Download to read offline


























![31
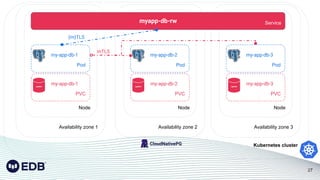
Install a Postgres cluster
apiVersion:
postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: myapp-db
spec:
instances: 3
[...]
storage:
size: 50Gi
walStorage:
size: 5Gi
Example with
WAL volume](https://image.slidesharecdn.com/dok152-runningpostgresqlinkubernetesfromday0today2withcloudnativepg-220928092517-f44df73d/85/Running-PostgreSQL-in-Kubernetes-from-day-0-to-day-2-with-CloudNativePG-DoK-152-31-320.jpg)






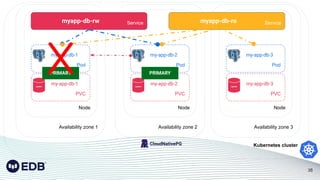







The document discusses the challenges and considerations of running PostgreSQL databases in a Kubernetes environment, emphasizing the importance of appropriate infrastructure planning from initial setup to operations. It introduces CloudNativePG, an open-source Kubernetes operator that automates database management tasks, and outlines best practices for installation, monitoring, and backup processes within Kubernetes. Additionally, it highlights future enhancements and the evolving role of DBAs in DevOps settings, advocating for proactive database management from day zero.























































































