Download to read offline




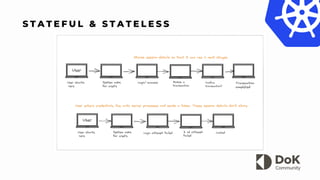





The document discusses the difference between stateful and stateless applications, highlighting how stateful services track sessions while stateless services do not. It introduces StatefulSets as an API object used to manage stateful applications, providing guarantees about pod ordering and uniqueness. Additionally, it outlines the limitations of traditional deployments regarding pod management and identity.