Downloaded 10 times


















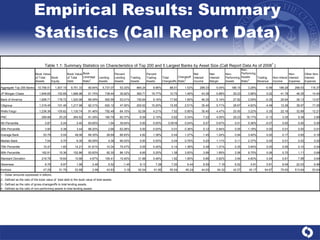
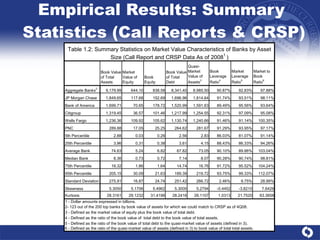
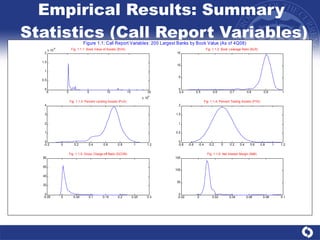
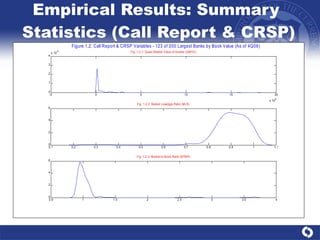
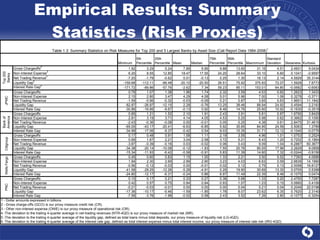
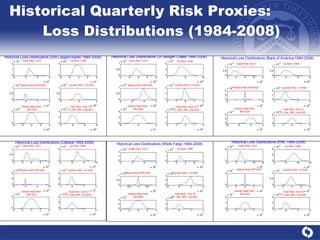
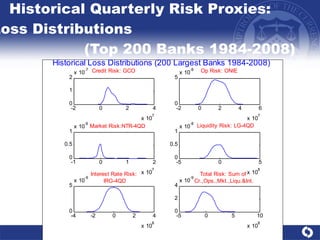
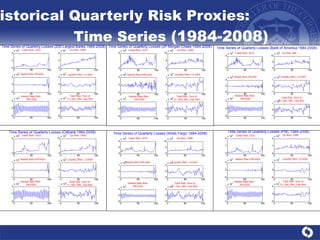
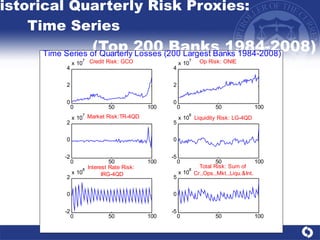
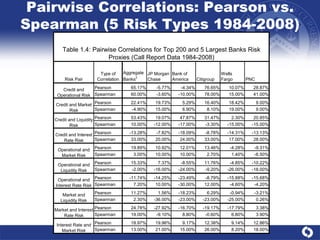
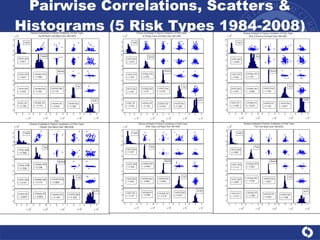
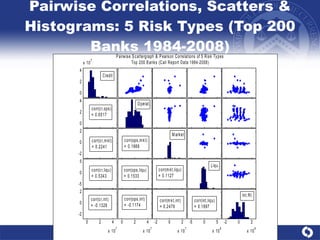


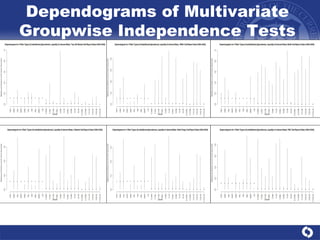
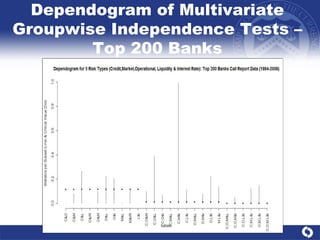
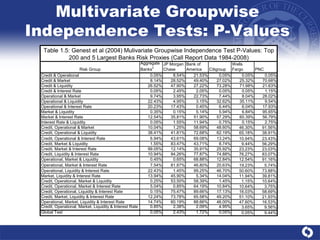
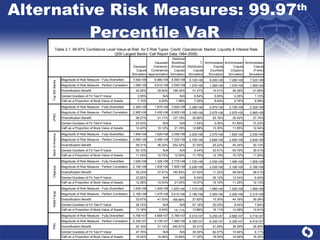
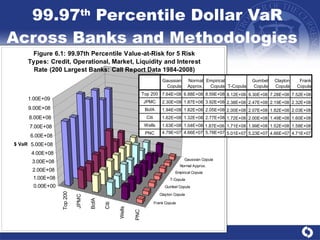
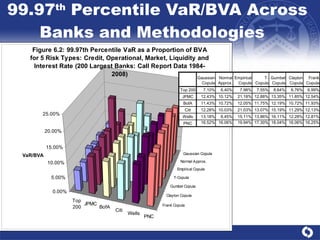
