Download as PDF, PPTX







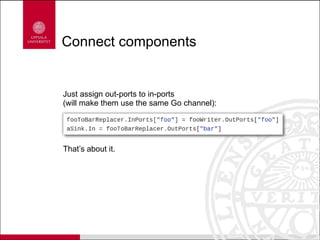






Scipipe is a lightweight workflow library inspired by flow-based programming, allowing for dynamic scheduling and efficient resource use with simple code maintenance. It supports writing workflows in Go, enabling easy execution and leveraging existing Go tools. Key features include high-performance components, easy extension, and a distinct architecture for processes and tasks.






















































































