Overcoming challenges with protecting and migrating data in multi-cloud K8s environments - DoK Talks #149

Link: https://youtu.be/EFaRyl4HmmE https://go.dok.community/slack https://dok.community/ ABSTRACT OF THE TALK If you are running or planning a multi-cloud or even a multi-cluster environment, there are several considerations in implementing a data protection solution – especially if you plan on an organic home-grown, do-it-yourself option. This talk will highlight challenges and best practices around centralized management of configuration, credentials, compliance across multiple accounts, regions, providers etc. We will also highlight the deviations in CSI driver implementations of various storage vendors and cloud providers. Finally, we will cover the various recovery options available in the market today. Kubernetes cloud services are popular since they mitigate, but do not eliminate, the difficulties of operating a Kubernetes environment. This is especially true for protecting the stateful configuration and data of your Kubernetes applications, where the inherent high-availability and infrastructure as code are not a substitute for have cloud-native backup and disaster recovery capabilities. Further, many companies now have multi-cloud strategies for their cloud-native applications. These challenges can be addressed with backup applications that are both Kubernetes managed service and multi-cloud aware in order to snapshot, copy, restore, and migrate Kubernetes workloads (resources and data) running on AKS, EKS and GKE. Capturing information from cloud accounts and how the cluster and storage resources are configured allows 1) centralized visibility into all cloud accounts and the clusters and resources in the accounts including for compliance; 2) cross-account, cross-cluster, and cross-region data restores; 3) automation of the cluster and data restores including for Dev, Test, and Production recovery use cases. BIO Sebastian Glab is a Cloud Architect for CloudCasa and he resides in Poland. He is responsible for integrating the different cloud providers with the CloudCasa service, and making sure that all clusters in the cloud service get discovered and protected. In his free time, he plays volleyball and develops his own projects. Martin Phan is the Field CTO in North America for CloudCasa by Catalogic Software. With over 20+ years of experience in the software-industry, he takes pride in supporting, developing, implementing, and selling enterprise software and data protection solutions to help customer solve their backup and recovery challenges. KEY TAKE-AWAYS FROM THE TALK 1) Challenges and best practices around centralized management of configuration, credentials, compliance across multiple accounts, regions, providers etc. 2) Advantages of cloud awareness and Kubernetes managed service awareness for application and data recovery and security 3) Examples of overcoming Container Storage Interface (CSI) deviations 4) Various recovery options available in the market today.

Recommended
Recommended
More Related Content
More from DoKC
More from DoKC (20)
Overcoming challenges with protecting and migrating data in multi-cloud K8s environments - DoK Talks #149
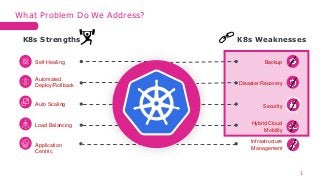
- 1. Self-Healing Automated Deploy/Rollback Auto Scaling Load Balancing Application Centric Backup Disaster Recovery Infrastructure Management Hybrid Cloud Mobility K8s Strengths K8s Weaknesses Security What Problem Do We Address? 1
- 2. Go No Go Decision Template $ 0.10/hr Pay-as-you-go: Standard costs of node VMsand otherresources $ 0.10/hr 2018 2018 2015 Cloud Formation Stack AzureResource Manager Auto-Pilot /Standard Window EBS / CSI AzureDisk /AzureFile (CSI) GCE PersistentDisk / CSI … … … … … … ManagedKubernetes- Comparison AmazonEKS AzureAKS GoogleCloudGKE
- 3. • Kubernetes Data Landscape / Adoption • Users should be free to adopt and use whatever Kubernetes managed services that best suits their requirements • Storage Providers / Classes • Users should be free to adopt whatever persistent storage volume classes and protect data without overthinking the migration of moving between infrastructure • Different storage classes • Azure Block / Azure File • Amazon EBS / CSI • Google Compute Engine Persistent Disk Agnostic Approach 3
- 4. • https://kubernetes- csi.github.io/docs/drivers.html Supported Capabilities of Current CSI Drivers 4 Supported Capabilities of Current CSI Drivers
- 5. An Interesting Case Of Azure File CSI Driver 5 • https://docs.microsoft.com/en-us/azure/aks/azure-files-csi
- 6. Find some more details about automated restore 6 • https://cloudcasa.io/blog/automating-azure-files-restore-in-aks/