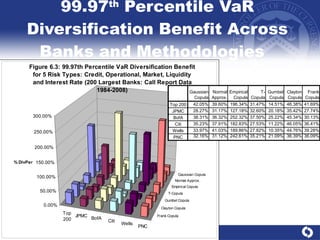
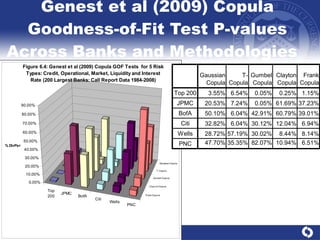

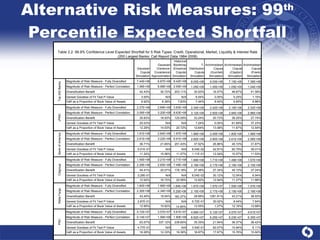
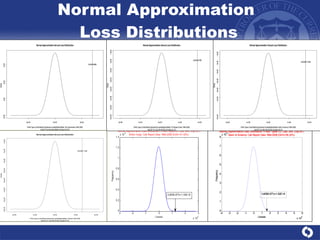
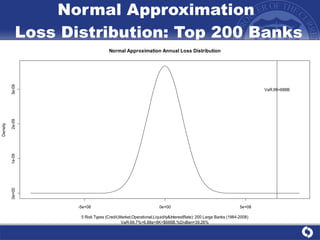
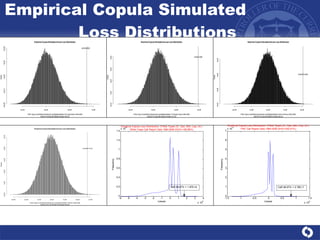
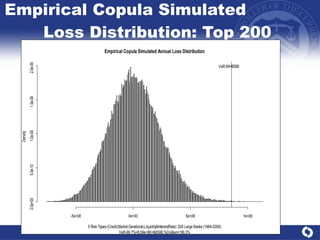
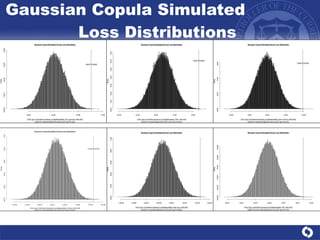
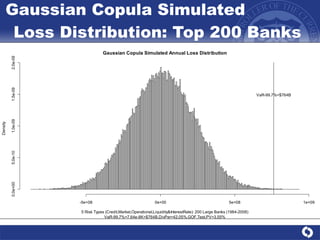
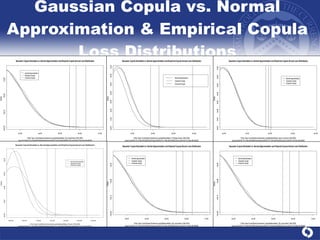
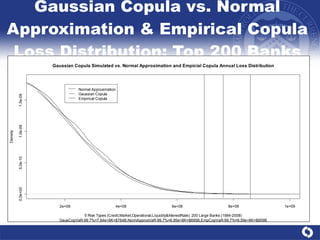
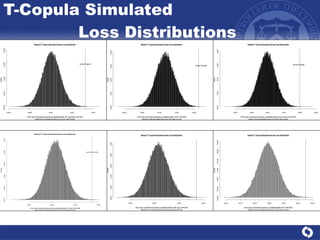
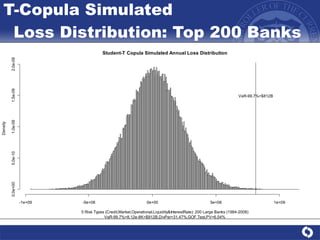
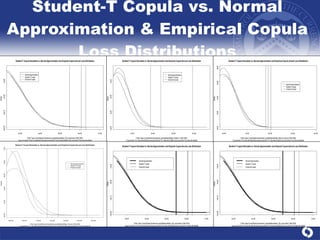
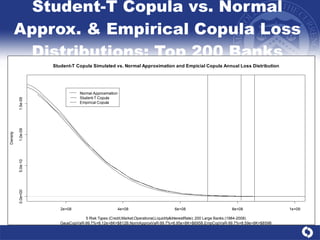
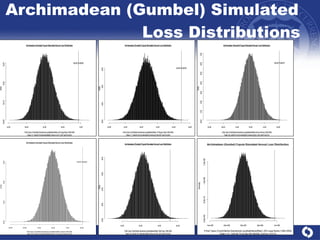
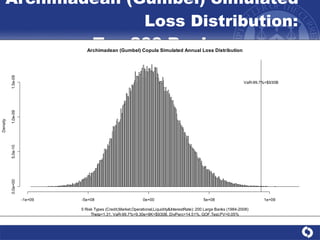
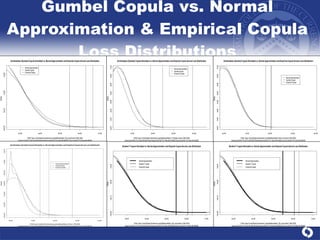
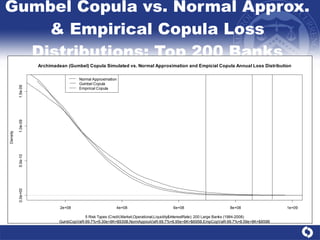
