Download as PDF, PPTX






















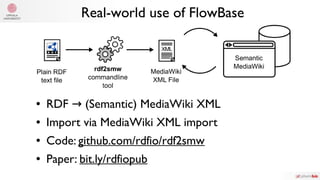
![Connecting dependencies with FlowBase
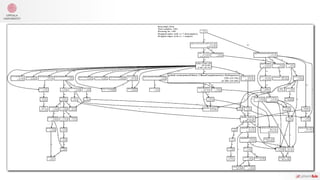
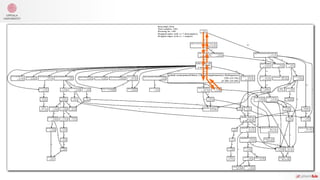
ttlFileRead.OutTriple = aggregator.In
aggregator.Out = indexCreator.In
indexCreator.Out = indexFanOut.In
indexFanOut.Out["serialize"] = indexToAggr.In
indexFanOut.Out["conv"] = triplesToWikiConverter.InIndex
indexToAggr.Out = triplesToWikiConverter.InAggregate
triplesToWikiConverter.OutPage = xmlCreator.InWikiPage
xmlCreator.OutTemplates = templateWriter.In
xmlCreator.OutProperties = propertyWriter.In
xmlCreator.OutPages = pageWriter.In
github.com/rdfio/rdf2smw/blob/e7e2b3/main.go#L100-L125](https://image.slidesharecdn.com/goconf20181006-181010144214/85/Using-Flow-based-programming-to-write-tools-and-workflows-for-Scientific-Computing-in-Go-29-320.jpg)


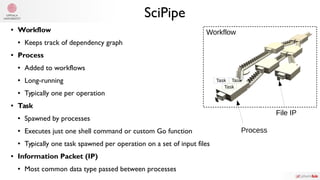






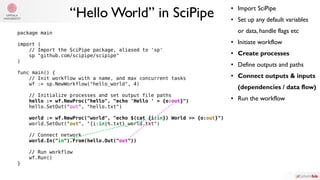





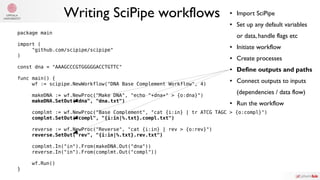


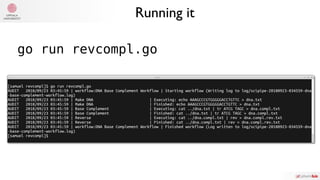
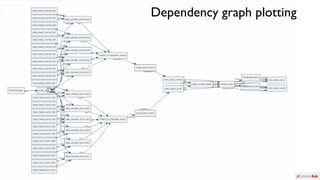






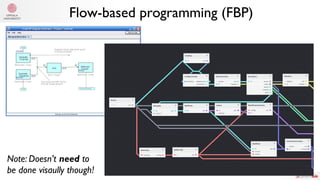
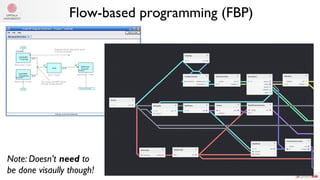
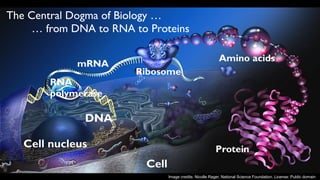
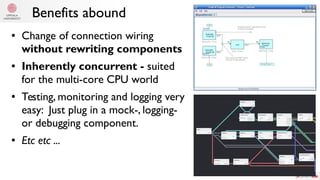
The document summarizes Samuel Lampa's talk on using flow-based programming for scientific computing. It provides biographical information on Samuel Lampa, including his background in pharmaceutical bioinformatics and current work. It then gives an overview of flow-based programming, describing it as using black box processes connected by data flows, with connections specified separately from processes. Benefits mentioned include easy testing, monitoring, and changing connections without rewriting components. Examples of using FBP in Go are also presented.


















































































