Download as PDF, PPTX








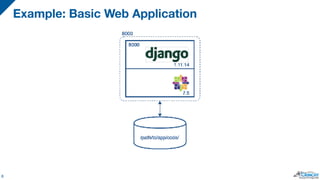
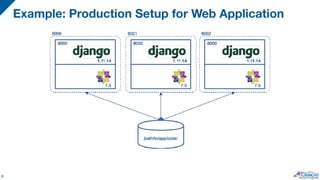
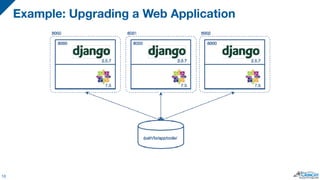



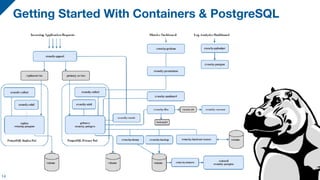



















The document discusses the integration of PostgreSQL with Docker and Kubernetes, highlighting the advantages and challenges of containerization for database management. It covers setup procedures, the use of Crunchy Data's container suite for PostgreSQL, and describes how Kubernetes can aid in orchestrating these containers for scalability and management. Ultimately, it emphasizes the benefits of containerized environments and the potential for automating database tasks through operators.














































































