Download as PDF, PPTX

![Research data management [RDM]
what #1
Essence of RDM: “… tracking back to what you did 7
years ago and recovering it (...) immediately in a re-
usable manner.” (Henry Rzepa)](https://image.slidesharecdn.com/0hv90rdm2017-11-22-171123112215/85/Research-data-management-course-0HV90-Behavioral-Research-Methods-2-320.jpg)
![Research data management [RDM]
what #2
RDM: caring for your data with the purpose to:
1. protect their mere existence: data loss, data authenticity
(RDM basics)
2. share them with others
a. for reasons of reuse: in the same context or in a different context; during
research and after research
b. for reasons of reproducibility checks scientific integrity; data quality
RDM = good data practices that make your data easy to work with,
understandable, and available to other scientists](https://image.slidesharecdn.com/0hv90rdm2017-11-22-171123112215/85/Research-data-management-course-0HV90-Behavioral-Research-Methods-3-320.jpg)
![Source: Research Data
Netherlands / Marina
Noordegraaf
Outline
1. Research data management [RDM]: what and why
2. Sharing your data, or making your data findable and accessible
a. data protection: back up, file naming, organizing data
b. data sharing: via collaboration platforms, data archives
3. Caring for your data, or making your data usable and interoperable
a. tidy data
b. metadata/documentation
c. licenses
d. open data formats](https://image.slidesharecdn.com/0hv90rdm2017-11-22-171123112215/85/Research-data-management-course-0HV90-Behavioral-Research-Methods-4-320.jpg)




















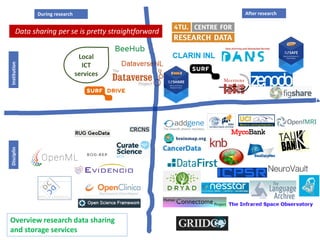

![General data sharing platforms:
SURFdrive [TU/e only]: Dutch academic Dropbox, 250 Gb,
maximum data transfer 16 Gb
Students can request a SURFdrive account
Google Drive, Dropbox: don’t use these to store sensitive data
Sharing your data
during your research: general data sharing platforms](https://image.slidesharecdn.com/0hv90rdm2017-11-22-171123112215/85/Research-data-management-course-0HV90-Behavioral-Research-Methods-27-320.jpg)
![DataverseNL [TU/e only]: data sharing platform for active
research data [based on Harvard’s Dataverse Project] where you
may:
store your data in an organized
and safe way
clearly describe your data
version control of your data
arrange access to your data
Sharing your data
during your research: DataverseNL
Students may use DataverseNL
Go to: https://dataverse.nl/
Click ‘Log in’ (at the top right); under Institutional
account click SURFconext
Select Eindhoven University of Technology and log
on with your TU/e username and password
When asked for it, give permission to share your
data by answering Yes or click this Tab
When asked to create an account, answer Yes or
click this Tab.
When you succeeded to create an account, your
username is the prefix of your email address
Click 4TU dataverse Eindhoven dataverse Add
data: you can now create and publish data sets,
upload files and assign access rights to data sets or
files.](https://image.slidesharecdn.com/0hv90rdm2017-11-22-171123112215/85/Research-data-management-course-0HV90-Behavioral-Research-Methods-28-320.jpg)


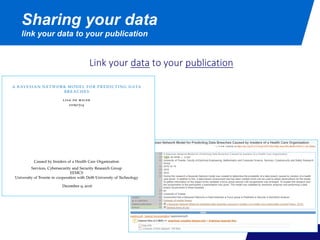
![Choose a repository where other researchers in your discipline are sharing
their data
If not available, use a multidisciplinary or general repository that at least
assigns a persistent identifier to your data (DOI) and requires that you provide
adequate metadata
for example Zenodo, Figshare, DANS, B2SHARE, or;
4TU.ResearchData
+ DOI’s [ persistent identifier for citability and retrievability ]
+ open access
+ long-term availability, Data Seal of Approval
+ self-upload (single data sets < 3Gb)
Sharing your data
after your research has ended, via an archive or repository](https://image.slidesharecdn.com/0hv90rdm2017-11-22-171123112215/85/Research-data-management-course-0HV90-Behavioral-Research-Methods-31-320.jpg)















![Data Coach [website]
Online course with web lectures
Support](https://image.slidesharecdn.com/0hv90rdm2017-11-22-171123112215/85/Research-data-management-course-0HV90-Behavioral-Research-Methods-50-320.jpg)

The document discusses the importance of Research Data Management (RDM), emphasizing its role in protecting data integrity, facilitating sharing for reuse and reproducibility, and promoting scientific integrity. It outlines best practices for managing data, including organization, file naming, and documentation, as well as the rationale for sharing data during and after research. Additionally, it covers data storage solutions and platforms for effective data sharing within the research community.





































![Research data management : [part of] PROOF course Finding and controlling sci...](https://cdn.slidesharecdn.com/ss_thumbnails/proofrdm19-11-2014-141119054859-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)



































![[DSC Europe 25] Josip Saban - Career building for data professionals.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/zroflcttkm1vmli0txea-josip-saban-career-building-for-data-professionals-260123083019-587cdb8c-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Andrzej Kowalczyk - AI - how to start small and grow in the f...](https://cdn.slidesharecdn.com/ss_thumbnails/oy1zmo94qv6vpcqjvno2-andrzej-kowalczyk-ai-how-to-start-small-and-grow-in-the-future-1-260119121559-cf093b23-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Milos Belcevic - Product Professional's Journey to Full-Stack...](https://cdn.slidesharecdn.com/ss_thumbnails/1zovd6fgsycdg4wvgvls-milos-belcevic-product-professionals-journey-to-full-stack-product-developer-260123083019-d993120d-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Laila Kakar - Leveraging AI for Strategic Excellence: Enhanci...](https://cdn.slidesharecdn.com/ss_thumbnails/eykmhrtsqmaaftwkexh7-dsc-lailakakar-1-260119101520-5f3b5616-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Milovan Jovicic - Beyond AI's Reach: The Enduring Value of Ev...](https://cdn.slidesharecdn.com/ss_thumbnails/pyeij0hurgwq5jugmtnv-2-milovan-jovicic-beyond-ais-reach-the-enduring-value-of-evergreen-design-v2-260120105856-d6ee57e5-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Tamas Srancsik - How To Teach Your AI Football? An Argument f...](https://cdn.slidesharecdn.com/ss_thumbnails/bcjh1m9xtbosv20ucftb-tamas-srancsik-how-to-teach-your-ai-football-260121115910-08b53e9e-thumbnail.jpg?width=640&height=640&fit=bounds)