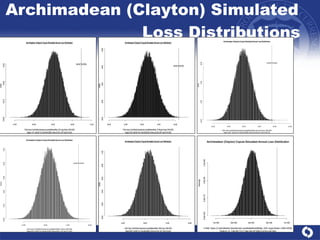
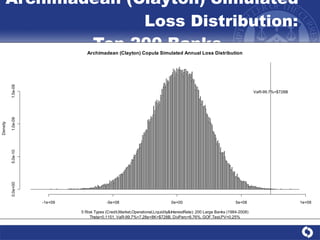
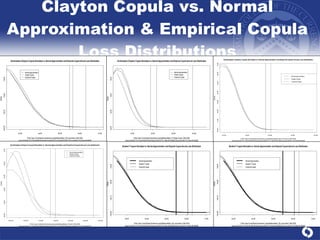
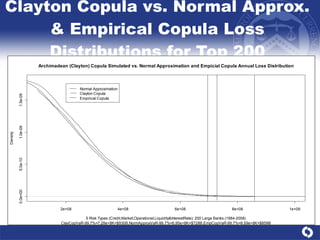
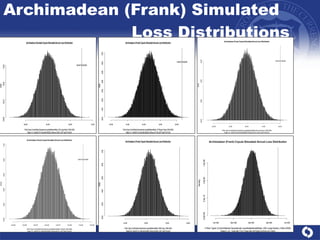
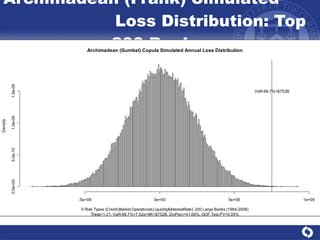
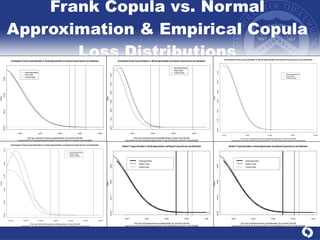
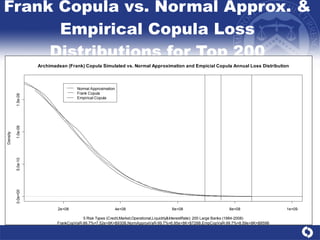
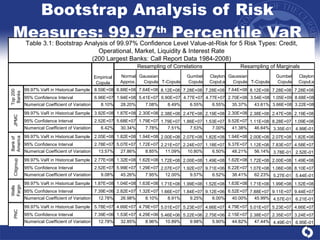
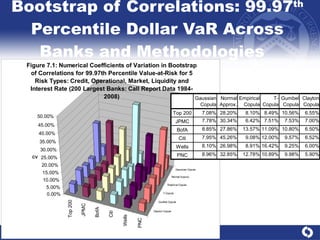
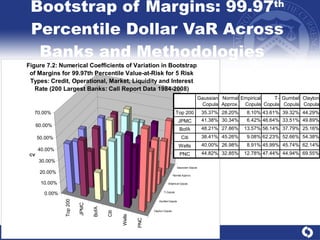
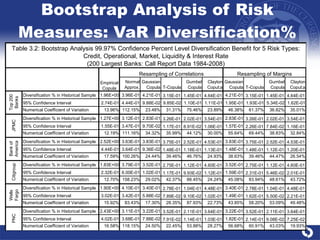
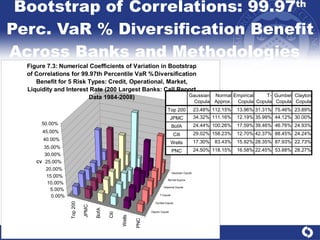
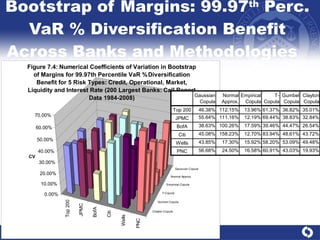

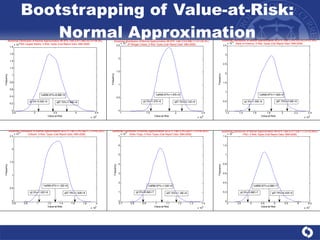
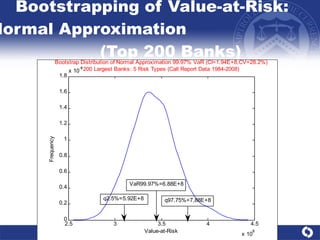
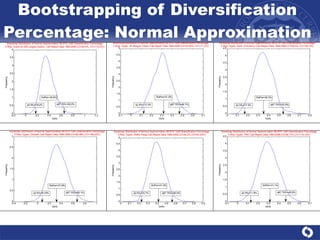
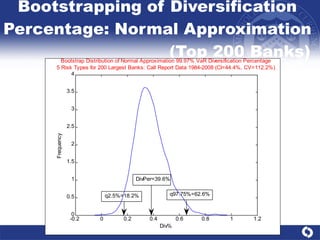
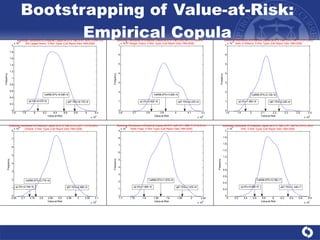
