Download as PDF, PPTX




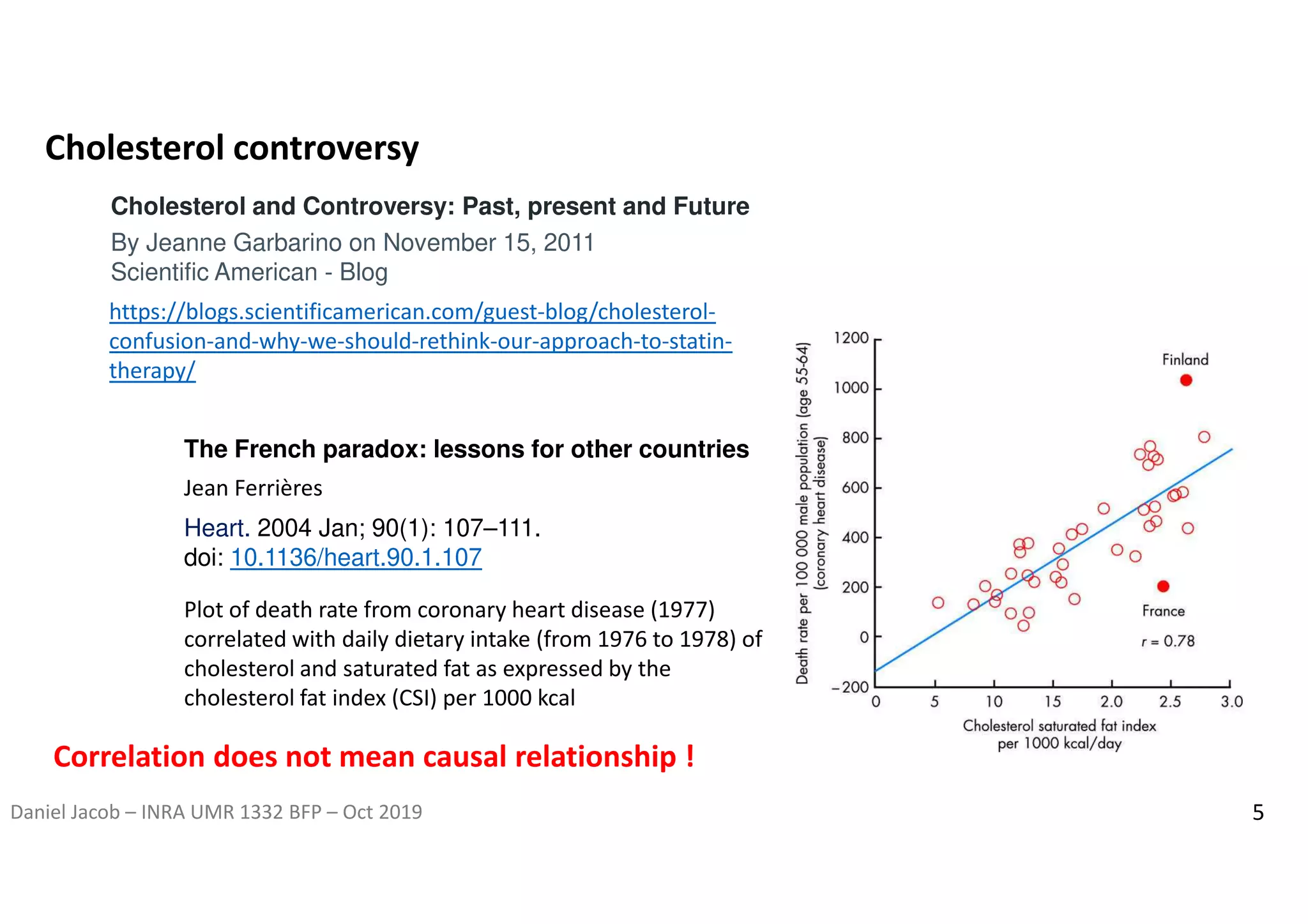

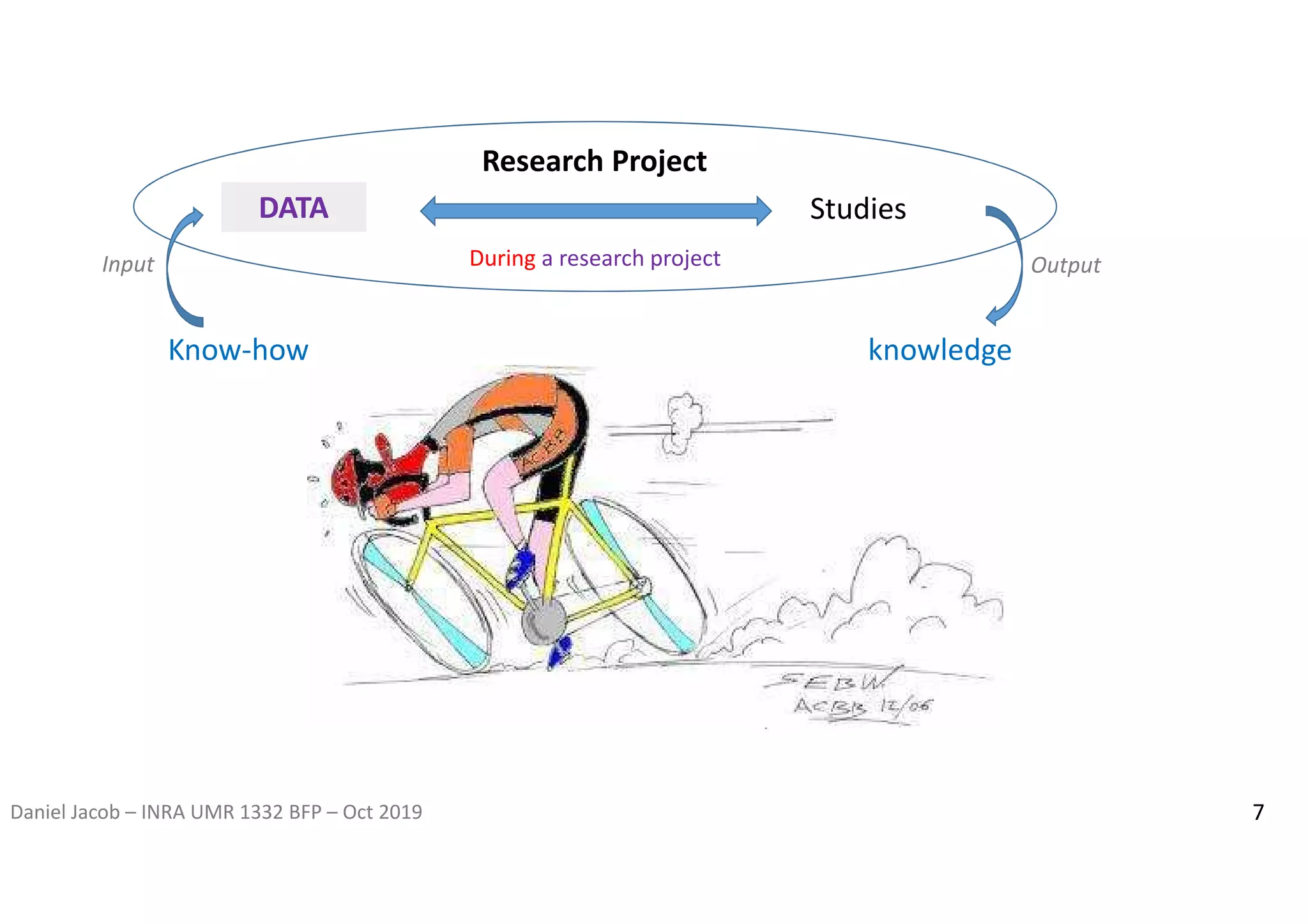

