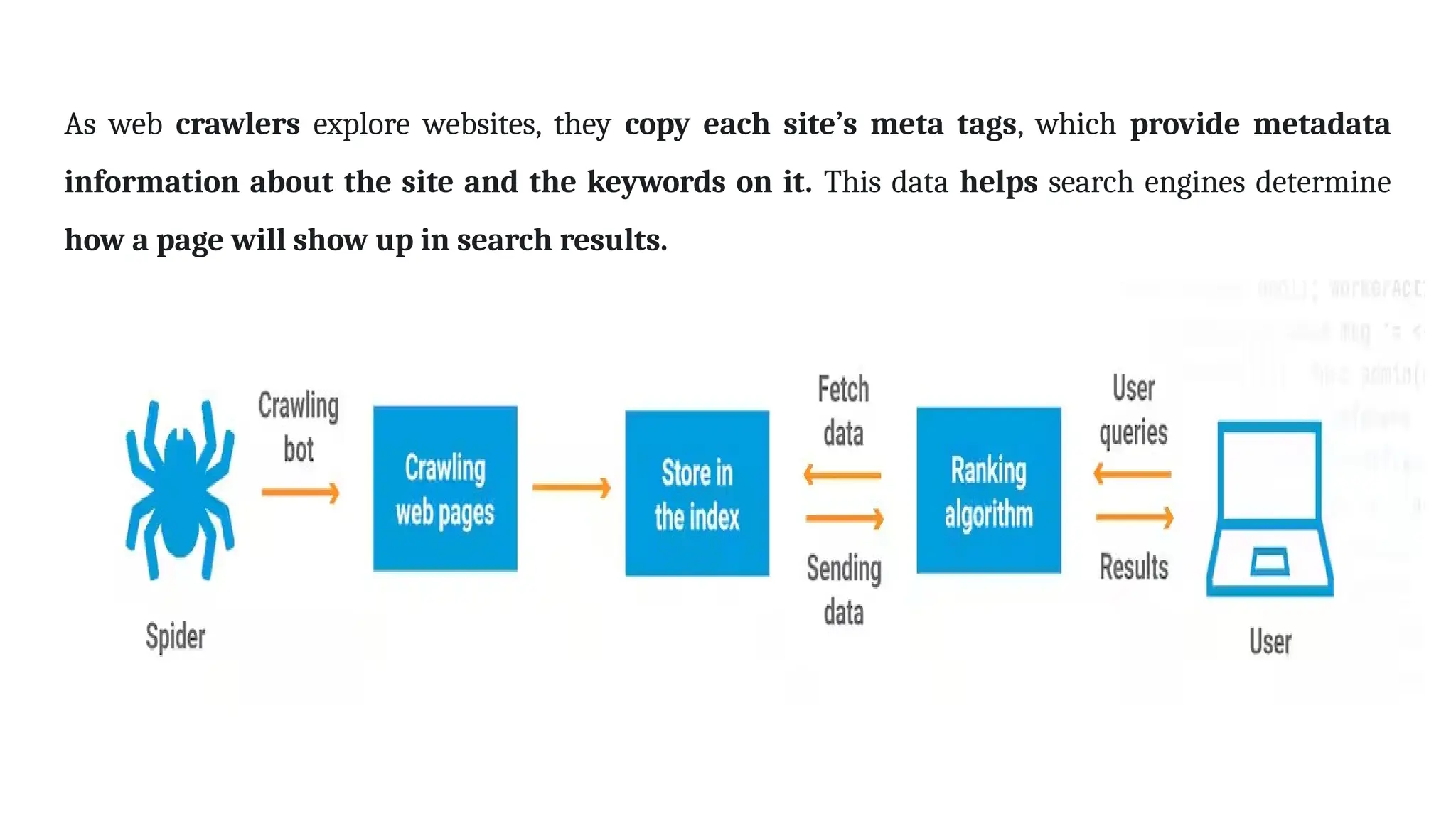
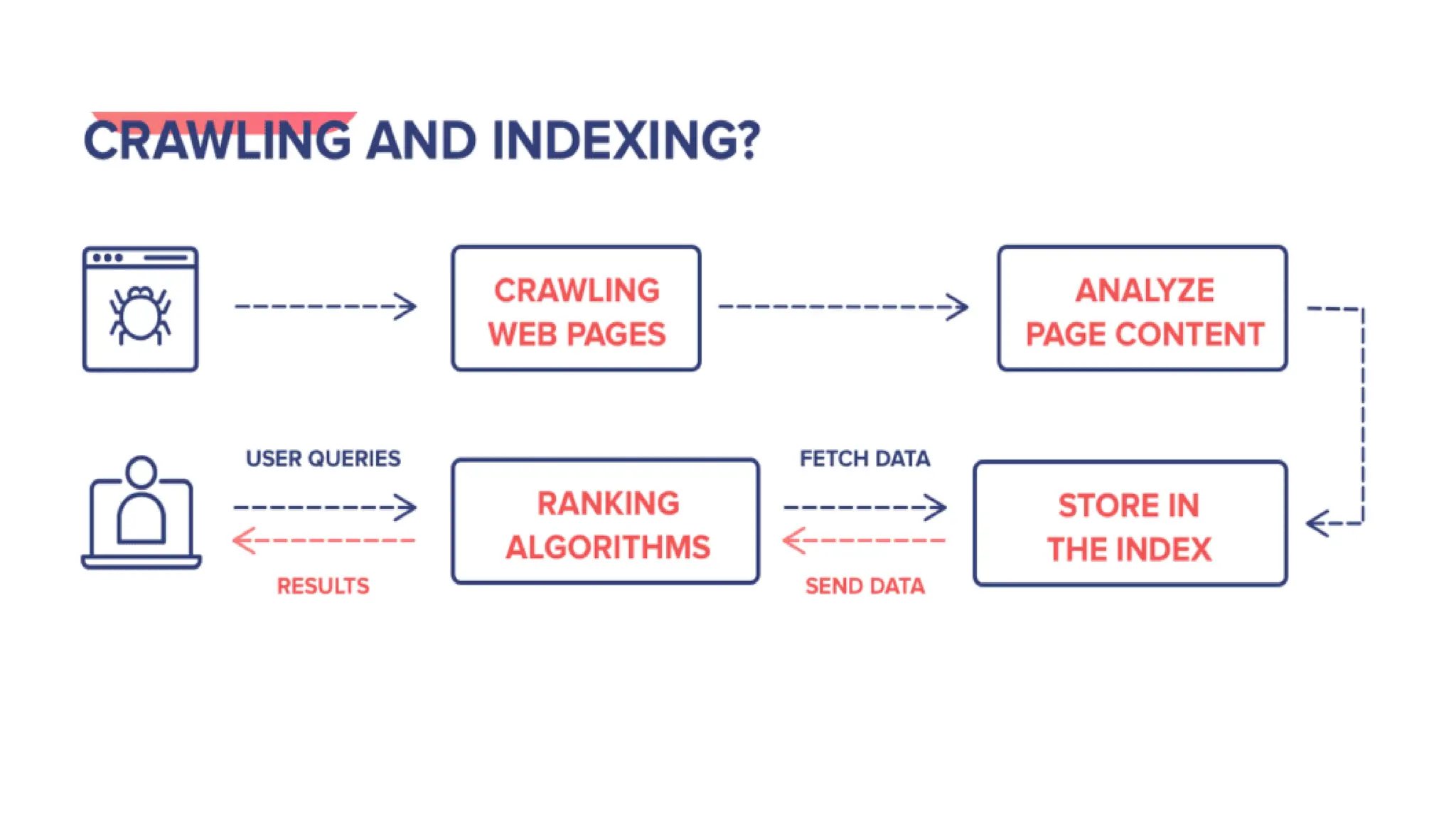
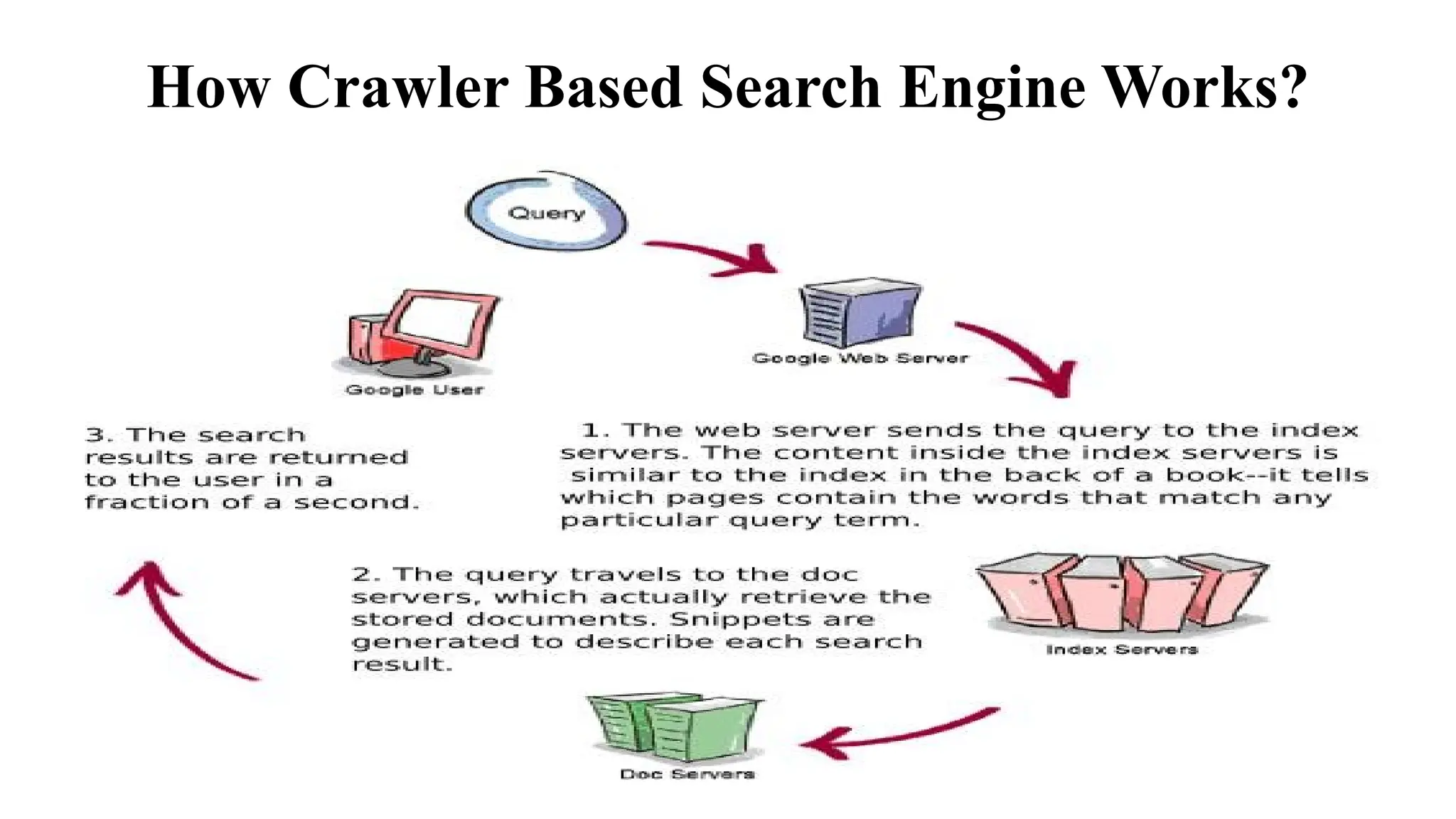
A web crawler, or spider, is a bot used by search engines to index web content by systematically browsing the internet. It gathers data from web pages, including titles, keywords, and links, enabling search engines to provide efficient search results. The document details the various types of crawlers, indexing processes, and the importance of search engine ranking and query processing.





