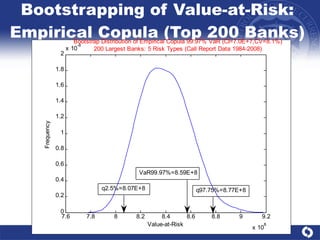
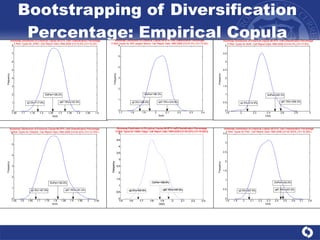
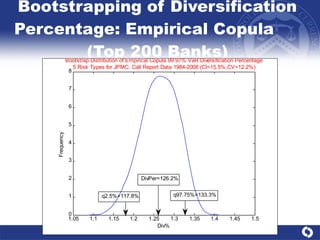
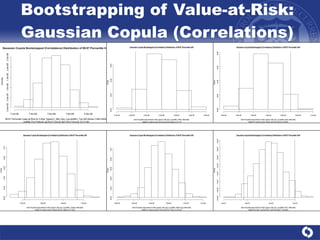
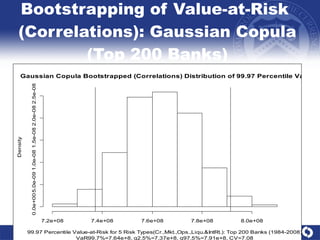
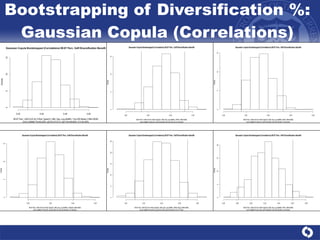
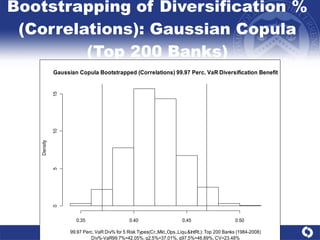
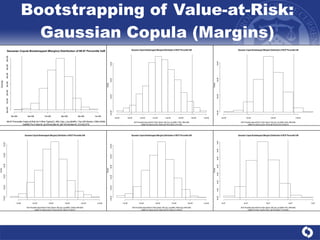
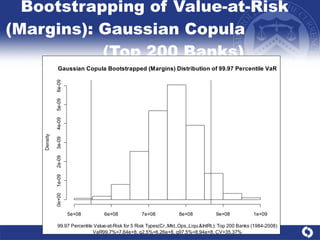
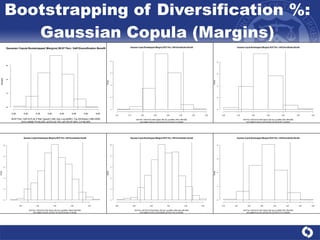
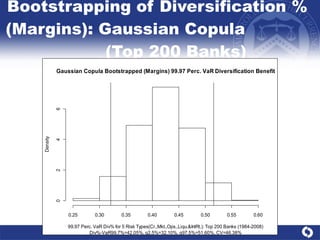
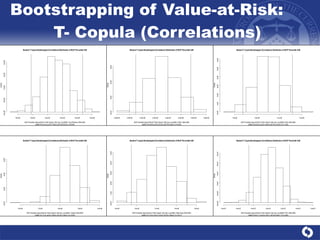
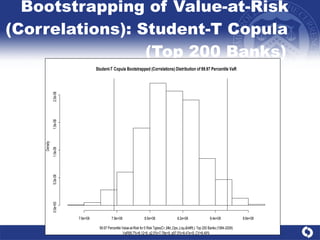
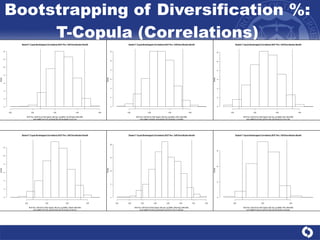
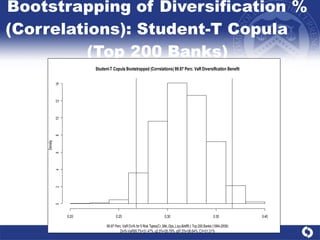
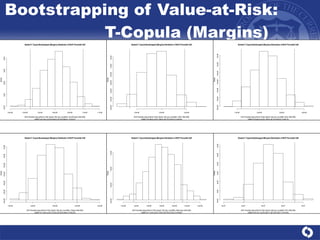
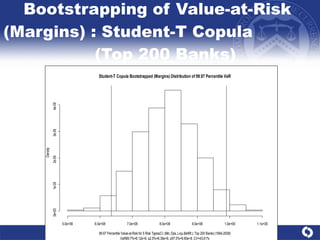
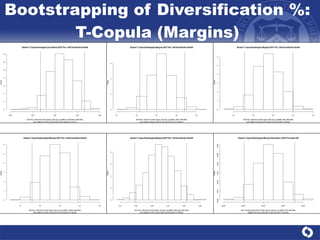
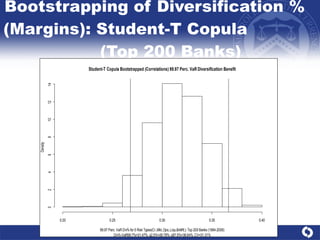