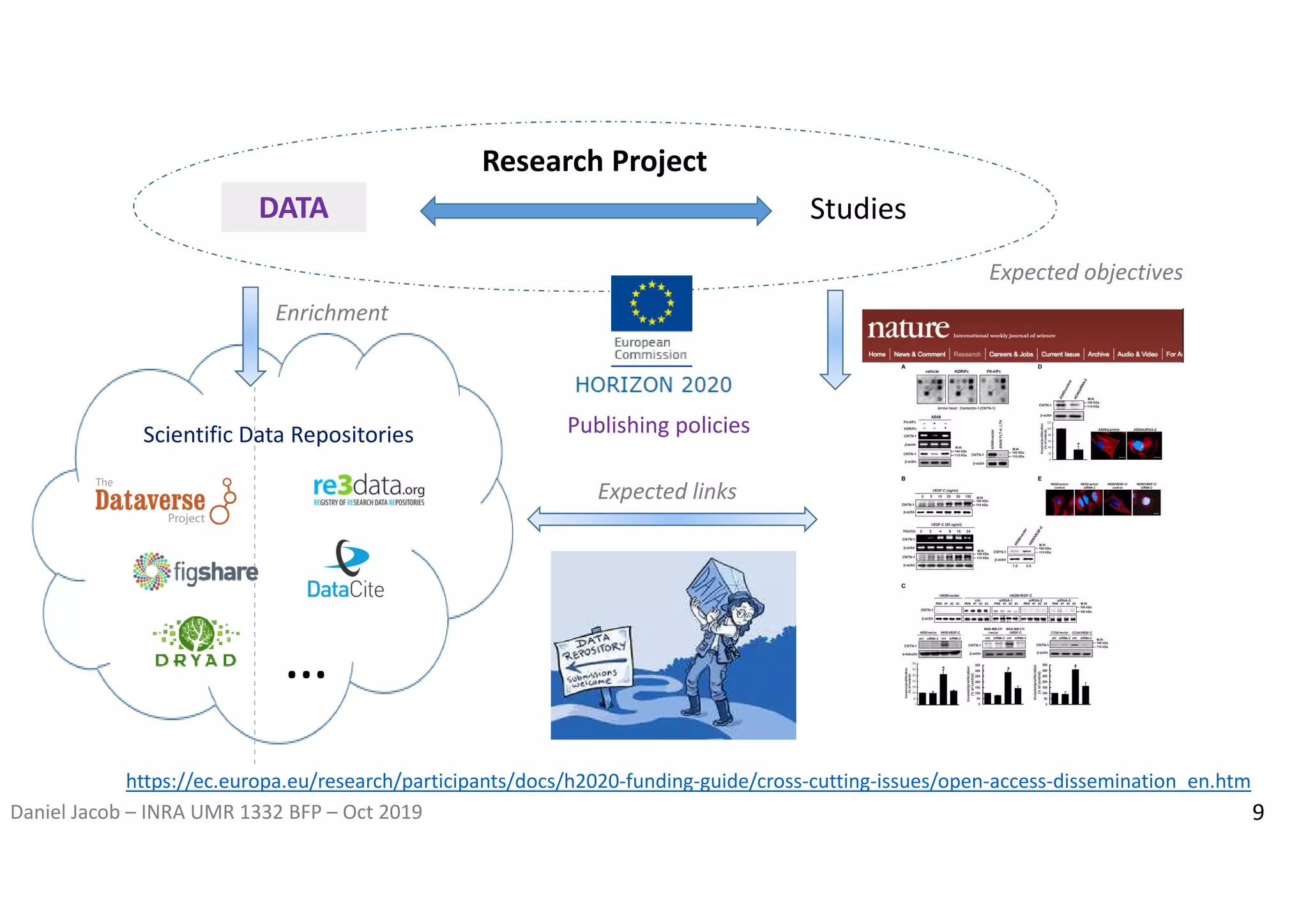








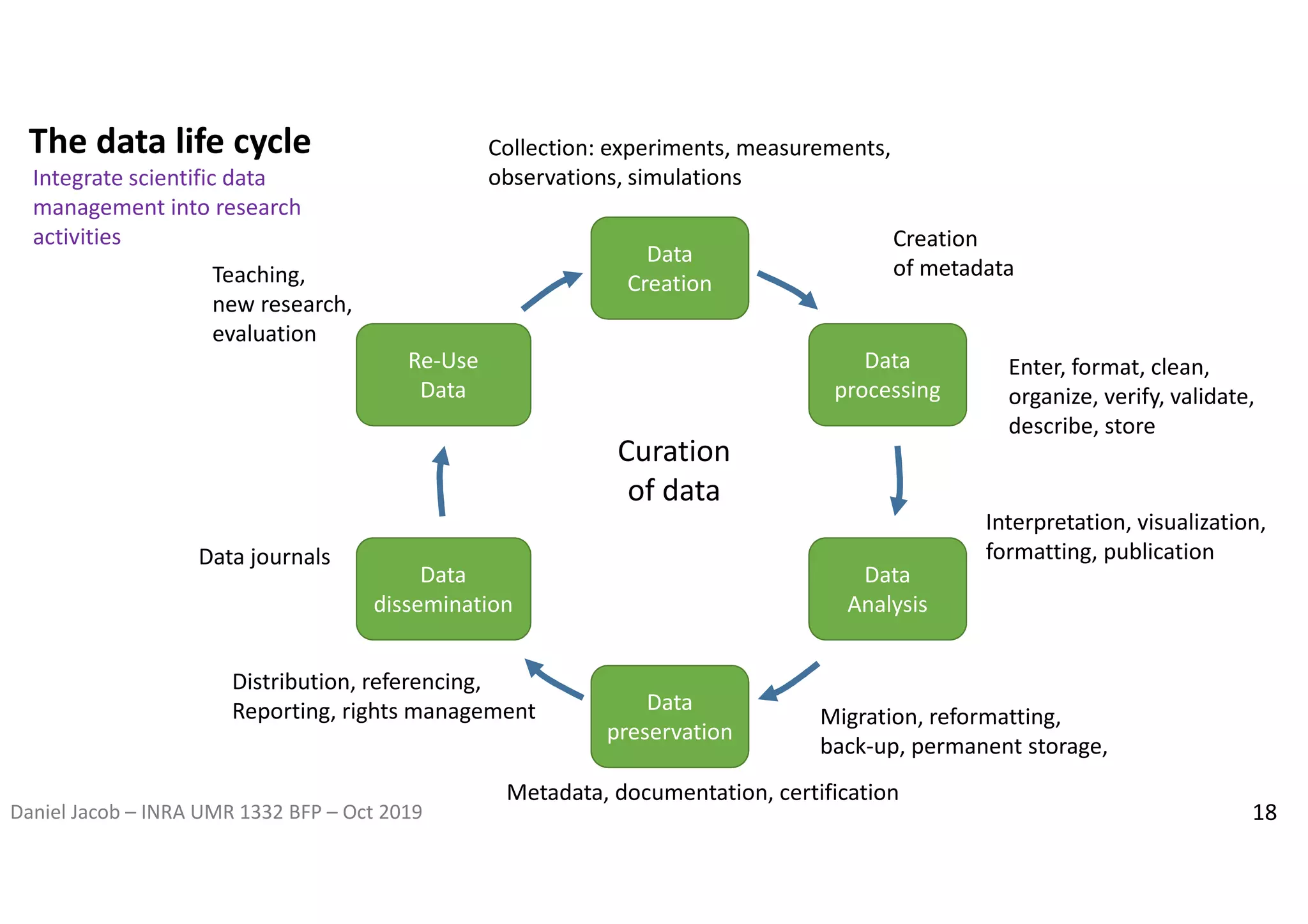
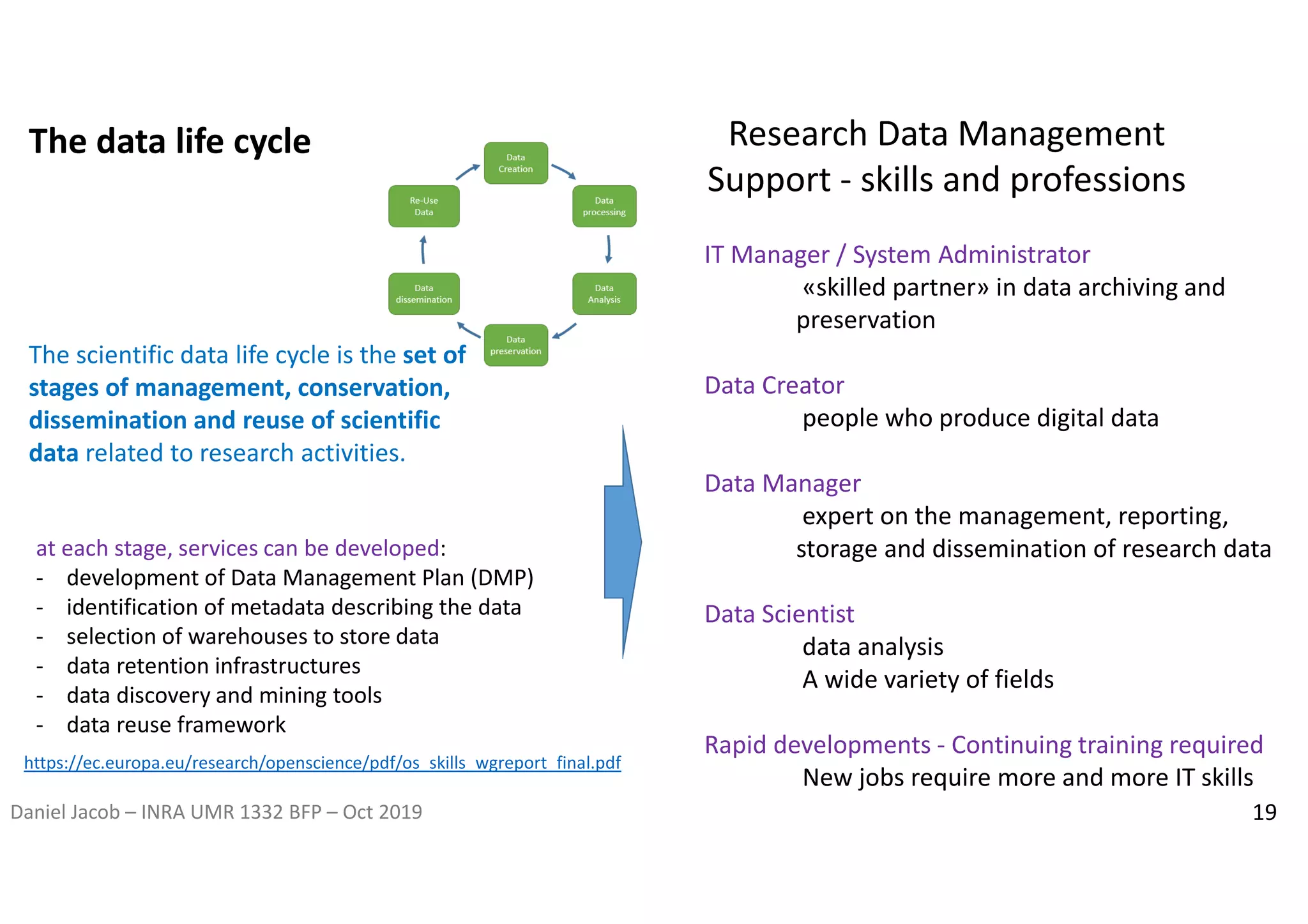