- 7. Cross-cluster and Cross-cloud Migrations Challenges 7 Reasons: • Reduce workload on existing cluster by moving some of the workload to another cluster • Clone the environment for testing purposes • Migrate to different data center or cloud Challenges • Storage and network isolation • Different storage options for each cloud provider • No native Kubernetes support for operations such as copying or data migration Tools: • Velero and Restic • CloudCasa by Catalogic Software
- 8. • Infrastructure – installs on the cluster • Cloud Credentials requirement to talk to cluster • Setup differs for each cloud provider • No central logging and storage credentials management • There is no one place to manage all clusters • Works if you have a handful of clusters – but leaves a lot to be desired when talking about Kubernetes scale Challenges with Velero 8
- 9. Issues With Restic 9 • Poor restore speed "Restic incremental restore speed continued to be extremely slow because 1 and sometimes 2 Restic threads are using 100% CPU/ Only 15 GB was restored in 16 hours at 0.25 MB/s [..] it will take 2 months to restore 1.5 TB." • Performed poorly with parallelism • Performed poorly with small and large files Alternatives • Kopia • Borg (BorgBackup)
- 10. • Leveraging data copies for more than just insurance policies • Spin up a cluster from scratch (vs. having a standby cluster ready and available waiting to receive data) • Automating restore processes • Migrate between managed Kubernetes service providers (cloud, on- prem) • Restore with production data / customizations • Remap storage / namespaces • Cross cluster (on-prem / cloud) 10 Restoring from Backup
- 11. Cluster Recoveries 11 • Protect your data but also your infrastructure • Integrate with different cloud providers without unnecessary credentials management
- 12. Keep You Backup Data Private 11 • Bring Your Own Storage • Keep our data isolated from the public Internet with Private Link Azure Private Link • Reduces exposure to brute force and DDoS attacks • Azure Private Link enables user to access Azure Services over a private endpoint in a virtual network
- 13. Did you know about Azure Private Link? You can backup your data to S3 without traversing the Internet. 13 Azure Private Link Public Internet Data Transfer Azure Private Link allows you to provide private connectivity between your clusters and Storage, without exposing your traffic to the public internet. Data Leakage is a common concern in using SaaS services, but Azure Private Links shut the door on exfiltration. Trusted worldwide by large organizations such as Discover, Salesforce, Autodesk and Goldman Sachs. Private Endpoints are supported by CloudCasa to direct backup traffic to your Azure Blob Storage through this service Local Proxy AKS Cluster is used to route all S3 bucket and storage management operations privately.
- 14. Maintain at least 3copies of yourdata 3 2 1 Keep 2 copies on different media Store at least 1 copy at an off-site location, ideally air-gapped 1 verified copy for recovery 3-2-1-1 Ransomware ProtectionRule 14
- 15. Centralized Management, Cross-Platform and Composable Recoveries Think about RTO and Compliance 15 One step onboarding of all clusters Never miss a new cluster Multi-cluster and multi- cloud Auto Discovery and Compliance Backup your AKS/EKS cluster configuration Over 40 configuration properties collected Run security scans on your clusters Cloud-Aware Config. Protection Backup to another region, cloud or account One-click, tamper proof SafeLock on your backups Cross-Region Compliance Create an AKS or EKS cluster on the fly No need to maintain a standby cluster Recovery Through Code
- 16. 50+ CSI DRIVERS Managed Storage CSI Snapshots Choice of 20+ Regions BYO Storage Cloud-Aware Backup-as-a-Service for Kubernetes And more… In the Cloud On-Premises Self Service Backup & Recovery Multi-Cluster and Multi-Cloud Centralized Discovery & Mgmt Proactive Security Scans Tamper-Proof Backups Cross Region & Cloud Resilience App-Aware Templates 16
- 18. Discovery from Cloud Accounts 18
- 19. 19 Discovery from Cloud Accounts
Editor's Notes
- Not have all eggs in one basket Differences to be aware of, role in what you choose Orienting the rest of these 3 platforms, multi-cloud neutral to multi-cloud environments Integration into cloud providers. All the challenges we solve X% of Kubernetes users are running in Cloud, gist of what we want to communicate in the slide. Everyone has so many different accounts