![Specialized Search Engines
Specialized search engines have been developed to cater for the demands of niche areas
(Specific areas). There are hundreds of specialized search engines, including:
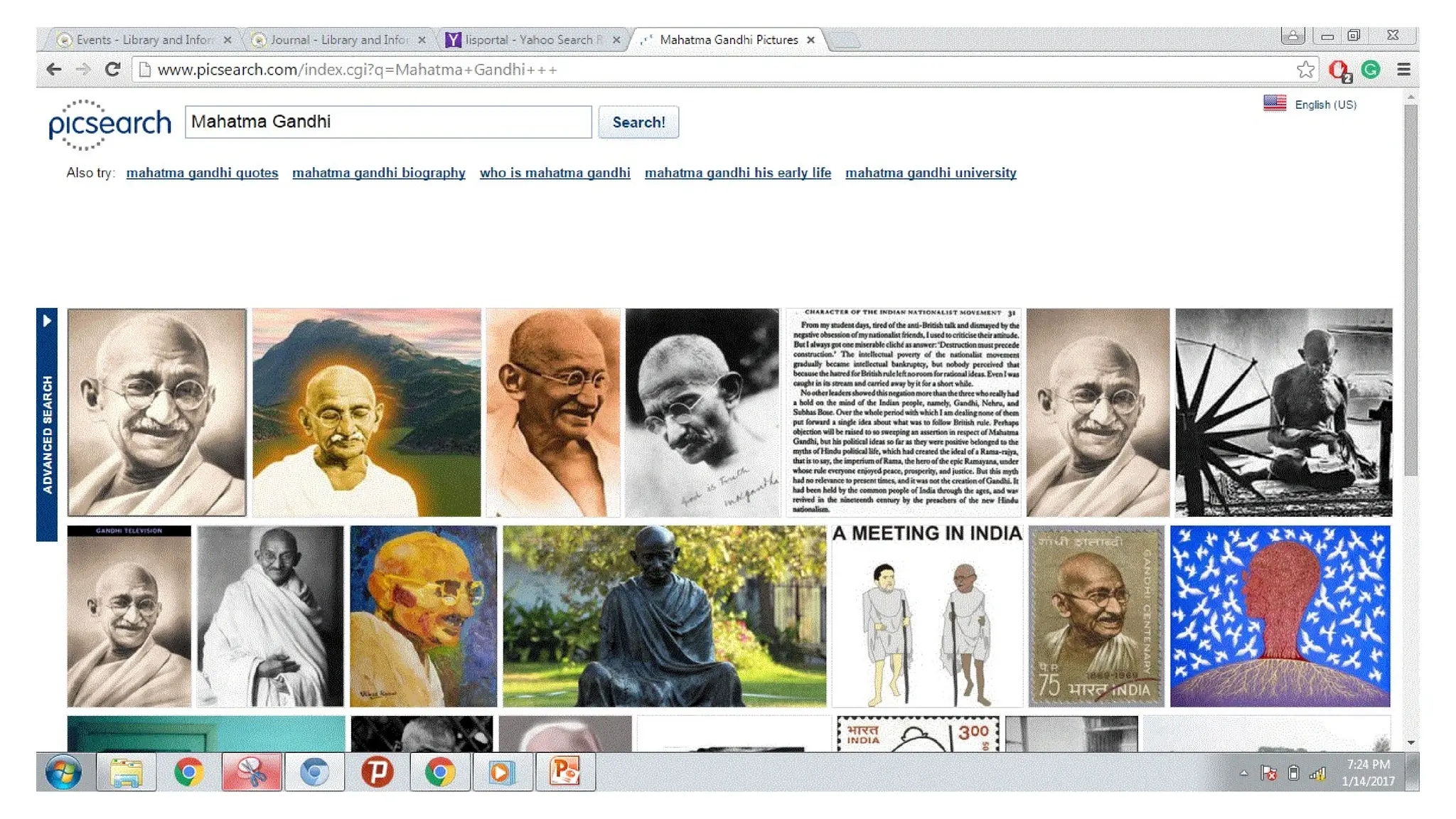
Images (PicSearch.com)
Shopping (shopping.yahoo.com)
Flights / Travel (SkyScanner.net)
Blogs (BlogPulse.com)
People (Pipl.com)
Forums (BoardReader.com)
Music (SongBoxx.com)
Audio & Video (PodScope.com, Blinkx.com)
Resources (FileDigg.com [.ppt and .pdf])
Private Search (DuckDuckGo.com)](https://image.slidesharecdn.com/crawlerindexranking-241221052037-5a6975a1/75/CRAWLER-INDEX-RANKING-AND-ITS-WORKING-pptx-36-2048.jpg)