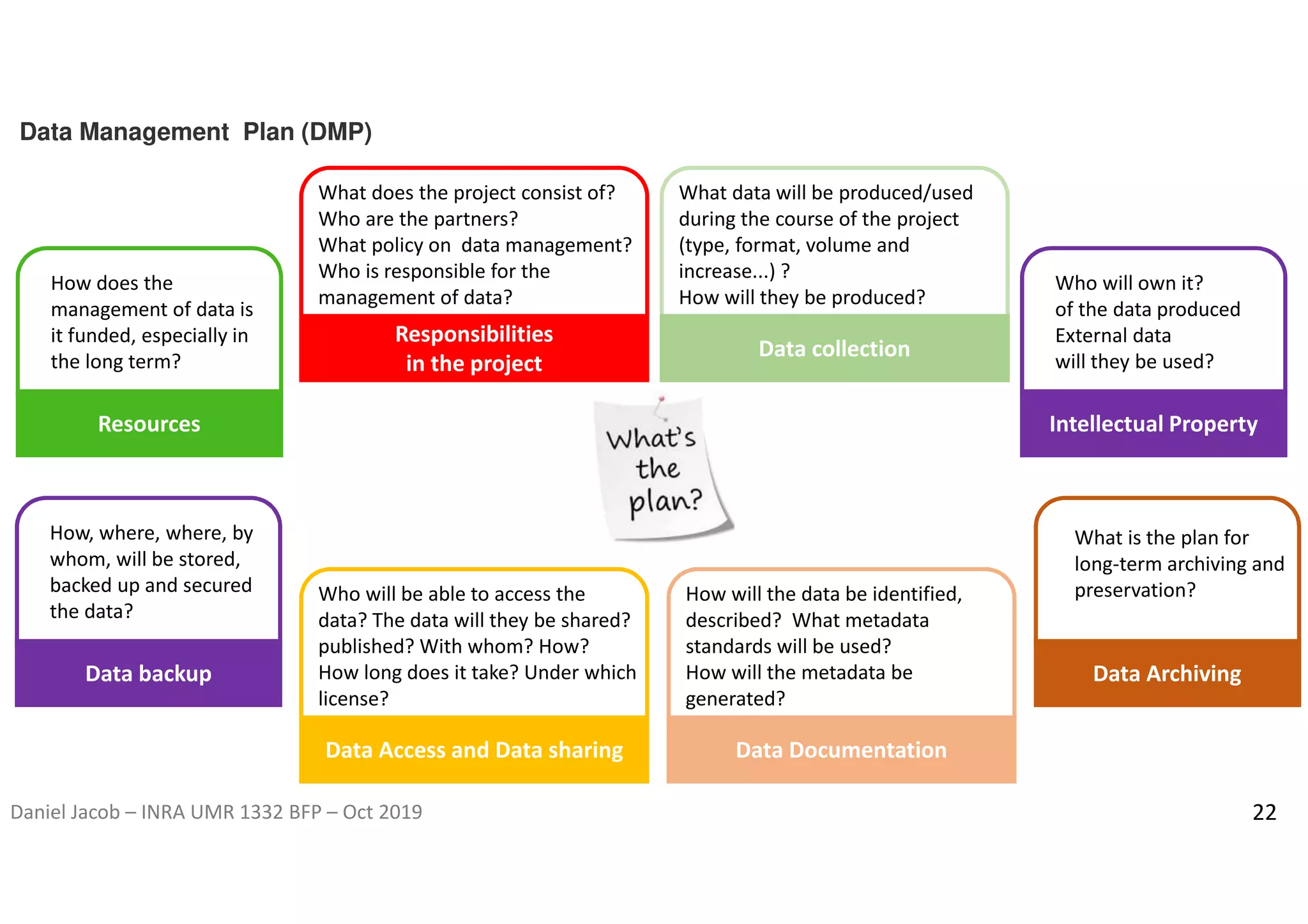





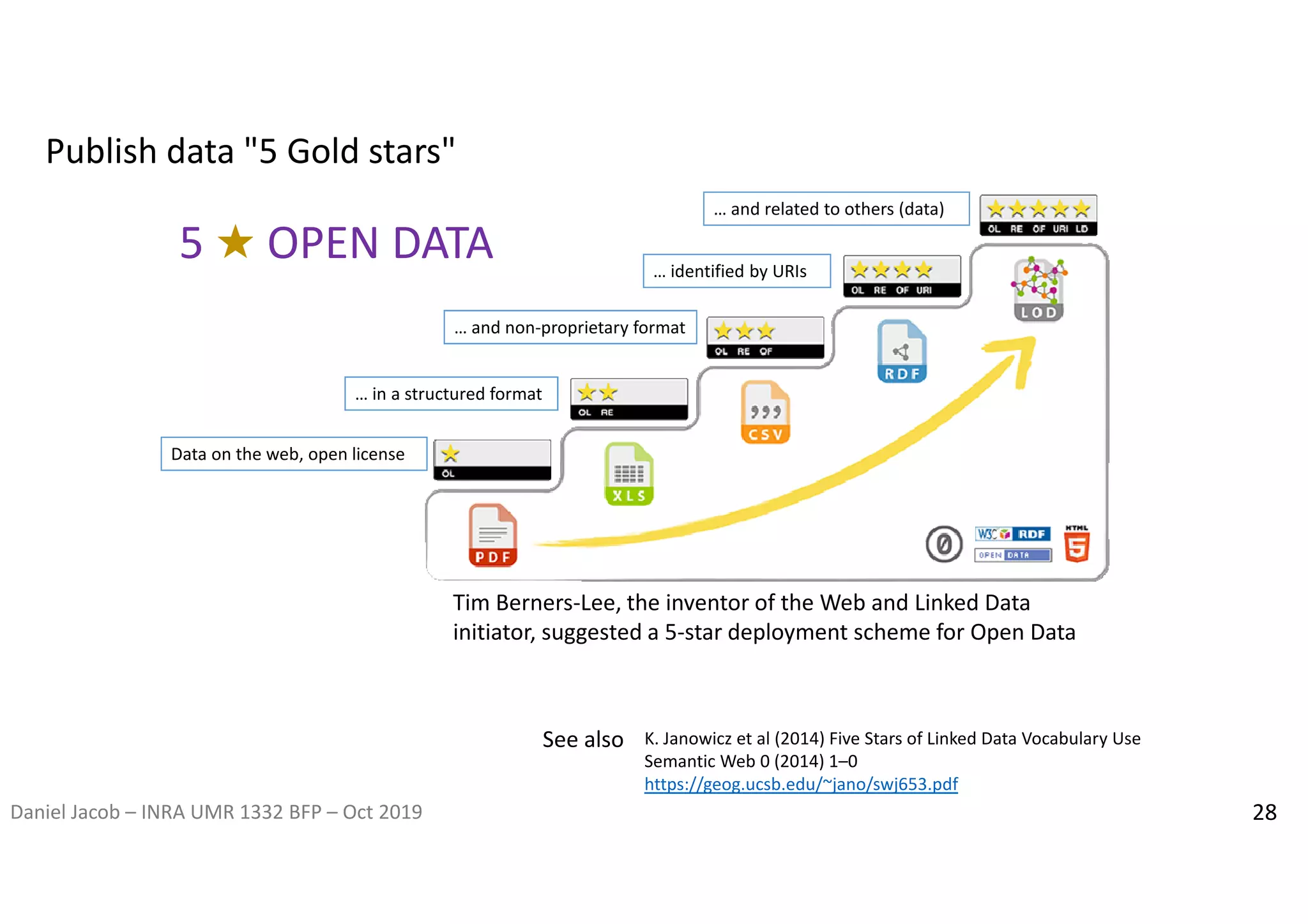











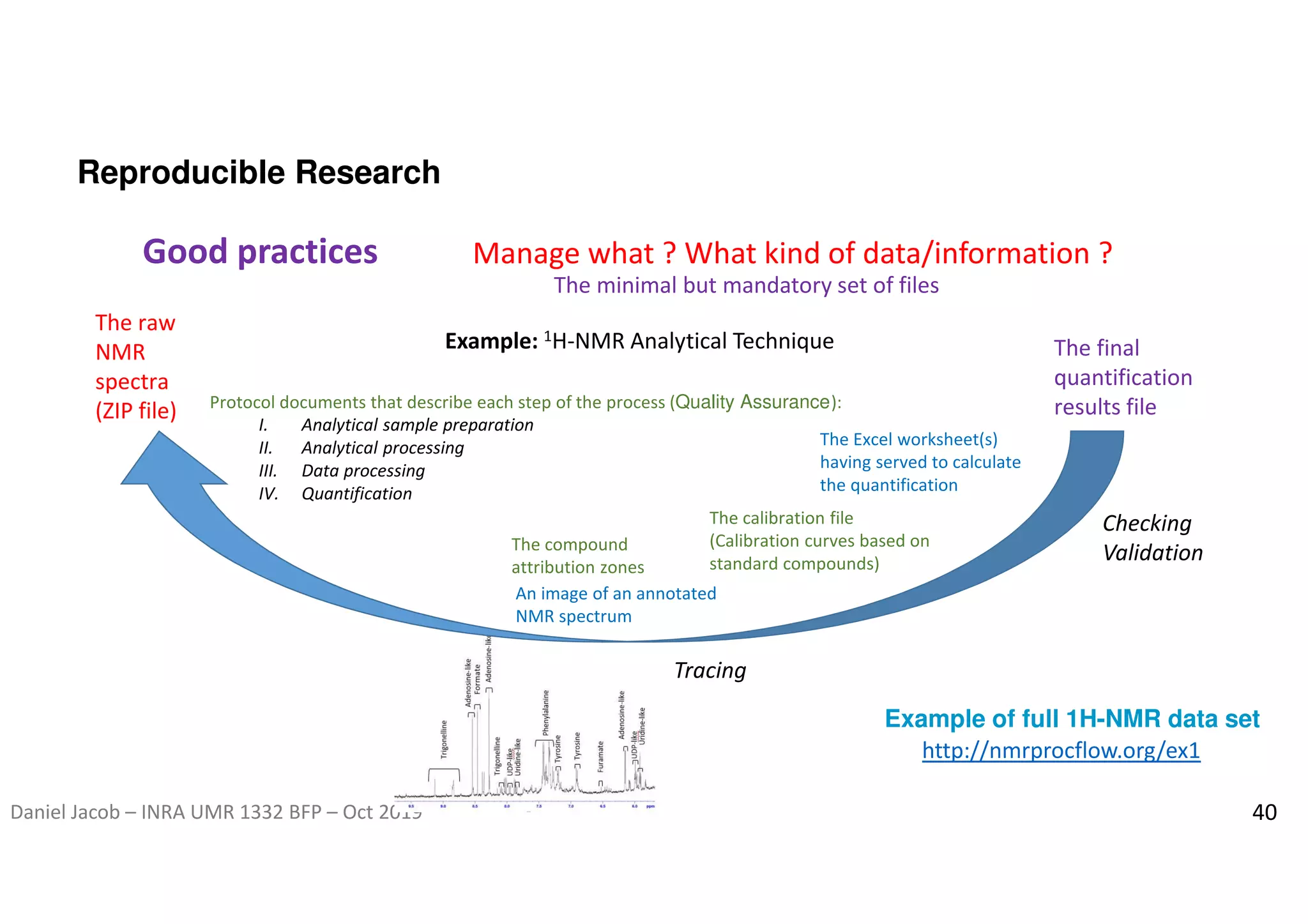






The document discusses the importance of research data management and open science, emphasizing the need for transparency, reproducibility, and proper data handling practices. It outlines the challenges of the reproducibility crisis in science and the significance of managing data throughout its life cycle, including collection, analysis, preservation, and sharing. The document also details the FAIR data principles aimed at improving data accessibility, interoperability, and reusability in research.







































































