Download as PDF, PPTX







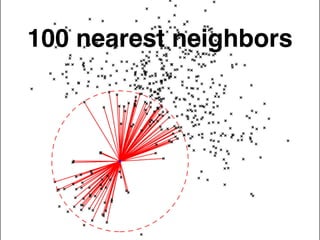




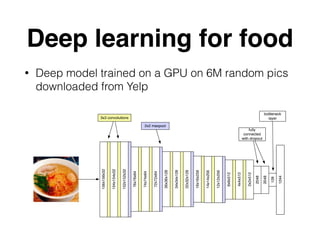





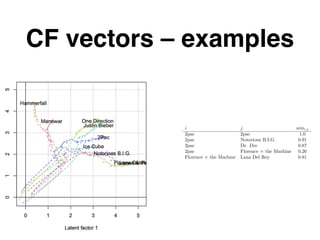




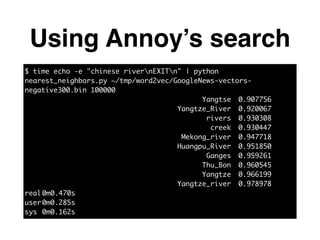
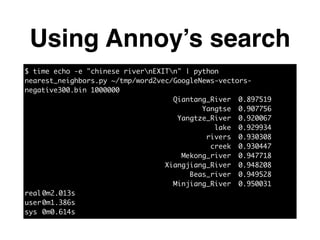
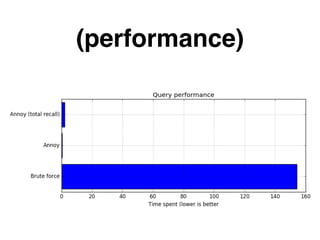







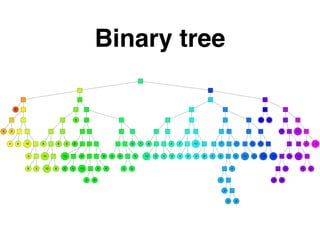

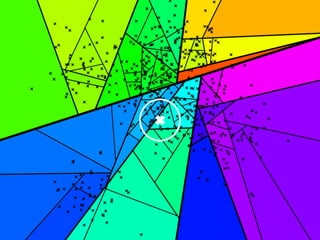
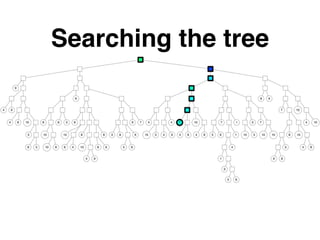
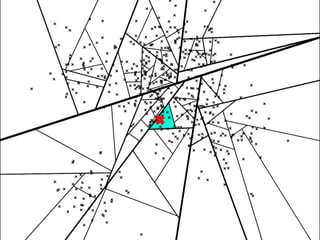

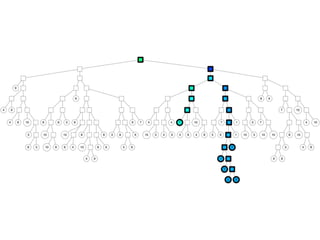
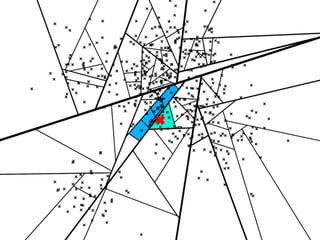



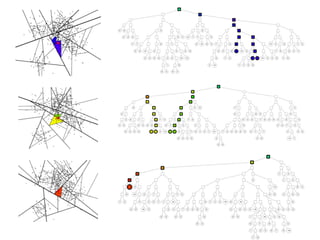







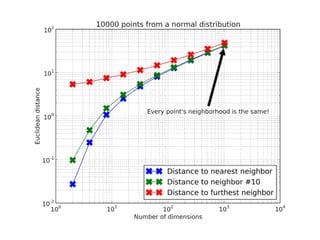


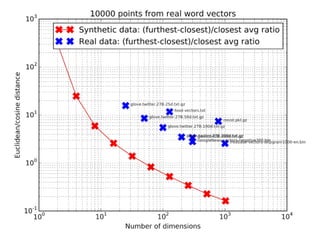
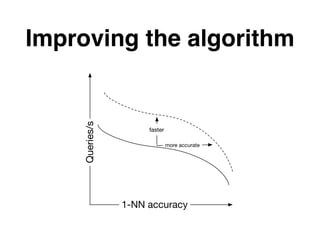
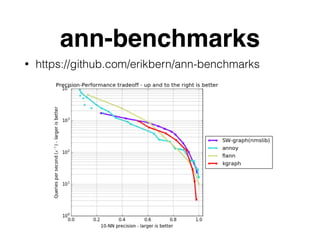
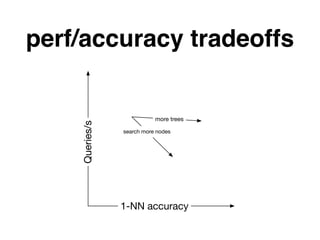






The document discusses approximate nearest neighbors and vector models, presenting their applications across various domains including language processing and computer vision. It introduces the Annoy library for efficient nearest neighbor searches and examines different vector methods for tasks such as collaborative filtering and text representation. Additionally, it highlights performance optimizations and future improvements for the algorithm.
























































![DataEngConf SF16 - BYOMQ: Why We [re]Built IronMQ](https://cdn.slidesharecdn.com/ss_thumbnails/byomq-160414230807-thumbnail.jpg?width=640&height=640&fit=bounds)






