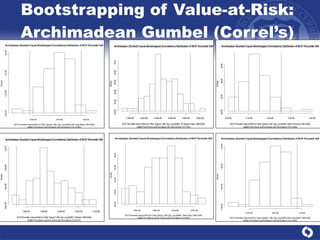
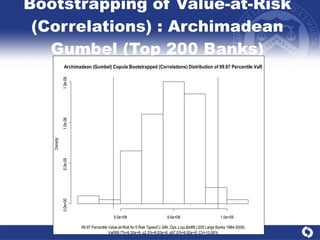
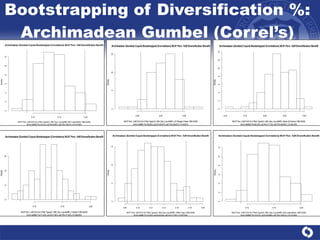
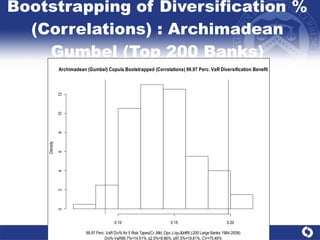
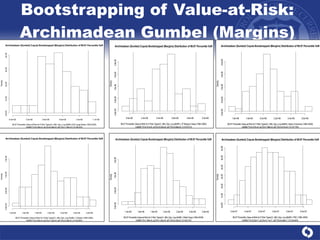
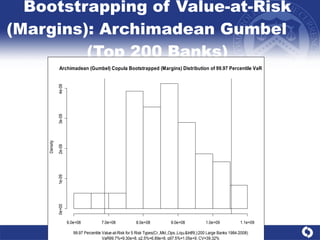
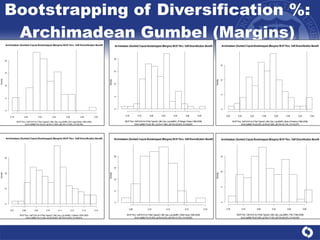
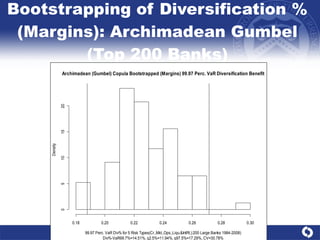
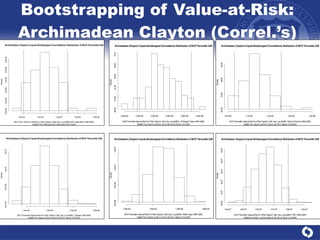
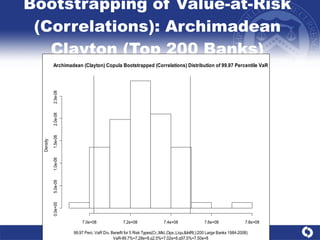
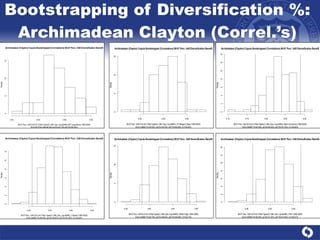
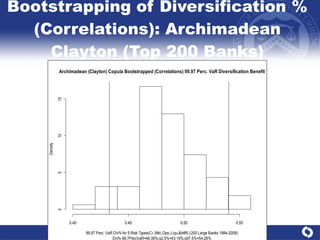
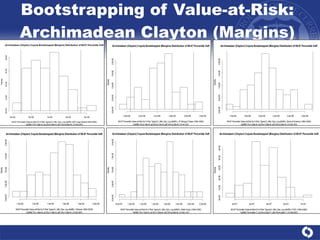
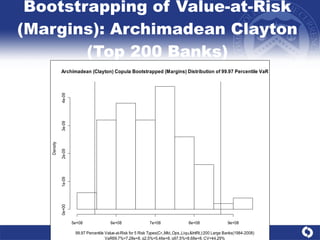
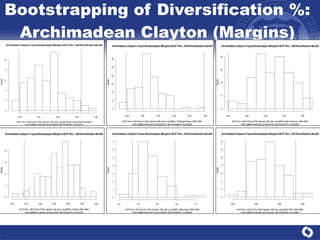
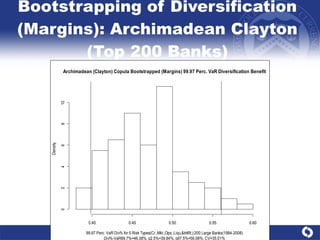



The document summarizes a study on modeling risk aggregation and sensitivity analysis for economic capital at banks. It finds that different risk aggregation methodologies, such as historical bootstrap, normal approximation, and copula models, produce significantly different economic capital estimates ranging from 10% to 60% differences. The empirical copula approach tends to be the most conservative while normal approximation is the least conservative. The results indicate banks should take a conservative approach to quantify integrated risk and consider the impact of methodology choice and parameter uncertainty on economic capital estimates.











































































![Lgd Model Jacobs 10 10 V2[1]](https://cdn.slidesharecdn.com/ss_thumbnails/lgdmodeljacobs1010v21-12872530142448-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





