Downloaded 16 times




![© 2014 Aerospike. All rights reserved ‹#›
Prehistory: The RDBMS [continued]
■ 1974: Ingres prototype is open sourced and is worked on
by teams of students.
■ Includes the Quel query language.¹
■ After three years commercializing Ingres, Stonebraker returns to
UC Berkeley in 1985 and starts work on Postgres.²
■ 1984: An ex-Ingres team starts Sybase (first commercial
release in 1987).
■ Sybase includes the T-SQL query language.
■ Sybase cooperates with Microsoft which licenses its product,
rebranding it in 1992 as SQL Server.
■ 1985: Informix RDBMS includes the ISQL query engine.
■ 1995: Postgres replaces Quel with SQL closely mirroring
Oracle’s SQL. Renames to PostgreSQL.
■ 1996: An open-source RDBMS named MySQL is
released.](https://image.slidesharecdn.com/w9bi4yxmqna44bzep7qy-signature-8235525525d1d43a12aa477c66ddff2c3a639f8fc4b0c4a7448720f99f68dee0-poli-150213113437-conversion-gate02/85/That-ORM-is-Lying-to-You-4-320.jpg)

![© 2014 Aerospike. All rights reserved ‹#›
Here Come The Internets [continued]
■ Individuals, then startups use open-source tools.
■ Server-side scripting mostly done through the Common Gateway
Interface (CGI) using Perl.
■ 1997: PHP2/FI emerges as another popular CGI language, then as
a web server module (SAPI).
■ 1996: Java shows up, promising one language to rule
them all. jk, WORA, FTW¹
■ 1999: Java 1.2. A shadow falls on Greenwood. Marketing
call it: J2EE.](https://image.slidesharecdn.com/w9bi4yxmqna44bzep7qy-signature-8235525525d1d43a12aa477c66ddff2c3a639f8fc4b0c4a7448720f99f68dee0-poli-150213113437-conversion-gate02/85/That-ORM-is-Lying-to-You-6-320.jpg)











![© 2014 Aerospike. All rights reserved ‹#›
Ted Neward, 2006 [Updated 2012]
http://blogs.tedneward.com/2006/06/26/Th
e+Vietnam+Of+Computer+Science.aspx
“Object-Relational Mapping is the Vietnam of Computer
Science”](https://image.slidesharecdn.com/w9bi4yxmqna44bzep7qy-signature-8235525525d1d43a12aa477c66ddff2c3a639f8fc4b0c4a7448720f99f68dee0-poli-150213113437-conversion-gate02/85/That-ORM-is-Lying-to-You-18-320.jpg)


![© 2014 Aerospike. All rights reserved ‹#›
Do You Really Need an RDBMS? [continued]
■ Normalization kills web applications.¹
■ The goal in the 70s and 80s when normalization was formalized by
Codd and Boyce was for the data to be as small as possible.
■ The goal since the late 90s and web applications is speed.
■ No web application that is open to a global audience via
desktop and mobile apps is even in third normal form.²
■ Web applications quickly devolve to lower forms of normalization
(denormalization).
■ RESTful APIs are a particular example of modeling for the internet
age which is essentially single-table access.
http://example.com/api/:resource/:id](https://image.slidesharecdn.com/w9bi4yxmqna44bzep7qy-signature-8235525525d1d43a12aa477c66ddff2c3a639f8fc4b0c4a7448720f99f68dee0-poli-150213113437-conversion-gate02/85/That-ORM-is-Lying-to-You-21-320.jpg)



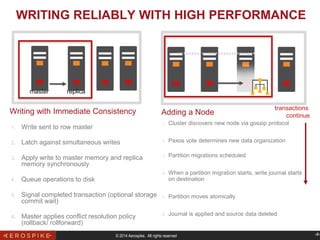
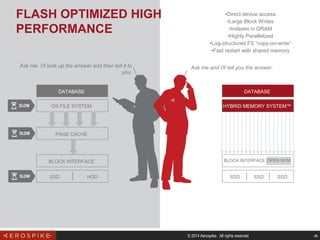
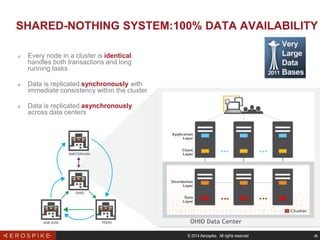


The document discusses the evolution of relational database management systems (RDBMS) and the challenges associated with Object-Relational Mapping (ORM). It highlights that while ORMs can reduce boilerplate code, they can also introduce inefficiencies and misalign with the underlying database characteristics, leading to performance issues. The author argues for a re-evaluation of whether an RDBMS is the right choice for modern applications, suggesting that key-value stores may be more suitable for web applications.



































































