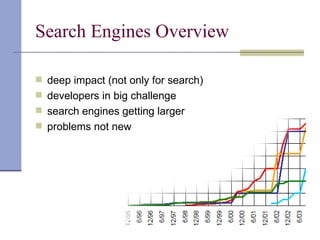
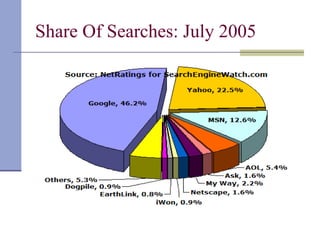
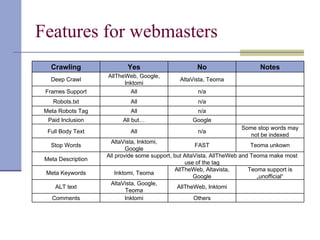
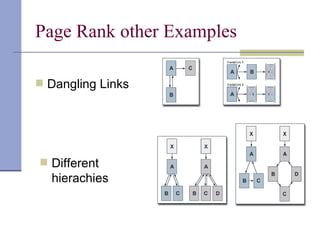
Downloaded 63 times













![Quality of an IR-System (1)
Precision:
Is the ratio of the relevant documents retrieved
to the total number of documents retrieved.
= [0;1]
Precision = 1: all retrieved documents are
relevant](https://image.slidesharecdn.com/suchmaschinen-120506053522-phpapp01/85/Introduction-into-Search-Engines-and-Information-Retrieval-16-320.jpg)
![Quality of an IR-System (2)
Recall:
Is the ratio of the number of relevant
documents retrieved to the total number of
relevant documents (retrieved and not).
= [0;1]
Recall = 1: all relevant documents were found](https://image.slidesharecdn.com/suchmaschinen-120506053522-phpapp01/85/Introduction-into-Search-Engines-and-Information-Retrieval-17-320.jpg)






























The document provides a comprehensive overview of search engines, focusing on their history, functioning, and the concept of information retrieval. It discusses the evolution of major search engines like Google and Yahoo, their strengths and weaknesses, and the models used for ranking and retrieving information. Additionally, it explores the challenges faced in refining search capabilities and the significance of concepts like PageRank and web mining.






















































