- Want to choose a data protection scheme that doesn’t vendor lock you in to doing data protection a certain way Amazon snapshots Azure snapshots on block/file storage CSI snapshots on prem storage Security concerns (discussion from Sebastian, one per cluster, service account/custom role, bind to one project; GKE (organization-project-cluster, repeat) Discovered cloud agnostic approach allows customer to choose the best managed service to suit their requirements Auto-discovery of all clusters - native cloud services integration Cloud Formation Stack, Azure Resource Manager Easy automated deployment for on-prem. Deploy an agent Manage everything the same way from the Cloud We have multiple cloud accounts in each of these providers, customer is storing their data into each of these platforms. Inventorying is first big problem Cloud Accounts – no idea how many clusters in an environment of that size. Everything created by code, large ISP with 100+ cloud accounts (Concurrency – 30 down to 4 minutes, ) What would it take to perform Velero backup in one cluster. Management Octeto talking In addition to maintaining infrastructure, other concerns you would need to be aware of when using a basic toolset. (streamline processes from an end-user perspective)
- Every single Velero install at a cluster level. Cloud credentials in order to talk to Cloud storage Cloud connectivity separately Manage schedule and everything separately. 200 times for 200 clusters. No policy to distribute to all clusters. No centralized monitoring / management, simple agent that runs on CLI, no management plane across, but do this every single cluster. And even if you automate there is no centralized management. Works great if you have a handful of clusters. Just not something that scales with Kuberenetes. Open Source Options Scripting backups and restores Deployment concerns (Charter anecdote here) …How many clusters do you have and manage? Centralized management
- Every single Velero install at a cluster level. Cloud credentials in order to talk to Cloud storage Cloud connectivity separately Manage schedule and everything separately. 200 times for 200 clusters. No policy to distribute to all clusters. No centralized monitoring / management, simple agent that runs on CLI, no management plane across, but do this every single cluster. And even if you automate there is no centralized management. Works great if you have a handful of clusters. Just not something that scales with Kuberenetes. Open Source Options Scripting backups and restores Deployment concerns (Charter anecdote here) …How many clusters do you have and manage? Centralized management
- Every single Velero install at a cluster level. Cloud credentials in order to talk to Cloud storage Cloud connectivity separately Manage schedule and everything separately. 200 times for 200 clusters. No policy to distribute to all clusters. No centralized monitoring / management, simple agent that runs on CLI, no management plane across, but do this every single cluster. And even if you automate there is no centralized management. Works great if you have a handful of clusters. Just not something that scales with Kuberenetes. Open Source Options Scripting backups and restores Deployment concerns (Charter anecdote here) …How many clusters do you have and manage? Centralized management
- Working with account – how many clusters (?), how many accounts?
- Where is the snapshot? Local to storage copied to a separate location? What will it take to restore the snapshot? Infrastructure requirements,
- Mention Proxy servers here in this slide
- 3-2-1 rule is critical when considering backup solutions for recovering from ransomware DPX can provide you at least three (3) copies of your data, on two (2) different storage media types, with one (1) airgapped copy offsite or in the cloud. One copy on vStor stored in immutable snapshots One copy replicated using vStor replication technology One airgapped copy in the cloud or on tape. When ransomware hits, they attempt to also remove all backups that one must pay to get the data back With at least 2 copies one in immutable snapshots and one-off site you rest easy that the data can be recovered
- AWS inventory, concurrency 30 minutes inventory to 4 minutes. EKS offers no backups, AKS offers preview mode (what does GKE support) 3-2-1 rule in play. Option today is Restic a bit of the pain and Velero now promoting Kopia (each vendor write your own data mover). Velero creating a pluggable data mover for upcoming releases (Sebastian) Performed very poorly with lot of small files (and large files) (Sebastian) Performed poorly with parallelism (which is why we ended up using Kopia)
- Let’s face it, backups are a necessary evil… no one wants to do backups, but need to do backups Snapshot or Backup (Copy) Automate the backup environment (Sebastian – REST API, Automation, CICD pipelines (don’t have access to the UI) (Screenshot documentation / swagger / example / api-docs) BYOS – where to backup to Isolated environments that cannot speak to the Internet (Sebastian, private links, Azure/AWS, does not traverse internet)